[CS231N] Lecture 2 Image Classification pipeline

1. 이미지 인식의 어려움
이미지 분류는 컴퓨터 비전의 핵심 작업이라 할 수 있다. 컴퓨터는 입력된 이미지를 보고 이미 분류된 범주 레이블 중 하나를 지정해줌으로써 이미지를 분류한다.
이 과정에서 여러 문제들이 발생할 수 있다.
- semantic gap : 컴퓨터는 사진을 거대한 숫자 그리드로만 인식할 수 있기 때문에 인간이 생각하는 고양이에 대한 아이디어와 컴퓨터가 받아들이는 정보 사이에 발생하는 차이
- Viewpoint variation : 관점의 변화에 따라 같은 대상이어도 모든 픽셀이 달라질 수 있음
- Illumination : 다양한 조명에 따른 픽셀 변화
- Deformation : 자세에 따른 픽셀 변화
- Occlusion : 대상의 일부만 보이는 이미지에서 발생하는 문제
- Background Clutter : 대상과 배경이 유사한 경우 발생하는 문제
- Intraclass variation : 여러 대상의 모든 다양한 변형을 처리하기 어려움

그동안 했던 시도 중 이미지의 가장자리를 계산한 다음, 모든 다른 모서리와 경계를 분류하는 방법이 있는데, 이는 가장자리가 시각적 인식과 관련하여 매우 중요하다는 Hubel&Wisel의 주장을 참고한 것이다.
이 방법은 확장 가능한 접근방식이 아니라는 문제점을 가지고 있다.
위의 문제점을 보완하여 세상의 모든 다양한 물체에 훨씬 더 자연스럽게 확장되는 알고리즘이나 방법을 제시하고자 2가지 분류 방법을 설명했다.
2-1. Nearest Neighbor Classifier

이미지 학습 -> 테스트 -> 테스트 이미지 중에 가장 근접한 라벨 예측 순서로 진행된다.
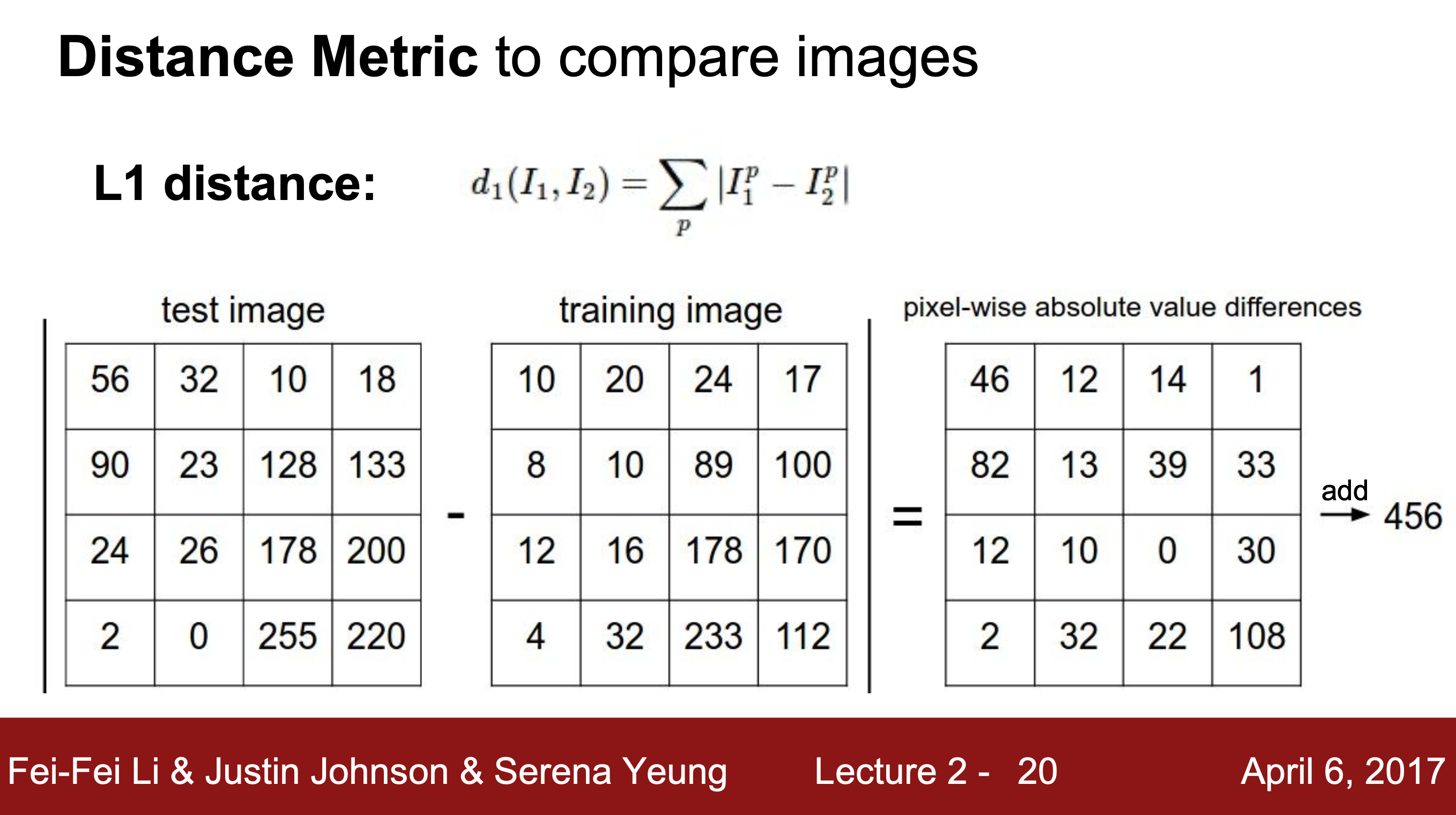
L1 distance : 이미지를 비교하기 위한 아이디어로, 이미지의 개별 픽셀을 비교한다.
