[CS231N] Lecture 4 Loss Introduction to Neural Networks

1. Backpropagation
- backpropagation(역전파)
선형 분류 연산의 결과를 역방향으로 다시 지나가면서 가중치를 재업데이트하는 방법으로, 최종 손실값 L을 구하는 Computational graph를 편미분 연산을 통해 역방향으로 계산해가면서 각 부분에 해당하는 경사값을 구한다.
최종 손실값을 구하는 과정을 computational graph로 나타내면 다음과 같다.
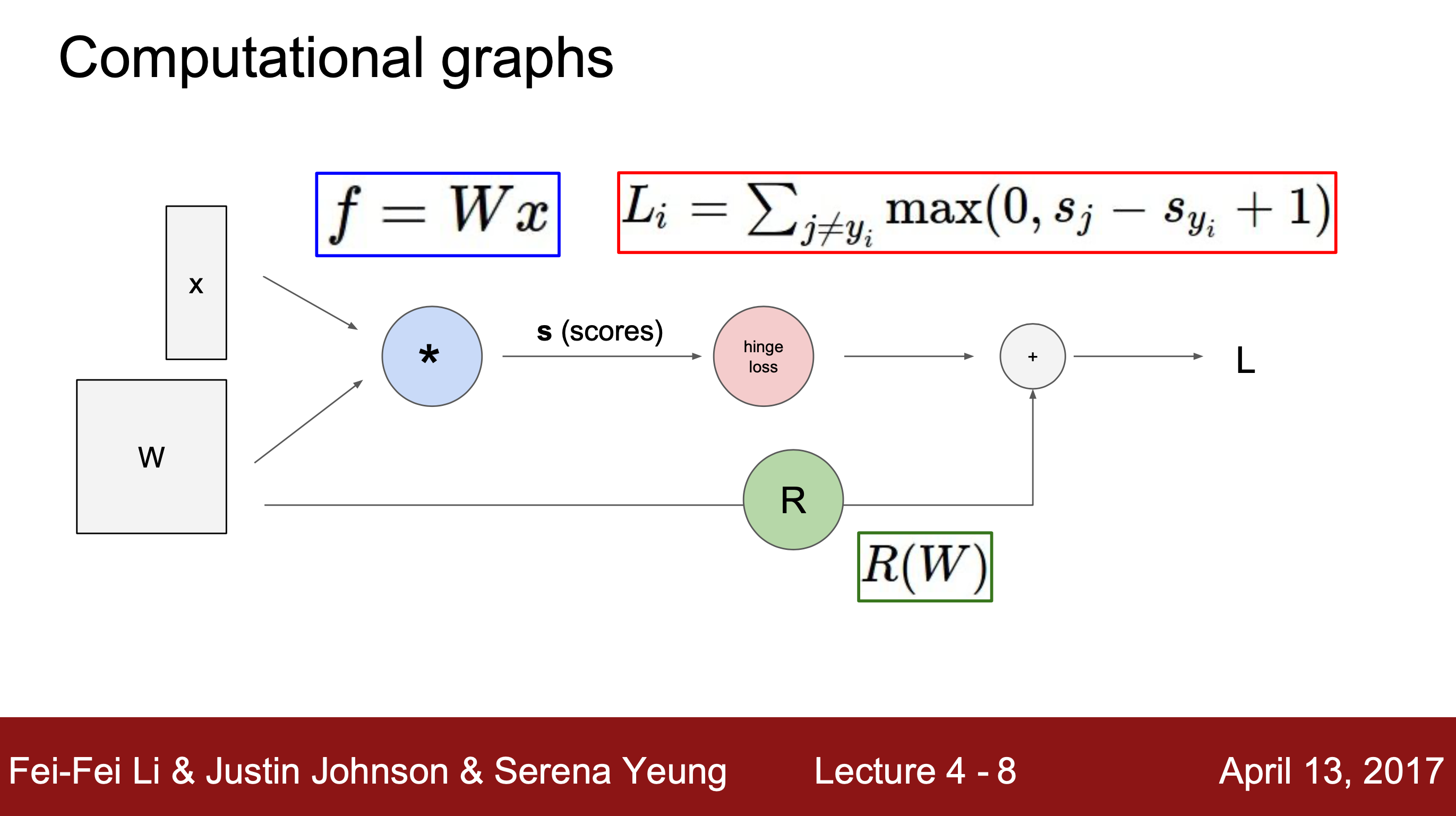 f는 입력값과 가중치 간의 행렬곱을 통해 얻을 수 있는 class 점수 함수이고, L은 각 클래스마다의 손실값으로 지난 시간에 배운 SVM 손실 함수를 통해 값을 얻을 수 있다. 마지막으로 추가항 R(W)를 더해줘 정규화(regulation)을 해준다.
f는 입력값과 가중치 간의 행렬곱을 통해 얻을 수 있는 class 점수 함수이고, L은 각 클래스마다의 손실값으로 지난 시간에 배운 SVM 손실 함수를 통해 값을 얻을 수 있다. 마지막으로 추가항 R(W)를 더해줘 정규화(regulation)을 해준다.
