1. Kibana란 ?
 Kibana 공식 홈
Kibana 공식 홈
: Elastic에서 제공하는 오픈소스 데이터 대시보드 / 시각화 툴
2. 뱅크샐러드 결제내역 시각화 실습
step1) 데이터 준비
스마트폰 뱅크샐러드 앱 설치 -> 본인확인 & 계좌 연결 -> 설정 > 데이터 내보내기
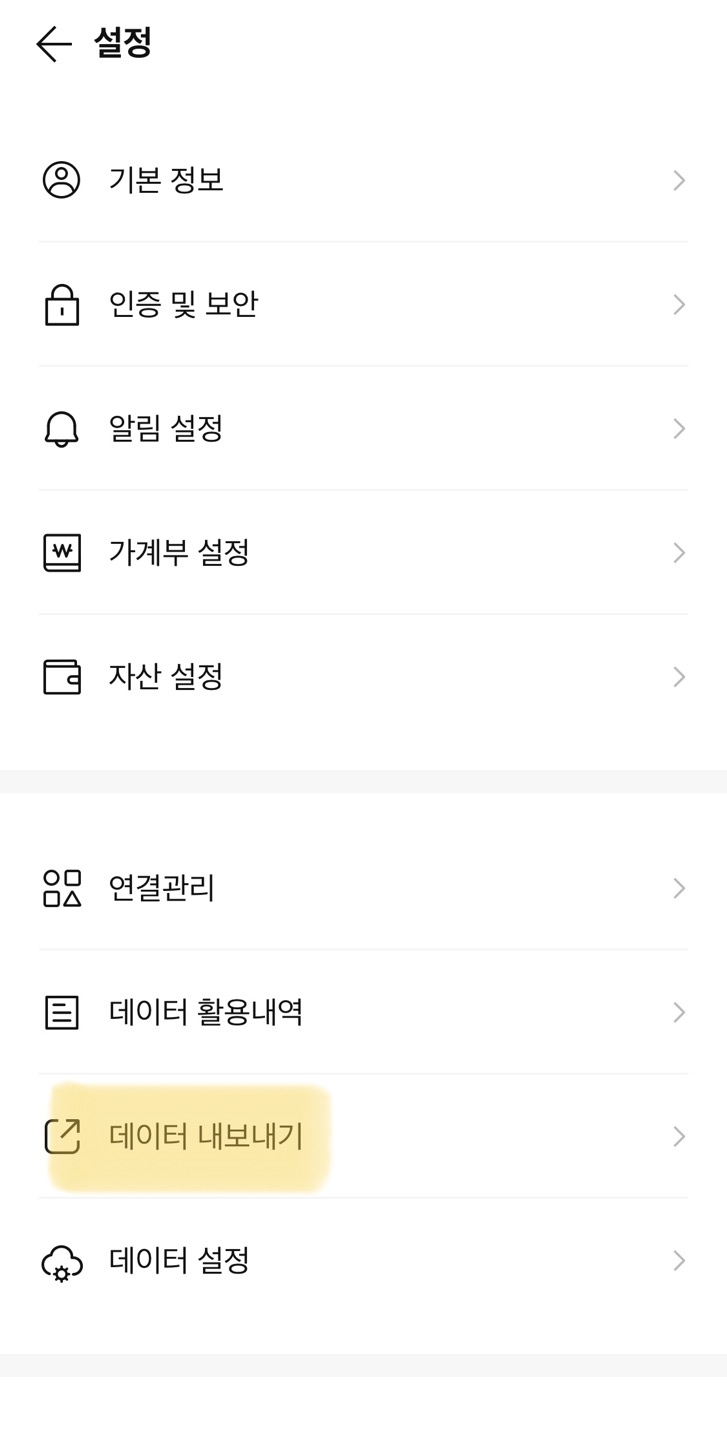 위 과정을 거치면 이메일로 자신의 입출금, 카드 사용 내역을 csv 파일이 전송된다.
위 과정을 거치면 이메일로 자신의 입출금, 카드 사용 내역을 csv 파일이 전송된다.
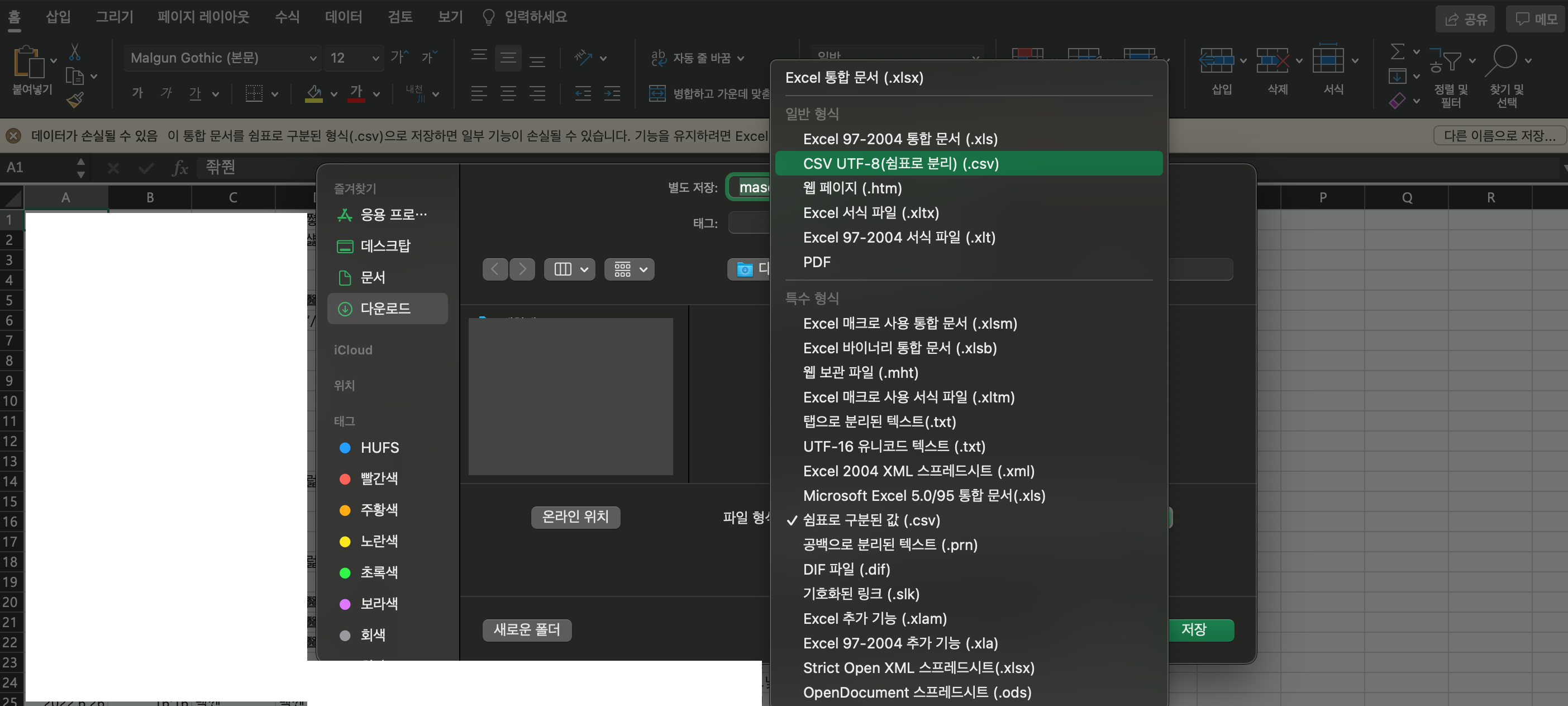 파일 다운로드 -> 다른 이름으로 저장 -> 파일 형식 : csv 파일 & 인코딩 : UTF-8
파일 다운로드 -> 다른 이름으로 저장 -> 파일 형식 : csv 파일 & 인코딩 : UTF-8
저장해주고 텍스트 편집기나 메모장으로 파일을 열어 한글이 깨지지 않는지 확인해본다.