L1 함수를 통해 테스트 이미지와 훈련 예제를 비교하고 훈련 데이터에서 가장 유사한 예제를 찾는다.
- 수행시간
- 훈련 : 데이터를 기억하기만 하면 되므르 O(1)
- 예측 : 테스트 이미지를 n만큼의 훈련 데이터와 비교해야 하므로 O(n)
2-2. K-Nearest Neighbors
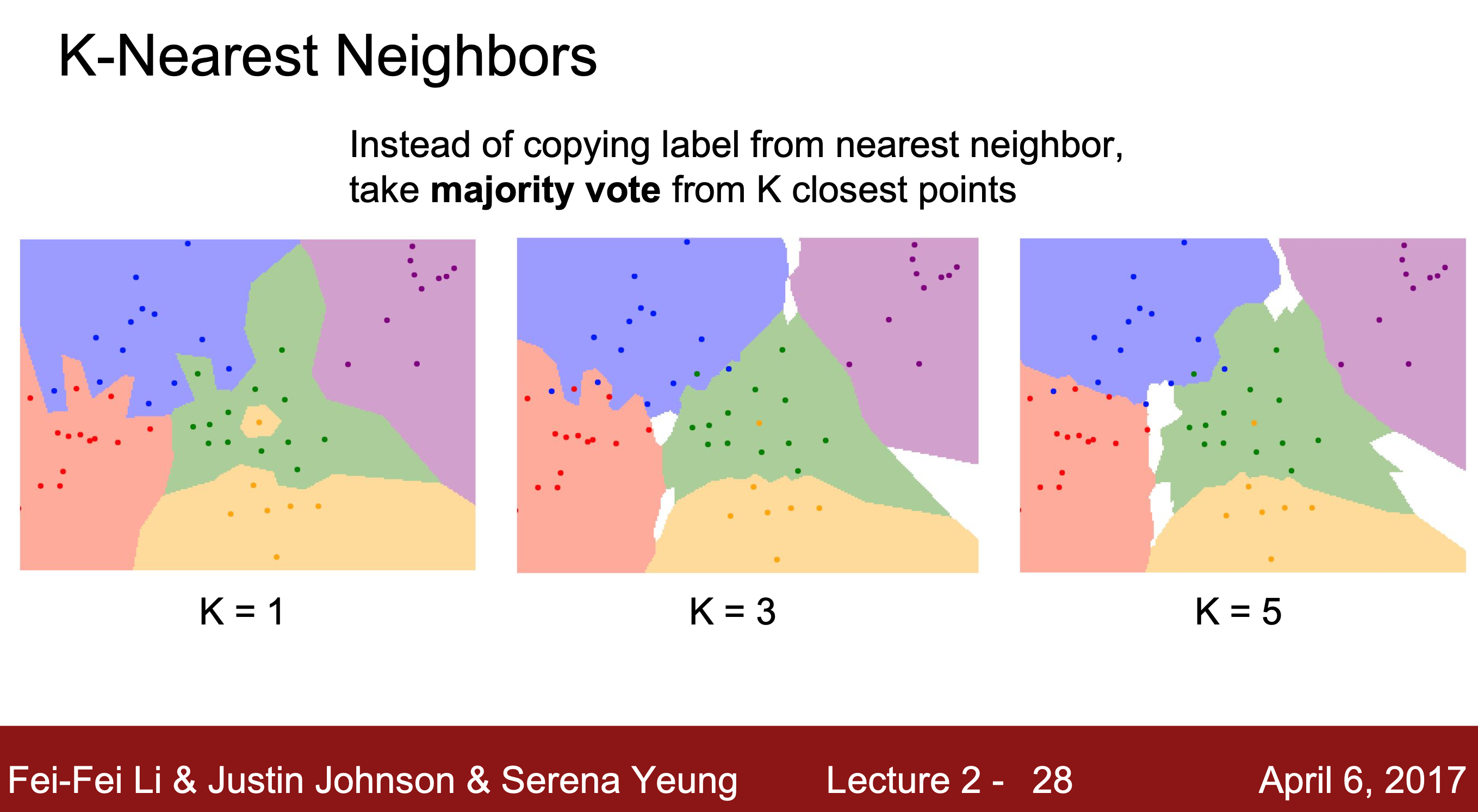
가장 가까운 단일 이웃을 찾는 대신 K만큼 가까이 있는 위치에서 가장 대다수인 것을 라벨로 예측한다.