- backpropagation 과정
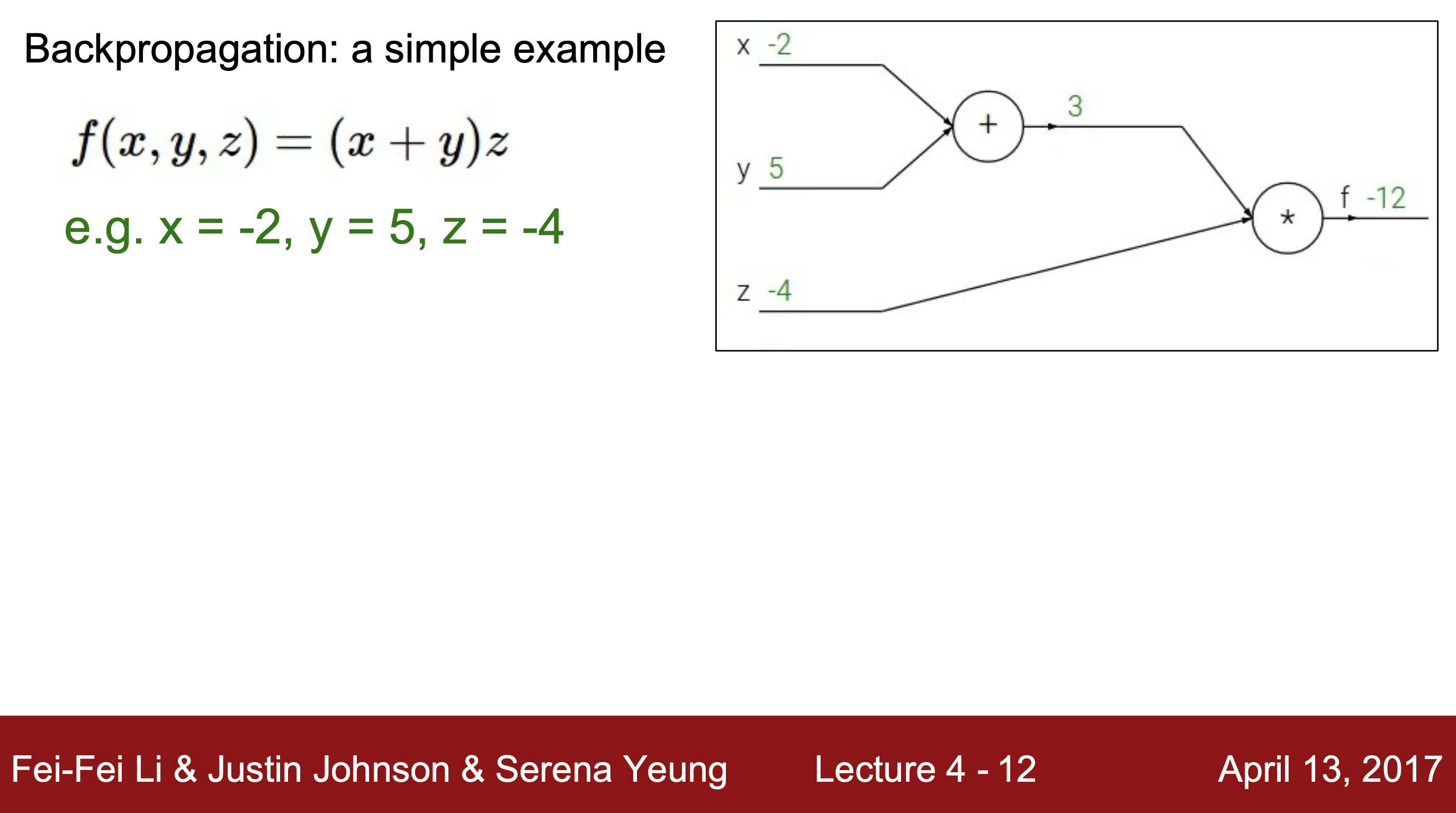 1. 주어진 함수식을 computational graph로 나타내준다.
1. 주어진 함수식을 computational graph로 나타내준다.
 2. 입력값과 함수식을 이용해 순방향으로 계산해준다. 이때 계산 노드에도 이름을 부여해줘서 중간값을 저장해준다.
2. 입력값과 함수식을 이용해 순방향으로 계산해준다. 이때 계산 노드에도 이름을 부여해줘서 중간값을 저장해준다.
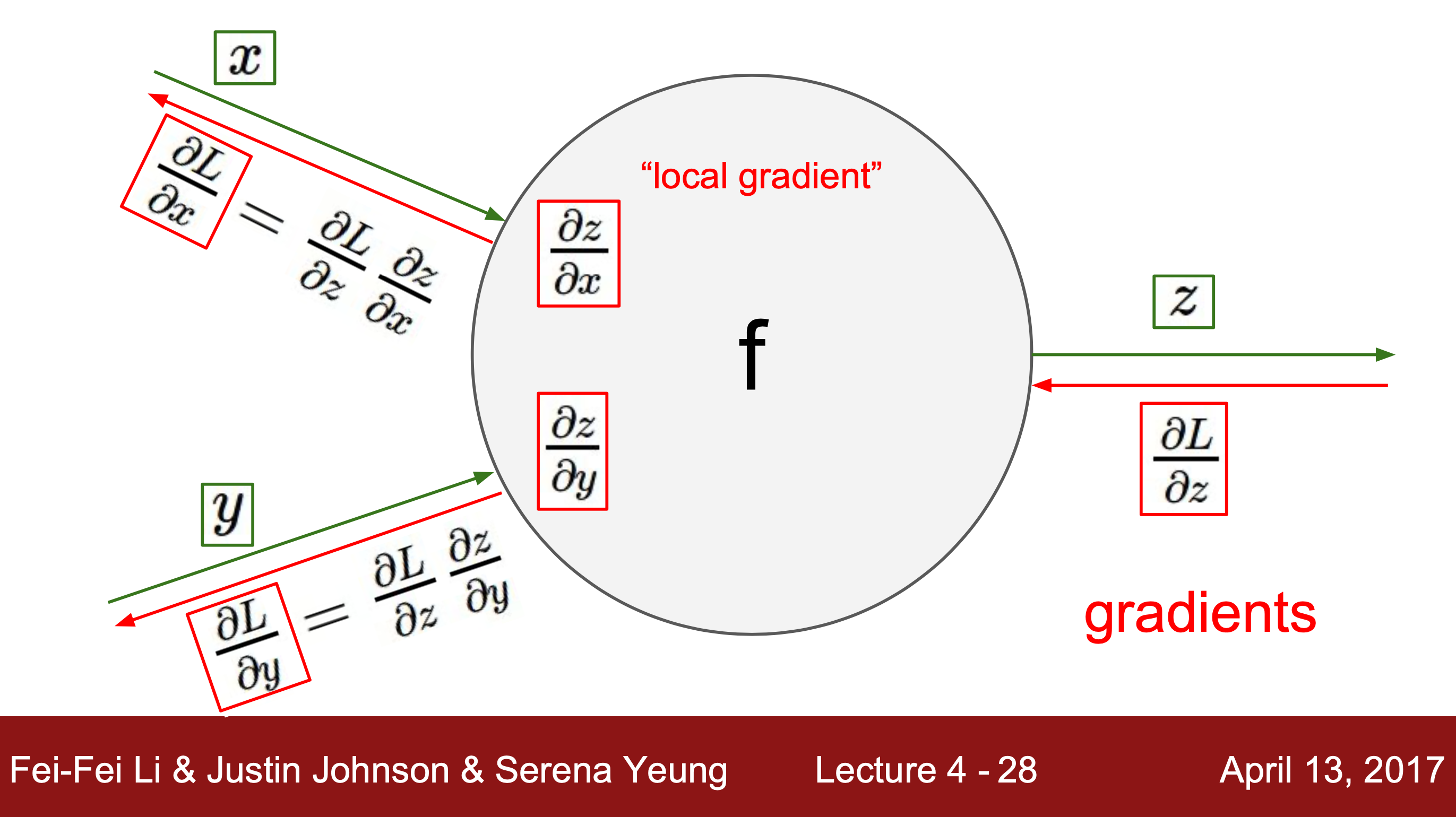 이때 중간값은 나중에 chain rule에서 경유값인 local grdient와 상위값인 global gradient를 구할 때 사용된다.