step2) 키바나에 데이터 업로드하기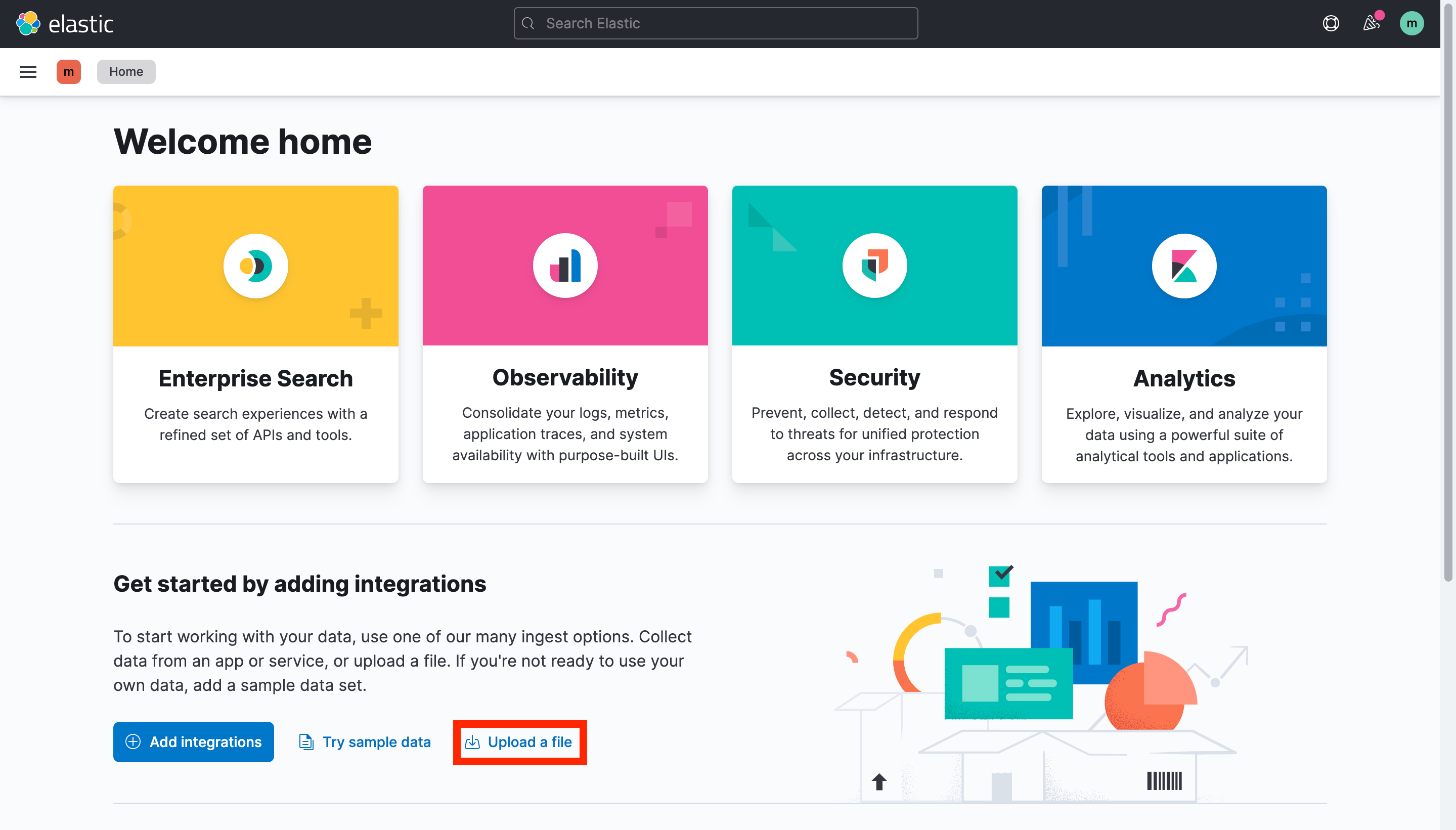
본인 스페이스에 접속한 후 홈에서 Upload a file을 선택한다.
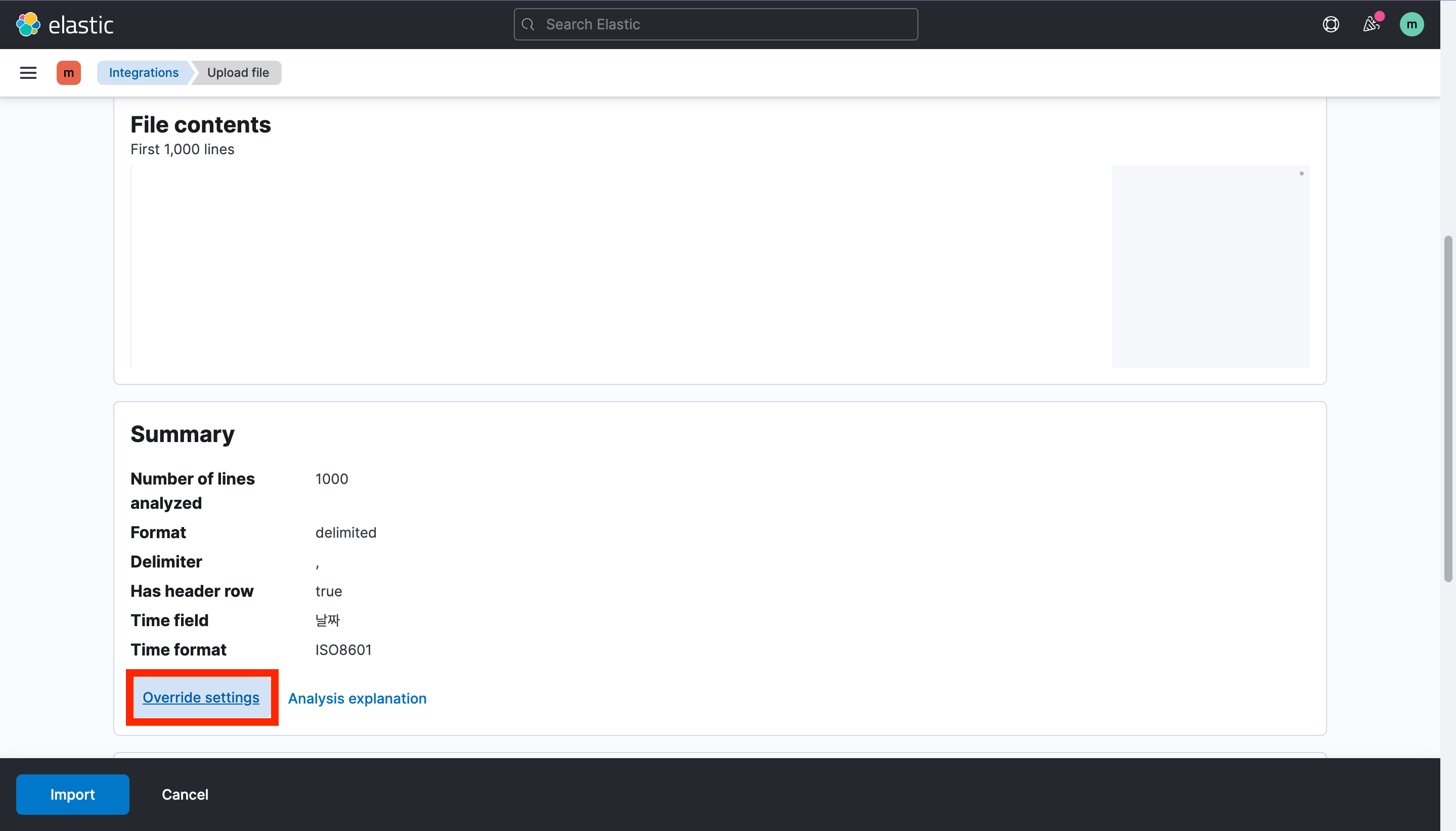
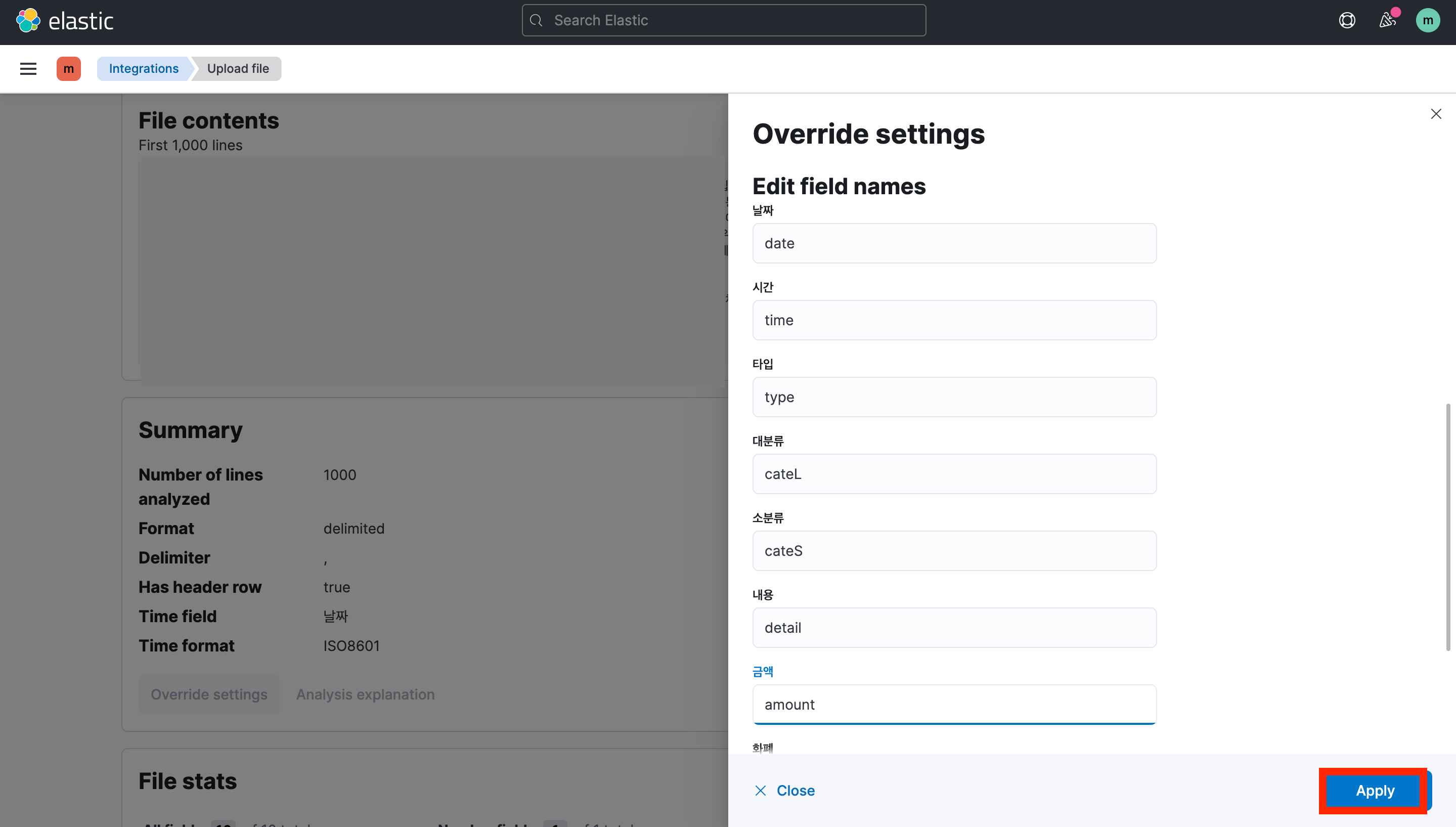 원하는 csv 파일을 선택한 다음 override settings에서 필드명을 영어로 적절하게 바꾸고 Apply로 변경 사항을 저장해준다.
원하는 csv 파일을 선택한 다음 override settings에서 필드명을 영어로 적절하게 바꾸고 Apply로 변경 사항을 저장해준다.
import하면 인덱스 이름을 설정해야 하는데, 공통된 인덱스명을 통해 여러 스페이스를 하나로 묶어 전체 데이터를 분석할 수도 있다. 이는 키바나에서만 제공하는 기능이고, 엘라스틱 서치에는 이런 기능이 없다고 한다.
예를 들어 사용자 1이 biohealth_user1이라는 인덱스명으로 데이터를 업로드하고
사용자 2가 biohealth_user2, 사용자 3이 biohealth_user3 등 각자의 스페이스에서 데이터를 업로드하면 나중에 biohealth라는 인덱스명을 포함하는 개인의 데이터들을 통합해 전체적으로 분석, 시각화할 수 있다.
이를 Data View라 하는데 하나 또는 여러 개의 인덱스를 하나의 속성으로 묶어주는 역할을 한다.
