
자연어 처리란?
NLP(Natural Language Processing, 자연어 처리)는 인공지능의 한 분야로서 머신러닝을 사용하여 텍스트와 데이터를 처리하고 해석한다. 자연어 인식 및 자연어 생성이 NLP의 유형이다.
구조화되지 않은 텍스트 기반 데이터로부터 유용한 정보를 얻기 위해 사용된다.
예) 고객 감정, 영수증 및 인보이스 이해, 문서 분석, 콘텐츠 분류, 트렌드 추적, 의료
정규표현식 re 모듈
import re- re.compile(패턴, 플래그)
패턴과 플래그가 동일한 정규식을 여러번 사용하려면 compile()로 미리 지정해주면 편리하다. - re.search(패턴, 문자열, 플래그)
match()와 유사하지만 패턴이 문자열의 처음부터 일치하지 않아도 괜찮다는 차이가 있다.
r = re.compile("abc")
r.search("123abcdef")결과 : <re.Match object; span=(3, 6), match='abc'>
- re.mathch(패턴, 문자열, 플래그)
문자열의 처음부터 시작해서 작성한 패턴이 일치하는지 확인한다. 일치하지 않는 경우 아무것도 리턴하지 않는다.
r = re.compile("ab.")
r.match("abckkk")결과 : <re.Match object; span=(0, 3), match='abc'>- re.findall(패턴, 문자열, 플래그)
문자열 안에 패턴이 맞는 케이스를 전부 찾아서 리스트로 반환한다. 일치하지 않는 경우 빈 리스트를 반환한다.
txt = """
Name : Pengsoo
Phone : 010 - 1234 - 1111
Species : Penguin
Age : 10
"""
re.findall("\d+", txt)결과 : ['010', '1234', '1111', '10']- re.split(패턴, 문자열, 최대 split 수, 플래그)
문자열에서 패턴이 맞으면 이를 기점으로 리스트로 쪼갠다. 최대 split 수를 지정하면 문자열을 지정한 수만큼 쪼개고 그 이후부터는 패턴이 일치해도 쪼개지 않는다.
txt = "사과 딸기 수박 메론 바나나"
re.split(" ", txt)결과 : ['사과', '딸기', '수박', '메론', '바나나']- re.sub(패턴, 교체할 문자열, 문자열, 최대 교체 수, 플래그)
문자열에 맞는 패턴을 지정한 문자열 형태로 교체한다.
txt = "Name : Pengsoo, Phone : 010 - 1234 - 1111, Age : 10"
re.sub("[^a-zA-Z]", " ", txt)결과 : 'Name Pengsoo Phone Age 'txt = "Name : Pengsoo, Phone : 010 - 1234 - 1111, Age : 10"
re.sub("[^a-zA-Z]", "", txt)결과 : 'NamePengsooPhoneAge'txt = "Name : Pengsoo, Phone : 010 - 1234 - 1111, Age : 10"
re.sub("[^a-zA-Z]", "*", txt)결과 : 'Name***Pengsoo**Phone**********************Age*****'- grouping
패턴을 묶어 찾을 때 소괄호로 그룹핑할 수 있다.
r = re.compile("(\w+)@(.+)")
r_gp = r.search("test@abc.com")
print(r_gp.group(1))
print(r_gp.group(2))
print(r_gp.group(0))결과
test
abc.com
test@abc.com연습 문제
- 다음 text에서 휴대폰 번호와 전화 번호를 모두 추출하시오
text = "제 휴대폰 번호는 010-1234-5678이고, 전화 번호는 02.987.6543입니다."풀이
import re
re.findall("\d+\W\d+\W\d+", text)결과
['010-1234-5678', '02.987.6543']- 다음 두소 중 올바른 웹페이지(http, https)만 추출하시오
webs = """
http://www.test.co.kr,
https://www.test1/com,
https://www.test.com,
ftp://www.test.com,
http:://www.test.com,
htp://www.test.com,
http://google.com,
https://www.homepage.com,
"""풀이
import re
re.findall("https?://[\w.]+\w", webs)결과
['http://www.test.co.kr',
'https://www.test1',
'https://www.test.com',
'http://google.com',
'https://www.homepage.com']텍스트 전처리
자연어 처리는 일반적으로 토큰화, 단어 집합 생성, 정수 인코딩, 패딩, 벡터화의 과정을 거친다.
