sql의 기초 문법을 알아보자.
create
테이블을 만들 때는 create table 명령어를 사용한다.
create table table1
(
// attribute
attribute1 char(5),
attribute2 varchar(20) not null,
attribute3 numeric(8,2),
// key
primary key (attribute1),
foreign key (attribute2) references table2
)- primary key는 여러 attribute를 넣을 수 있다.
- foreign key는 어떤 테이블을 레퍼러스하느냐에 따라서 여러 개 선언할 수 있다.
update
테이블을 업데이트하는 명령어는 여러 개 있다.
insert
insert into tablename values('aaa', 'bbb', 1234)values를 이용해서 직접 값을 입력해줄 수도 있고 select from where 문을 이용해서 다른 테이블에서 찾은 값을 입력할 수도 있다.
insert into r (name, id)
select name, id
from b
where name='aaa'select로 넣고 싶은 데이터를 가져와서 insert into문에 있는 괄호에 인자로 넘긴다. 주의할 점은 select로 가져오는 데이터 = 인자로 넘기는 데이터여야 한다는 점이다.
예를 들어 name과 id를 select해서 id만 넣거나, name만 select해서 name과 id를 모두 넣는 식으로는 작동하지 않는다.
delete
delete from tablename
where year='2017'where 절로 조건을 명시하지 않으면 모든 tuple을 삭제한다.
drop table
drop table tablename테이블을 삭제한다.
alter
// attribute 추가
alter table r add A D
// attribute 삭제
alter table r drop (A)테이블에 attribute를 추가하거나 테이블에서 삭제하는 기능이다.
attribute drop을 지원하지 않는 데이터베이스도 많다.
oracle live sql에서는 예시처럼 대상 attribute 이름을 괄호 안에 작성해야 동작한다.
update
tuple을 update하려면 update-set 문을 활용할 수 있다.
// 예시 1
update a
set salary = salary * 2
// 예시 2
update b
set salary = salary * 2
where salary < (select avg(salary) from b)update문에서는 조건문을 활용할 수 있다.
case-end문을 활용하면 되는데 예시는 아래와 같다.
update c
set salary = case
when salary > 10000 then salary * 1.5
else salary * 2
endcase문의 조건으로 subquery도 들어갈 수 있다.
다만 스칼라 값을 반환해야 하고 성능적으로 좋지 못할 가능성이 있다...
쿼리의 기본 구조 - select, from, where
쿼리는 기본적으로 select-from-where 구조로 이루어져있다.
select는 column 선택, from은 table 선택, where는 row 선택에 해당한다.
as
select 문에as를 붙이면 선택한 column을 변수처럼 할당할 수 있다.select name as n
where문의 경우 and를 활용해서 조건을 여러 개 붙일 수 있다.
from은 테이블을 선택할 때 쓰지만, 여러 개의 테이블을 대상으로 지정할 수 있다.
from instructor, teaches이 경우 두 테이블의 tuple을 짝지어서 가능한 모든 경우의 수를 만든다. (cartesian product)
| table a | table b | from a, b |
|---|---|---|
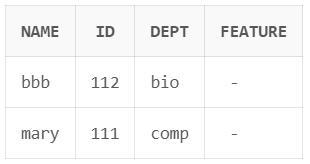 | 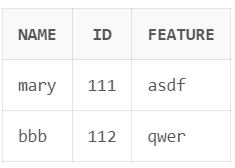 | 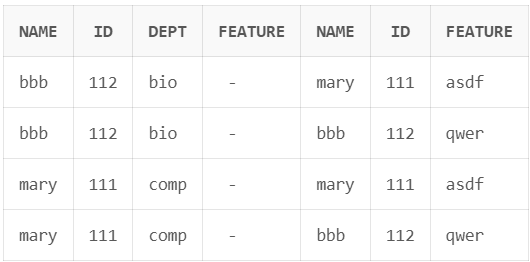 |
이 경우 앞에 쓴 테이블일수록 왼쪽에 붙는다.
또한 앞에 쓴 테이블의 첫 번째 tuple에 대한 경우의 수를 모두 따지고, 두 번째 tuple과 관련된 경우의 수를 만드는 방법으로 생성한다.
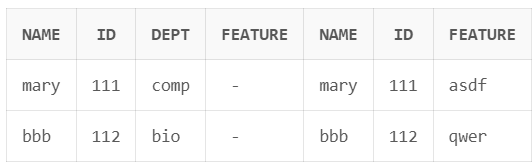
where문을 사용해서 조건을 추가할 수 있다.
아래 예시는 where a.name=b.name 조건을 통해 같은 name값을 가진 tuple끼리만 짝지은 결과이다.
where문의 조건은 between-and 를 활용해서 범위로 지정할 수도 있다.
ex) where salary between 90000 and 100000
like
sql에서는 해당 string을 포함하는 tuple도 검색할 수 있다.
string의 경우 %, char의 경우 _ 기호를 활용한다.
만약 문자열이 %나 _를 포함한다면 escape문을 활용한다.
select * from a where dept like '%*%%' escape '*'escape의 기준은 길이가 1인 문자열로 해야 하며, 꼭 기호일 필요는 없다.
%나 _를 붙이는 위치에 따라 검색 기준도 달라진다.
- intro% -> intro로 시작하는 문자열 검색
- %contain% -> contain을 포함하는 문자열 검색
- %end -> end로 끝나는 문자열 검색
- ___ -> 세 글자인 문자열 검색
- % 또는 % -> 세 글자 이상인 문자열 검색
like의 자료형 제한
varchartype은 string 검색으로만 찾을 수 있지만numerictype은 string과 char 검색 방법 모두 이용할 수 있다.
order by
order by 를 활용해서 tuple을 정렬할 수 있다.
조건으로 여러 개의 attribute를 지정하는 것도 가능하다. 정렬 방법은 기본이 asc이고, desc 태그를 붙이면 내림차순으로도 가능하다.
집합 명령어
union, intersect, except 를 활용하면 두 개의 조건을 두고 검색한 column/tuple에 집합 계산을 수행할 수 있다.
oracle에서는 except대신
minus를 쓴다.
집합 명령어는 자동으로 중복을 제거하는데 유지하고 싶다면 union all, except all 처럼 작성하면 된다.
aggregate functions
avg, min, max, sum, count
위 5가지의 통계 함수를 사용할 수 있으며 대상 column을 괄호 안에 명시한다.
// ex1
select avg(salary)
// ex2
select count(*)group by
통계를 낼 때 tuple끼리 기준에 따라 묶을 수 있다.
예를 들어 교수를 전공 영역에 따라 분류해서 각 전공 별 평균 연봉을 알아보려고 한다면 이 기능을 사용할 수 있다.
예시 코드는 다음과 같다.
select dept_name, avg(salary)
from instructor
group by dept_name주의할 점
select문에 조건으로 들어간 attribute 중 aggregate function의 인자로 쓰이지 않은 것은 전부 group by에도 들어가야 한다.
예를 들어 select a, avg(b) - group by a처럼 작성하면 괜찮지만,
select a, c, avg(b) - group by a처럼 작성하면 오류가 발생한다.
having
aggregate function의 결과값에 조건을 걸고 싶을 때 having 문을 활용한다.
where와 다른 점
where는 group by가 이뤄지기 전에 모든 tuple을 대상으로 동작하지만, having은 그룹이 생성된 이후에 해당 그룹을 대상으로 조건을 적용한다.