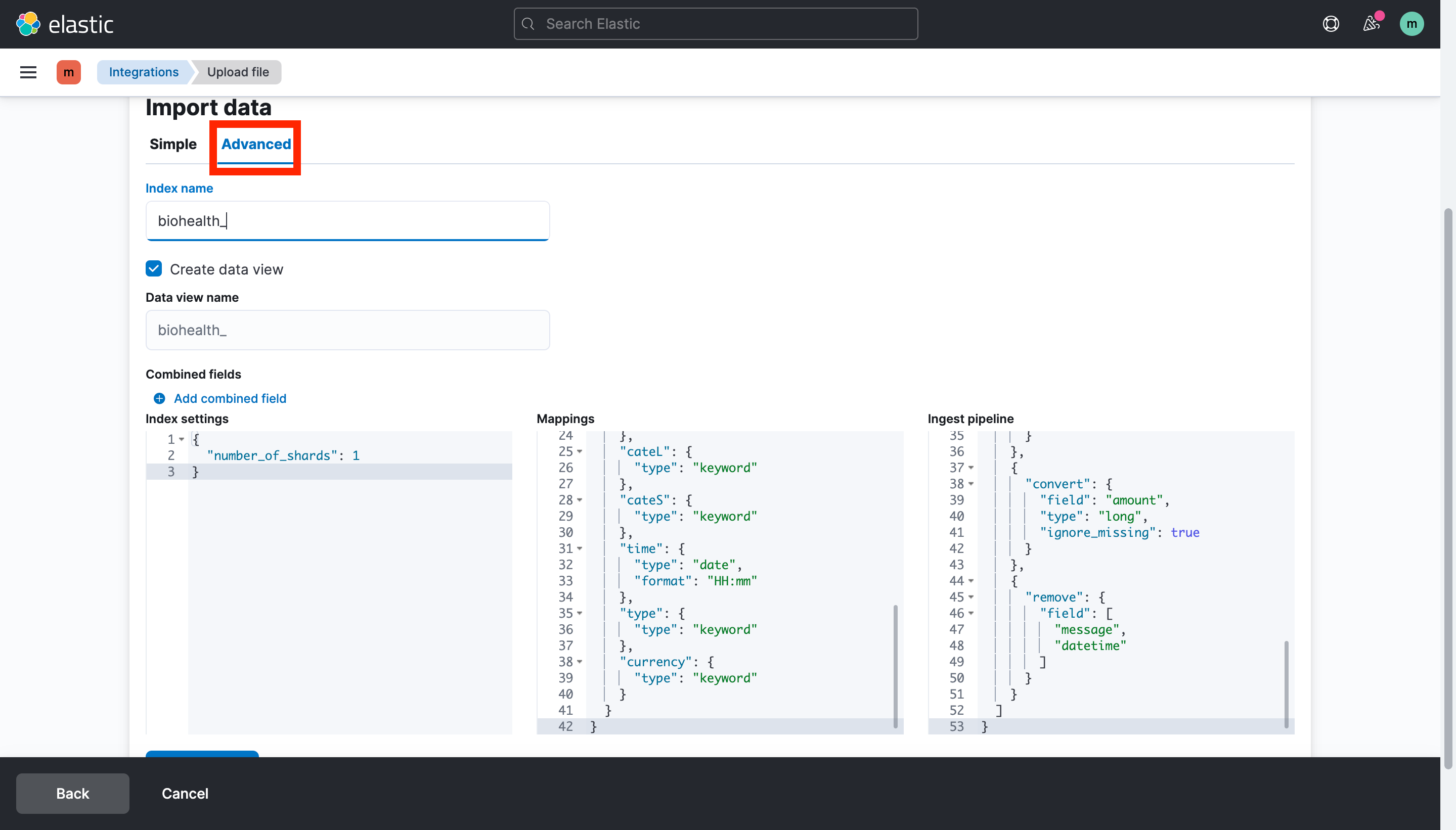 Advanced에서 인덱스 이름 뿐만 아니라 Mappings와 Ingest pipeline도 적절하게 수정해준다.
Advanced에서 인덱스 이름 뿐만 아니라 Mappings와 Ingest pipeline도 적절하게 수정해준다.
Mappings : 필드들을 각 어떤 성질로 저장할 것인지 설정
#Mappings
{
"properties": {
"@timestamp": {
"type": "date"
},
"payment_tp": {
"type": "keyword"
},
"amount": {
"type": "long"
},
"date": {
"type": "date",
"format": "yyyy-MM-dd"
},
"detail": {
"type": "keyword",
"fields": {
"analyzed": {
"type": "text",
"fielddata": true
}
}
},
"cateL": {
"type": "keyword"
},
"cateS": {
"type": "keyword"
},
"time": {
"type": "date",
"format": "HH:mm"
},
"type": {
"type": "keyword"
},
"currency": {
"type": "keyword"
}
}
}#Ingest pipeline
{
"description": "Ingest pipeline created by text structure finder",
"processors": [
{
"csv": {
"field": "message",
"target_fields": [
"date",
"time",
"type",
"cateL",
"cateS",
"detail",
"amount",
"currency",
"payment_tp",
"memo"
],
"ignore_missing": false
}
},
{
"script": {
"lang": "painless",
"source": "String datetime = ctx['date']+' '+ctx['time']; ctx['datetime'] = datetime;"
}
},
{
"date": {
"field": "datetime",
"timezone": "{{ event.timezone }}",
"formats": [
"yyyy-MM-dd HH:mm"
]
}
},
{
"convert": {
"field": "amount",
"type": "long",
"ignore_missing": true
}
},
{
"remove": {
"field": [
"message",
"datetime"
]
}
}
]
}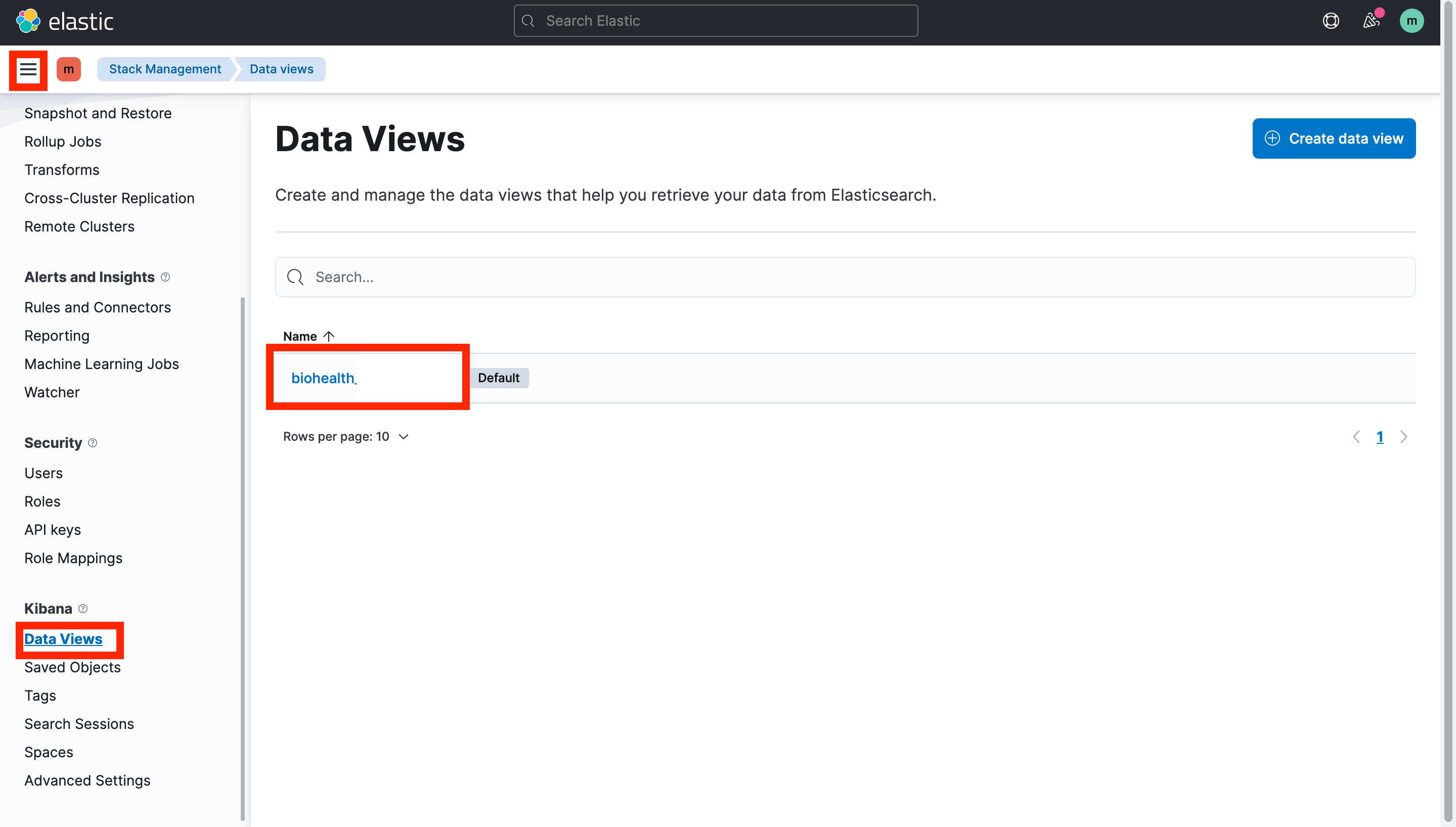 이 과정을 마쳐 성공적으로 데이터가 import 되었다면
이 과정을 마쳐 성공적으로 데이터가 import 되었다면
왼쪽 상단 햄버거 버튼 -> Stack Management > Kibana > Data Views에서 데이터가 잘 업로드 되었는지 확인한다.