이때 중간값은 나중에 chain rule에서 경유값인 local grdient와 상위값인 global gradient를 구할 때 사용된다.
 3. 결과값과 결과값 사이의 편미분을 계산해준다. 결과는 항상 1이 된다.
3. 결과값과 결과값 사이의 편미분을 계산해준다. 결과는 항상 1이 된다.

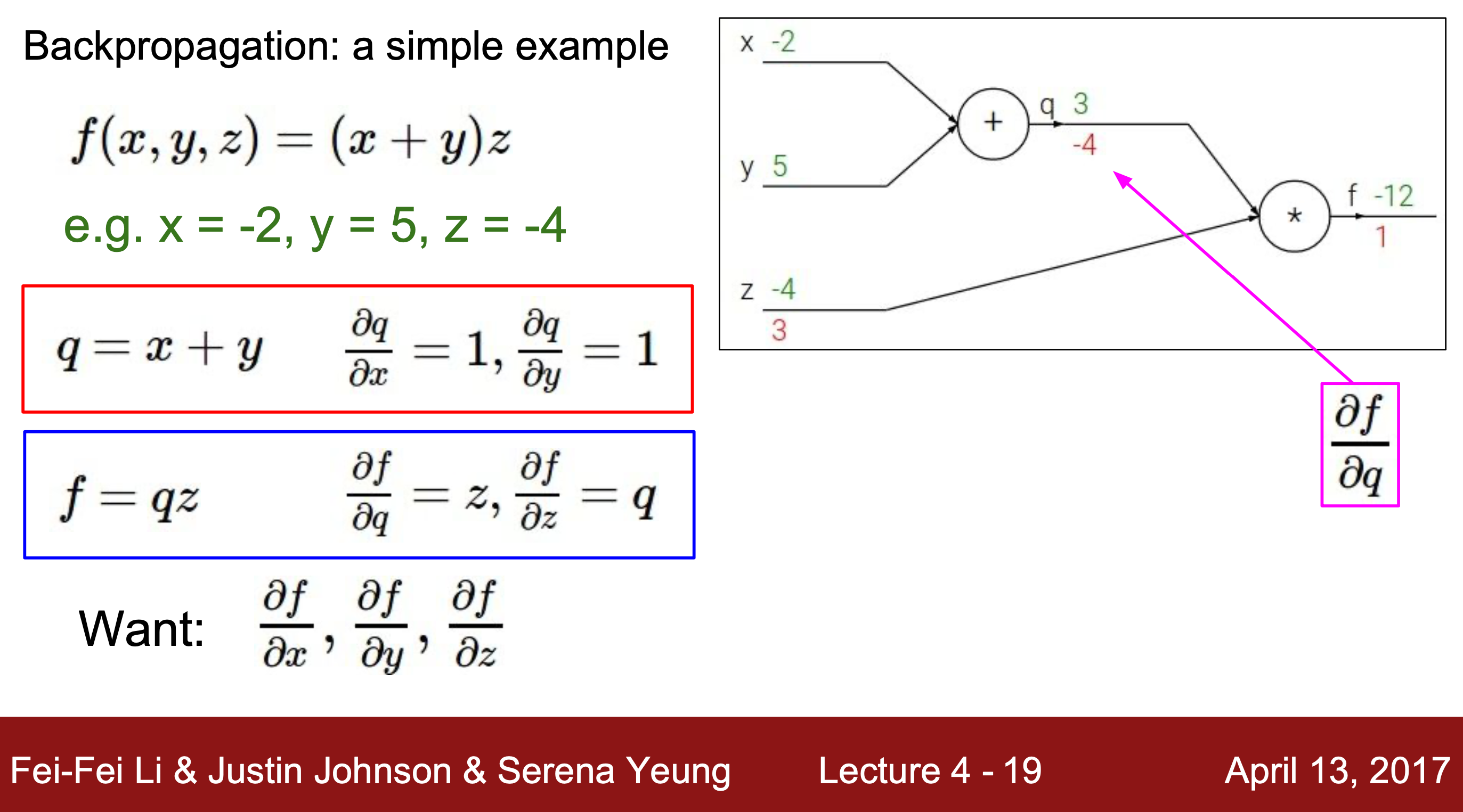
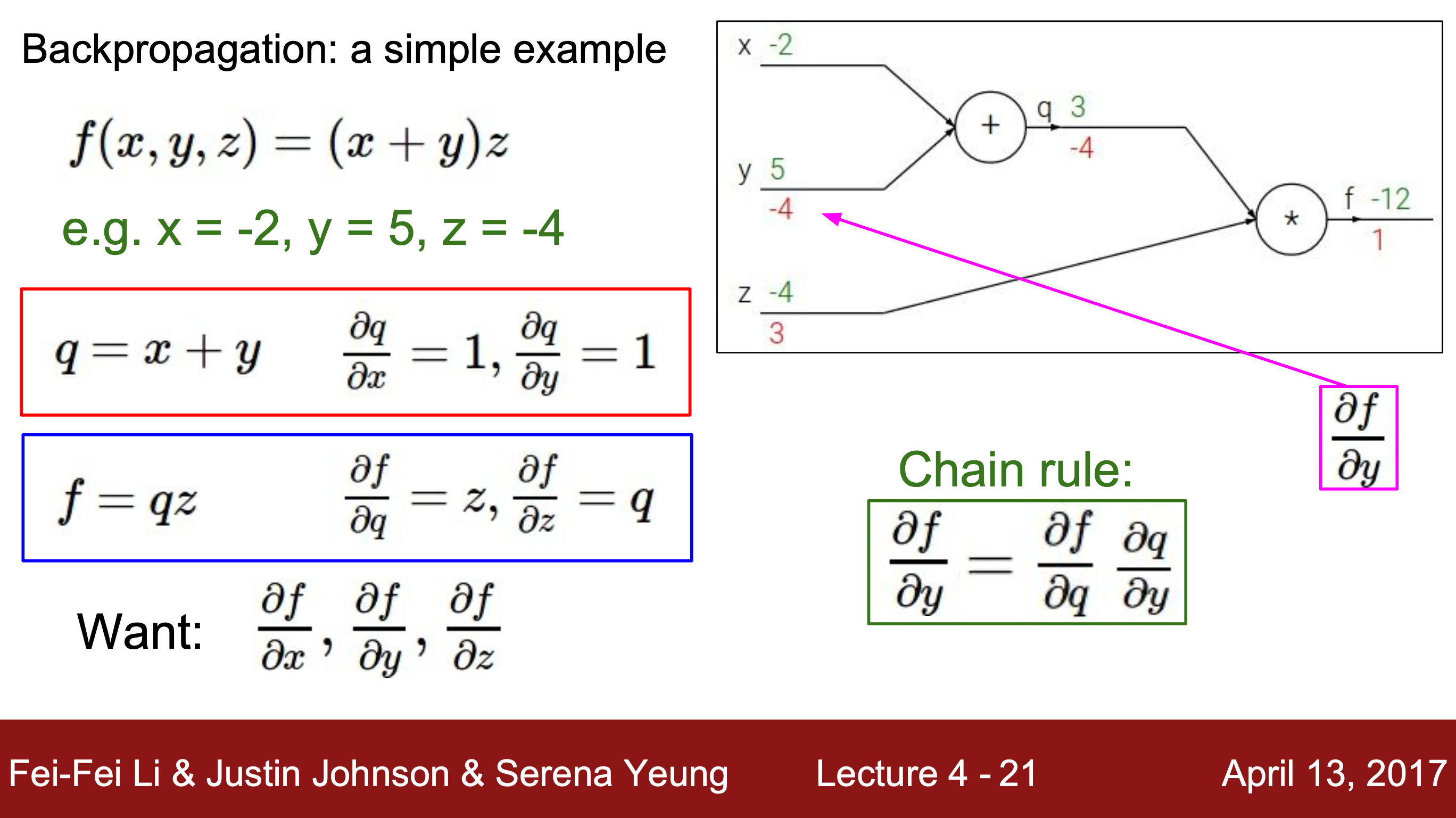
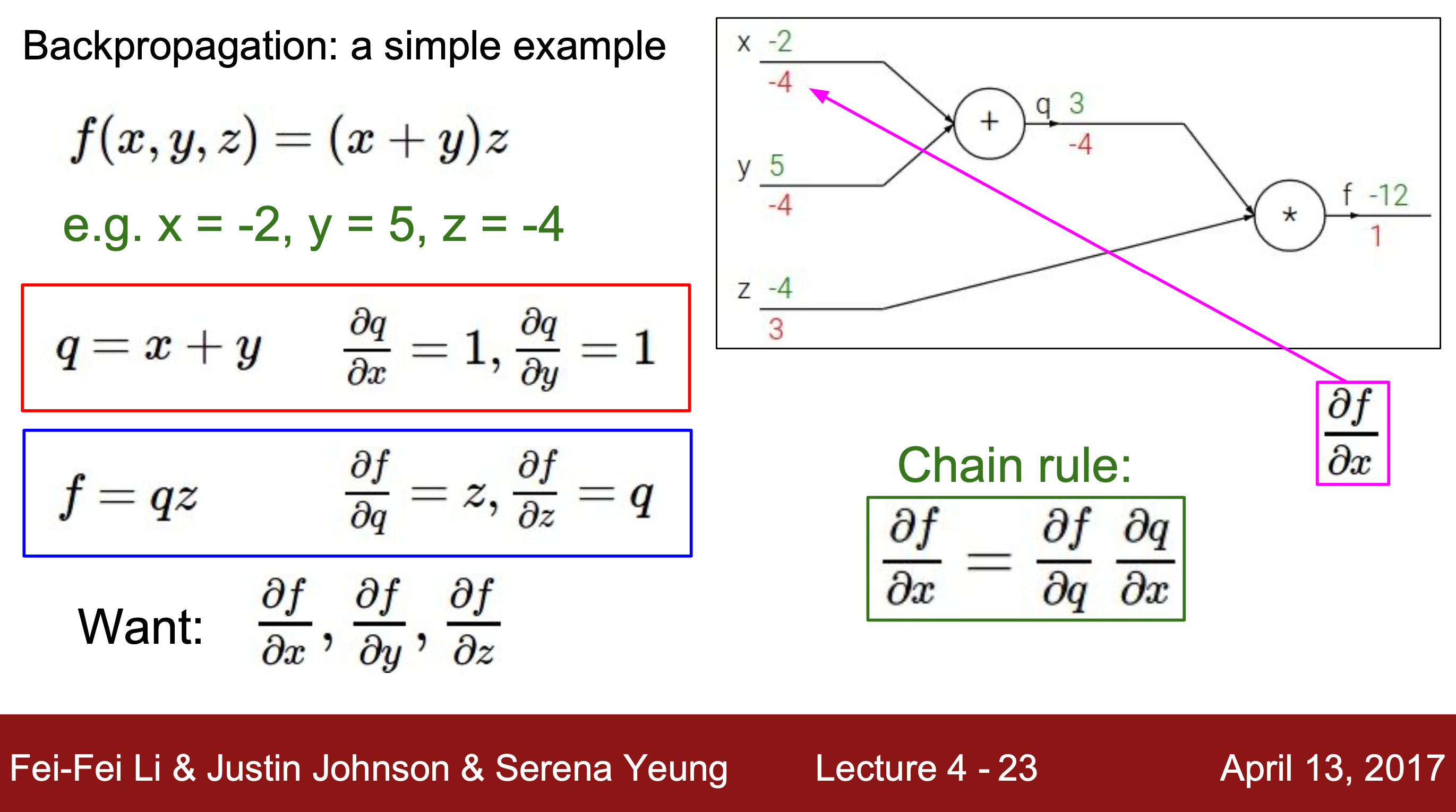 4. 역방향으로 결과값 f와 입력값 사이의 편미분을 진행해준다.