토큰화(Tokenization)
토큰화란 주어진 텍스트를 단어 또는 문자 단위로 자르는 것을 뜻한다. NLTK라는 파이썬 패키지를 이용하면 쉽게 토큰화를 수행할 수 있다.
!pip install ntlk
import nltk
nltk.downlad()nltk.downlad() : NLTK Data라는 데이터를 추가적으로 설치하기 위한 코드
위 코드를 실행헸을 때 True 라는 결과가 나오면 잘 실행된 것이다.
NLTK에서 제공하는 tokenizer의 종류는 다음과 같다.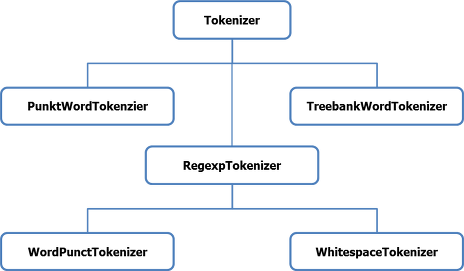
- word_tokenize(문자열)
문자열을 단어 단위로 나눠준다. 이때 구두점(')은 토큰화하지 않는다.
import nltk
from nltk.tokenize import word_tokenize
print(word_tokenize(
"Don't be fooled by the dark sounding name, Mr.Jone's Orphanage is as cheery goes for a pastry shop."
))결과
['Do', "n't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', ',', 'Mr.Jone', "'s", 'Orphanage', 'is', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop', '.']import nltk
from nltk.tokenize import word_tokenize
text = "I am actively looking for Ph.D students. and you are a Ph.D student."
print(word_tokenize(text))결과
['I', 'am', 'actively', 'looking', 'for', 'Ph.D', 'students', '.', 'and', 'you', 'are', 'a', 'Ph.D', 'student', '.']- WordPunctTokenizer
word_tokenize와 달리 모든 구두점(punktuation)으로 문장을 분리한다.
import nltk
from nltk.tokenize import WordPunctTokenizer
WordPunctTokenizer().tokenize(
"Don't be fooled by the dark sounding name, Mr.Jone's Orphanage is as cheery goes for a pastry shop."
)결과
['Don',
"'",
't',
'be',
'fooled',
'by',
'the',
'dark',
'sounding',
'name',
',',
'Mr',
'.',
'Jone',
"'",
's',
'Orphanage',
'is',
'as',
'cheery',
'goes',
'for',
'a',
'pastry',
'shop',
'.']- TreebankWordTokenizer
표준화된 토큰화 모델로, 하이픈으로 구성된 단어는 하나로 유지하고 doesn't와 같이 접어(')가 함께하는 단어는 분리한다.
import nltk
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
text = "Starting a home-based restaurant may be an ideal. It doesn't have a food chain or restaurant of their own."
tokenizer.tokenize(text)결과
['Starting',
'a',
'home-based',
'restaurant',
'may',
'be',
'an',
'ideal.',
'It',
'does',
"n't",
'have',
'a',
'food',
'chain',
'or',
'restaurant',
'of',
'their',
'own',
'.']형태소 분석하기
Konlpy 사용하여 한국어 자연어 처리
한국어 자연어 처리를 하기 위해서 형태소 분석을 해야 하는 경우가 많다.
<한국어 형태소 분석기 종류>
- Hannanum(한나눔)
- Kkma(꼬꼬마)
- Komoran(코모란)
- Okt(Open Korean Text)
- Mecab(메캅)
- Khaii(카이) 등
여러 가지 한국어 형태소 분석기를 사용 목적에 따라 골라 사용한다.
이때 KoNLPy 라는 패키지를 설치하면 Hannanum(한나눔), Kkma(꼬꼬마), Komoran(코모란), Okt(Open Korean Text)을 한꺼번에 손쉽게 사용할 수 있어 편리하다.
!pip install konlpy
import konlpy모든 형태소 분석기의 사용법은 동일한데, 그냥 분석기를 import 해와서 원하는 함수를 사용하면 된다.
- morphs()
문장을 형태소 단위로 나눠준다. - nouns()
문장에서 명사만 추출한다. - pos()
형태소의 종류까지 반환해준다. (ex 'N' : 명사, 'J' : 조사) - tagset
형태소 종류를 나타내는 알파벳들이 어떤 의미인지, 어떤 종류가 있는지 확인할 수 있다.
