
크롤링(Crawling)이란?
분석하기 쉽고 활용하기 쉽도록 웹 페이지에서 데이터를 수집하는 행위.
여러 가지 방법이 있지만 수업에서는 BeautifulSoup과 Selenium을 활용하여 간단한 크롤링 연습을 해보았다.
urllib
- url을 입력하여 작동하는 라이브러리로, 통신을 통해 데이터를 주고 받는 기능을 한다.
- 데이터를 받아오거나 다운로드할 수 있다.
추가적으로, urlerror를 통해 더욱 상세하게 웹과 관련된 에러 처리를 하거나
url parser를 통해 어떤 요소들이 url에 들어가 있는지 확인할 수 있다.
- urllib.request로 이미지 다운 받기
- urletrieve
url로 표시된 네트워크 정보를 파일로 저장할 수 있는 기능(html, 이미지)
- urletrieve
import urllib.request as req
url = "웹에서 원하는 이미지의 주소"
path = "저장하고자 하는 경로"
file, header = req.urletrieve(url, path)+) 현재 위치 확인하기
import os
os.getcwd()url = "https://www.naver.com/"
path = "naver.html"
file, header = req.urletrieve(url, path)위와 같은 코드를 실행했을 때 
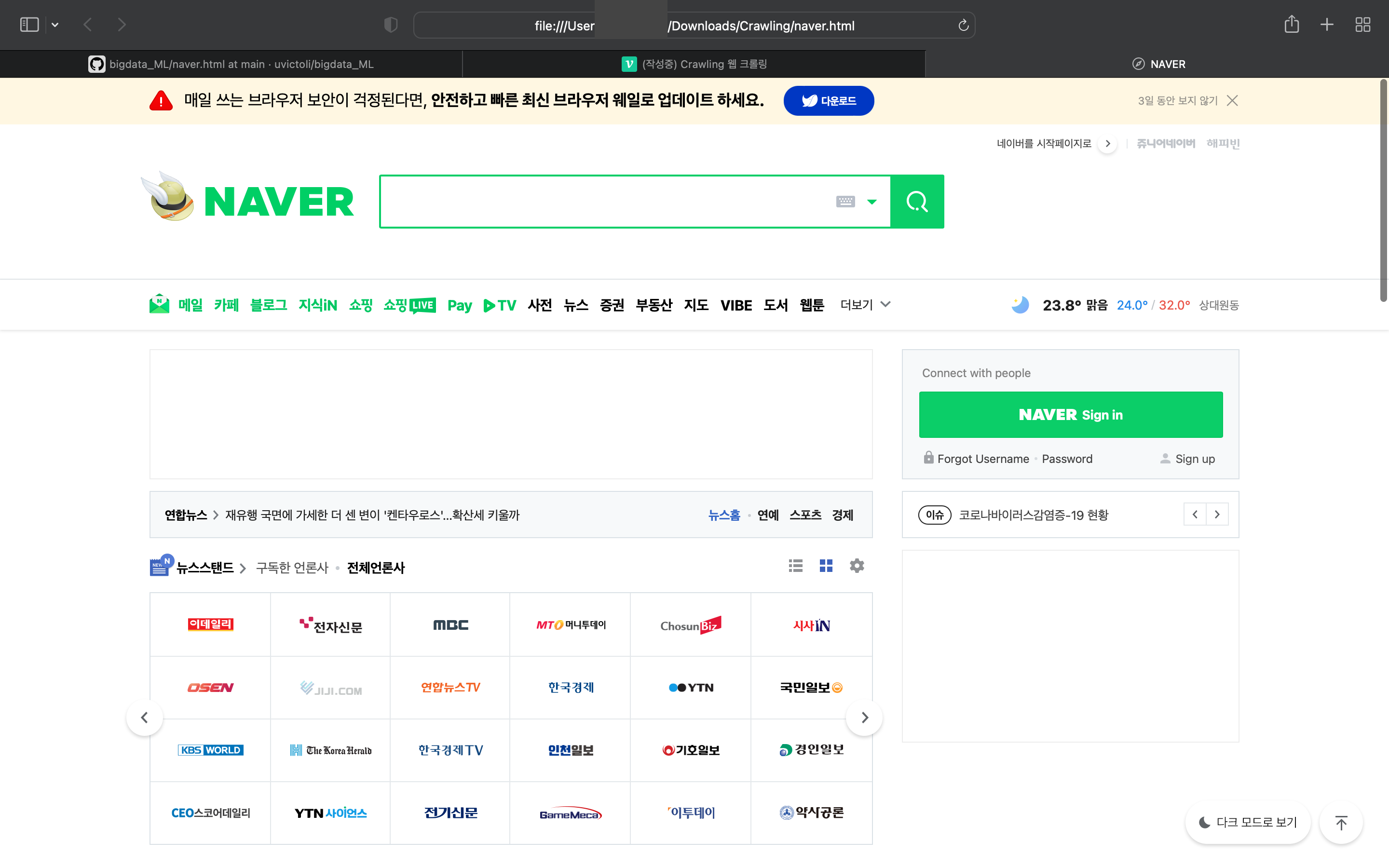
네이버 이미지를 담은 html 파일이 생성된 것을 볼 수 있고, 그 파일을 실행했을 때 일반 웹 페이지와 다르게 클릭과 같은 기능은 안되고 이미지로써 보여지기만 한다는 것을 확인할 수 있다.
print(file)
print(header)결과
naver.html
Server: NWS
Date: Thu, 14 Jul 2022 15:44:21 GMT
Content-Type: text/html; charset=UTF-8
Transfer-Encoding: chunked
Connection: close
Set-Cookie: PM_CK_loc=0ca2b2933029536b80719a694efcd5e696822b610119e9f7fa528837df156f11; Expires=Fri, 15 Jul 2022 15:44:21 GMT; Path=/; HttpOnly
Cache-Control: no-cache, no-store, must-revalidate
Pragma: no-cache
P3P: CP="CAO DSP CURa ADMa TAIa PSAa OUR LAW STP PHY ONL UNI PUR FIN COM NAV INT DEM STA PRE"
X-Frame-Options: DENY
X-XSS-Protection: 1; mode=block
Strict-Transport-Security: max-age=63072000; includeSubdomains
Referrer-Policy: unsafe-urlfile과 header가 정상적으로 출력되는지를 통해 이미지 혹은 html 파일이 제대로 저장되었는지 확인할 수 있다.
- urlerror
에러코드를 통해서 어떤 에러가 발생하였는지 파악하고 코드를 수정하면서 크롤링에서 발생하는 에러를 처리할 수 있다.- URLError : 요청한 것의 서버가 없거나 네트워크 연결이 없는 상황에서 발생
- HTTPError : HTTP 응답에 있는 status에 따라서 상태를 반환한다
주의사항 : URLError가 HTTPError도 잡기 때문에 HTTPError를 먼저 처리해줘야 한다.
- urlopen / urlparse
import urllib.request as rq
from urllib.parse import urlparse
url = "https://www.smu.ac.kr"
ele = rq.urlopen(url)
print(type(ele))
print(ele.geturl())
print(ele.status)
ele.getheaders()결과
<class 'http.client.HTTPResponse'>
https://www.smu.ac.kr/ko/index.do #geturl
200 # 정상 작동
# 헤더 정보
[('Content-Language', 'ko'),
('Date', 'Thu, 14 Jul 2022 16:03:43 GMT'),
('Expires', 'Thu, 01 Jan 1970 00:00:00 GMT'),
('Set-Cookie',
'JSESSIONID=VbISmXHuRMA3lx8SK71ULhQvdzIGY1i1sVVghNN43OEEAJ5877uH8PO1rpI6qZID.d3d3X2RvbWFpbi9jbXM=; Path=/; HttpOnly'),
('Set-Cookie', 'ko_visited=Y; Expires=Fri, 15-Jul-2022 14:59:43 GMT; Path=/'),
('Set-Cookie',
'ko_visited=20220715010343662001; Expires=Fri, 15-Jul-2022 14:59:43 GMT; Path=/'),
('Set-Cookie', 'locale=ko; Path=/'),
('Connection', 'close'),
('Content-Type', 'text/html; charset=UTF-8'),
('Pragma', 'no-cache'),
('Cache-Control', 'no-store'),
('Cache-Control', 'no-cache')]urlparse("https://www.smu.ac.kr/ko/index.do?param=test").query결과
'param=test'Requests & BeautifulSoup
request로 데이터를 요청한 후 BeautifulSoup으로 파싱한다.
