Module 4. 『딥러닝(Deep Learning)』 4. Seq2Seq with Attention for Natural Language Understanding and Generation
LG Aimers

📍 강의 자료 출처 : LG Aimers
4. seq2seq with attention 모델 및 이를 통한 자연어 이해 및 생성
RNN (Recurrent Neural Networks)
: sequence data에 특화된 형태를 띄며 동일한 function을 반복적으로 호출하는 방식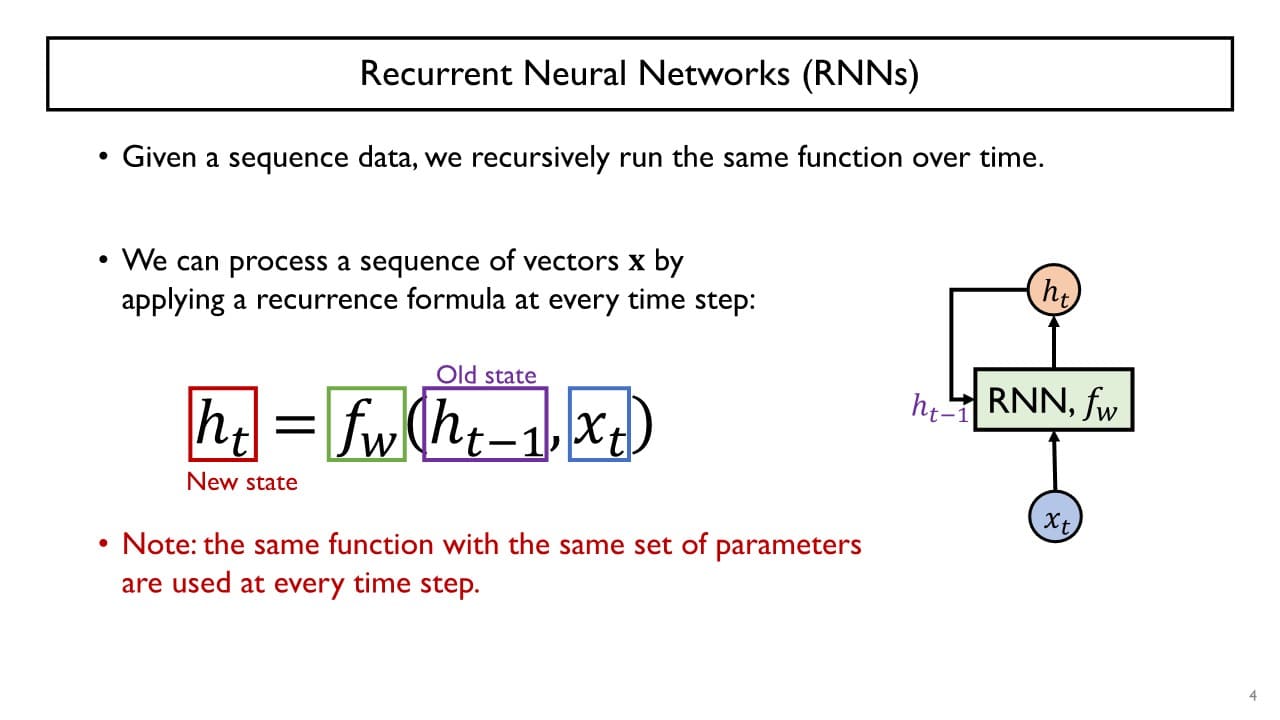
 현재 시점에서의 데이터 와 Hidden state vector 을 입력으로 받아 current hidden state vector인 를 만든다.
현재 시점에서의 데이터 와 Hidden state vector 을 입력으로 받아 current hidden state vector인 를 만든다.
→ 매 time step마다 동일한 function 즉, 동일한 parameter set을 가지는 layer가 반복적으로 수행된다.