- Okt
from konlpy.tag import Okt #Okt 모듈 불러오기
okt = Okt()
print(okt.morphs("이 여름 다시 한 번 설레고 싶다, 그 여름을 틀어줘. 싹쓰리")) #형태소 분석
print(okt.nouns("이 여름 다시 한 번 설레고 싶다, 그 여름을 틀어줘. 싹쓰리")) #명사 추출
print(okt.pos("이 여름 다시 한 번 설레고 싶다, 그 여름을 틀어줘. 싹쓰리")) # 품사 태깅결과
['이', '여름', '다시', '한', '번', '설레고', '싶다', ',', '그', '여름', '을', '틀어줘', '.', '싹', '쓰리'] #morphs
['이', '여름', '다시', '번', '그', '여름', '싹'] #nouns
[('이', 'Noun'), ('여름', 'Noun'), ('다시', 'Noun'), ('한', 'Verb'), ('번', 'Noun'), ('설레고', 'Adjective'), ('싶다', 'Verb'), (',', 'Punctuation'), ('그', 'Noun'), ('여름', 'Noun'), ('을', 'Josa'), ('틀어줘', 'Verb'), ('.', 'Punctuation'), ('싹', 'Noun'), ('쓰리', 'Adjective')] #pos- Hannanum(한나눔)
from konlpy.tag import Hannanum # 한나눔 모듈 불러오기
han = Hannanum()
print(han.morphs("이 여름 다시 한 번 설레고 싶다, 그 여름을 틀어줘. 싹쓰리")) # 형태소 분석
print(han.nouns("이 여름 다시 한 번 설레고 싶다, 그 여름을 틀어줘. 싹쓰리")) # 명사 추출
print(han.pos("이 여름 다시 한 번 설레고 싶다, 그 여름을 틀어줘. 싹쓰리")) # 품사 태깅결과
['이', '여름', '다시', '하', 'ㄴ', '번', '설레', '고', '싶', '다', ',', '그', '여름', '을', '틀', '어', '주', '어', '.', '싹쓰', '이', '리'] #morphs
['여름', '번', '여름', '싹쓰'] #nouns
[('이', 'M'), ('여름', 'N'), ('다시', 'M'), ('하', 'P'), ('ㄴ', 'E'), ('번', 'N'), ('설레', 'P'), ('고', 'E'), ('싶', 'P'), ('다', 'E'), (',', 'S'), ('그', 'M'), ('여름', 'N'), ('을', 'J'), ('틀', 'P'), ('어', 'E'), ('주', 'P'), ('어', 'E'), ('.', 'S'), ('싹쓰', 'N'), ('이', 'J'), ('리', 'E')] #pos텍스트를 입력 받아 형태소 분석을 하고 싶을 때는 아래와 같은 코드를 사용할 수 있다.
import konlpy
from konlpy.tag import Hannanum
nan = Hannanum()
text = input("분석할 텍스트를 입력하시오: ")
result = han.pos(text)
for lex, pos in result:
print("{}\t{}".format(lex, pos))corpus와 wordcloud
corpus는 '말뭉치'를 뜻하며, 언어의 표본을 담아준 묶음(단어사전)을 나타낸다.
konlpy.corpus에서 제공하는 kolaw를 바탕으로 wordcloud로 단어의 빈도 수를 시각화해 볼 것이다.
from konlpy.corpus import kolaw
from konlpy.tag import Okt
okt = Okt()
law_corpus = kolaw.open("constitution.txt").read()
law_corpus[:50]
#kolaw 중 constitution.txt 파일을 읽어 앞 50글자 출력하기결과
'대한민국헌법\n\n유구한 역사와 전통에 빛나는 우리 대한국민은 3·1운동으로 건립된 대한민국임'okt.pos(law_corpus[:50]) # 품사 태깅결과
[('대한민국', 'Noun'),
('헌법', 'Noun'),
('\n\n', 'Foreign'),
('유구', 'Noun'),
('한', 'Josa'),
('역사', 'Noun'),
('와', 'Josa'),
('전통', 'Noun'),
('에', 'Josa'),
('빛나는', 'Verb'),
('우리', 'Noun'),
('대', 'Modifier'),
('한', 'Modifier'),
('국민', 'Noun'),
('은', 'Josa'),
('3', 'Number'),
('·', 'Punctuation'),
('1', 'Number'),
('운동', 'Noun'),
('으로', 'Josa'),
('건립', 'Noun'),
('된', 'Verb'),
('대한민국', 'Noun'),
('임', 'Noun')]corpus에서 용도에 맞게 토큰을 분류하는 작업을 "토큰화(tokenize)"라고 하며,
토큰화 작업 전/후에는 텍스트 데이터를 용도에 맞게 정제(cleaning) 및 정규화(normalization) 해줘야 한다.