4. 역방향으로 결과값 f와 입력값 사이의 편미분을 진행해준다.
4-1. 바로 편미분이 안되는 경우, Chain rule(연쇄 법칙) 사용해 계산해줄 수 있다.
Chain rule : 3개 이상의 변수를 가지는 경우 편미분식을 분리하여 계산해주는 방법
5. 위의 방법으로 ∂f/∂x, ∂f/∂y, ∂f/∂z를 모두 구할 수 있다.
=> 5의 값을 모두 더해주면 함수 f의 gradient를 알 수 있다.
추가적으로, 또다른 예제에서는 가장 작은 단위의 계산 노드로 분해하지 않고, sigmoid 함수로 설정해 역전파해주는 것을 볼 수 있다.
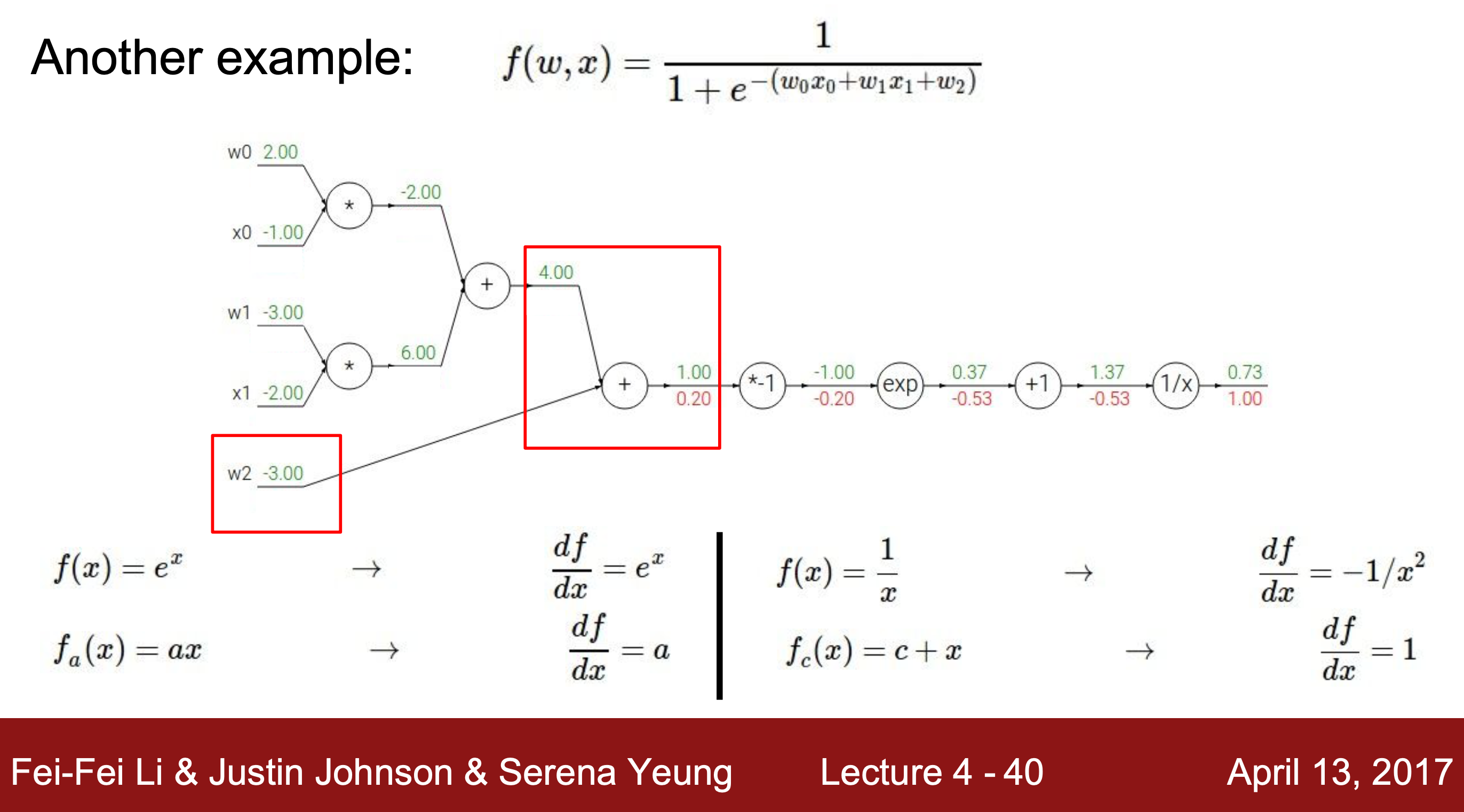
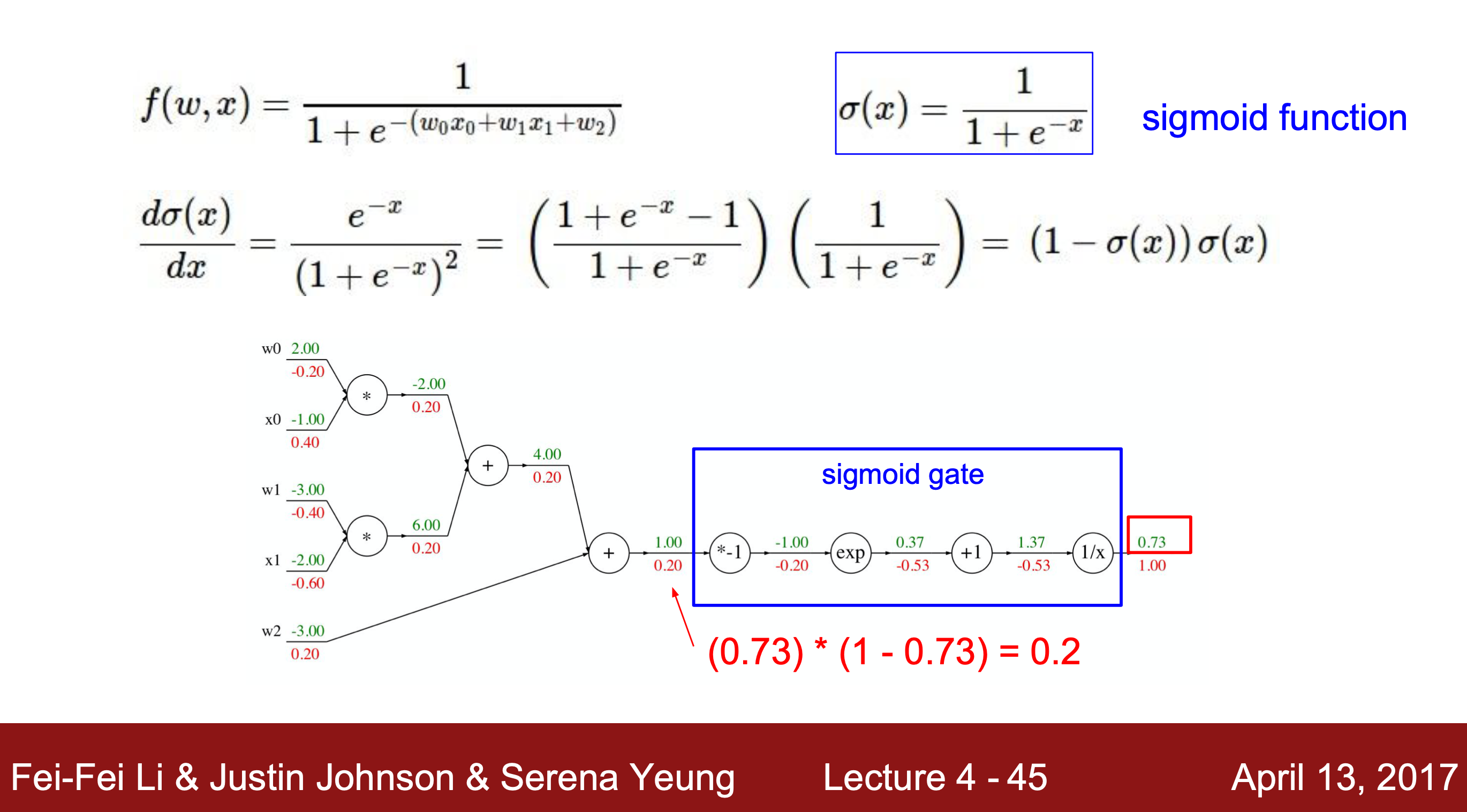
- backpropagation의 패턴
역전파를 할 때, 계산 기호에 따라 특정한 역할을 해주는 패턴이 있다.
 1. add(+) gate : gradient distributor로, global gradient를 하위 단계로 경사값을 똑같이 분배해준다.
1. add(+) gate : gradient distributor로, global gradient를 하위 단계로 경사값을 똑같이 분배해준다.
2. max gate : gradient router로, global gradient의 값을 하위 단계에서 더 큰 연산값을 가졌던 쪽에 전달하고 나머지에는 0을 전달한다.
3. mul(*) gate : gradient switcher로, global gradient와 local gradient의 연산값을 교차해 하위 단계로 전달한다.
