
📍 강의 자료 출처 : LG Aimers
Machine Learning
: Data로부터 내재된 패턴을 학습하는 과정 = Learning from data
예) 스팸 메일 분류, Image Recognition(이미지 분류) 등
크게 supervised learning, unsupervised learning으로 구분할 수 있다.
Supervised learning
: data의 label이 있는 경우
→ 입력 와 출력 의 쌍으로 data set이 이루어져 있고, 이때 를 label이라 한다.
목적 : 에서 로 가게 되는 함수 를 학습하는 것
= 새로운 입력이 들어왔을 때 해당 영상의 category label을 맞추는 함수 를 구하는 것
-
Regression
: 출력이 연속 변수인 경우 -
Classification
: 출력이 이산 변수인 경우
Supervised Learning은 크게 2가지 단계로 나누어 이뤄진다.
Step 1. Training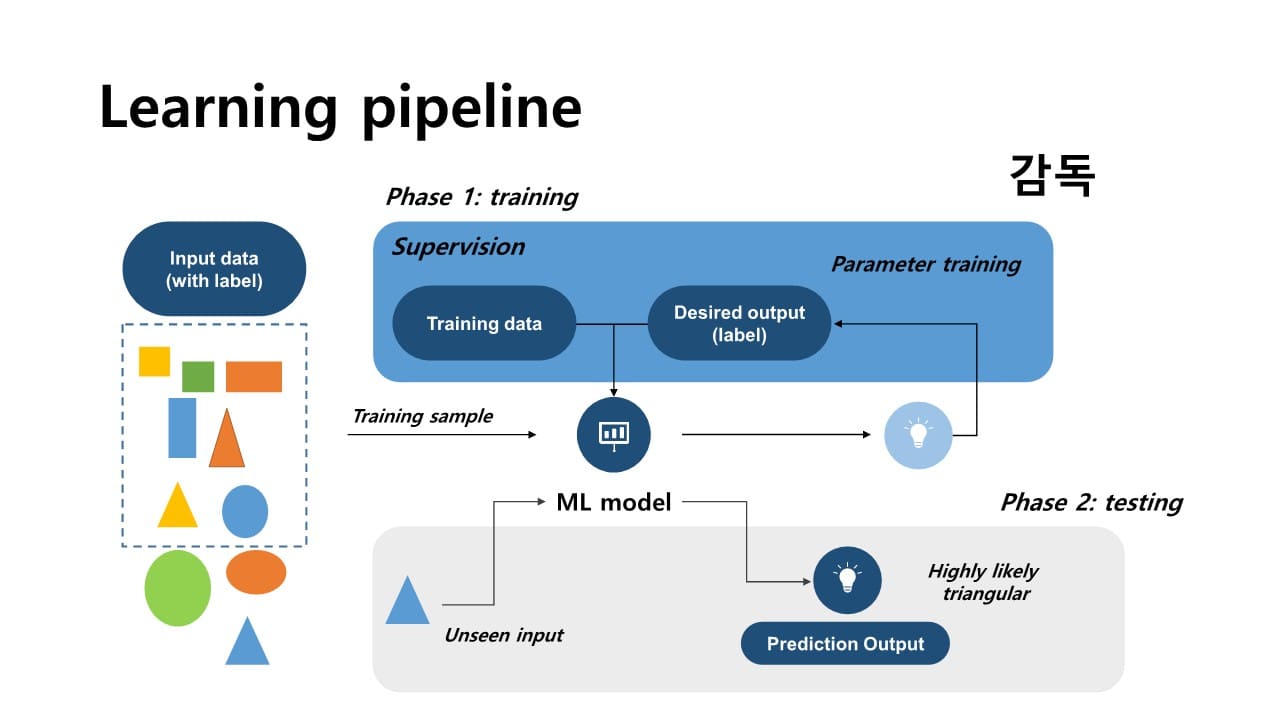
처음에는 model의 출력이 정확하지 않기 때문에 우리가 가지고 있는 data set의 label, 즉 정답으로부터 ML model이 정답을 정확하게 찾을 수 있도록 학습시키는 과정
model의 파라미터값을 변경해가면서 model의 정확도를 향상시킨다.