step3) 데이터 분석
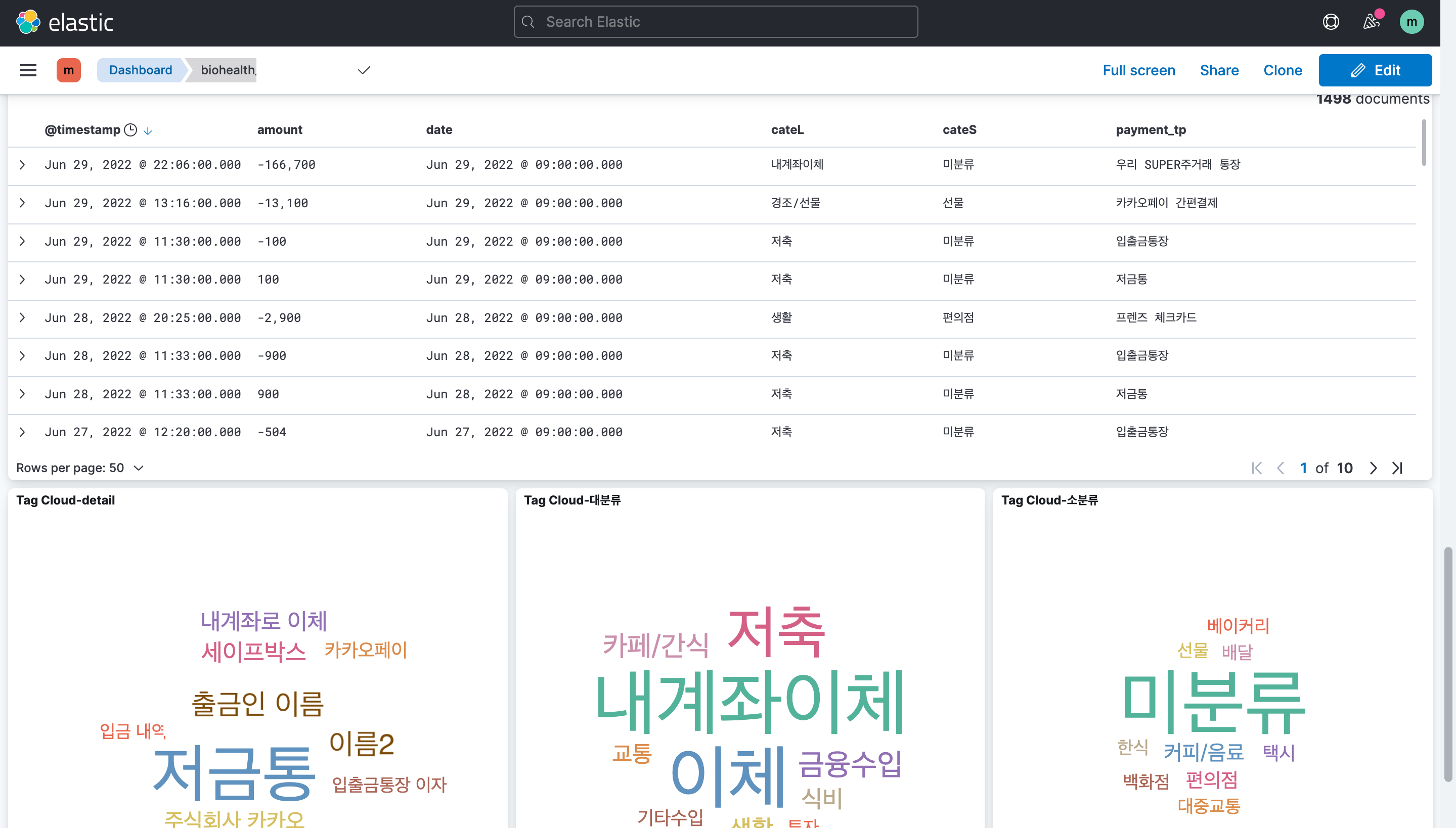
왼쪽 상단 햄버거 버튼 -> Analytics -> Discover
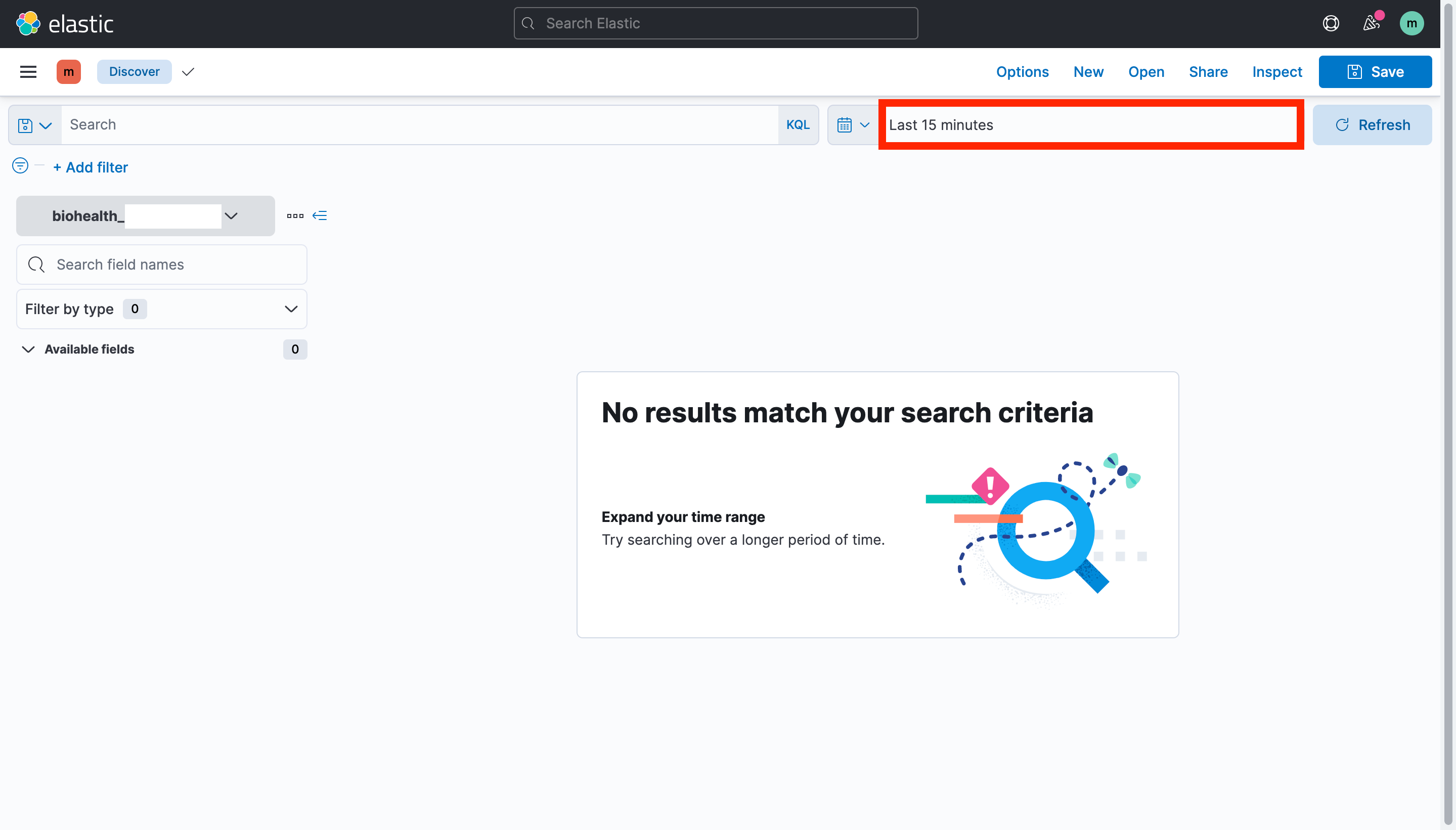 처음에는 기본값으로 '최근 15분 전 데이터'를 검색하기 때문에 이때 거래내력이 없다면 빈 화면이 나타난다. 따라서 시간을 바꿔 데이터를 불러와야 한다.