정제(cleaning) : 갖고 있는 corpus로부터 노이즈 데이터를 제거한다.
정규화(normalization) : 표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만들어준다.
-
정제(cleaning)
- 불용어 제거
노이즈 데이터(noise data)는 자연어가 아니면서 아무 의미도 갖지 않은 글자들(특수 문자 등)을 의미하기도 하지만, 분석하고자 하는 목적에 맞지 않는 불필요한 단어들도 포함시킬 수 있다.nltk.download('stopwords')결과값으로 True가 반환되면 정상적으로 다운로드된 것이다.
import nltk from nltk.corpus import stopwords stopwords.words('english')[:10]결과 ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're"]import nltk from nltk.corpus import stopwords from nltk.tokenize import word_tokenize example = "Family is not an important thing. It's everything." stop_words = set(stopwords.words('english')) word_tokens = word_tokenize(example) result = [] for w in word_tokens: if w not in stop_words: result.append(w) print(word_tokens) print(result)결과 ['Family', 'is', 'not', 'an', 'important', 'thing', '.', 'It', "'s", 'everything', '.'] ['Family', 'important', 'thing', '.', 'It', "'s", 'everything', '.']한글에서 불용어를 제거하는 방식도 동일하다.
import nltk from nltk.corpus import stopwords from nltk.tokenize import word_tokenize example = """이 여름 다시 한번 설레고 싶다 그때 그 여름을 틀어줘 그 여름을 들려줘 이 여름도 언젠가는 그해 여름 오늘이 가장 젊은 내 여름""" stop_words = "이 그 또 가장" # 위의 불용어는 명사가 아닌 단어 중에서 임의로 선정한 것으로 실제 의미있는 선정 기준이 아님 stop_words = stop_words.split(" ") word_tokens = word_tokenize(example) result = [] for w in word_tokens: if w not in stop_words: result.append(w) print(word_tokens) print(result)결과 ['이', '여름', '다시', '한번', '설레고', '싶다', '그때', '그', '여름을', '틀어줘', '그', '여름을', '들려줘', '이', '여름도', '언젠가는', '그해', '여름', '오늘이', '가장', '젊은', '내', '여름'] ['여름', '다시', '한번', '설레고', '싶다', '그때', '여름을', '틀어줘', '여름을', '들려줘', '여름도', '언젠가는', '그해', '여름', '오늘이', '젊은', '내', '여름']
-
kobill를 사용한 실습
kobill은 konlpy에 내장되어 있는 법률안을 읽어오는 함수이다.``` import nltk import konlpy from konlpy.corpus import kobill files_ko = kobill.fileids() # kobill에는 team POPONG(pokr.kr)에 의해 취합된 의회 정보들이 존재 files_ko #kobill에 담긴 문서 확인 ``` ``` 결과 ['1809896.txt', '1809897.txt', '1809895.txt', '1809894.txt', '1809890.txt', '1809891.txt', '1809893.txt', '1809892.txt', '1809899.txt', '1809898.txt'] ``` ``` doc_ko = kobill.open("1809894.txt").read() doc_ko ``` ``` 결과 '고등교육법 일부개정법률안\n\n(안상수의원 대표발의 )\n\n 의 안\n 번 호\n\n9894\n\n발의연월일 : 2010. 11. 15.