→ model의 output과 정답과의 차이인 error를 통해서 그 error를 줄여가는 방향으로 학습이 이루어진다.
Step 2. Test
model이 실제 환경에 적용되는 것으로, training 단계에서 사용하지 않은 새로운 input을 이용한다.
+) feature는 풀고자 하는 문제에 관하여 어느 정도의 domain knowledge를 알고 있어야 사용할 수 있다.
→ classification에 효과적인 feature를 도입하기 위해서는 해당 주제에 대한 사전 지식을 갖추고 있어야 한다.
cf> 최근 Deep learning의 경우, 이러한 feature도 스스로 학습할 수 있게 되어 domain knowledge로부터 비교적 자유로워졌다.
Target function
: 입력 를 target 로 mapping하게 되는 정답 함수로, 달성하기 어려운 이상적인 함수
존재하는 모든 입력 샘플에 대한 관찰이 있어야 함 & 모델이 모든 샘플에 대해 정답이어야 함
→ target function 에 근접한 함수를 만들자 = hypothesis H
Training 과정
1. feature selection
2. model selection
: 풀고자 하는 문제에 가장 적합한 model을 선택하는 과정
3. optimization
: model parameter을 최적화하여 model이 가장 우수한 성능을 제공하도록 하는 과정
Machine Learning 학습 과정에서 모든 data sample들을 관찰할 수는 없기 때문에 ML은 그 자체로 Data의 결핍으로 인한 불확실성을 포함하고 있다.
→ ML 학습 과정에서 가장 중요한 것 중 하나는 Generalization(일반화)
Generalization
: model이 학습 과정에서 우리가 관찰하지 못한 sample에 대해서도 우수한 성능을 제공할 수 있도록 함
이러한 성능을 측정하는 지표로 generalization error 를 정의한다.
→ 목표 : 를 최소화하는 것
하지만 이것은 이상적인 함수로, 이 error function을 최소화할 수는 없기 때문에 Supervised Learning에서는 training error, validation error, test error를 통해 generalization error를 최소화하도록 노력한다.
Errors
각 sample별로 pointwise로 계산한다.
예) binary error, squared error

는 model의 출력이고, 는 정답을 의미힌다.
최종적으로는 data sample에서 발생하는 모든 sample들의 pointwise error를 합쳐서 overall error를 계산한다.
이때 이 overall error를 손실함수 loss function( = cost function)이라 한다.
- : model을 주어진 data set에 맞추어 학습하는 데 사용하는 error
→ 주어진 sample에서 model parameter를 최적화 하도록 사용하기 때문에 을 근사화하는 데 적합하지 않다. - : model이 real world에서 적용될 때 나타나는 generalization error를 표현한다.
→ 목표 : 가 0에 근사하도록 하여 또한 0으로 근사하도록 함.
= ≈ ≈ 0
아래 2가지 단계를 거쳐, " ≈ ≈ 0"을 수행한다.
1. 가 가 가까워지도록 학습시키기
분산이 작게끔 학습시키는 방법으로, regularization 혹은more data를 통해 이루어진다.
cf> overfitting = high variance
2. 이 0에 가까워지도록 학습시키기
편차가 낮아지도록 학습시켜 모델의 정확도를 향상시키는 방법으로, optimization 혹은 more complex model을 통해 이루어진다.
cf> underfitting = high bias
bais와 variance의 Trade off 관계
model의 정확도 ↑ = bias ↓ = model 일반성 ↑ = variance ↓→ 목표 : trade off를 적절히 조절하여 generalization error를 최소화하는 것
cf> 오늘날 모델의 복잡도 증가 속도는 매우 빠르게 증가하는 반면, Data set sample 수를 늘리는 것은 한계가 있기 때문에 Overfitting 문제가 더 많이 나타난다.
= Curse of dimension
- Training data set : 학습
- Validation data set : 최적화
- Test data set : 성능 평가