처음에는 기본값으로 '최근 15분 전 데이터'를 검색하기 때문에 이때 거래내력이 없다면 빈 화면이 나타난다. 따라서 시간을 바꿔 데이터를 불러와야 한다.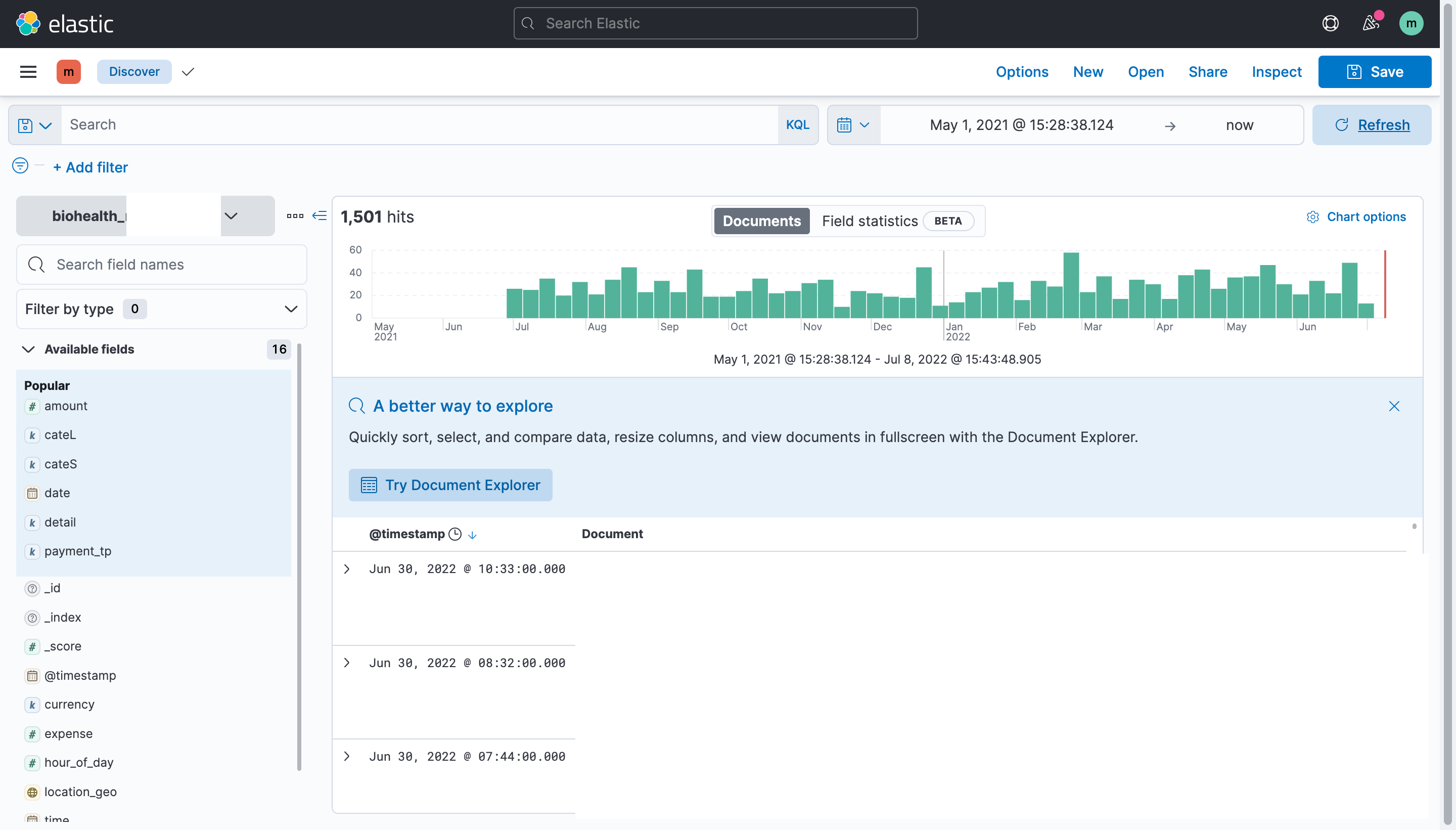 나는 2021년 5월 1일 ~ 현재까지로 구간을 변경했고 시간 설정 후 update를 누르면 구간에 포함된 데이터가 나타나는 것을 볼 수 있다.
나는 2021년 5월 1일 ~ 현재까지로 구간을 변경했고 시간 설정 후 update를 누르면 구간에 포함된 데이터가 나타나는 것을 볼 수 있다.
검색 엔진 기반 데이터 플랫폼으로, 원하는 필드명을 기준으로 데이터를 표시할 수 있다.
