
📍 강의 자료 출처 : LG Aimers
5. Transformer 모델의 동작 원리
overview
- seq2seq model
: encoder, decoder와 각 time step으로부터 encoder의 hidden state vector들 중 원하는 정보를 그때그때 가져갈 수 있도록 하는 추가적인 attention module로 구성된 RNN 기반 모델
Transformer
: RNN이나 CNN 없이 attention module만으로 전체 sequence를 입력 및 출력으로 처리할 수 있는 모델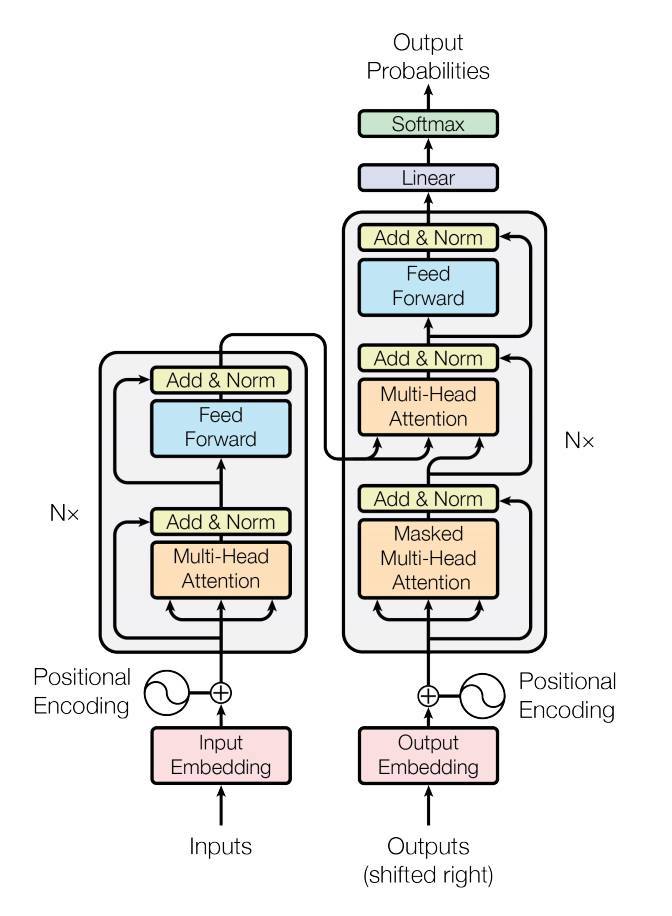
Seq2seq model의 한계
- Long-term dependecy
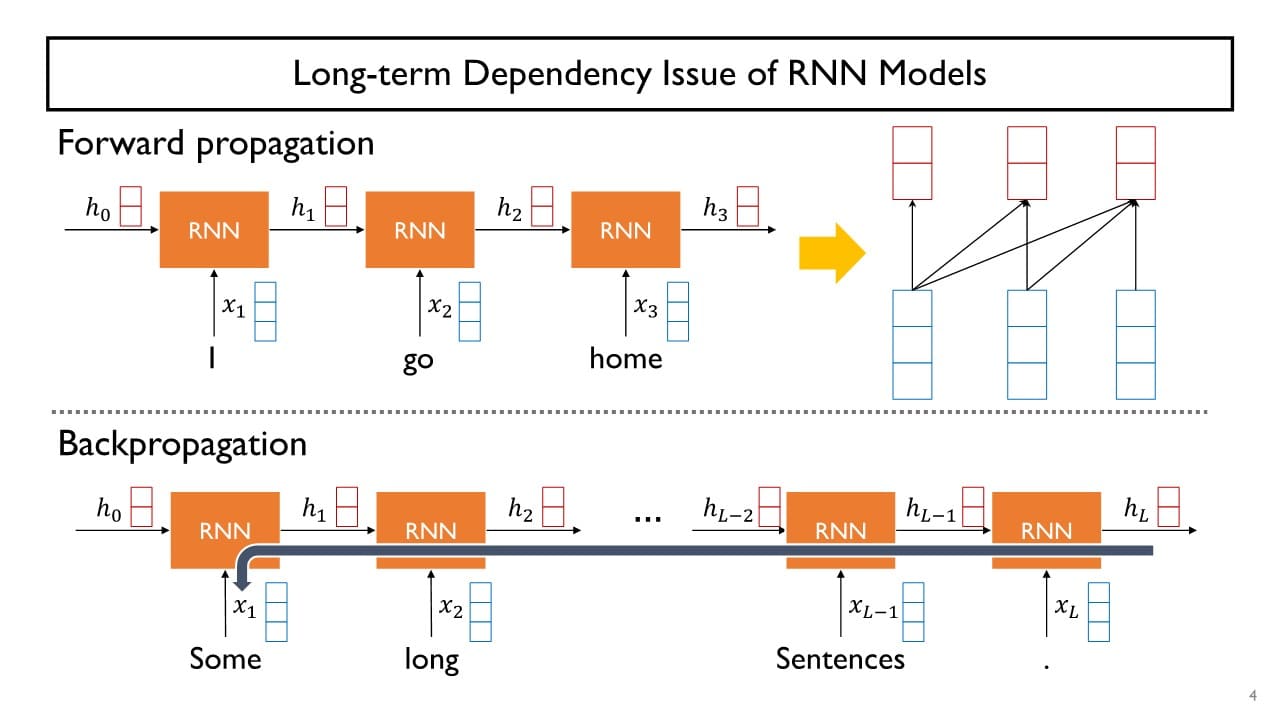
 → Transformer에서는 각각의 단어들이 쿼리로 사용돼서
→ Transformer에서는 각각의 단어들이 쿼리로 사용돼서
전체 sequence에 존재하는 각 단어들의 직접적인 유사도를 구하고, 유사도가 높은 단어의 time step 간 차이(= 입력 시차)에 관계없이 원하는 정보를 직접적으로 꺼내갈 수 있다.
1. Transformer를 활용한 Encoding
- 기존 Seq2seq 모델
정보를 찾고자 하는 질의어 혹은 쿼리에 해당하는 정보 = 특정 time step의 decoder의 hidden state vector
→ encoder hidden state vector와의 내적을 통해 유사도를 구하고
거기에 softmax를 취해 나온 가중치를 다시 encoder hidden state vector에 반영해줌으로써 encoder hidden state vector의 가중합을
attention model의 결과값으로 주는 방식
⇒ '정보를 찾고자 하는 쿼리'에 해당하는 decoder hidden state vector는 '정보를 꺼내가려고 하는 재료 정보'인 encoder hidden state vector들과는 분리된 형태였다.