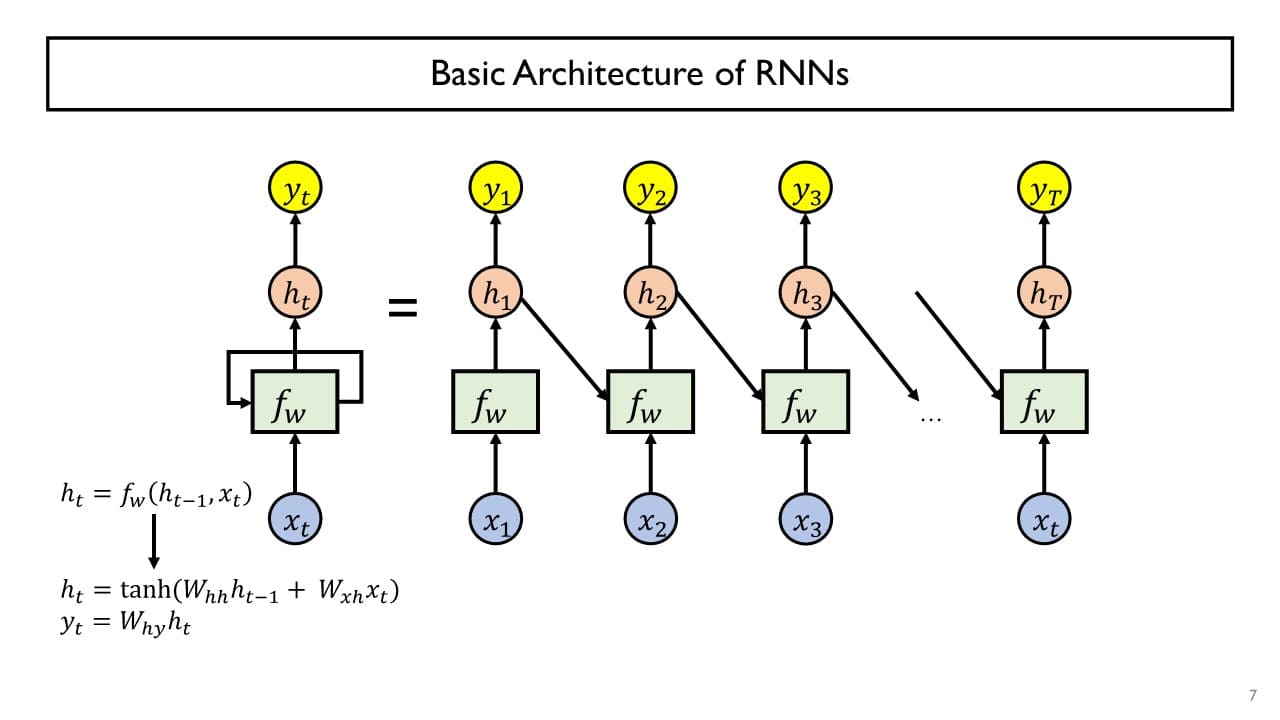
RNN의 현재 time step의 출력인 를 선형변환한 후 다시 입력으로 output layer에 전달함으로써 최종 예측 결과를 만든다.
cf> multi-class classification : 최종 결과에 softmax 적용하여 확률 vector 얻기
+) RNN에서는 주로 활성함수로 를 사용한다.
+) (현재 time step의 hidden state vector의 크기) 의 크기
