TMDB API 데이터를 사용하며 클린 아키텍처를 적용해보자.
클린 아키텍처란?
지금까지 소프트웨어를 구성하는 데 필요한 다양한 요소를 배웠다. 어떤 것이 있었는지 상품 판매 프로그램을 예시로 들면서 되짚어보자.
우선 사용자나 상품 데이터를 저장하는 모델이 있어야 한다. 그렇다고 해서 모델만 있으면 안 되고, 물건을 등록하거나 회원가입을 할 수 있게 연결하는 함수도 필요하다.
그렇게 잘 빚은 데이터를 저장하려면 데이터베이스와 통신하는 코드는 물론이고 데이터베이스 자체도 빠져서는 안 된다. 마지막으로 이 모든 일을 하려면 사용자가 클릭할 수 있는 UI가 있어야 한다.
이처럼 개발자는 목적도 구현 방법도 다양한 기능을 이것저것 만든다. 그리고 이 모든 코드는 어쨌거나 한 프로젝트 파일 안에 있어야 한다. 이때 데이터 흐름을 깔끔하게 제어하지 않으면 종류가 다른 코드끼리 섞여서 유지보수하기 매우 어려워질 것이다.
이러한 현상을 방지하기 위해 기능을 계층에 따라 나눠서 개발하자는 아이디어에서 출발한 소프트웨어 개발 방법론이 바로 클린 아키텍처이다.
구성 요소에는 무엇이 있을까?
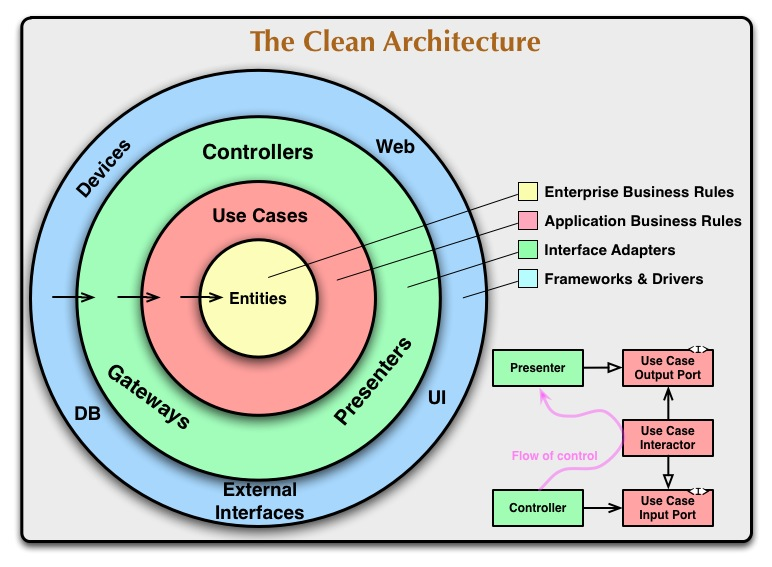
유명한 그림클린 아키텍처에서는 각 계층을 레이어(layer) 라고 부른다.
큰 범주에서 레이어는 다음 4개로 생각하면 된다.
- Entities : 핵심 개념(예시 : User 모델 클래스)
엔티티에 정의하는 데이터는 거의 변하지 않는다. 소프트웨어의 한 부분에 한정되는 것이 아니라 전역으로 쓰이는 데이터, 일반화된 핵심 데이터를 이곳에 생성한다.- Use Cases : 애플리케이션의 기능과 관련된 부분(예시 : 회원 가입 기능)
- Interface Adapters : Use Cases와 Frameworks and Drivers 사이 연결고리(예시 : 회원 레포지토리에 접근하는 뷰모델)
- Frameworks and Drivers : 시스템 핵심 업무와 상관없는 외부 기능(예시 : 회원 정보를 저장하는 데이터베이스, UI)
의존성 규칙이란?
위 구성 요소에서 위쪽(안쪽)에 있는 Entities와 Use Cases는 고수준 영역, 아래쪽(바깥쪽)에 있는 interface Adapters와 Frameworks and Drivers는 저수준 영역이라고 부른다.
클린 아키텍처에서는 저수준에서 고수준 영역으로 영향을 끼칠 수 없다. 비즈니스 핵심 로직은 일정하고, 핵심에서 먼 영역에 위치한 기능은 상위 로직을 참조할 뿐이다.
이러한 규칙을 의존성 규칙(Dependency Rule)이라고 부른다. 클린 아키텍처의 핵심은 바로 이 의존성 규칙을 지키는 것이다. 레이어를 4개 이상 가짓수로 나누더라도, 레이어를 동심원 모양으로 명확히 구분할 수 없더라도 의존성 규칙만 지켰다면 클린 아키텍처라고 할 수 있다.
예를 들어 뷰모델을 편집할 때마다 데이터 모델에 변동이 발생한다면 안정적인 소프트웨어라고 할 수 없다. 데이터 모델은 가장 핵심에 가까운 Entities 영역에 속하므로 가능한 한 일정해야 한다.
또 다른 예시를 들어보자.
서버 상의 데이터를 받아와서 Model 타입 객체를 만들 일이 생겼다. 이 때 Model 에서 바로 서버 데이터를 참조한다면 클린 아키텍처라고 부를 수 없다. 왜냐하면 서버에 변경점이 생겼을 때 DB보다 고수준 영역에 속하는 모델을 편집하는 불상사가 발생하기 때문이다.
이상적으로 의존성 규칙을 지키려면 Use Cases 계층에서 서버 데이터를 이래저래 잘라서 모델 객체를 생성하는 식으로 코드를 짜는 편이 나을 것이다.
DTO
DTO 는 Data Tranfer Object의 줄임말로, 데이터를 전달하는 객체를 뜻한다. 지금까지는 DTO를 따로 두지 않고도 서버에서 데이터를 잘만 받아왔었다.
하지만 DTO에는 데이터를 요청할 때 덧붙여야 하는 다양한 조건문을 포함할 수 있다. (유효성 검사, 그로 인해 발생하는 복잡한 쿼리문 등) 이런 조건을 뷰모델에 두면 코드가 길어진다. 그렇다고 모델에 작성하자니 모델은 위에서 설명한 것처럼 비즈니스 핵심 로직이라 최대한 필수불가결한 데이터만 포함하고 비즈니스 로직에 따라 변동해서는 안된다.
그리고 Use Cases도 DB보다는 고수준 영역에 위치하니까 DB로부터 바로 데이터를 읽어오기보다는 DTO를 가운데 끼고 운영하는 편이 의존성 규칙을 지키기에도 좋을 것 같다.
이럴 때 중간에 DTO를 두면 다음과 같은 장점이 발생할 것이라고 유추했다.
- 코드가 짧아진다.
- 의존성 규칙을 지킬 수 있다.
- 데이터를 받아오는 부분을 DTO 혼자서 온전히 담당하므로 명료성을 챙긴다.
이상적인 구조는
- 서버에서 데이터를 받아온다. (이때 DTO 이용)
- Use Cases 계층에서 받아온 데이터로 객체를 생성한다.
-> Entities, Use Cases 모두 서버 데이터의 형태에 영향받지 않는다.
인 것 같다. 다음 시간에는 실제로 DTO를 사용해서 클린 아키텍처로 API 데이터를 다뤄보자.