이미지 상 서로 다른 점을 정확히 어떻게 비교할 지 선택해야 한다.
- L1 distance : L1은 선택한 좌표계에 따라 값이 달라져 좌표축을 따르는 경향이 있다. 입력 기능이 있고 벡터의 개별 항목이 작업에 중요한 의미를 가지는 경우 사용할 수 있다.
- L2 distance : 어떤 공간의 일반적인 벡터이고 다른 요소 중 어떤 것이 실제로 무엇을 의미하는지 모르는 경우 사용할 수 있다.
Hyperparameters(초매개변수) K는 학습 과정에서 여러 번 시도를 통해 얻을 수 있는데 설정 방법은 아래와 같다.
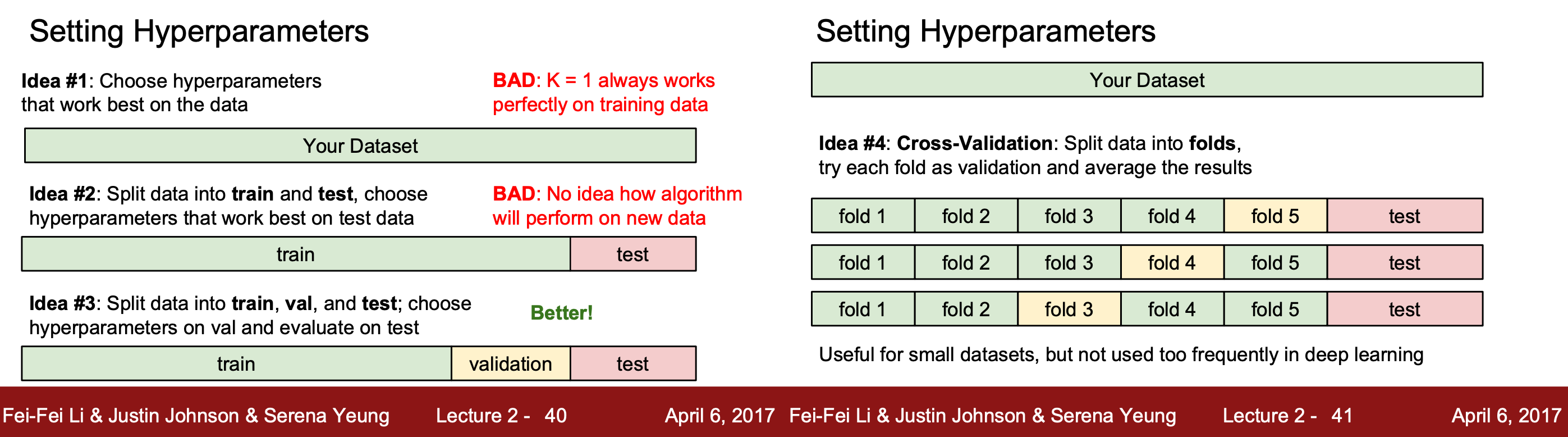
1. 모든 데이터셋을 훈련 데이터로 설정하는 경우
K = 1일때 훈련 데이터는 정확하게 맞힐 수 있으나 예측에는 적합하지 않아 추천하지 않는다.
2. 데이터셋을 훈련 데이터와 예측 데이터로 나누는 경우
테스트 데이터에서만 성능이 좋아 추천하지 않는다.
