파일
데이터베이스는 일련의 파일에 저장된다.
파일은 레코드로 이루어진 시퀀스이며, 레코드는 필드로 이루어진 시퀀스이다.
fixed-length records
길이가 고정된 레코드의 경우 size n의 레코드 i개를 n*i 바이트 안에 저장할 수 있다.
이 경우 레코드 접근은 간단하지만, 레코드가 블록을 넘어서는 경우도 발생한다.
variable-length records
레코드의 길이가 변수이다.
이 경우 여러 가지의 레코드 타입을 파일에 저장할 수 있다.
Slotted page structure
페이지를 고정 크기의 슬롯으로 나누고 각 슬롯에 레코드 길이 등 레코드와 관련된 정보를 저장하는 슬롯 헤더를 두는 방식이다.
레코드가 페이지 사이를 오가며 공백을 두지 않고 연속적으로 위치하도록 배열할 수 있으며, 포인터는 레코드가 아니라 헤더에 위치한 엔트리를 가리키게 된다.
용량이 큰 데이터를 적재하는 법
blob/clob 등의 볼륨이 큰 데이터의 경우, 레코드가 기본적으로 페이지보다 작아야 하기 때문에 페이지에 적재하기 힘들다.
따라서 대규모 데이터를 시스템 또는 DB상에 별개의 파일로 저장하거나,
데이터 자체를 튜플로 쪼개서 여러 개의 relation 형태로 저장할 수도 있다.
파일에서 레코드를 저장하는 방법
- Heap
- sequential
- multitable clusterling file organization
heap file organization
레코드를 파일 내 빈 공간 아무 곳에나 저장할 수 있다.
보통 한 번 할당되면 그 뒤로 위치를 이동할 수 없으며 빈 공간을 찾는 과정에서 효율적인 알고리즘이 쓰인다는 보장이 필요하다. (단편화 가능성)
free-space map
힙 방식에서는 빈 공간을 파악하는 것이 중요하다.
따라서 free-space를 맵으로 관리하는데, 이 맵은 3비트 엔트리로 이루어진 배열이다.
각 배열은 3비트이므로 0부터 8까지의 숫자를 표시한다.
예를 들어 배열의 0번 인덱스가 5라면 0번째 엔트리는 5/8만큼의 공간이 비어있다는 의미가 된다.
free-space map의 업데이트
주기적으로 업데이트되기 때문에 잘못된 값이 있어도 크리티컬한 문제가 발생하지는 않는다.
sequential file organization
파일 전체에 걸쳐서 순차적으로 작업해야 하는 프로그램에 적합한 방식이다.
파일 내 레코드는 search-key 를 통해 순서에 맞춰 저장된다.
multitable clustering file organization
여러 개의 릴레이션으로 이루어진 데이터를 한 파일에 저장하는 방식이다.
이 경우 저장된 데이터가 겉보기에는 테이블 모양이지만, 결국 파일 하나에 모두 저장해야 하기 때문에 attribute의 종류에 따라 행을 구분하지 않는다.
예시는 다음과 같다.
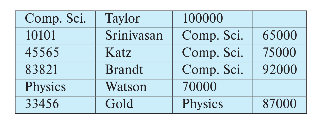
출처 : https://db-book.com/
레코드를 특정한 릴레이션으로 묶기 위해 pointer chain 을 활용할 수 있다.
partitioning
릴레이션 내의 레코드를 더 작은 부분으로 나누어 각자 저장하는 방식을 말한다.
트랜잭션으로 쿼리를 작성했을 시, 모든 파티션의 레코드에 접근해야 한다.
장점
- 파티셔닝을 통해
free space management등의 연산을 간략화할 수 있다. - 또한 서로 다른 파티션을 각각 다른 저장장치에 나눠 보관할 수 있다.
data dictionary storage
데이터 딕셔너리(시스템 카탈로그라고도 불린다)는 메타데이터 를 보관하는 역할을 한다.
메모리에 접근하기 쉽도록 특성화된 데이터 구조를 사용한다.
buffer manager
프로그램은 디스크의 블록이 필요할 때 버퍼 매니저를 호출한다.
만약 해당 블록이 이미 버퍼에 있다면 버퍼에서 바로 주소를 얻을 수 있고, 그렇지 않다면 데이터를 가져오는 과정을 거쳐야 한다.
- 버퍼에 블록을 위한 공간을 할당한다.
- 이 과정에서 필요하다면 기존에 자리를 차지하던 블록을 제거한다. (변경사항 있으면 디스크에 기록)
- 디스크에서 버퍼로 블록을 읽어온 후 해당 데이터를 요구한 프로세스에 전달한다.
pinned block
디스크에 쓰기되는 것이 (일시적으로)금지된 버퍼 블록이다.
블록마다 핀 카운트가 있고 해당 숫자가 0이 될 때만 플러시가 가능하다.
read/write가 완료되기 전에 pin 을, 완료된 후에 unpin을 수행한다.
하나에 블록에 여러 개의 핀/언핀을 동시에 할 수 있다.
공유 락과 배타 락
페이지에 변화가 생겼을 때 중간 상태를 다른 작업에서 읽지 못하도록 보호하기 위한 장치이다. 같은 시점에 하나의 프로세스만 배타 락을 가질 수 있으며, 공유 락과 배타 락을 동시에 가질 수는 없다.
공유 락은 여러 프로새스가 동시에 획득할 수 있다.
buffer replacement policies
대부분의 OS는 블록을 LRU로 처리한다. (가장 최근에 쓰이지 않은 블록 삭제)
이 외에도 toss-immediate, MRU 등의 방식이 있다.
toss-immediate
블록에 공간을 할당해줬다가 프로세스가 끝나면 곧바로 자리를 비워 이후에 사용할 수 있도록 한다.
MRU
현재 사용하고 있는 블록에 핀을 두었다가 프로세스가 끝나면 핀을 해제해서 MRU로 만든다.
columnar representation
릴레이션의 각 속성을 따로 분류해서 열 단위로 저장하는 방식이다.
column-oriented storage 라고도 부른다.
장점
- 특정 속성만 참조해야 하는 경우 IO 처리량을 줄일 수 있다.
- cpu 캐시의 성능을 개선한다.
- 압축 성능이 종하진다.
vector processing을 할 수 있다.
단점
- 속성을 나누어서 새로 튜플을 만드는 데 비용이 소모된다.
- 튜플을 삭제하거나 업데이트할 때 column 여러 개를 일일히 수정해야 하므로 시간이 오래 걸린다.
column 뿐만 아니라 row-oriented storage도 있는데, 일반적으로 열 방식이 더 효율적이다.
두 방식을 모두 제공하는 경우 hybrid row/column stores 라고 부른다.
