
비정형 데이터베이스
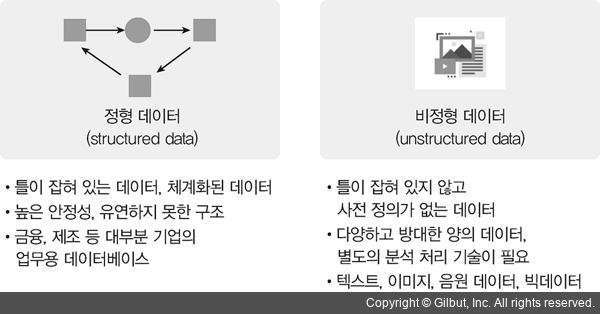
정형 데이터란?
- 고정된 필드에 저장된 데이터
- 데이터베이스를 설계한 사람에 의해 수집되는 정보의 형태가 정해짐
ex) 관계형 DB의 테이블들, 엑셀 스프레드시트 등
비정형 데이터란?
- 미리 정해져서 고정되어 있는 필드에 저장되어 있지 않은 데이터
ex) 페이스북, 트위터, 유튜브 등으로 생성되는 소셜 데이터 & IoT 환경에서 생성되는 위치 정보다 센서 데이터와 같은 사물 데이터 등
비정형 데이터의 등장 배경
-
빅데이터 시대의 도래
-> 기존의 RDB나 DW와 같은 정형 데이터 베이스만으로는 해결이 어려움
-> 분산 시스템으로 갈 수 밖에 없음분산 시스템
: 작업이나 데이터를 여러 대의 컴퓨터에 나누어서 처리, 저장하여 그 내용이나 결과가 통신망을 통해 상호교환 되도록 연결되어 있는 시스템
CAP 이론
: 분산 시스템이 세 가지를 모두 만족시키는 것은 불가능하다. 셋 중 최대 두 개까지만 만족시킬 수 있다.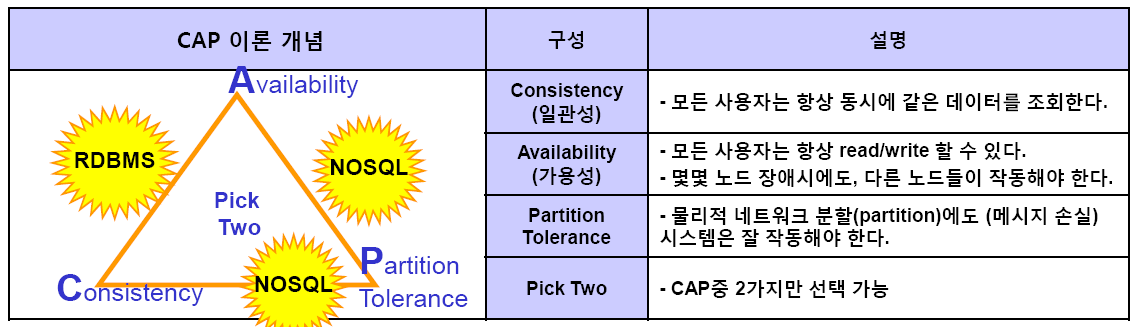 기존의 RDB가 C와 A 중심이라면, 비정형 데이터베이스는 P를 중시함
기존의 RDB가 C와 A 중심이라면, 비정형 데이터베이스는 P를 중시함=> 분산 환경 하에서 대용량의 데이터를 신속하게 처리할 비정형 데이터베이스가 등장하게 됨
NoSQL
= Not-Only SQL 혹은 No SQL