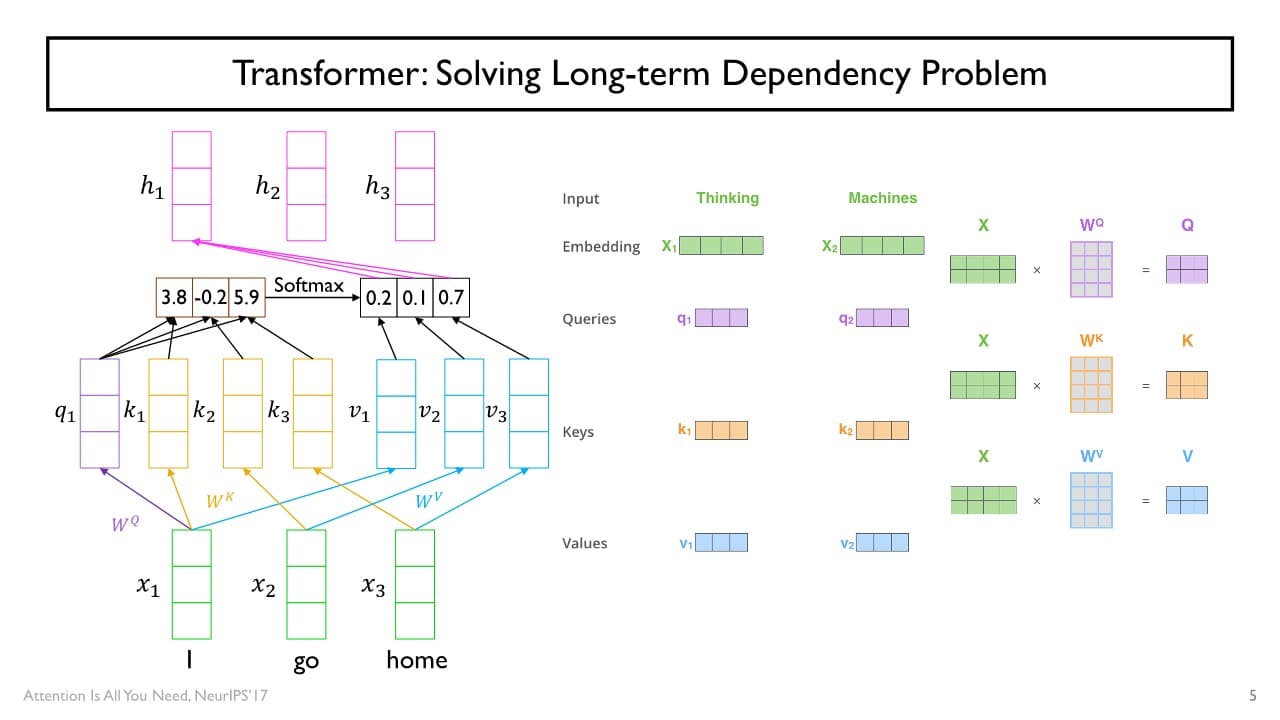
⇒ Self-attention
: 정보를 찾고자 하는 주체 혹은 query vector를 정보를 꺼내가려는 재료 vector들과 같은 주체로 생각해, 주어진 sequence를 attention model을 통해 encoding하는 방식
= 입력 vector들을 정보를 찾고자 하는 쿼리로 취급하여 encoding을 진행한다.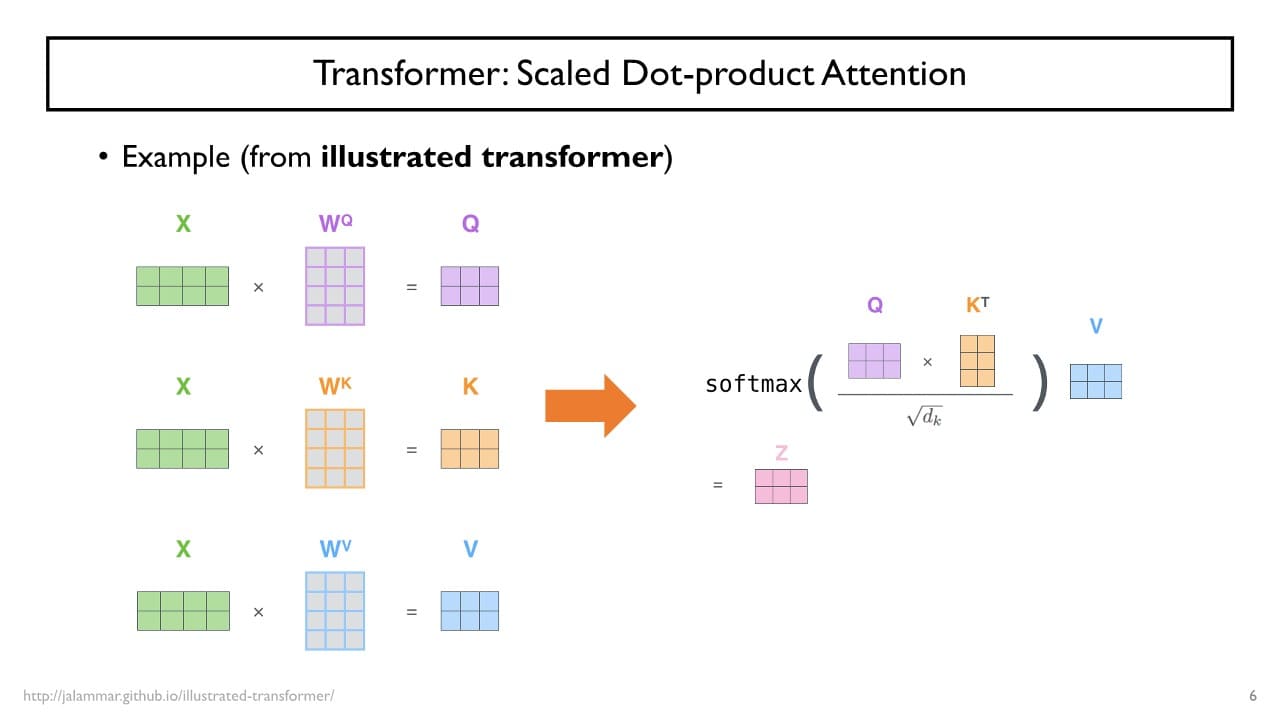
각각의 입력 vector는
1. query
2. 재료 vector로서 유사도 계산에 사용되는 vector로서의 key