최초의 time step 에 대해서는 이 존재하지 않는데, (혹은 ) 자리에 0 vector를 입력으로 주면 된다.
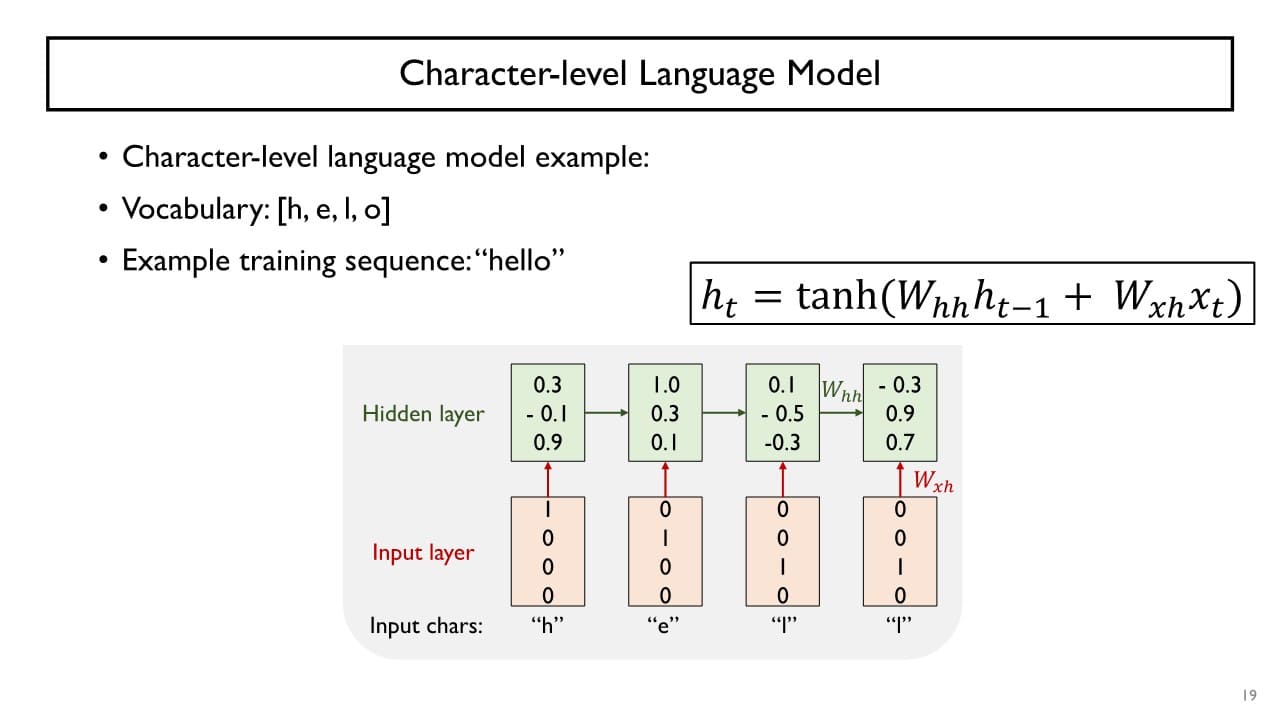
trainable한 parameter로 , , 를 경사하강법을 통해 학습한다.
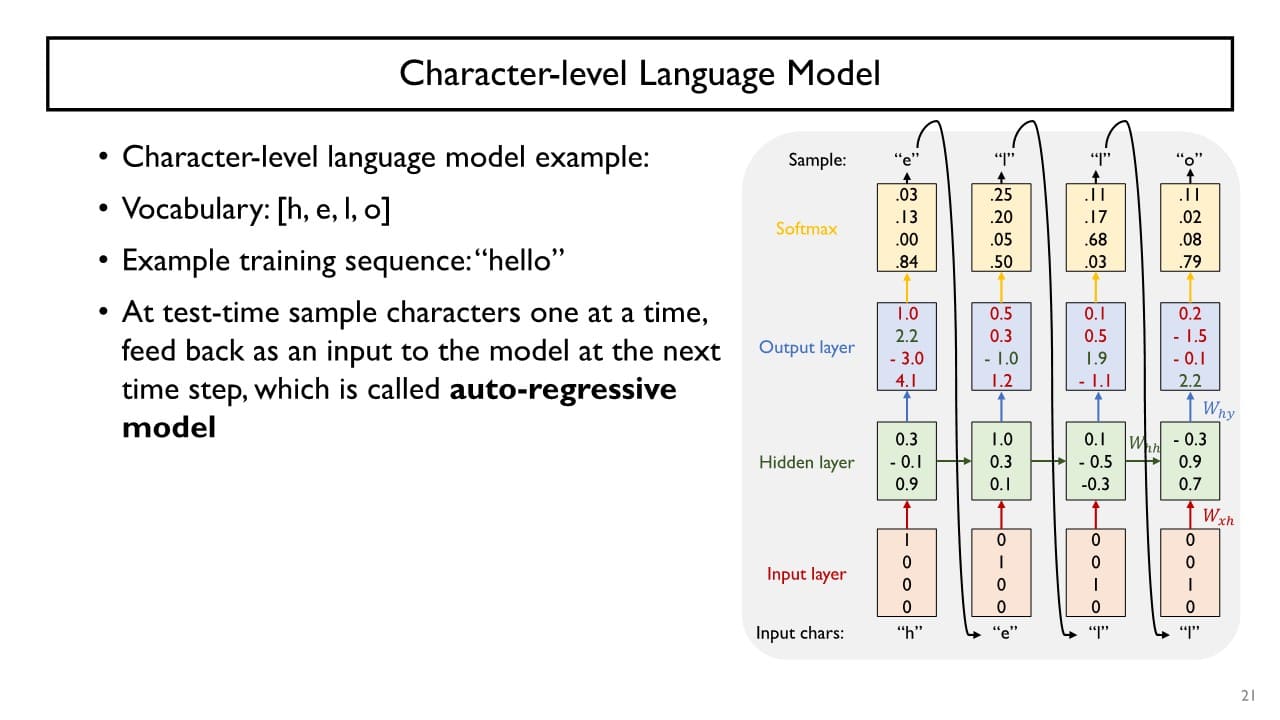
Auto regressive model
: sequence model에서 이전 time step에서 예측한 결과가 그다음 time step에 입력으로 주어지는 경우의 예측 모델