- 전통적인 RDBMS와 다르게 설계된 비관계형 데이터베이스
- 스키마가 없는 데이터베이스
- 덜 제한적인 데이터 저장 및 검색 메커니즘을 제공함
- 용이한 데이터 규모 확장성
=> 데이터를 다수의 하드웨어에 분산하여 저장함 - 대용량의 구조적 / 반구조적 데이터들을 저장&분석
ex) 웹, 소셜 미디어, 그래픽 등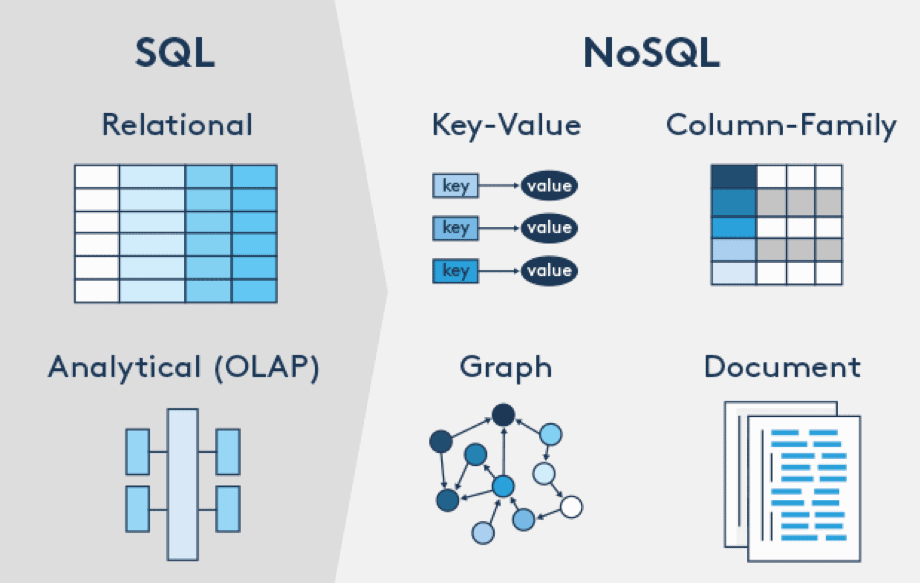
NoSQL의 특징
1. 스키마가 없음
- 고정된 스키마 없이 Key 값을 이용하여 다양한 형태의 데이터 저장 및 접근
2. 탄력성(유연성)
- 시스템 일부에 장애가 발생해도 클라이언트가 시스템에 접근 가능
- 응용 시스템의 다운 타임이 없도록 하는 동시에 대용량 데이터의 생성 및 갱신
- 시스템 규모와 성능 확장이 용이하며, 입출력의 부하는 분산시키는 데 용이한
3. 쿼리(Query) 가능
- 데이터의 특성에 맞게 효율적으로 데이터를 검색&처리 가능
RDBMS VS. NoSQL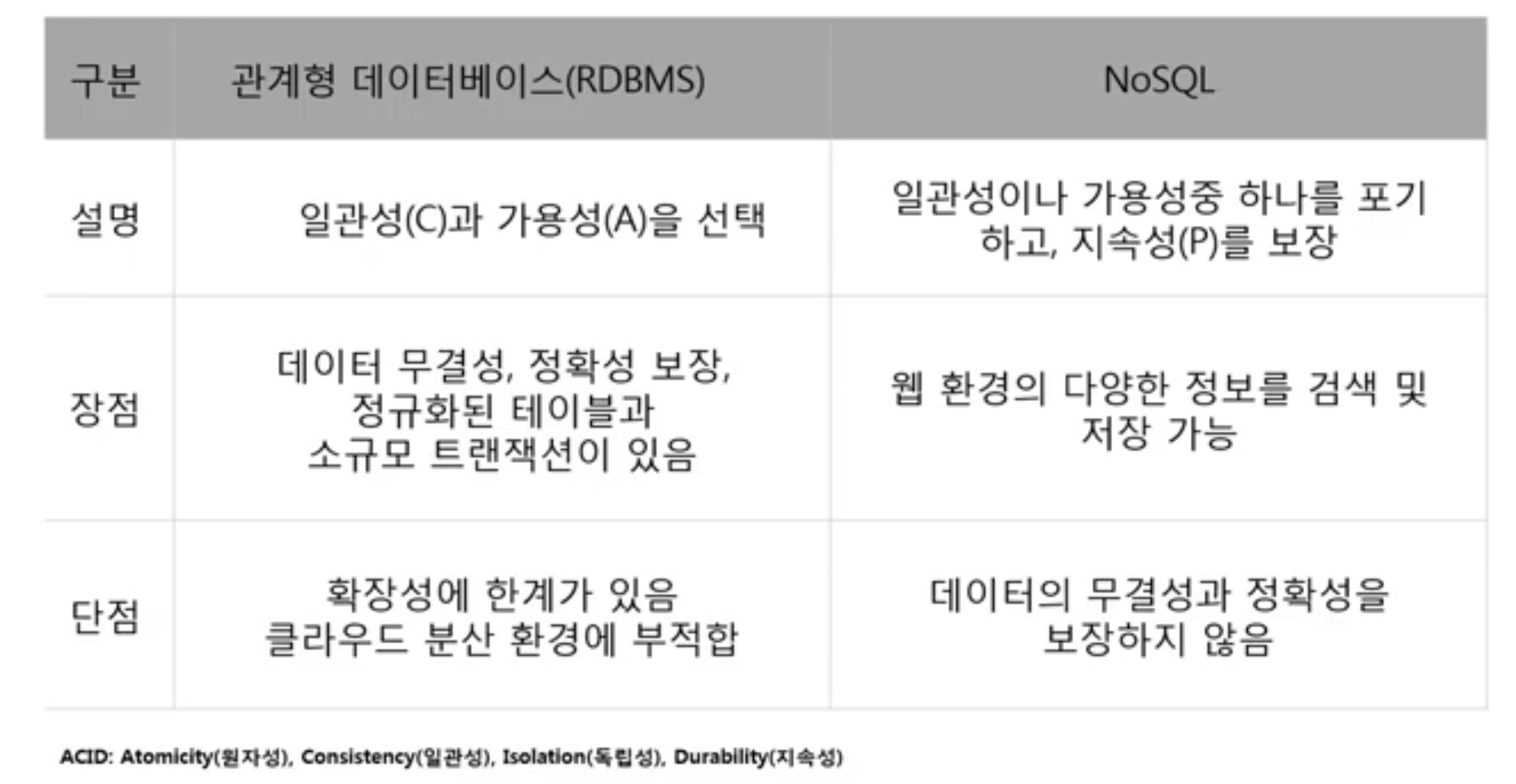
- RDBMS : 대용량 데이터 처리 및 다양한 유형의 데이터 처리를 하는데 어려움이 존재함
- NoSQL : 강력한 확장성
=> 데이터 분산 처리 및 다양한 유형의 데이터 관리가 가능해짐
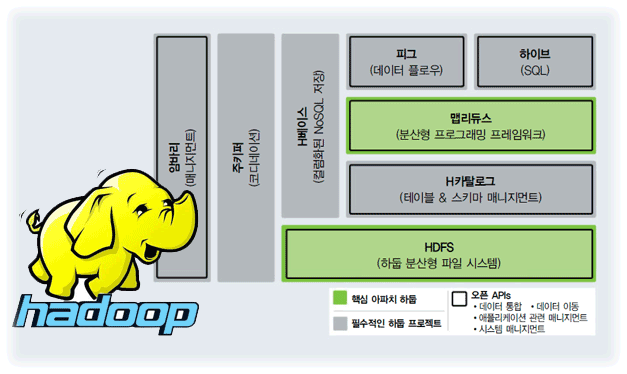
하둡 (Hadoop)

하둡(Hadoop)이란?