3. 전체 데이터셋을 훈련/검증/예측 데이터로 나누는 경우
검증 데이터셋에서 적절한 하이퍼파라미터를 설정하고 테스트 데이터셋에서 예측을 실시한다.
4. 교차 검증
데이터가 작을 때 주로 사용한다. 테스트 데이터를 제외한 나머지 데이터들을 폴더로 분할하고 폴더로 나눈 것 중에 하나씩만 hyperparameters로 설정하여 결과를 확인하고 평가하는 과정을 반복한다.
K-Nearest Neighbors는 아래와 같은 이유로 실제 이미지 분류에는 사용되지 않는다.
1. 테스트 시간이 매우 느림
2. 거리 측정법이 실제로 이미지 간의 거리를 측정하는 좋은 방법이 아님
3. 많은 훈련 데이터가 필요함
3. Linear Classification(선형 분류)
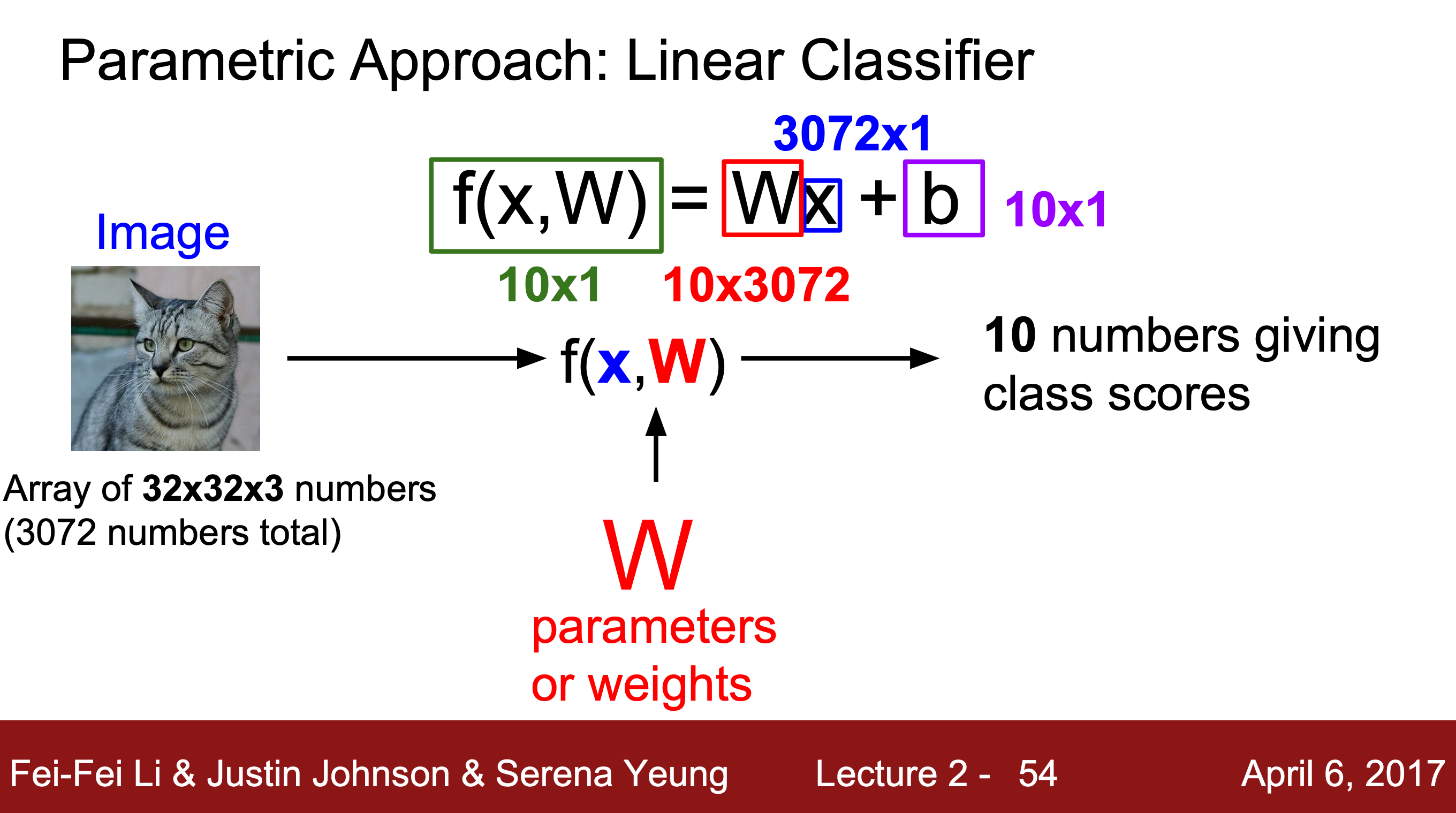
전체 훈련 데이터셋을 유지하는 K-Nearest Neighbors와 달리 매개변수적 접근 방식이다.