RNN-based Sequence Modeling의 다양한 형태
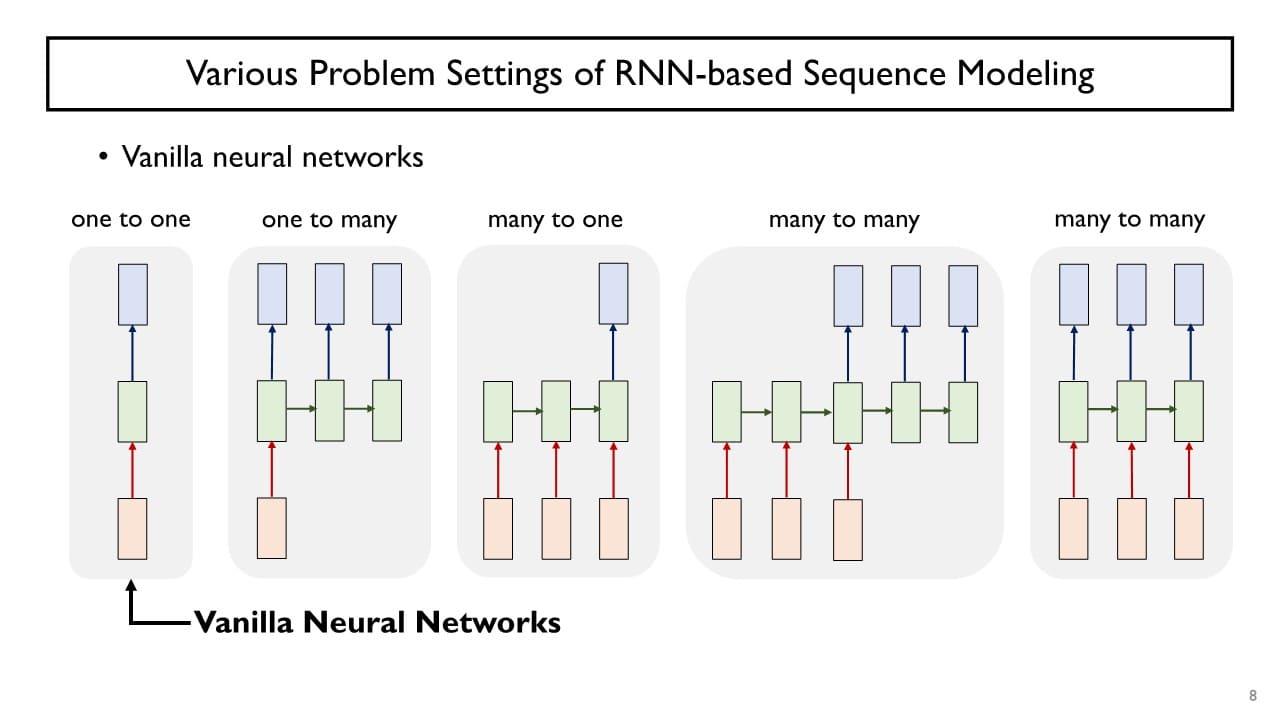
-
one-to-one(= Vanilla Neural Network)
: time step의 개념이 없고 한 번에 하나의 데이터를 독립적으로 입력 받아 그때그때 해당 예측 결과를 나타냄
vanilla RNN 구조를 사용했을 때 학습 과정 중에 gradient가 vanishing 되거나 / 폭발적으로 늘어나 학습이 불안정해지는 부작용이 종종 일어난다.