= 분산 데이터 처리 프레임워크
: 대용량 데이터의 분산 저장과 처리가 가능한 Java 기반의 오픈소스 프레임워크이자 패키지들의 집합
- 여러 개의 저렴한 컴퓨터들을 마치 하나인 것처럼 묶어 대용량 데이터를 처리하는 기술
- 하둡 파일 시스템(HDFS)
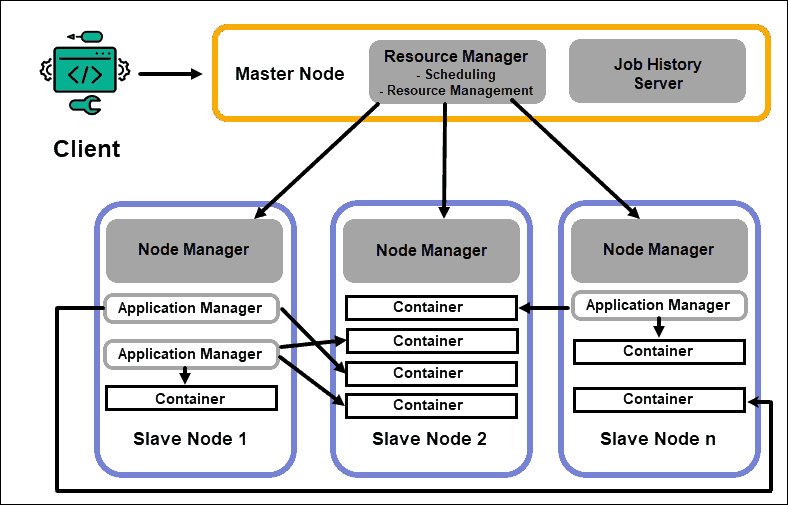 : 데이터 분산 저장
: 데이터 분산 저장
: 수천 대의 분산된 장비에 대용량 파일을 저장할 수 있는 기능을 제공하는 분산 파일 시스템
: 각 블록의 유실, 고장 등의 위험으로부터 신뢰성을 향상하기 위해 복제물을 항상 생성함
- 맵리듀스
: 데이터에 대한 분산 처리(계산) 수행
: 저장된 파일 데이터를 분산된 서버의 CPU와 메모리 자원을 이용해서 쉽고 빠르게 분석할 수 있는 컴퓨팅 프레임워크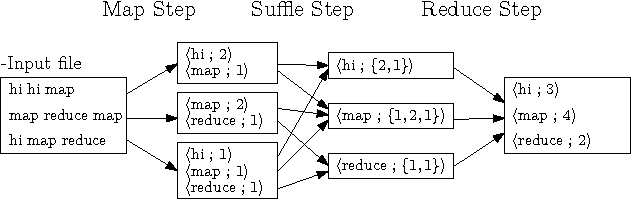
- 맵 (Map) : 입력 파일을 한 줄씩 읽어 필터링하거나 다른 값으로 변환하는 데이터 변형 작업 수행
- 리듀스 (Reduce) : 맵 함수를 통해 출력된 결과 값을 새로운 키 기준으로 중복 데이터 제거한 후, 그룹화 한 후 집계 연산을 수행한 결과를 추출
하둡의 주요 특징
- 대용량 데이터 처리에 최적화
ex) 분산 컴퓨팅, 클라우드 환경+) 클라우드 컴퓨팅
: 소프트웨어와 데이터를 인터넷과 연결된 중앙 컴퓨터에 저장
=> 인터넷에 접속하기만 하면 언제 어디서든 데이터를 이용할 수 있음
: 서로 다른 물리적인 위치에 존재하는 컴퓨팅 자원을 가상화 기술로 통합해 제공하는 기술
-
장애의 대비
: 데이터의 복제본을 저장함
=> 데이터의 유실이나 장애가 발생했을 때에도 복구가 용이함 -
저렴한 구축 비용