- requests : urllib.requests와 같이 데이터를 요청하고 응답값을 받는 역할
- 네트워크 통신을 하기 위해 사용하는 기능
- 브라우저에서 url을 요청하는 기능과 같다고 생각하면 된다.
- requests.get(url, header = , data = , cookies = ) 와 같은 형식
- url 부분에 브라우저에 넣는 url을 입력하면 되고 나머지는 선택적으로 입력하면 된다.
- BeautifulSoup : html을 받아와서 원하는 정보만 고를 수 있도록 해주는 라이브러리
import requests
from bs4 import BeautifulSoup
res = requests.get("https://m.naver.com/")requests.get(url)은 크롬창에서 url을 직접 입력하는 것과 같다고 생각하면 된다.
다시 말해, 브라우저에 url을 넣은 방식과 동일한데
단지 응답값을 Chrome(브라우저)은 웹페이지에서 보여주고 파이썬 코드는 html 코드를 그대로 받았다는 차이가 있다.
res.text 와 같이 naver 화면의 html을 잘 가져온 것을 확인할 수 있다.
와 같이 naver 화면의 html을 잘 가져온 것을 확인할 수 있다.
전체 html에서 BeautifulSoup을 통해 원하는 text만 가져오고자 할 때, BeautifulSoup()의 첫번째 인자로 requests 응답값을 넣고 받은 html 형식이나 html parser를 선택한다.
soup = BeautifulSoup(res.text, "html.parser")
# 가져온 text에서 원하는 태그 'setup_layer lyr_unsubscribe'에 있는 정보를 가져올 때
news = soup.select("setup_layer lyr_unsubscribe")BeautifulSoup 기초
- prettify()
html 구조를 파악하기 쉽게 바꿔준다.
- 원하는 태그에 접근하기
h1 = soup.html.body.h1
h2 = soup.html.body.h2.text
p = soup.html.body.p
p2 = p.next_sibling
print(h1)
print(h2)
print(p)
print(p2)결과
<h1 class="site-headline">
<a href="/"><img alt="python™" class="python-logo" height="62" src="/static/img/python-logo@2x.png" width="218"/></a>
</h1>
Get Started
<p><strong>Notice:</strong> While JavaScript is not essential for this website, your interaction with the content will be limited. Please turn JavaScript on for the full experience. </p>- find() / select_one()
soup.find('태그이름') 또는 soup.select_one('태그이름')
태그 이름에 해당하는 첫번째 요소를 뽑아준다.
li = soup.find("li")
print(li)
soup.select_one("span.prompt > p")
결과
<li class="python-meta current_item selectedcurrent_branch selected">
<a class="current_item selectedcurrent_branch selected" href="/" title="The Python Programming Language">Python</a>
</li>- find_all() / select()
soup.find_all('태그이름') 또는 soup.select('태그이름')
태그이름에 해당하는 모든 태그들을 뽑아준다.
a2 = soup.find_all("a", class_ = "current_item selectedcurrent_branch selected")
print(a2)
결과
[<a class="current_item selectedcurrent_branch selected" href="/" title="The Python Programming Language">Python</a>]soup.select("#site-map")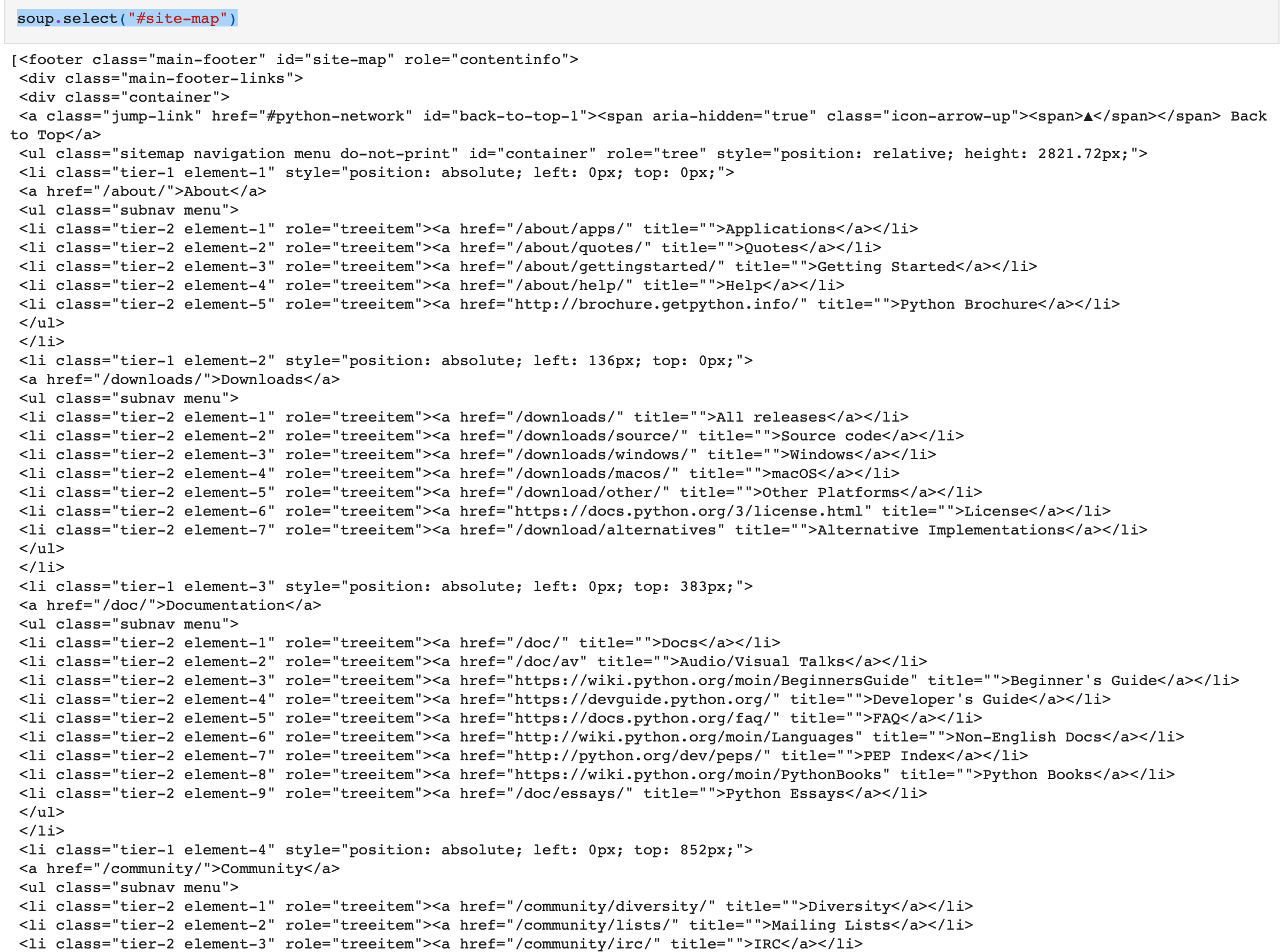
Selenium을 통한 동적 크롤링
Selenium이란 ?
다양한 언어에서 웹 드라이버를 통한 웹 자동화 테스트를 지원하는 라이브러리
requests 라이브러리는 단순하게 request만 날려 그 때 서버에서의 응답값만 가지고 (정적)크롤링한다는 특징이 있는 반면, selenium은 실제 브라우저를 사용한다는 것이 특징이다.