훈련 데이터를 요약하고 이 모든 정보를 매개변수 W에 전달해 테스트 시간에 실제 훈련 데이터 대신 매개변수 W를 사용한다. 모델이 더 효율적이고 휴대폰과 같은 작은 장치에서도 실행 가능하다는 장점이 있다. 필요에 따라 편향 요소 b를 추가하기도 한다.
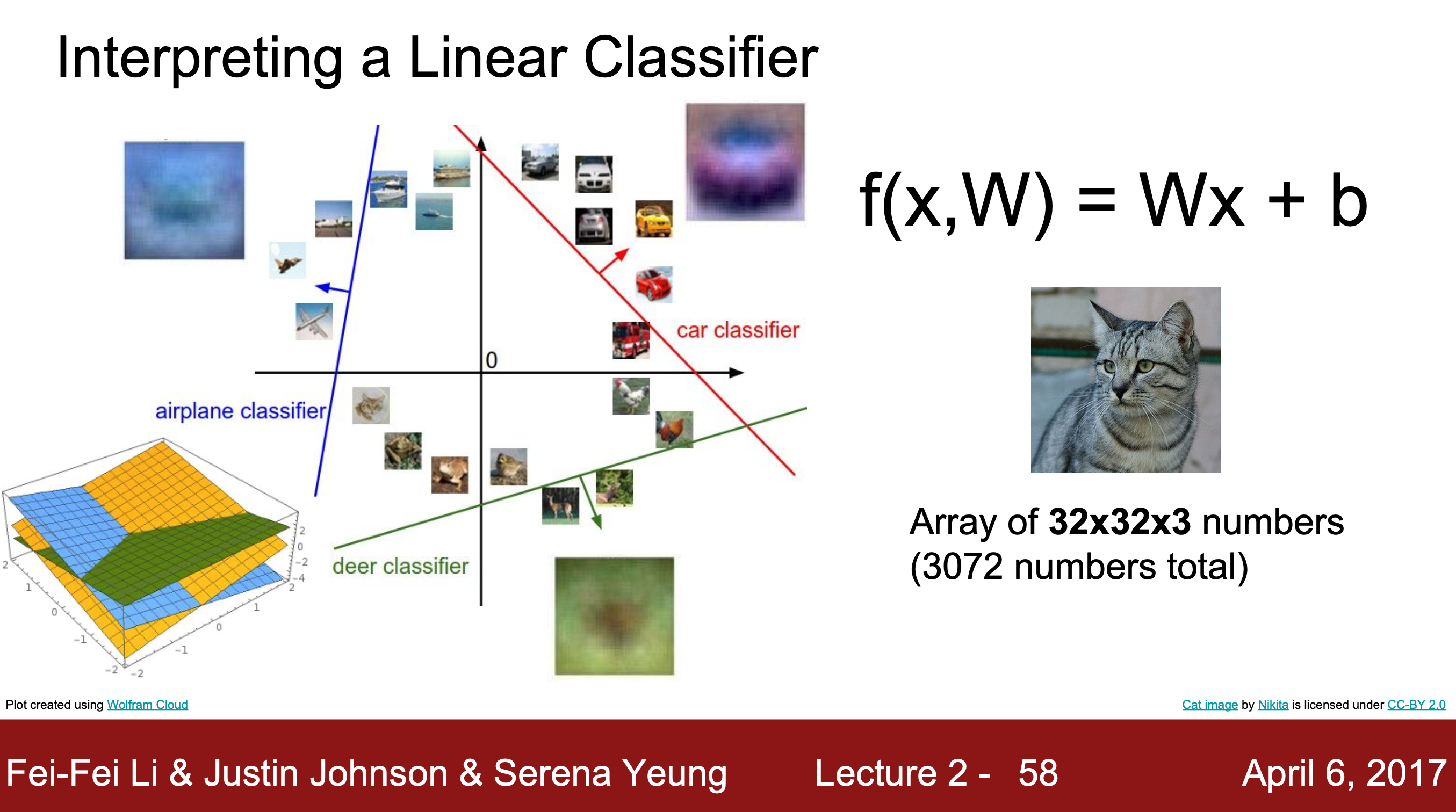
결과적으로 한 범주와 나머지 범주간의 선형 분리를 도출하려고 한다.

위와 같은 경우에는 데이터 범주를 구분하는 "단일 선"을 그을 수 없어 선형 분류가 어렵다.