3. key vector들과 짝을 이뤄 실제 유사도가 적용된(가중치가 적용된 혹은 가중평균에 사용되는) value vector
세 가지의 다른 용도로서 같은 vector set이 사용된다.
- query로 사용될 때
vector 원형이 아닌 선형변환한 를 query vector로 사용한다. - key로 사용될 때
vector 원형이 아닌 선형변환한 를 key vector로 사용한다. - value vector로 사용될 때
vector 원형이 아닌 선형변환한 를 value vector로 사용한다.
Scaled Dot-product Attention (로 나누는 이유)
: key vector의 dimension = 의 세로 = 의 가로
→ 가 커질수록 더 많은 개수의 숫자들의 합을 의미하고, 고차원 vector의 내적값은 더 큰 분산을 갖는다.
vector의 내적값이 softmax의 입력으로 사용되는데, softmax는 입력이 클수록 더 큰 값에 mapping을 시켜주기 때문에( 지수함수) 전체 확률 분포가 하나의 값에 거의 100%에 가까운 확률이 할당된다. (= 하나의 단일한 픽을 가지는 attention weight 생성)
= gradient가 잘 흐르지 않아 학습이 원활하게 이루어지지 않는 문제가 발생한다.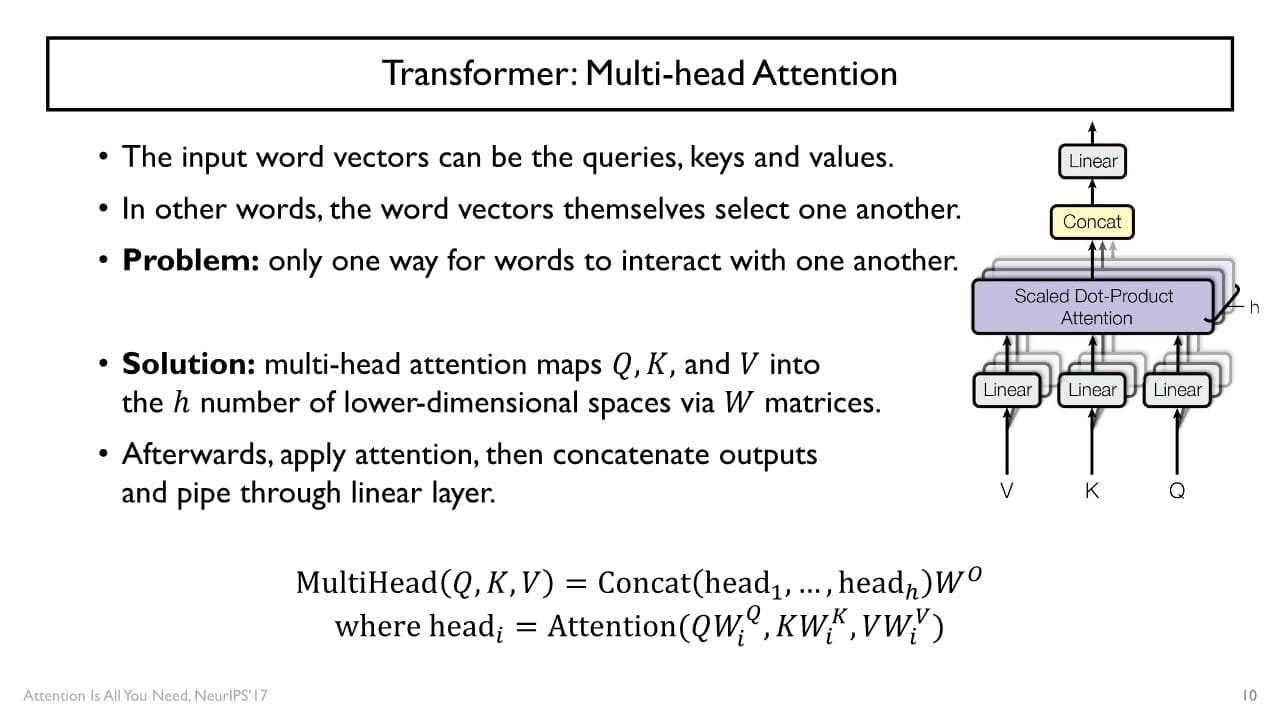
