관계형 데이터베이스
관계형 스키마와 인스턴스
attributes -> relation schema
attribute
각 데이터가 공유하는 타입을 domain이라고 한다. 관계형 DB에서 attribute 값은 더 쪼개질 수 없는 가장 작은 단위에 해당한다(원자적).
key
key
DB상에 중복 없이 하나만 존재하여 인덱싱에 쓰이는 값
superkey
key를 포함해서 tuple을 식별할 수 있게 하는 고유한 값
ex) ID와 ID,name은 모두 superkey에 해당한다.
candidate key
superkey중에서 가장 간결한 값
ex) ID는 candidate key지만 ID.name은 candidate key가 아니다.
primary key
candidate key는 여러 개 존재할 수 있다. 이 중에서 하나를 primary key로 선정할 수 있는데 정해진 기준이 없고 DB마다 다르기 때문에 상황에 맞게 사용하면 된다.
ex) 학번, 주민번호, 전화번호가 candidate라면, 전화번호는 가지지 않은 사람이 있을 수도 있고 주민번호는 예민한 개인정보이기 때문에 학번을 primary로 선정
foreign key
현재 테이블에서는 key가 아니지만 다른 테이블에서는 고유해서 join에 쓸 수 있는 참조용 키. 레퍼런스가 되는 키와 레퍼런스를 하는 키로 나눌 수 있다.
제약 조건
모든 Foreign key는 각자가 primary key가 되는 테이블에서 반드시 존재해야 한다.
예를 들어 테이블 A의 특정 attribute가 a b c b d c a b 구성이고,
테이블 B에서 a b c 구성이라면 primary key가 되는 테이블 B에 'd'가 존재하지 않으므로 foreign key로 쓸 수 없다. 하지만 반대 방향은 상관 없다.
foreign key가 반드시 단일 값일 필요는 없다.
예를 들어 건물 이름과 방 번호가 있다면 건물 이름attribute + 방 번호attribute를 합해서 하나의 foreign key로 쓸 수 있다. 하지만 건물 이름만, 또는 방 번호만으로는 값을 식별할 수 없을 것이다.
Schema Diagram
관계형 데이터베이스에서 attribute사이의 레퍼런스 관계를 나타낸 다이어그램.
Relational Query Languages
관계형 질의어
Pure Languages
- relational algebra
- tuple relational calculus
- domain relational calculus
이 중 relational algebra는 비절차 언어인 SQL과 달리, 절차적인 관계형 질의어이다. 명령어를 여러 개 실행할 경우 괄호로 묶어서 단계에 따라 수행할 수 있다.
Relational Algebra
relation 관련 연산을 수행하기 위한 절차적 언어이다.
기본 기능
select: σ
project: Π
union: ∪
set difference: –
Cartesian product: x
Join: ⋈
rename: ρ
Select
조건에 맞는 tuple을 선택한다. DB 명과 attribute값을 인자로 갖는다.
σ tuple_value='value' (relation_name)
논리 연산자를 활용해서 복합 조건을 사용할 수 있다. 또한 조건으로 비교 연산자를 쓸 수 있다.
조건문에서는 ∧(and), ∨(or), ¬(not) 를 통해 여러 가지의 조건을 둘 수 있다.
또한 dept_name=building 처럼 attribute끼리 직접 비교해도 된다.
select의 relation에는 또다른 select문이 들어갈 수 있다.
Project
조건에 맞는 attribute를 선택한다.
Π a1, a2, a3, ..., ak (relation_name)
기존 테이블에서 선택한 열만 모아 만든 새로운 relation을 반환한다. SQL의 select와 비슷하다.
relation이 집합의 성질을 갖기 때문에, 특정 열 값을 지움으로써 동일해진 행이 존재한다면 중복으로 간주하고 삭제한다.
relational algebra에서는 Π(σ~) 형태로 쓰는 일이 많다.
Cartesian product & Join
두 명령어 모두 테이블을 동일 속성을 기준 키로 하여 합치는 기능이다.
먼저 Cartesian product 는 relation간에 가능한 모든 경우의 수를 만드는 기능이다. 조건을 추가하려면 select 문에 넣으면 된다. 식을 작성하면 다음과 같다.
σ condition (r1 x r2)
Join 은 cartesian product과 같은 기능을 하지만 select가 없어도 자체적으로 조건을 가진다. 따라서 또다른 select문과 같이 사용할 수 있다.
r1 ⋈ condition r2
Union
두 테이블의 합집합을 구한다. ∪ 기호로 나타낸다.
테이블을 합치려면 속성 개수가 같아야 하고, 대응하는 속성의 타입이 같아야 한다.
sql의 union과 비슷한 방법으로 사용한다.
Set Difference
두 테이블의 차집합을 구한다. union과는 기호만 다르고 비슷한 방법으로 사용한다.
Assignment
← 기호를 활용하여 변수에 relation을 할당한다.
예시)
Physics ← σ (property)
Music ← σ (property)
Physics ∪ Music
Rename
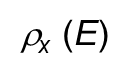
결과값 E를 X의 이름으로 반환한다.
ρx (E)
x(A1, A2, ..., An) 처럼 작성하면 특정 column만 반환할 수 있다.
Cartesian-product operation
서로 다른 두 개의 table이 있을 때 table A × table B를 구한다.
이 결과를 활용해서 join operation을 수행할 수 있다.