실제 브라우저를 사용하기 때문에 dom의 변화에 대해서도 처리가 가능하여 '동적 크롤링'이라 한다.
!pip install selenium
from selenium import webdriverselenium 외에도 웹 드라이버를 설치해줘야 한다. 크롬 드라이버를 사용하였는데 다운로드할 때 아래 게시글을 참고하였다.
[Mac] Chrome driver 설치, Path 설정, mac 에러 해결
- Chrome(브라우저) 실행
browser = webdriver.Chrome('./chromedriver') #크롬 실행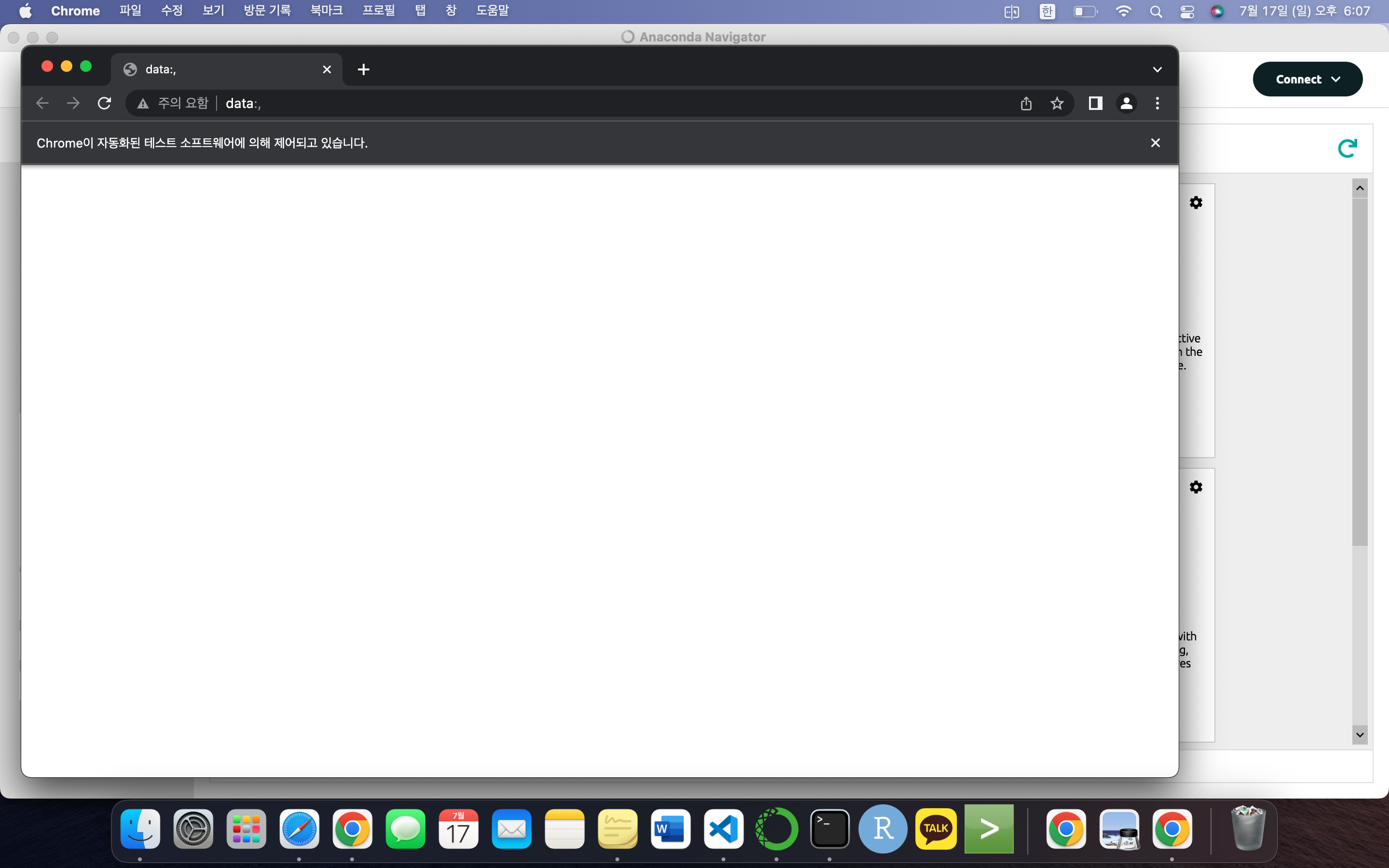 위 코드를 실행하면 아무것도 없는 빈 크롬창이 열리는 것을 볼 수 있다.
위 코드를 실행하면 아무것도 없는 빈 크롬창이 열리는 것을 볼 수 있다.
윈도우 크기 지정이나 시간 지정도 가능하다.
browser.set_window_size(1080, 1080) #window 창 크기 지정
browser.implicitly_wait(3) # 브라우저가 작업을 할 때 페이지에서 정보가 나타날 때까지 기다려줌browser.get("https://www.naver.com") # 네이버로 이동
# res = requests.get("www.naver.com") 코드를 실행하면 크롬창에서 저절로 네이버(입력한 url)로 이동한다.
코드를 실행하면 크롬창에서 저절로 네이버(입력한 url)로 이동한다.
browser.page_source로 해당 페이지의 html 구성도 확인할 수 있다.
browser.title
결과 'NAVER'browser.current_url
결과 'https://www.naver.com/'- find_element()
원하는 태그에 속한 요소를 찾을 수 있다.
CSS_SELECTOR 말고도 XPATH, styles 등 여러 방법으로 요소를 찾을 수 있는데 수업에서는 CSS_SELECTOR만 이용하였다.