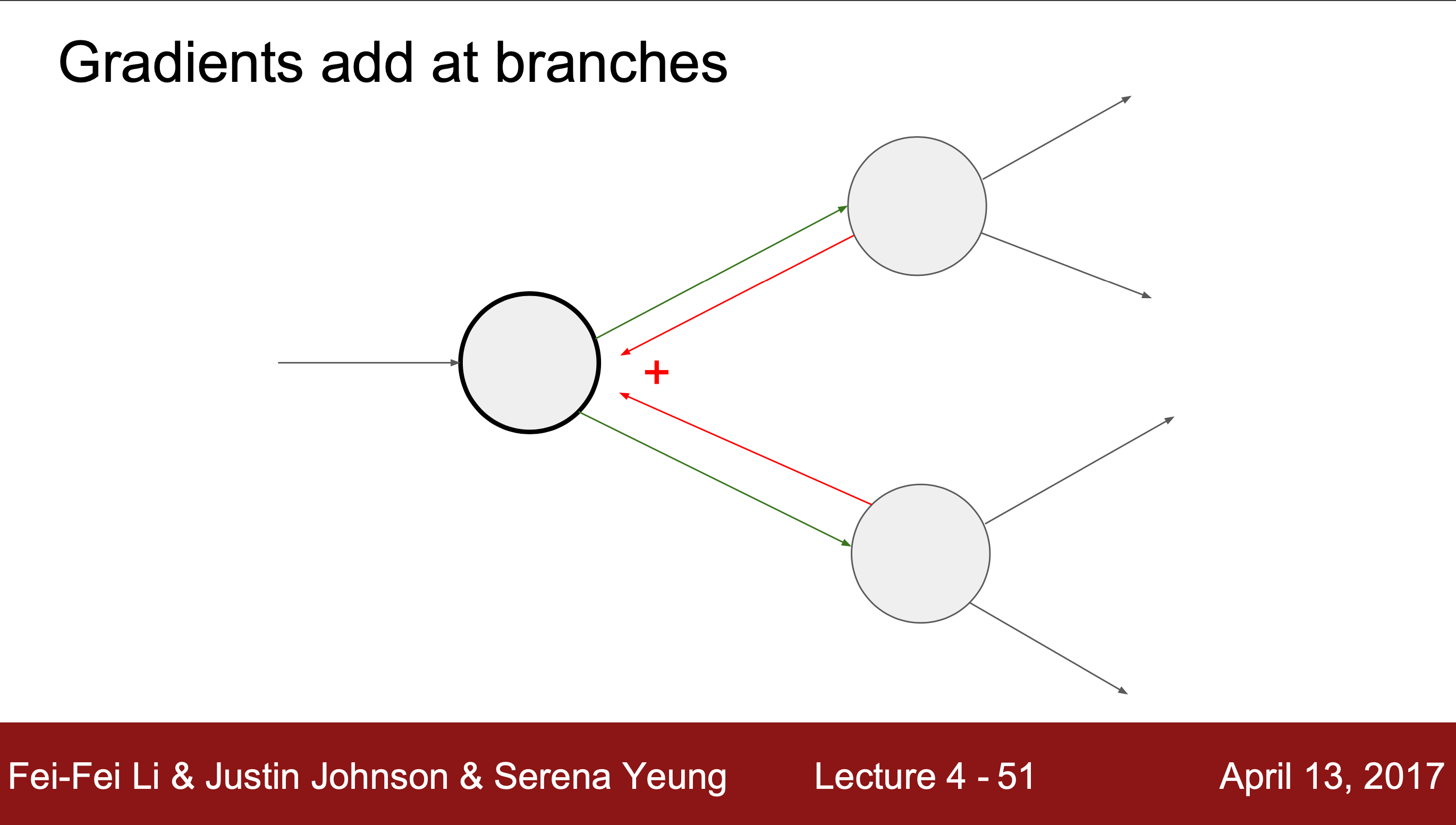 만약 전달 받은 gradient가 여러 개라면, 모든 gradient를 더해서 사용하면 된다.
만약 전달 받은 gradient가 여러 개라면, 모든 gradient를 더해서 사용하면 된다.
- 벡터화된 코드에서의 경사값
-> jacoibian 행렬을 이용해 계산한다.
Jacobian 행렬 : 각 요소의 미분을 포함한 행렬로, (입력의 크기(x minibatch의 크기) x 출력의 크기(x minibatch의 크기))가 이 행렬의 크기가 된다.
이 행렬은 elementwise이므로 요소별로 보기 때문에 입력의 각 요소(첫번째 차원)은 오직 출력의 해당 요소에만 영향을 주어 대각 행렬과 유사한 형태로 나타날 것이가. 행렬의 크기가 너무 커지기 때문에 실제로는 계산할 필요가 없다.
예시를 통해 살펴보면, 1. computational graph로 나타내주고 입력값을 통해 함수식을 계산해준다.
1. computational graph로 나타내주고 입력값을 통해 함수식을 계산해준다.
 2. ∂f/∂q는 ∂f/∂q_i들의 합, 즉 2q가 된다.
2. ∂f/∂q는 ∂f/∂q_i들의 합, 즉 2q가 된다.
 3. chain rule을 이용해 똑같이 계산해준다.
3. chain rule을 이용해 똑같이 계산해준다.
2. Neural Networks

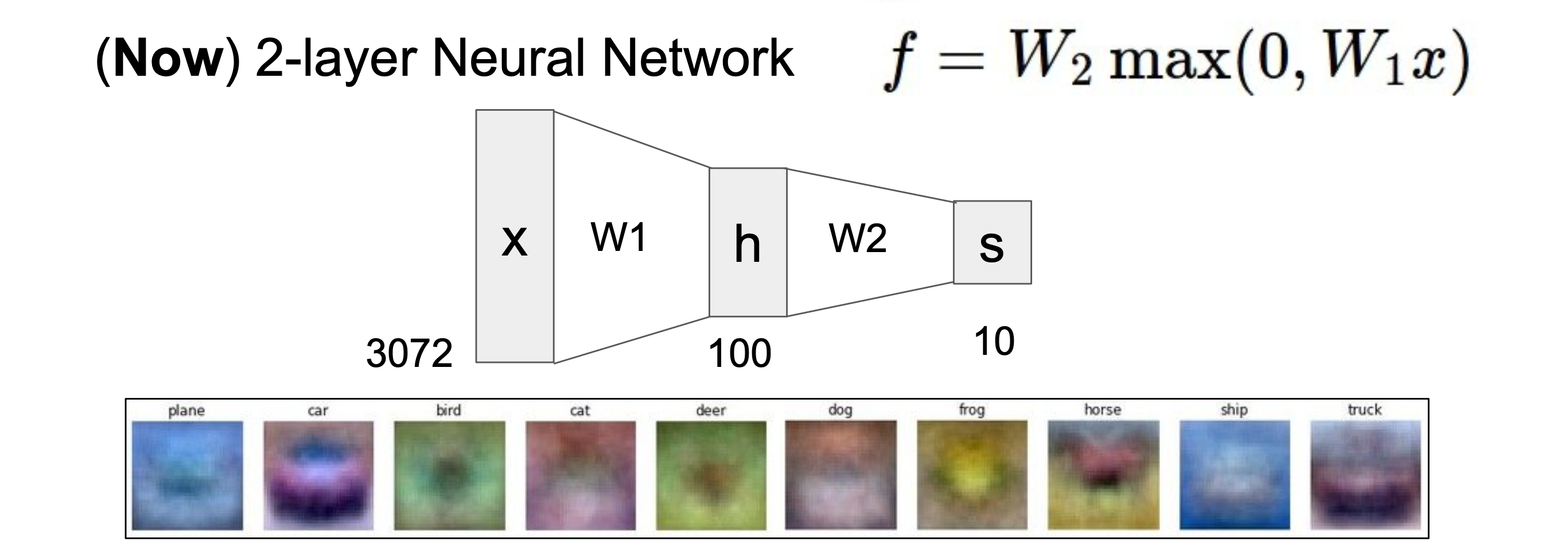
- 지금까지의 Linear Classification은 하나의 score function으로 이루어져 있었던 반면에, neural network는 여러 개의 score function들의 연속적으로 있어 여러 layer들의 결합으로 이루어져 있다.
