
📍 강의 자료 출처 : LG Aimers
Supervised Learning의 한 종류로, model의 출력이 연속적인 값을 갖는 경우이다.
입력 변수의 개수에 따라, Univariate problem / Multivariate problem으로 구분할 수 있다.
Linear Model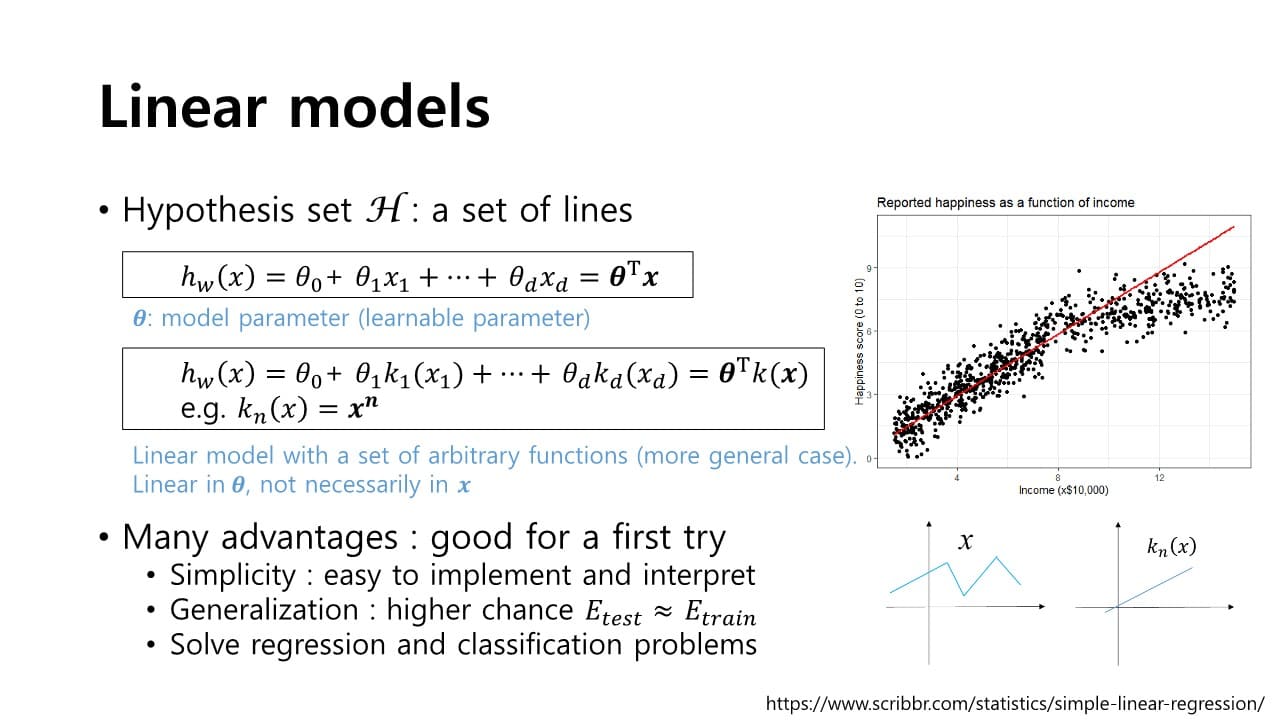
: Hypothesis 가 입력 feature와 model parameter의 linear combination으로 구성되는 모델
이때, 선형 모델이라고 해서 반드시 입력 변수도 선형일 필요는 없다.
에 대해서는 선형 함수가 아니더라도 model parameter 와 결합해 는 선형 함수가 될 수 있다.
예) 입력 으로 메일 주소를 받은 경우, 를 그대로 활용하는 것이 아니라 로부터 feature(메일의 길이, 특정한 기호를 가지는지 등)를 뽑을 수 있다.
- 장점
- 단순하다.
→ 성능 측정이 쉽다 - 입력 변수가 출력에 어느 정도 영향을 주는지 해석할 수 있다.
- 일반화
→ model이 단순하기 때문에 성능이 아주 높지는 않더라도 다양한 환경에서 안정적인 성능을 제공할 수 있다.
- 단순하다.