CSS_SELECTOR 쉽게 찾기,,
1. 개발자 도구(option + command + i) 켜기
2. css tag 알고 싶은 부분을 우클릭하여 '검사' 클릭
3. html 코드를 우클릭하여 'Copy' > 'Copy selctor' 클릭
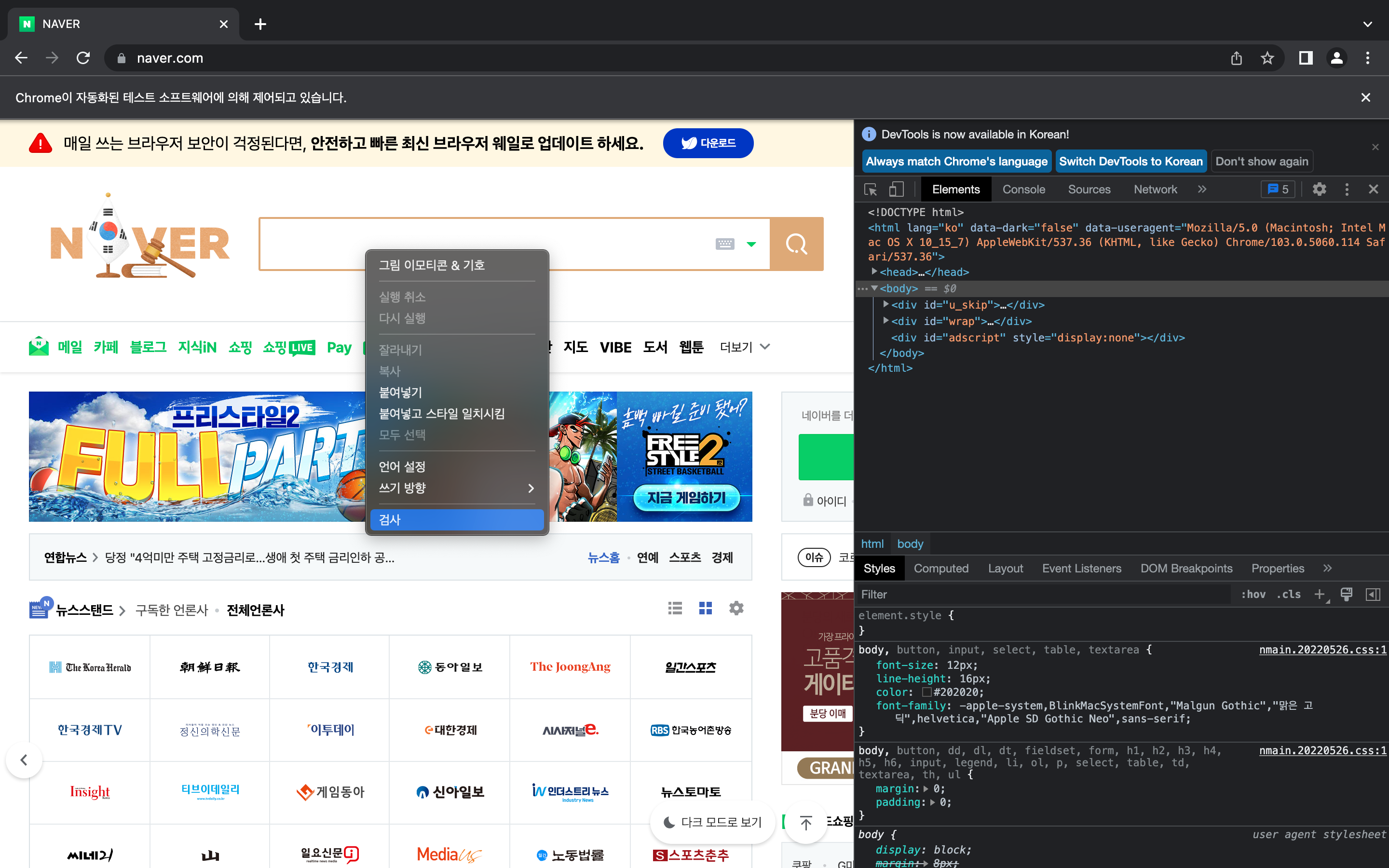
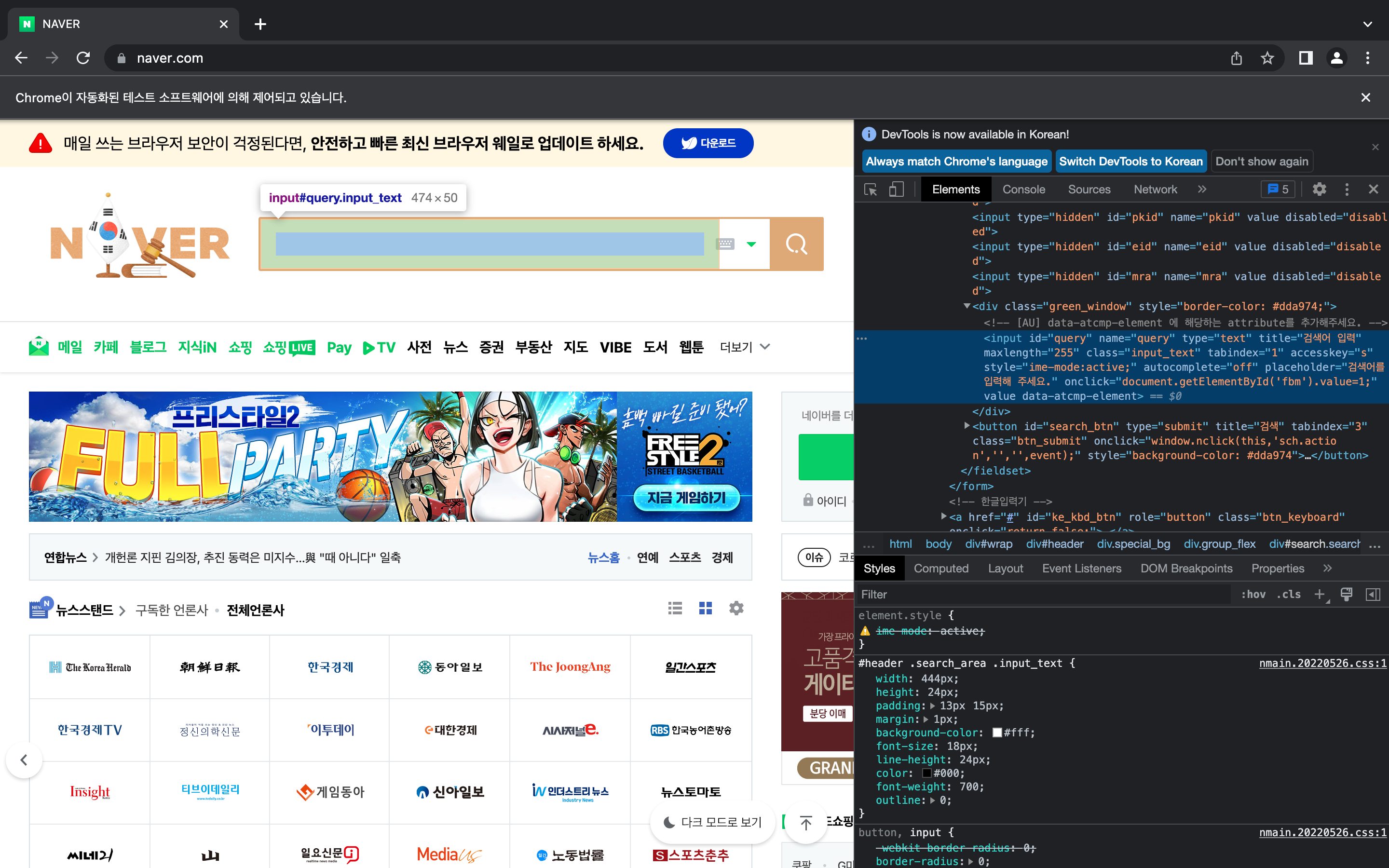
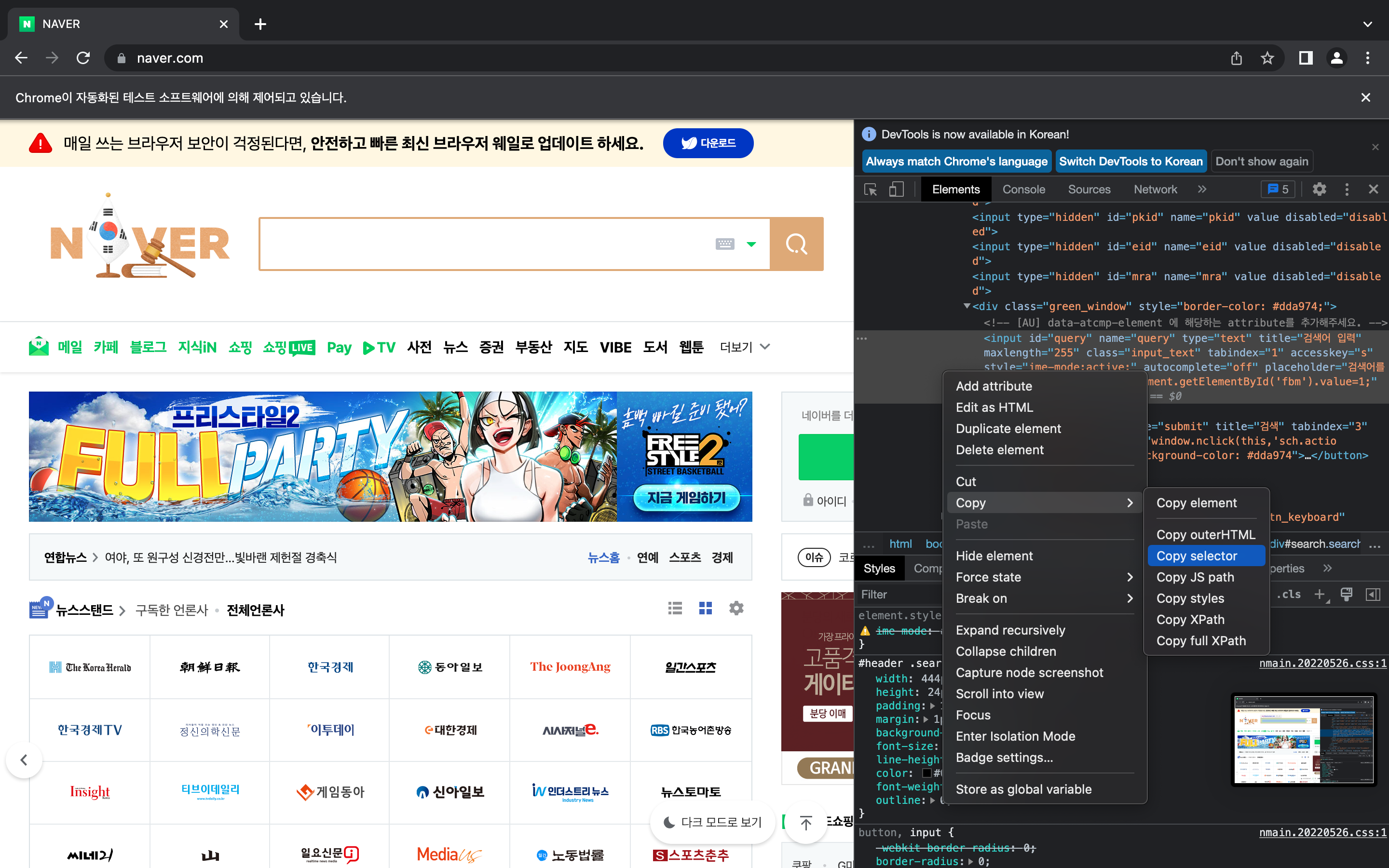
네이버 검색창에 검색어를 입력하고 '검색'하는 과정을 selenium으로 진행해보았다.