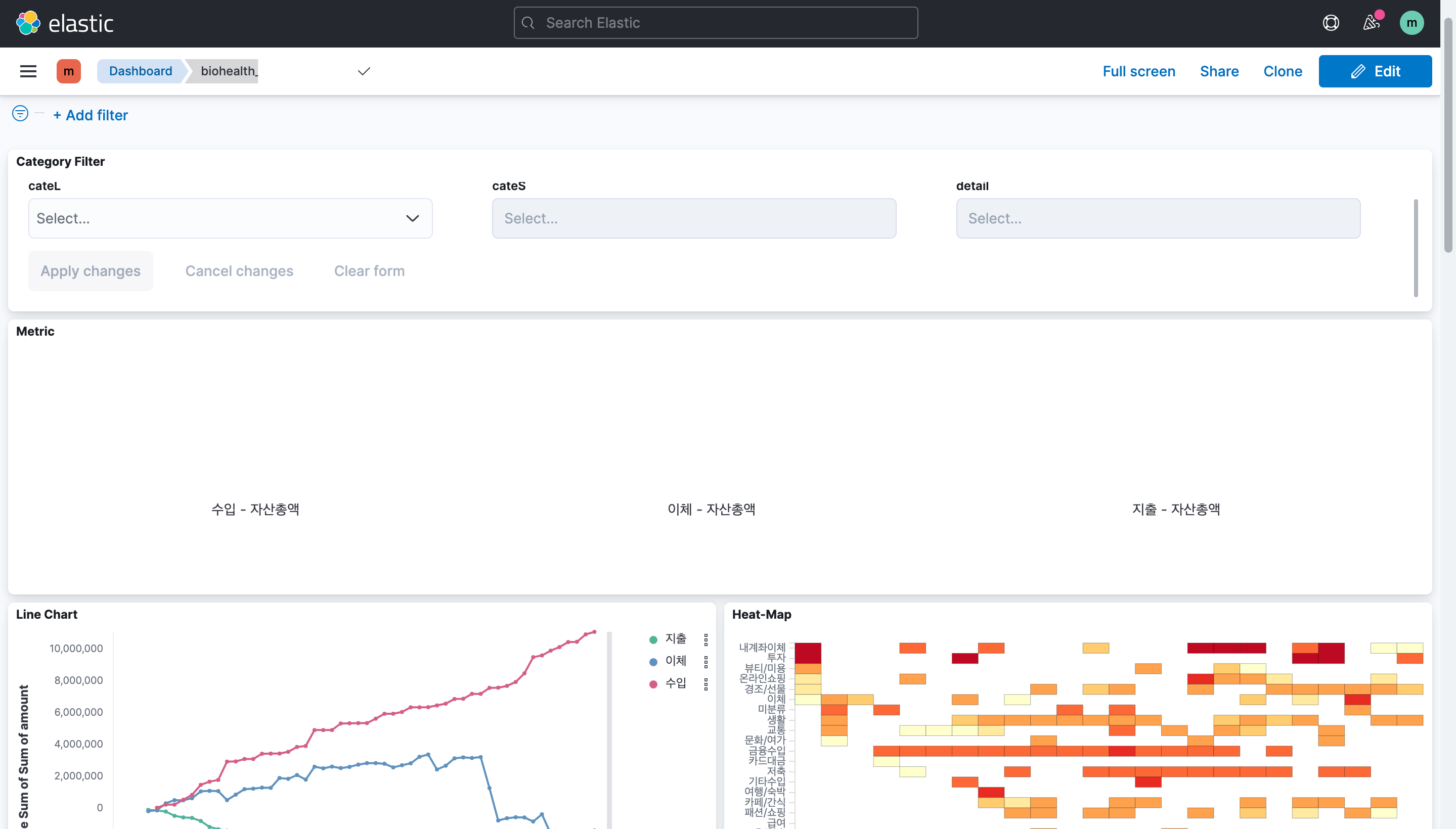
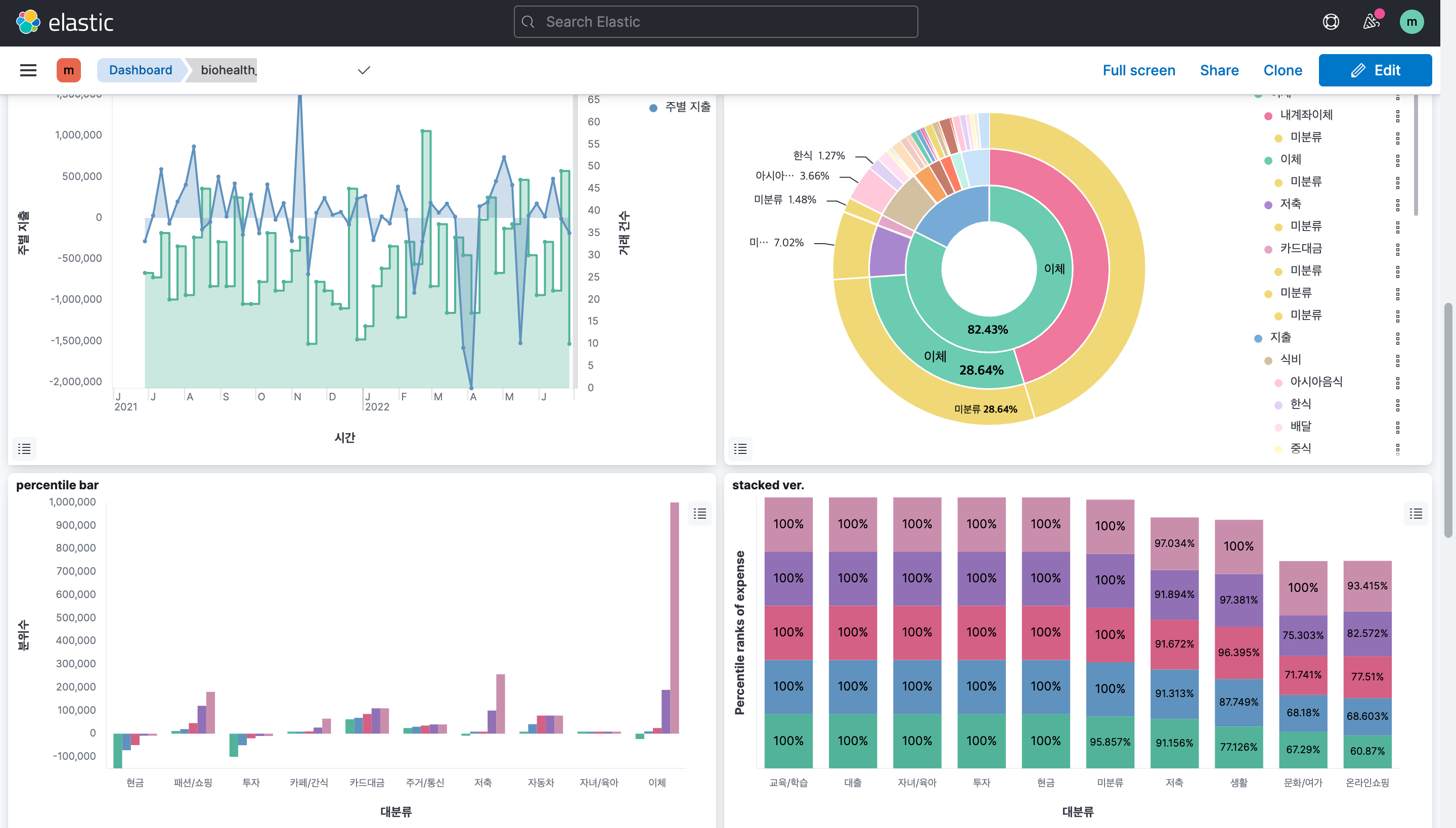
step4) Dashboards 데이터 시각화
왼쪽 상단 햄버거 버튼 -> Analytics -> Dashboards
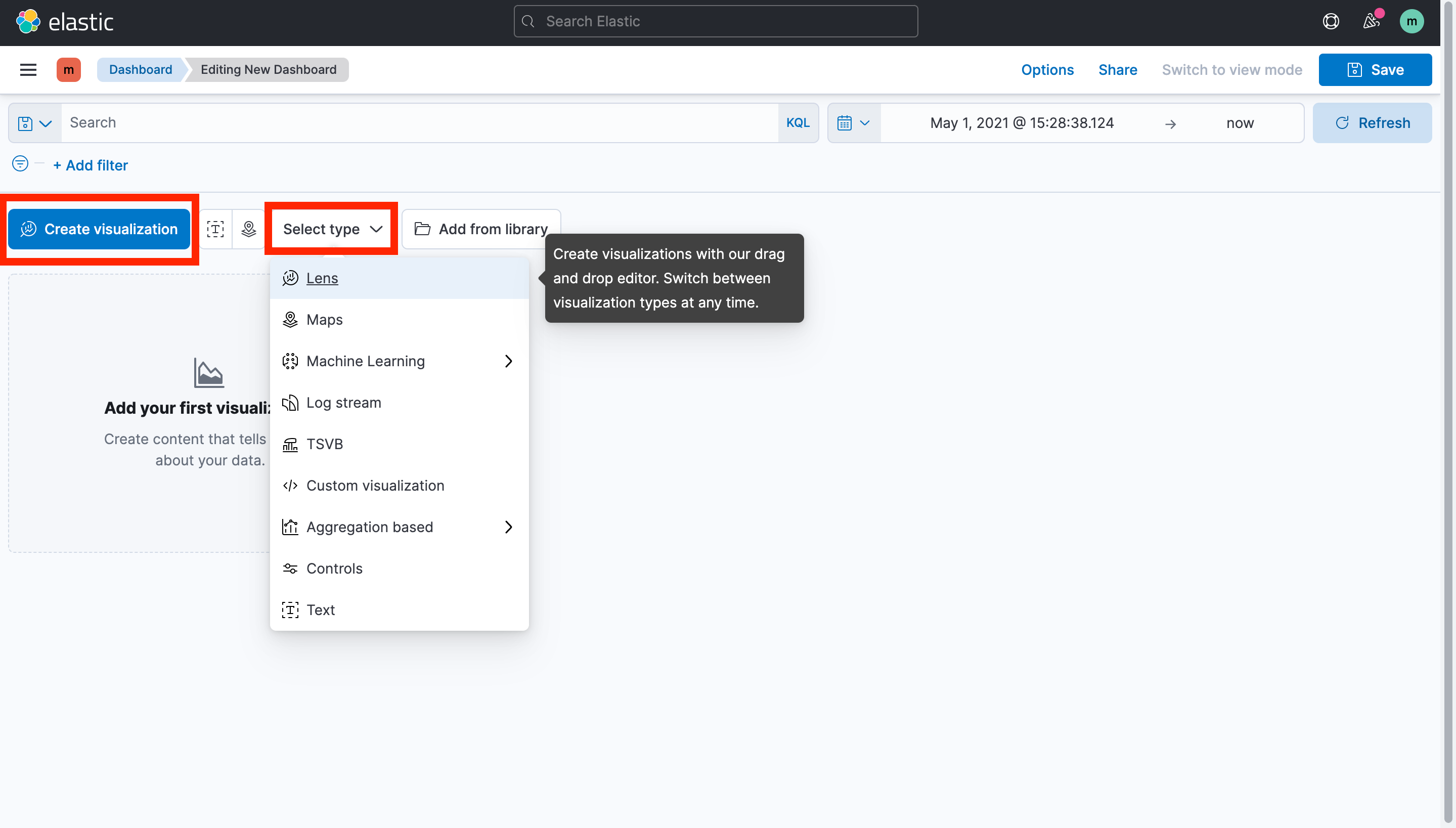
create dashboard를 누르면 빈 화면이 나타나고 여기에 시각화 결과를 저장하게 된다.
- create visualization을 사용하면 bar chart, pie chart 등 입력한 데이터에 적합한 모형을 추천해주기 때문에 간편하게 전반적인 데이터를 나타낼 수 있다.
- Select type에서는 원하는 차트의 모형을 선택해 데이터를 시각화할 수 있다.