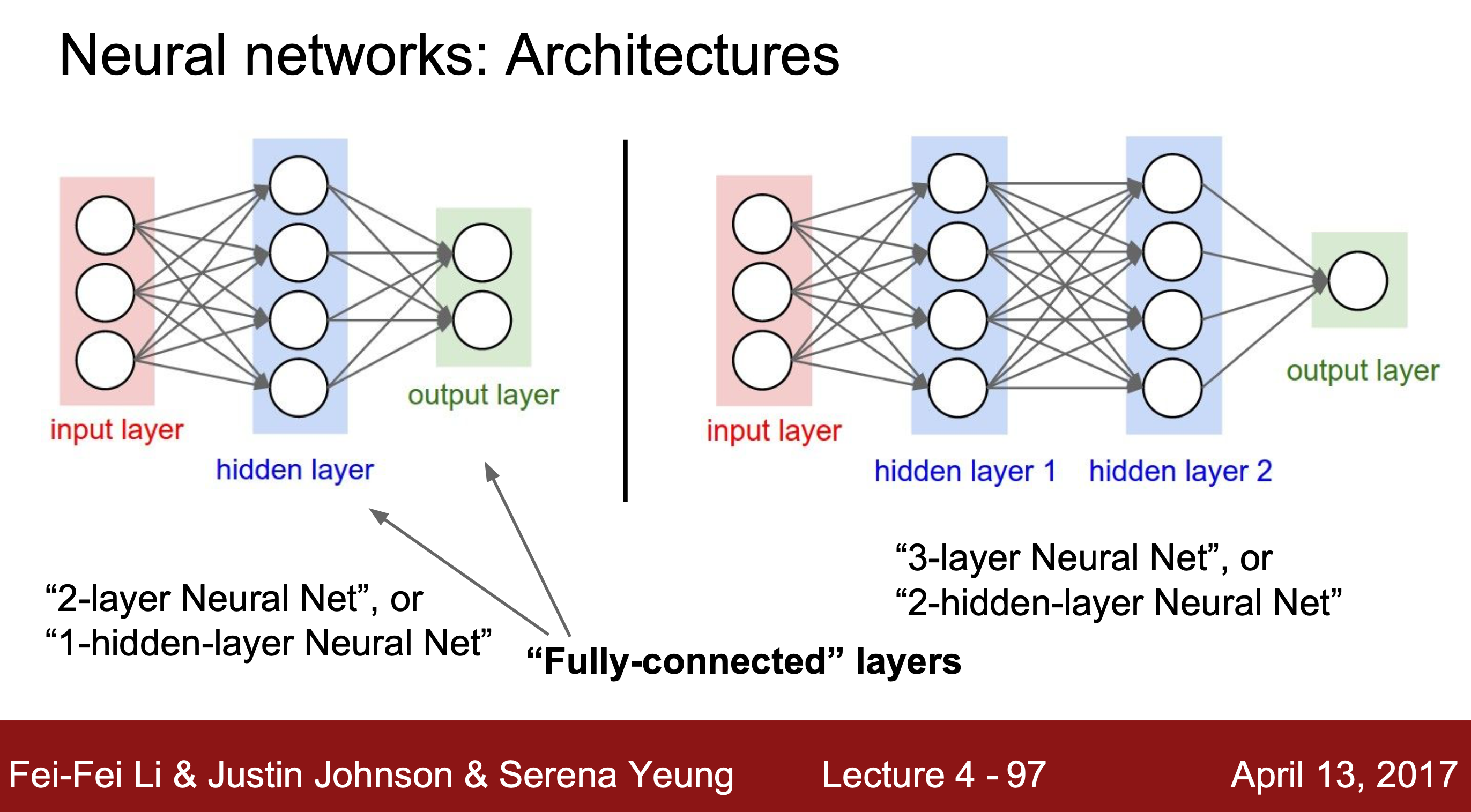
실제 뉴런과 비슷한 구조로, h를 hidden layer(은닉층)이라 한다. '은닉층의 개수 = 서로 다른 분류기의 개수'라 볼 수 있다.
ex) 2 layer 신경망 = 1 hidden layer 신경망, 3 layer 신경망 = 2 hidden layer 신경망
 신경망은 activation function을 이용해 활성인지 비활성인지를 표현한다는 점에서 자극의 특정 임계치를 넘으면 다음 뉴런으로 신호를 전달하는 특성을 가진 실제 생물학적 뉴런과 유사하지만, 완전히 같다고 볼 수 없다.
신경망은 activation function을 이용해 활성인지 비활성인지를 표현한다는 점에서 자극의 특정 임계치를 넘으면 다음 뉴런으로 신호를 전달하는 특성을 가진 실제 생물학적 뉴런과 유사하지만, 완전히 같다고 볼 수 없다.