from selenium.webdriver.common.by import By
# 검색창 찾아 ele에 저장
ele = browser.find_element(By.CSS_SELECTOR, "div.green_window > input.input_text")
# 네이버 검색창에 '상명대' 입력
ele.send_keys("상명대학교")
# 검색 버튼 클릭과 같은 결과
ele.submit() 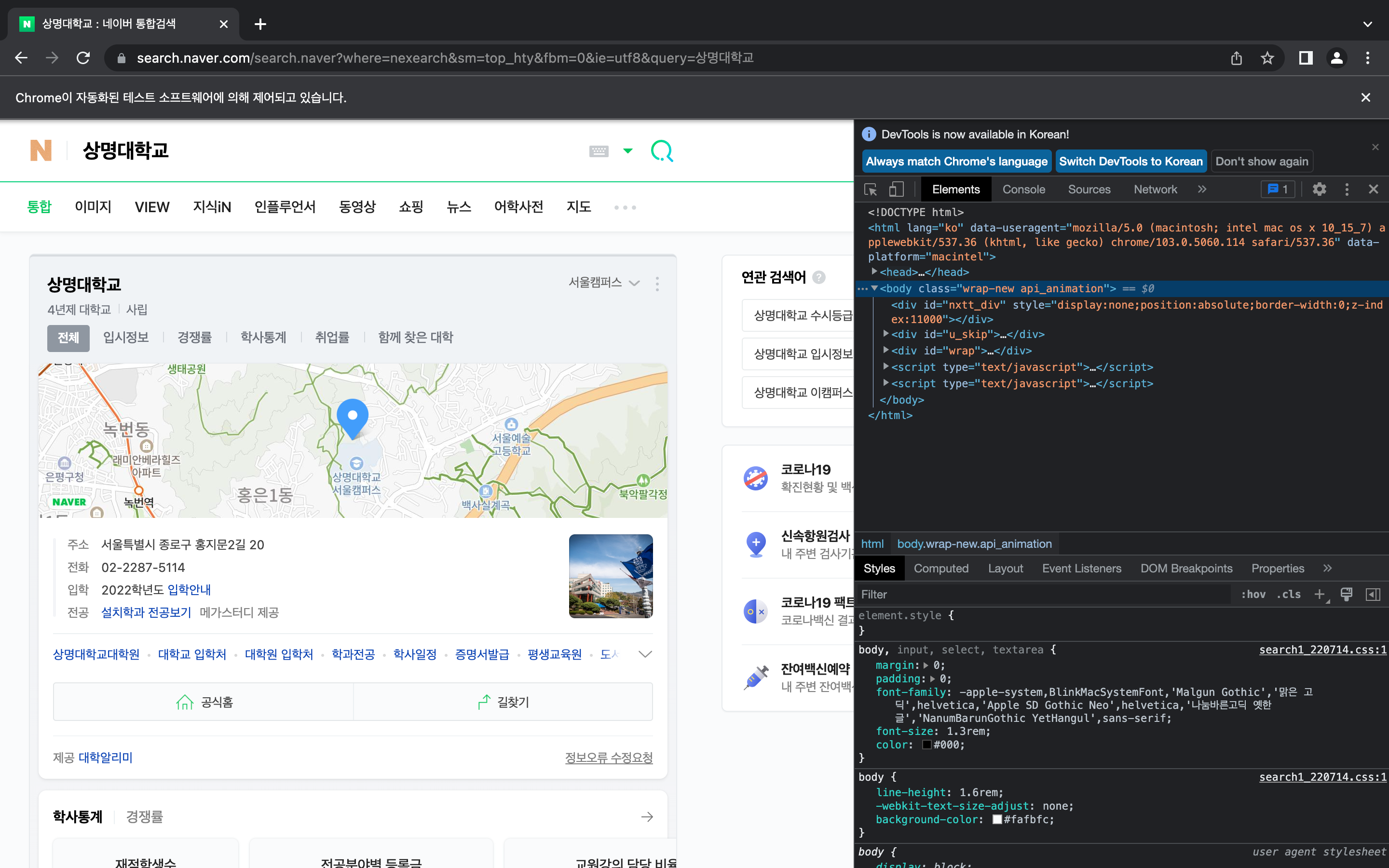 코드만 실행했을 뿐인데 자동으로 검색창에 '상명대학교'가 입력되고 검색된 것을 볼 수 있다.
코드만 실행했을 뿐인데 자동으로 검색창에 '상명대학교'가 입력되고 검색된 것을 볼 수 있다.