Multi-head Attention
: 여러 개의 linear transformation set을 사용해서 Attention을 수행하는 방식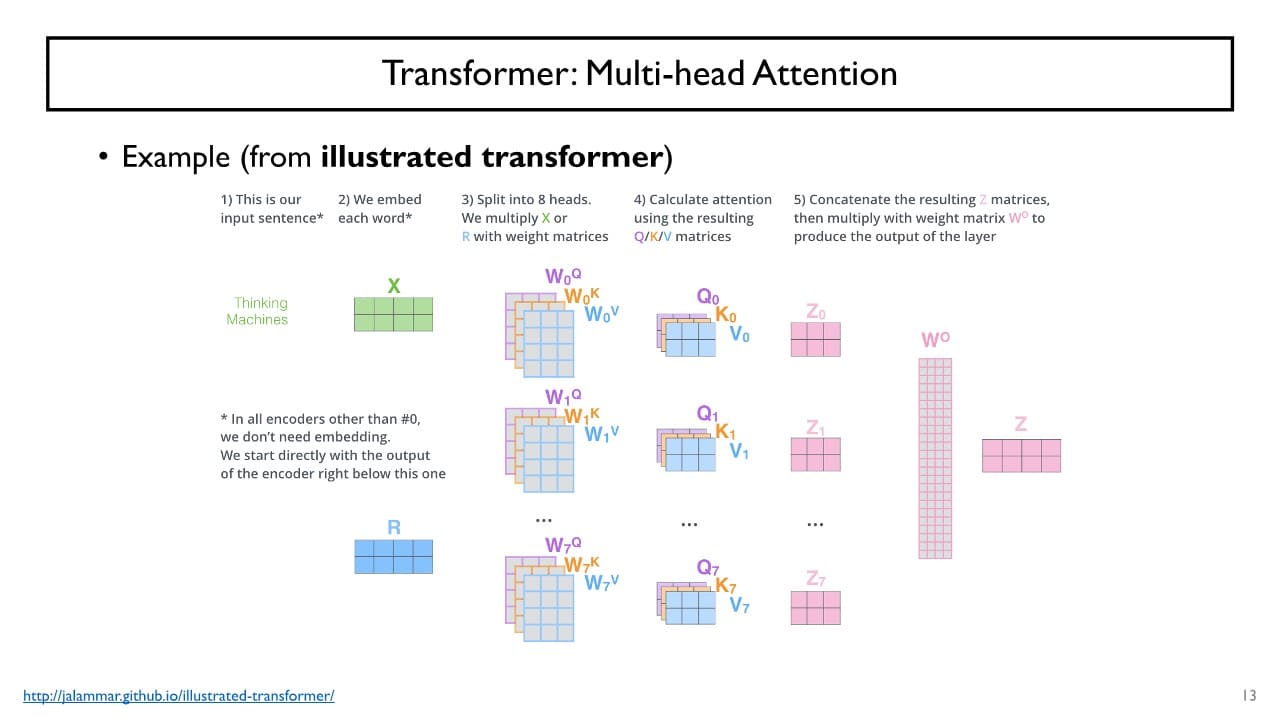
한 layer 내에서 encoding 시 self-attention model을 사용할 때 어떤 기준으로 선형변환할 지 결정하는 matric set을 여러개 두어,
각각의 set를 통해 변환된 , , 들을 사용해서 encoding하고
output을 나중에 concat하여 정보를 합치는 형태로 sequence를 encoding하게 된다.