→ 이러한 문제를 극복하기 위해 LSTM, GRU라는 특정한 구조의 RNN 모델을 주로 사용한다. -
one-to-many
: 입력은 최초의 time step에 전체가 모두 주어지고 출력 결과물은 여러 time step에 걸쳐서 순차적으로 예측 결과를 생성함
예) Image captioning : 하나의 이미지가 입력됐을 때 그 이미지를 설명하는 텍스트 워드들을 예측 -
many-to-one
: 입력이 sequence 형태로 주어지되 예측 결과물을 만들 때는 최종적인 time-step에서 단일한 예측 결과를 생성함
예) 문장 분류, Sentiment Classification -
many-to-many
: 입력과 출력이 모두 sequence인 경우
예) Machine Translation(입력 문장의 마지막 단어까지 순차적으로 입력 받은 후 출력 문장의 단어를 하나씩 예측), Video Classification in Frame Level(입력이 sequence로 주어지는 과정 중에 실시간으로 바로 예측 결과 생성)
Seq2seq Model
: many-to-many 중 delay를 허용하는 경우
예) 챗봇
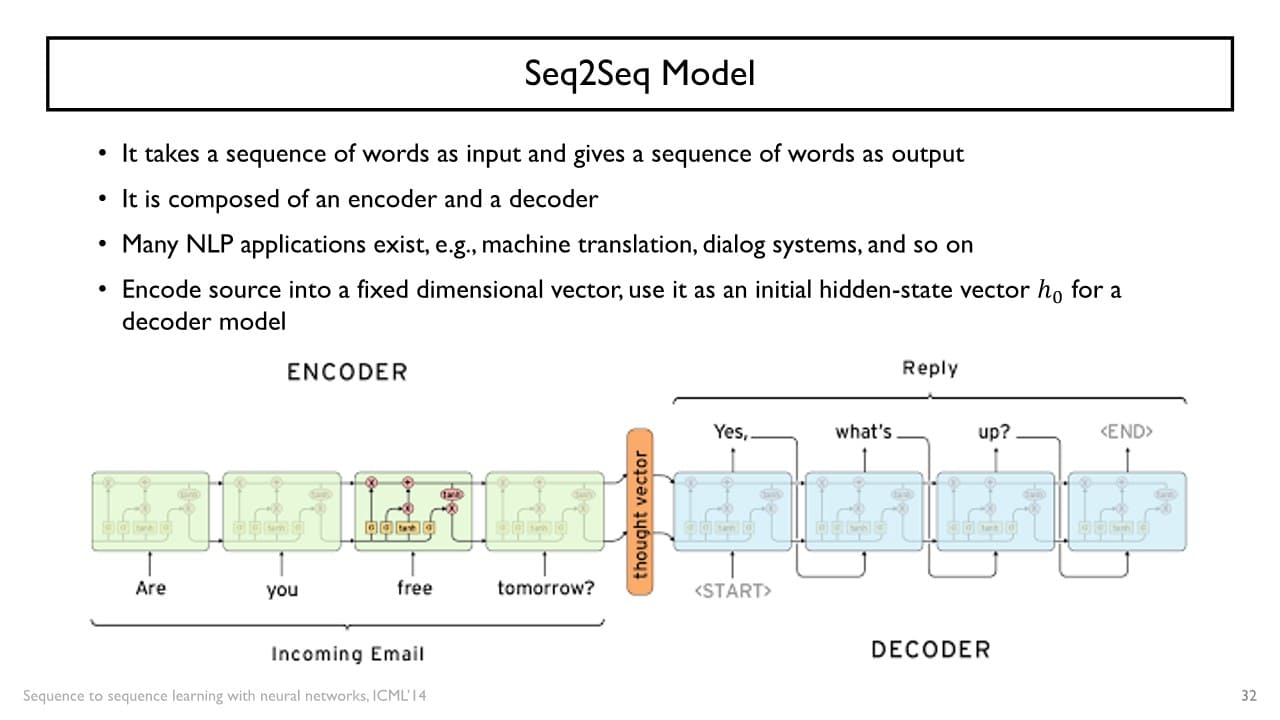
Encoder
: 입력 sequence 중 필요한 정보를 추출하는 과정
: 주어진 입력 데이터를 모두 축적한 vector으로, Encoder의 가 Decoder의 로 사용된다.
Decoder
: 를 이용하여 특정 단어들의 sequence로 이루어진 하나의 sequence를 출력하는 과정
출력하고자 하는 문장의 최초의 단어를 start of sentence라는 특수 단어를 입력으로 주고 '단어 생성이 끝났다'라는 end of sentence token이 예측될 때까지 차례대로 다음 단어들을 생성해나간다.
+) encoder와 decoder에 쓰이는 parameter들은 서로 공유되지 않고 2개의 독립적인 RNN 모델을 사용하는 경우가 일반적이다.
- RNN 모델의 제약 조건
입력 sequence가 짧든 길든 매 time step마다 생성되는 hidden state vector , , ...는 같은 dimension으로 이루어져 있어야 한다.
이전 단계에서의 output vector를 다시 입력 vector로 사용하기 위해
시간이 축적됨에 따라 정보는 많아짐에도 불구하고 항상 똑같은 개수의 vector에 욱여담아야 한다.