+) 네이버 메인 화면에서 '카페' 카테고리 클릭
ele = browser.find_element(
By.CSS_SELECTOR,
"#NM_FAVORITE > div.group_nav > ul.list_nav.type_fix > li:nth-child(2) > a"
)
ele.click()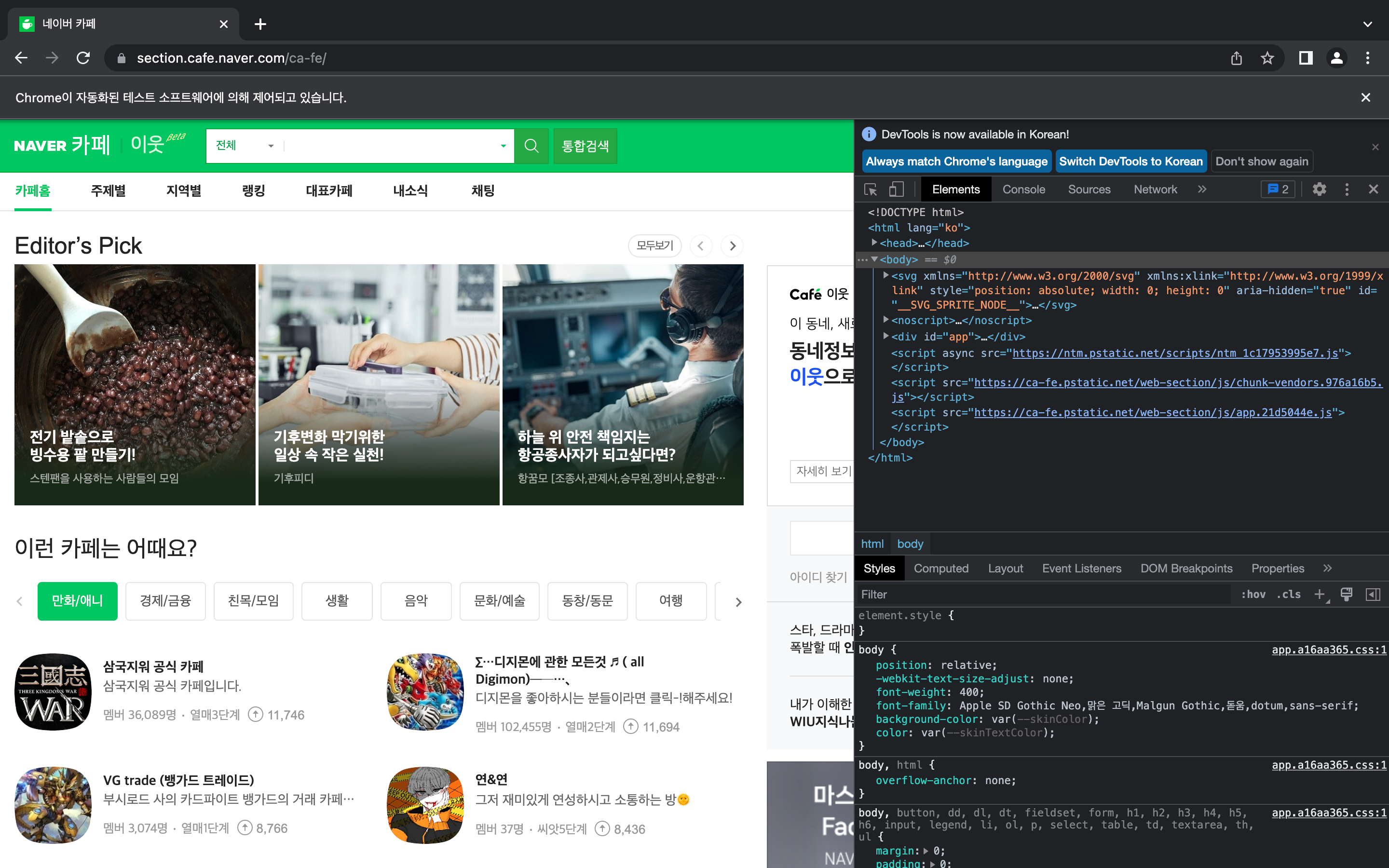
- quit()
브라우저 사용을 완료한 후에는 반드시 브라우저를 종료해줘야 한다.
두 가지 방법이 있는데,- driver.close()
현재 보고 있는 크롬 드라이버를 다운로드하는 이 탭만 닫고 나머지 탭들은 그대로 남아 있게 된다. - driver.quit()
현재 탭뿐만 아니라 같이 존재하는 나머지 크롬 탭들도 모두 종료시킨다.
- driver.close()
탭이 많은 경우 close와 quit을 잘 구분하여 사용해야겠지만 결과적으로 모든 작업을 끝낸 후에는 quit()을 실행시켜 모든 webdriver를 중지하고 세션을 안전하게 종료해줘야 한다.
그렇지 않을 경우 webdriver 세션이 완벽하게 종료되지 않아 메모리 누수가 발생할 수 있다고 한다.
selenium 기초
1. 네이버 쇼핑에서 상품 목록 가져오기
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
# 크롬 실행
browser = webdriver.Chrome('./chromedriver')
# '네이버 쇼핑'으로 이동
browser.get("https://search.shopping.naver.com/search/all?query=네이버%20쇼핑&cat_id=&frm=NVSHATC")
# 전체 html 중 원하는 text만 가져오기 위해 BeautifulSoup 사용
soup = BeautifulSoup(browser.page_source, "html.parser")-
상품명 가져오기
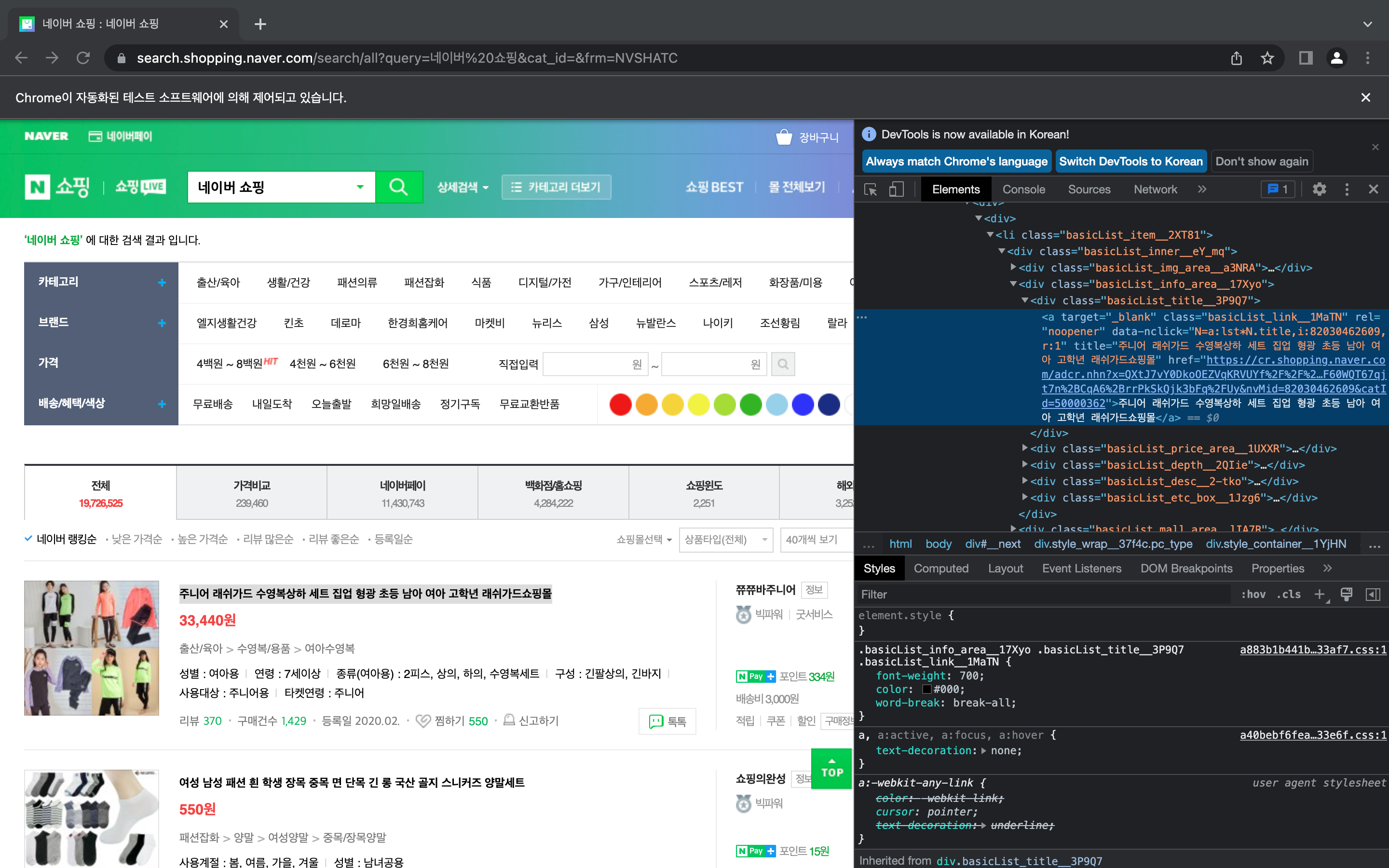 상품명을 나타내는 css selector를 찾아 find()를 실행하는데 화면에 나타나는 모든 상품명을 가져오기 위해 반복문을 사용해주었다.