\n\n발 의 자 : 안상수․김정훈․원희목 \n\n강석호․서상기․나성린 \n\n권영진․이춘식․정영희 \n\n이애주․안형환․백성운 \n\n김금래 의원(13인)\n\n제안이유 및 주요내용\n\n 현재 간호사의 경우 전문대학 졸업 또는 대학 졸업에 상관없이 면\n\n허증을 취득할 수 있지만, 학위의 종류가 전문학사이기 때문에 학사학\n\n위를 취득하기 위하여 87.2%가 별도로 학사학위 교육과정을 이수하고 \n\n있는 실정임.\n\n 이러한 4년제 간호 교육의 필요성과 선진 각국의 경향을 고려하고 \n\n국민에 대한 보다 나은 의료 서비스를 제공하기 위하여 대통령령이 \n\n정하는 일정한 기준을 충족하는 간호과에 대해서는 수업연한을 4년으\n\n로 하고, 수여하는 학위의 종류를 학사학위로 하도록 함(안 제50조의3 \n\n신설).\n\n- 1 -\n\n\x0c법률 제 호\n\n고등교육법 일부개정법률안\n\n고등교육법 일부를 다음과 같이 개정한다.\n\n제50조의3을 다음과 같이 신설한다.\n\n제50조의3(간호과의 수업연한 및 학위에 관한 특례) ① 대통령령이 정\n\n하는 기준을 충족하는 간호과의 수업연한은 4년으로 한다.\n\n ② 제1항의 간호과에서 학칙이 정하는 과정을 이수한 자에 대하여\n\n는 학사학위를 수여한다.\n\n ③ 제2항의 학위의 종류 및 수여에 관하여 필요한 사항은 대통령령\n\n으로 정한다.\n\n부 칙\n\n① 이 법은 공포 후 6개월이 경과한 날부터 시행한다.\n\n② 이 법 시행 당시 수업연한이 4년으로 된 간호과에 재학 중인 자에 \n\n대해서는 본인의 신청에 의하여 종전의 수업연한 및 학위에 관한 규\n\n정을 적용할 수 있다.\n\n- 3 -\n\n\x0c신·구조문대비표\n\n현 행\n\n개 정 안\n\n <신 설>\n\n제50조의3(간호과의 수업연한 및 \n\n학위에 관한 특례) ① 대통령\n\n령이 정하는 기준을 충족하는 \n\n간호과의 수업연한은 4년으로 \n\n한다.\n\n ② 제1항의 간호과에서 학칙이 \n\n정하는 과정을 이수한 자에 대\n\n하여는 학사학위를 수여한다.\n\n ③ 제2항의 학위의 종류 및 수\n\n여에 관하여 필요한 사항은 대\n\n통령령으로 정한다.\n\n- 5 -\n\n\x0c' ``` ``` from konlpy.tag import Okt okt = Okt() nouns = okt.nouns(doc_ko) # 명사 분석 nouns ``` 명사를 분석하는 nouns()를 사용하면 ['고등', '교육법', '일부', '개정', '법률', '안', '안상수', '의원', '대표', '발의', '의', '안', '번', '호', '발의', '연월일', '발', '의', '자', '안상수', '김정훈', '원희목', '강석호', '서상기',...]와 같은 결과가 나오는 것을 볼 수 있다.
ko = nltk.Text(nouns, name = "의안 제1809894호") print(len(ko.tokens)) # 수집된 단어의 횟수 print(len(set(ko.tokens))) # 수집된 단어의 고유한 횟수 ko.vocab() # 단어별 빈도결과 240 121 FreqDist({'학위': 11, '간호': 9, '정': 9, '제': 9, '수업': 7, '연한': 7, '및': 6, '안': 5, '관': 5, '자': 4, ...})빈도 수를 확인하고 이를 wordcloud로 시각화한다.
!pip install wordcloud from wordcloud import WordCloud stopwords = ["정", "제", "및", "안", "지", "과", "수", "의", "이", "발"] ko = [each_word for each_word in ko if each_word not in stopwords] ko결과 ['고등','교육법','일부','개정','법률','안상수','의원','대표','발의','번','호', ...]ko = nltk.Text(ko, name = "의안 제1809894호") data = ko.vocab().most_common(30) wordcloud = WordCloud(font_path = "글씨체 지정을 위한 경로", background_color = "white").generate_from_frequencies(dict(data)) plt.figure(figsize = (12, 8)) plt.imshow(wordcloud) plt.axis("off") plt.show()
다음과 같이 wordcloud가 나타나는 것을 확인할 수 있다.