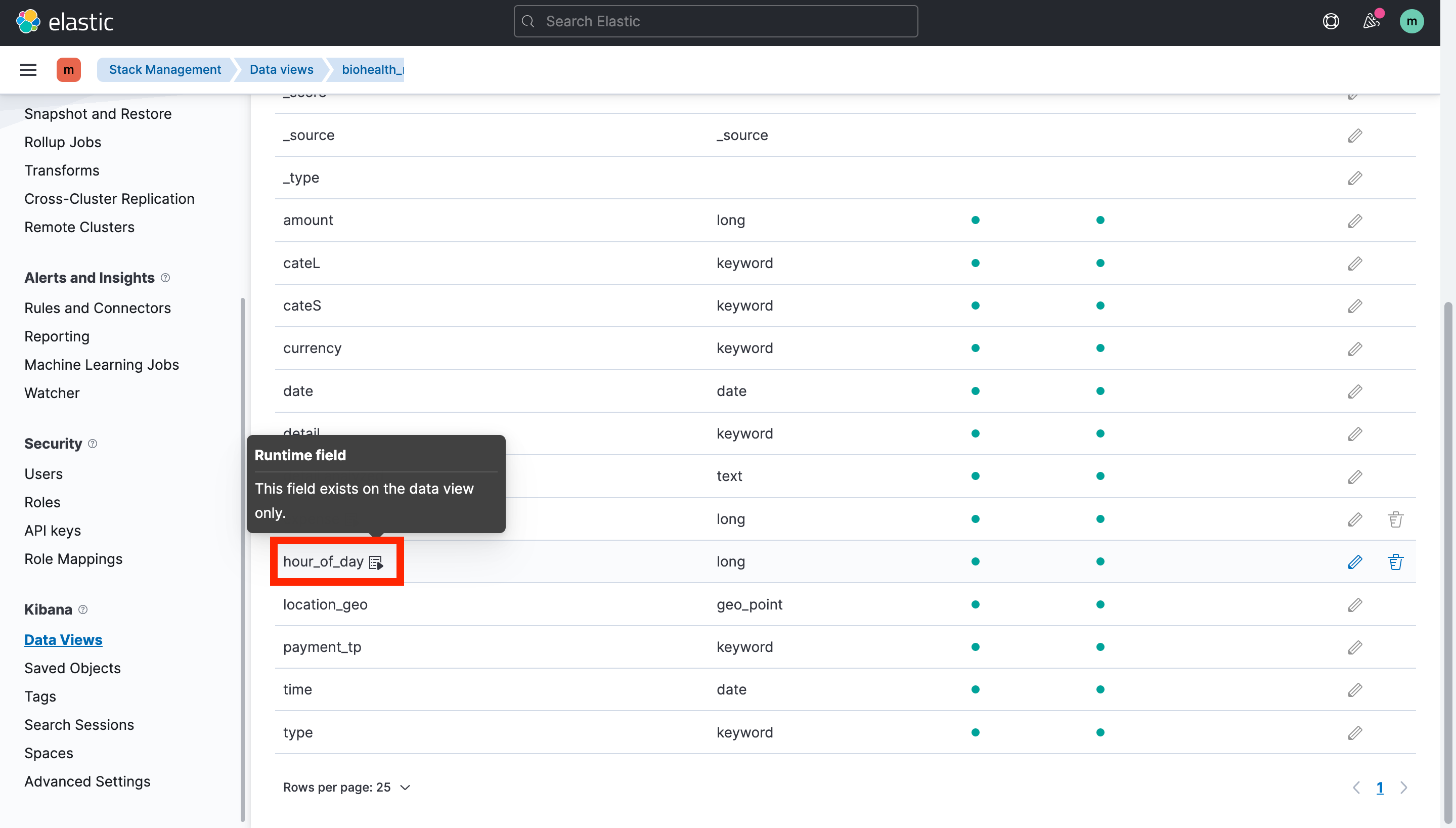 추가적으로 기존 필드 말고도 런타임 필드를 생성해줄 수도 있다.
추가적으로 기존 필드 말고도 런타임 필드를 생성해줄 수도 있다.
왼쪽 상단 햄버거 버튼 -> Stack Management -> Data Views > 내가 업로드한 인덱스 -> + Add field
별도의 코드 없이 새롭게 필드를 추가할 수 있어 편리하지만 데이터의 구간이 바뀔 때마다 필드의 내용도 갱신되는 것을 볼 수 있다. 따라서 런타임 필드를 너무 많이 만들면 성능이 저하될 수 있기 때문에 가능한 미리 데이터를 처리해 필요한 필드들을 만들어두는 것을 권장한다고 한다.
결과 화면