→ sequence가 길어질 때 정보를 유실하거나 output sequence가 제대로 생성되지 않는 문제가 발생할 수 있다.
이를 해결하기 위해 Attention이라는 추가적인 module을 도입하였다.
Attention
핵심 : 입력 데이터에 대해 차례대로 encoding 후 Decoder의 입력으로
Encoder의 마지막 time stamp의 hidden-state vector만 받기 (X)
위와 더불어 Decoder의 각 tiem step에서 Encoder에서 나온 여러 단어별 encoding 된 hidden-state vector 중 필요로 하는 vector들도 예측에 직접적으로 활용 (O)
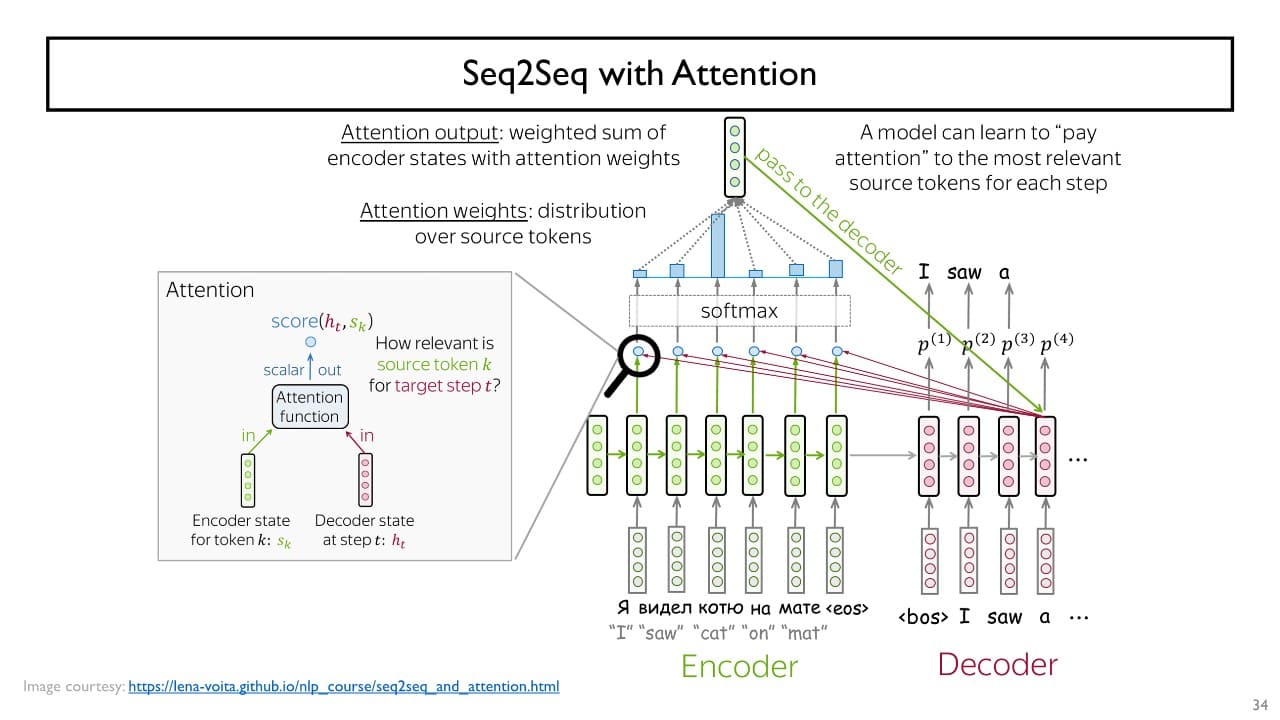
-
초록 vector와 각각의 빨강 vector와의 내적을 통해 유사도를 구하고
내적값(유사도)가 클수록 현재 time step에서 필요로 하는(= 관련성이 높은) 정보라고 학습을 진행한다. -
내적값을 softmax에 통과시켜 확률 vector를 얻고 이 vector를 Encoder의 hidden state vector의 가중치로 사용한다.
-
encoder state vector의 가중합을 구한다.
-
가중합이 가장 큰 encoder state vector를 Decoder의 output layer에 추가적인 입력으로 사용한다,
⇒ 다음에 나타날 단어 예측
Attention을 포함함으로써 각 time step에서 어떤 패턴을 보이는가 분석할 수 있다.
+) 서로 다른 언어 간 어순이나 단어들간의 다양한 매칭 관계를 잘 파악할 수 있다.