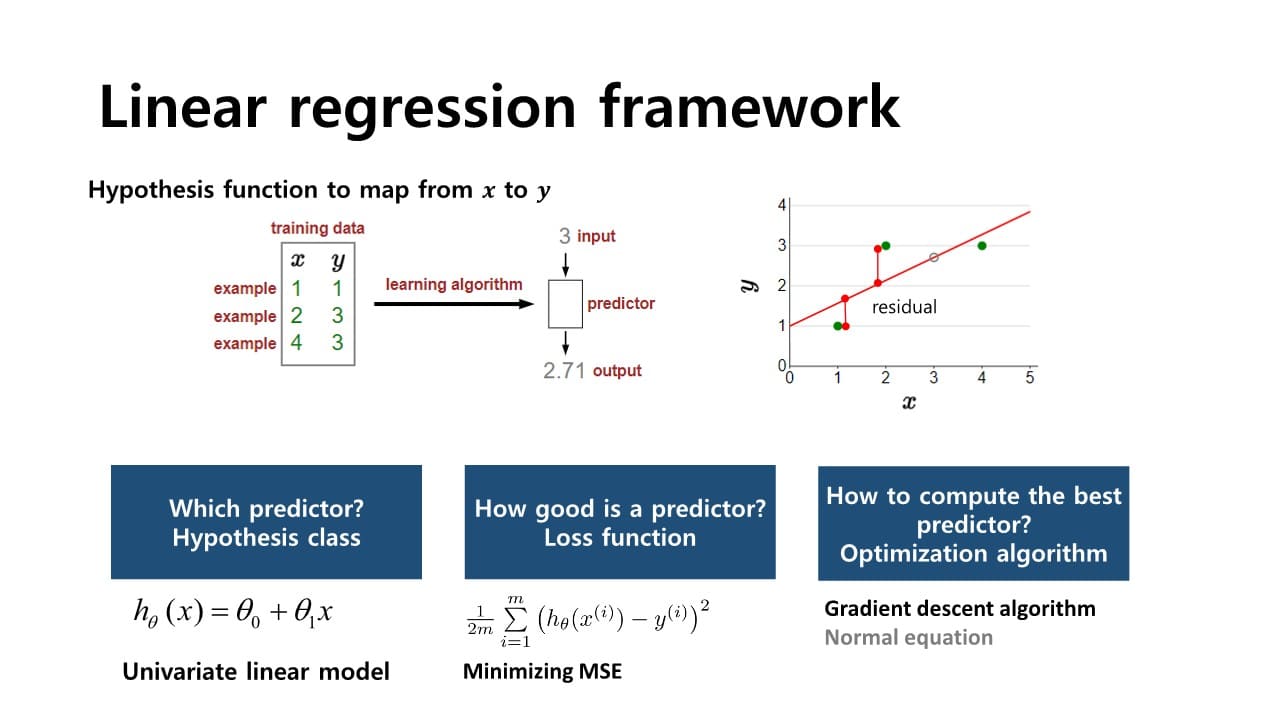
Linear regression
: 주어진 입력에 대해 출력과의 선형적인 관계를 추론하는 문제
linear model에서는 loss를 측정하기 위해 보통 MSE(Mean Squared Error)를 활용하고, Gradient descent나 Normal Equation을 이용해 parameter를 얻는다.
Loss function은 parameter 에 따라 값이 바뀐다.