상품명을 나타내는 css selector를 찾아 find()를 실행하는데 화면에 나타나는 모든 상품명을 가져오기 위해 반복문을 사용해주었다.for ele in soup.select(".list_basis > div > div"): print(ele.select_one(".basicList_link__1MaTN").text) 위 코드를 돌려보면 이렇게 상품명만 잘 가져온 것을 볼 수 있다.
위 코드를 돌려보면 이렇게 상품명만 잘 가져온 것을 볼 수 있다.
-
상품명과 가격 가져오기
마찬가지로 상품명에 해당하는 태그와 가격에 해당하는 태그를 이용해주면 된다.data_list = [] for ele in soup.select(".list_basis > div > div"): _dict = {} title = ele.select_one(".basicList_link__1MaTN").text price = ele.select_one(".price_num__2WUXn").text _dict['title'] = title _dict['price'] = price data_list.append(_dict) data_list
2. Everytime 로그인
먼저 브라우저를 실행하고 에브리타임 로그인 화면으로 이동시킨다.
browser = webdriver.Chrome('./chromedriver')
url = "https://everytime.kr/login"
browser.get(url)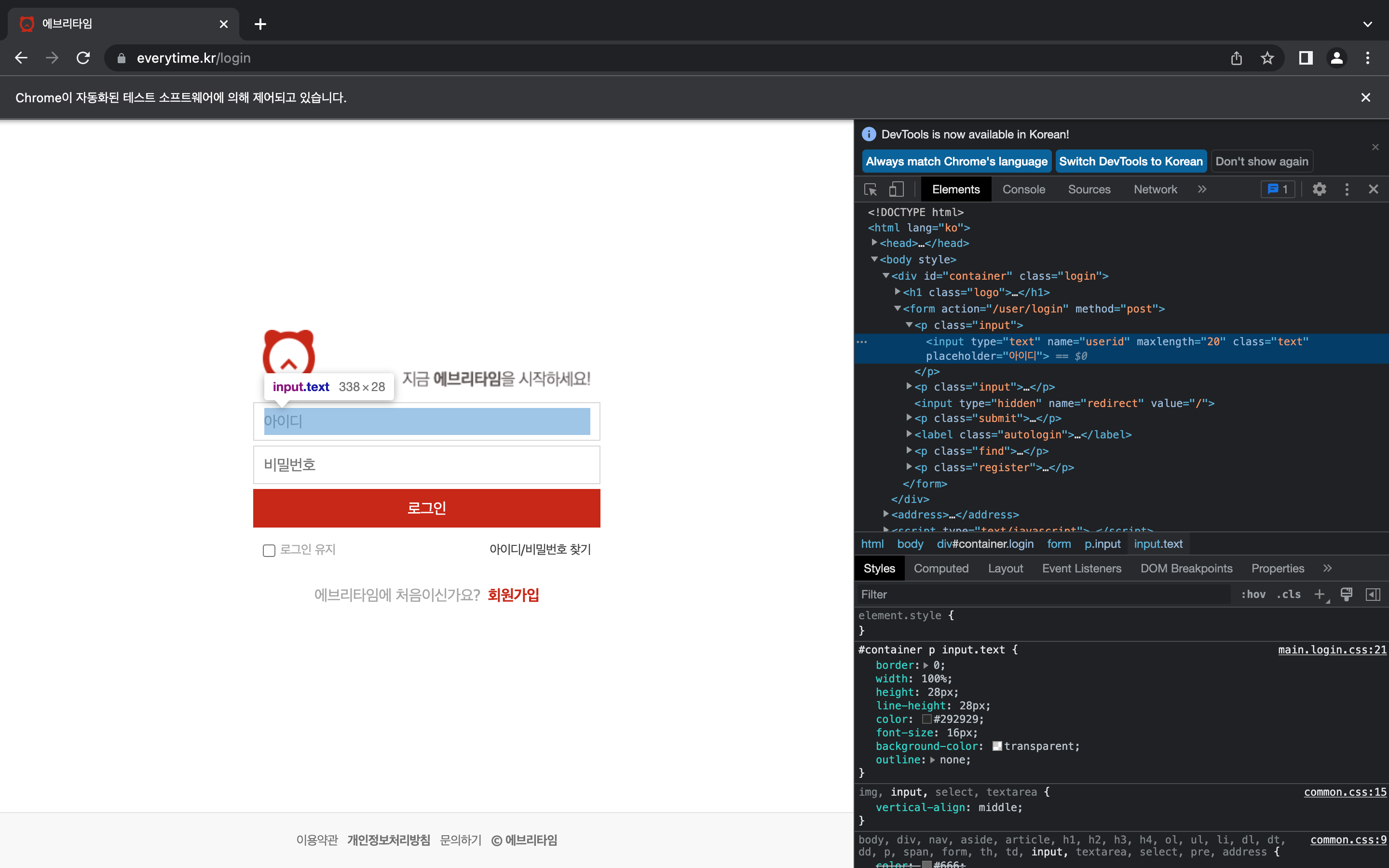 아이디와 비밀번호 창의 css selector를 확인하고
아이디와 비밀번호 창의 css selector를 확인하고
find(), submit()으로 코드를 작성하면 된다.
ele_id = browser.find_element(By.CSS_SELECTOR, "input[name = 'userid']")
ele_id.send_keys("...") # 개인 아이디 입력
ele_id = browser.find_element(By.CSS_SELECTOR, "input[name = 'password']")
ele_id.send_keys("...") # 개인 비밀번호 입력
ele_submit = browser.find_element(By.CSS_SELECTOR, "#container > form > p.submit > input")
ele_submit.click()
#로그인 성공"..." 에는 개인 아이디와 비밀번호를 적어주면 된다..!
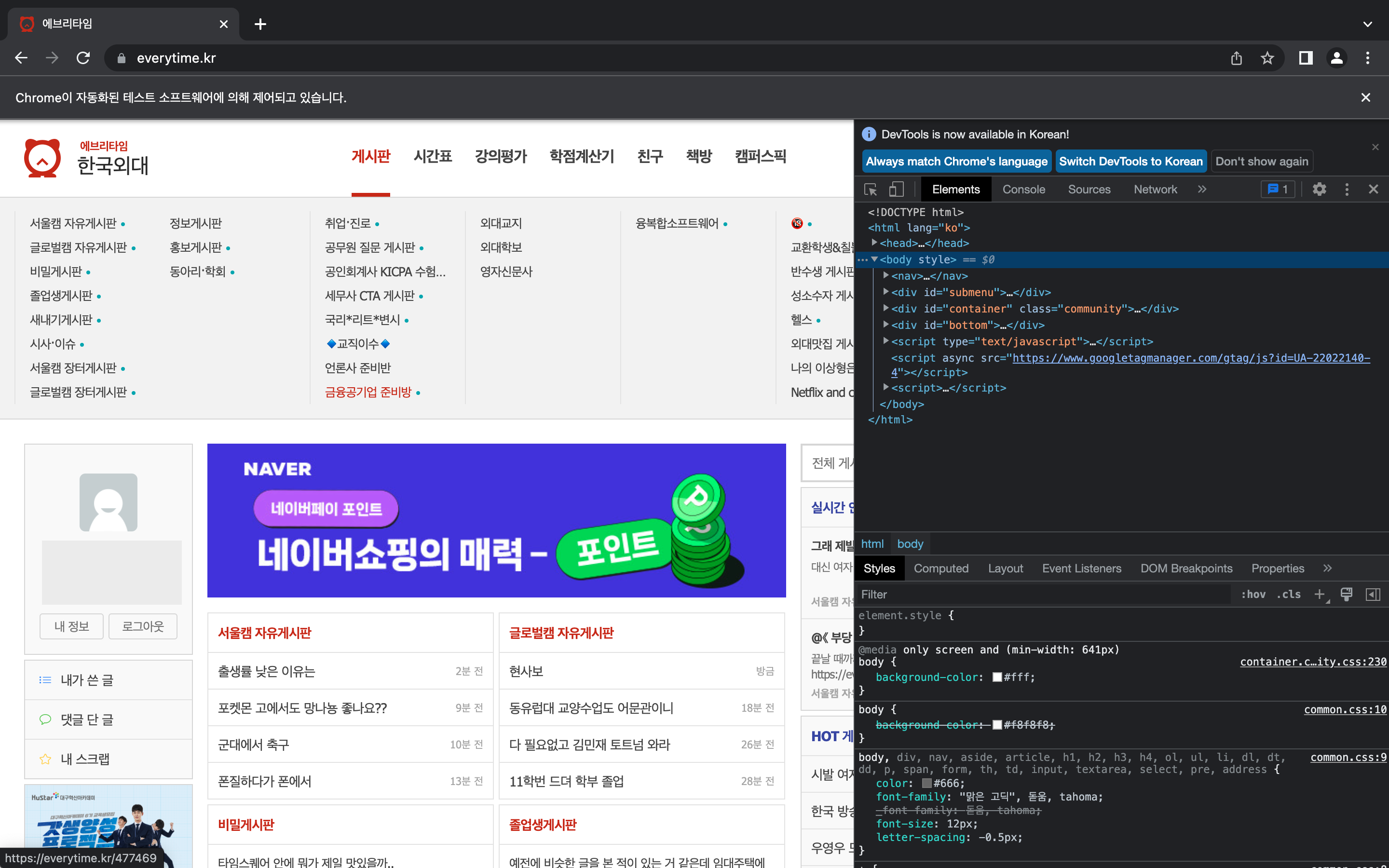 아이디나 비밀번호가 틀리지 않았다면 정상적으로 로그인이 될 것이다.