→ 목표 : Loss function을 최소화하는 찾기
Parameter Optimization ; 파라미터 최적화
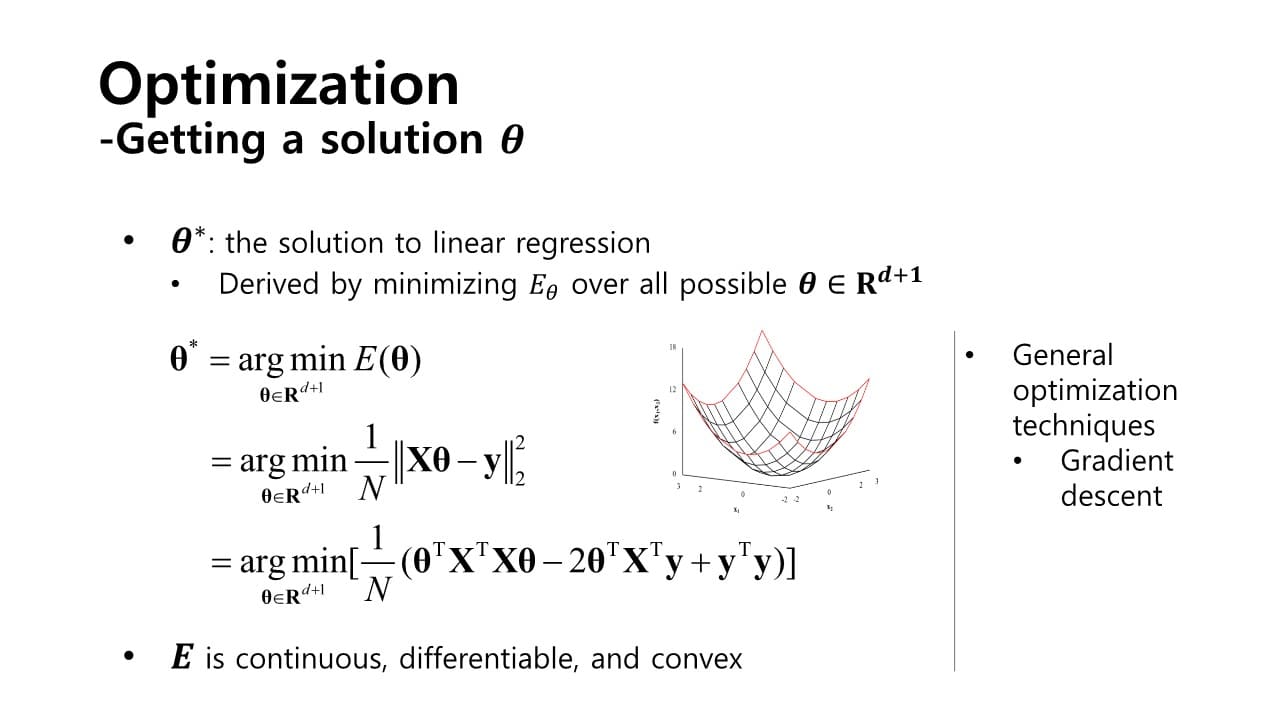
= 어떻게 , 을 구할 수 있을까?
→ cost function을 가장 최소화하는 것
cf> 가정 : loss function이 미분 가능하고 볼록해야 한다.
1. Normal equation

normal equation으로 해()를 구하는 경우, one-step으로 간단하게 값을 계산할 수 있다는 장점이 있지만
요즘처럼 Data의 샘플 숫자(n)가 늘어나는 경우에는 비효율적이다.
matrix의 dimension이 늘어나서 inverse 계산에 큰 복잡도가 소요됨
→ solution : Gradient descent
2. Gradient Descent


: iterative하게 최적 parameter 를 찾아가는 과정
gradient : 함수를 미분하여 얻은 term으로, 해당 함수의 변화하는 정도를 표현하는 값
목표 : 임의의 점에서 출발하여 loss function의 error surface를 따라 값이 최소인 지점, 즉 gradient = 0인 지점 찾기
→ 함수의 변화도(gradient)가 가장 큰 방향으로 이동
: step size를 나타내는 hyperparameter. 너무 작으면 수렴 속도가 너무 느리고, 너무 크면 최저점을 지나쳐 수렴하지 못할 수 있기 때문에 적절한 값으로 설정해줘야 한다.
(항상 > 0)
cf> : learnable parameter
Greedy algorithm의 특성 때문에 Gradient descent algorithm은 경우에 따라 Local optimum만을 달성하기 쉽다.
- Global optimum vs. Local optimum
Global optimum : 전체 error surface에서 가장 최소인 값을 갖는 지점
Local optimum : 지역적으로 최소이지만 전체 영역을 놓고 보았을 때는 최소가 아닐 수 있는 지점
- Normal equation vs. Gradient descent
- Gradient descent
: 여러 번의 반복적인 과정을 수행하여 해를 얻어 나간다.
: sample의 크기가 크더라도 반복적으로 해를 구해 나갈 수 있다. - Normal equation
: 한 번에 1 step으로 해를 구한다.
: sample의 크기가 커지면 inverse matrix를 계산하기 어렵다.
- Gradient descent