아이디나 비밀번호가 틀리지 않았다면 정상적으로 로그인이 될 것이다.
이제는 '정보 게시판'에서 게시글 제목과 내용을 가져오고자 한다.
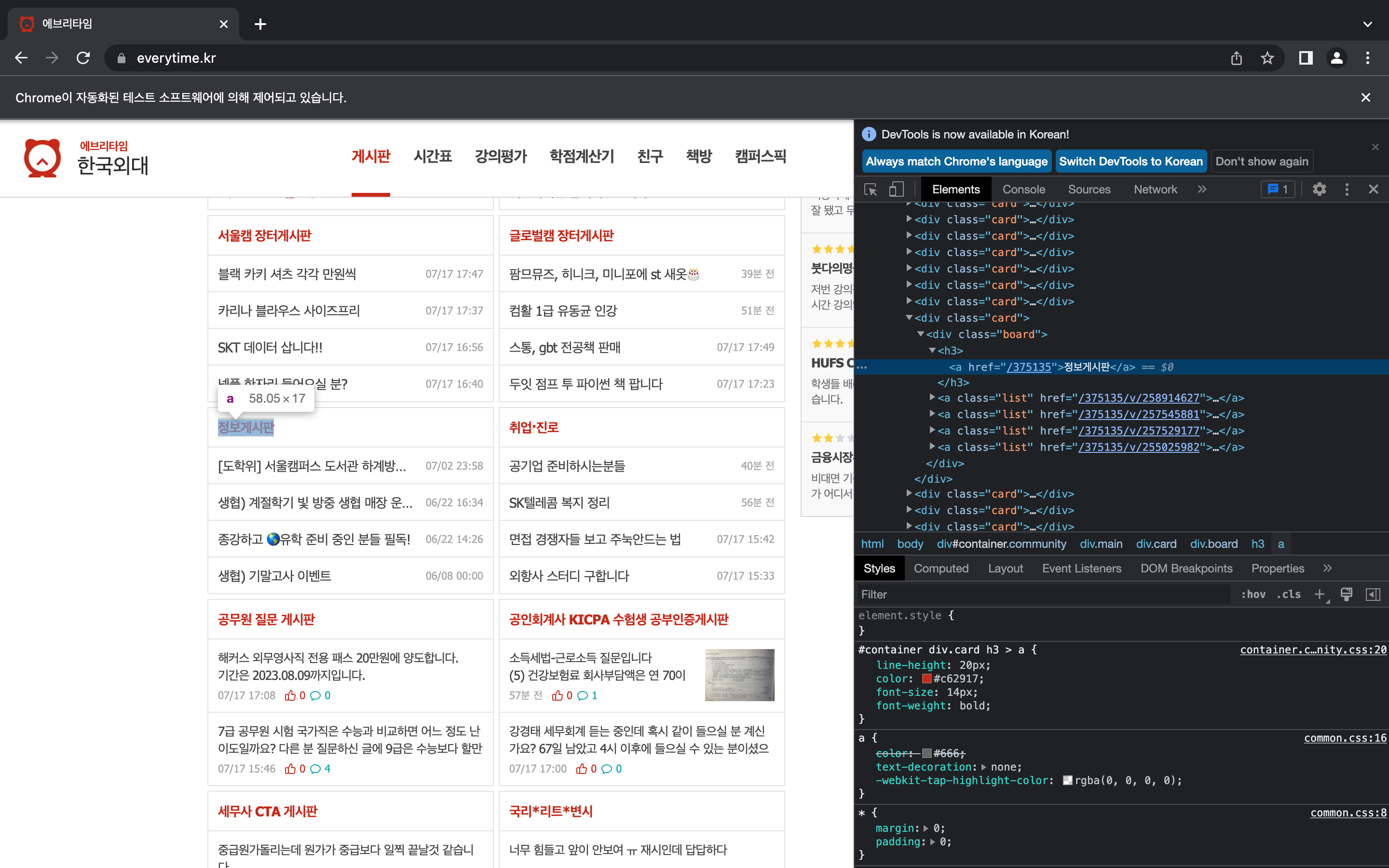 마찬가지로 태그를 확인해주고
마찬가지로 태그를 확인해주고
info_ele = browser.find_element(By.CSS_SELECTOR, "#container > div.rightside > div:nth-child(3) > div > h3 > a")
info_ele.click()
soup = BeautifulSoup(browser.page_source, "html.parser")
post = soup.select_one("#container > div.wrap.articles > article > a")
post.h2게시글 제목에 해당하는 태그가 h2라 BeautifulSoup으로 h2를 찾아주었다.
결과
<h2 class="medium bold">📝진취센 상담관님 후기 모음✏️</h2>게시물 내용은 p 태그 안에 있음을 확인할 수 있었고 전과 동일하게 BeautifulSoup으로 'p'를 찾아주었다.
content = ""
for p in post.select('p'):
content += p.text
content결과
'📌 이 글은 제가 진로취업센터의 존재도 모를 당시이것저것 찾느라 괜한 시간을 썼던 때를 떠올리며후배님들의 시행착오를 조금이나마 줄이고자작성하는 지극히 개인적인 후기입니다.일단 진로취업센터 상담관 분들과진로/자기소개서첨삭/면접 등의 상담을 하고 싶다면HUFS 대학일자리플러스본부 검색 - 로그인 -통합상담 - 상담신청 - 진로취업상담 상담신청누르고 원하는 상담관님을 선택하시고, 간단한 소개와 함께 본인의 이력이 담긴 파일을 첨부하시고 신청하시면'데이터마이닝 수업 때 한 번 크롤링 관련된 과제가 있었는데, 그 때는 '일단 결과만 제대로 나오면 된다'라는 마인드로 대충 무지성으로 과제를 했던 기억이 났다.
이번주에는 크롤링으로 웹 페이지 정보를 가져오고 그걸 바탕으로 텍스트를 시각화하는 과제가 있었는데 확실히 시간에 쫓기지 않고 할 수 있다 보니 전에 비해 더 자세하게 공부할 수 있어서 좋았다. 아직 기본 난이도라 그런지 코드를 돌리다 보면 너무 신기하고 재밌기도 했다. 과제를 잘했는지는 모르겠지만... 어쨌든 제출하긴 했는데 열심히 공부해서 더 멋진 결과물을 만들어 보고 싶다 !