multi-head의 수가 커지면 concat했을 때의 attention model의 output vector도 점차 dimension이 커지는데 encoding 후 hidden state vector를 원하는 크기로 조정하기 위해 와의 선형변환을 한 번 더 거치게 된다.
Self Attention 단점
: 메모리 요구량
의 가로, 세로 크기 입력 sequence의 길이
⇒ 만큼의 메모리가 필요하다.
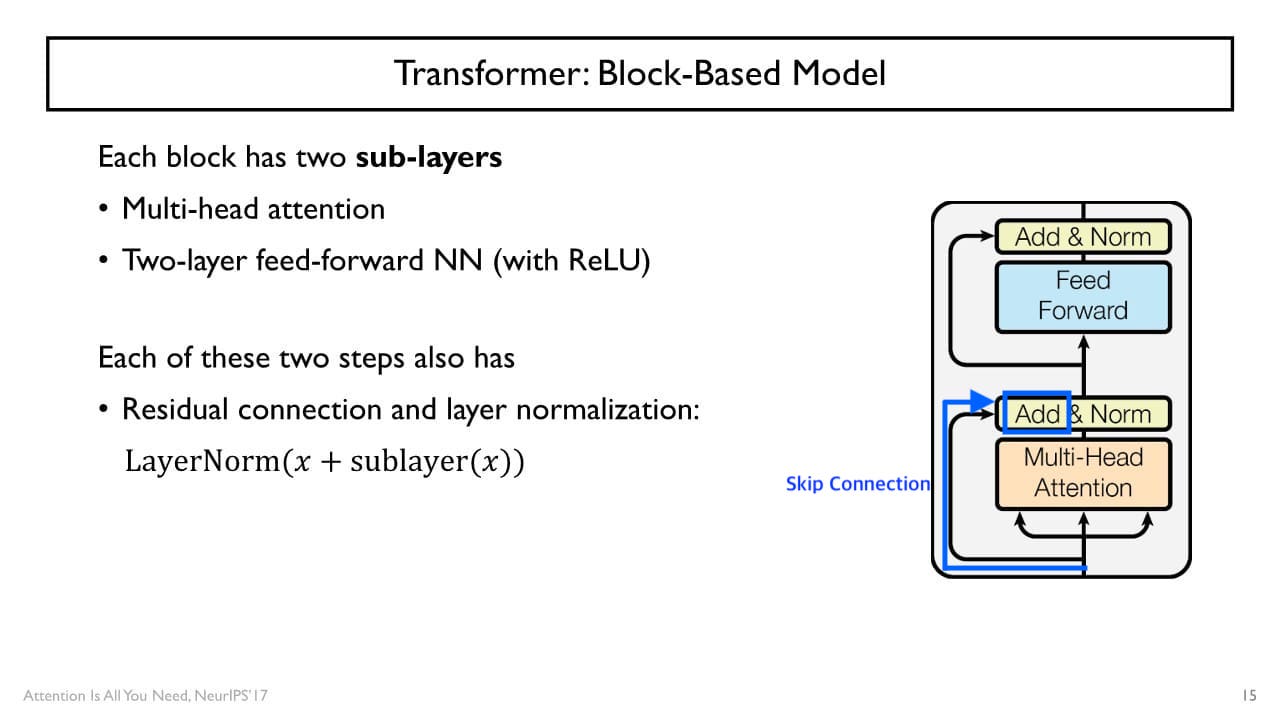
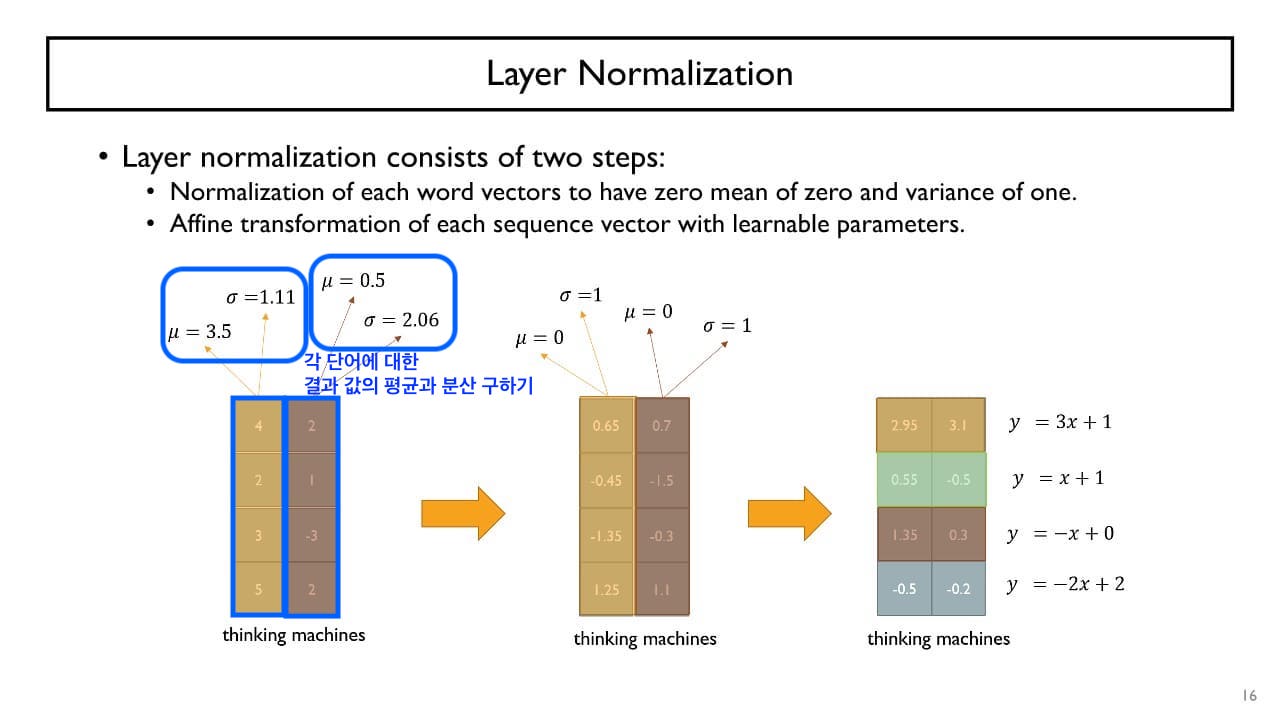
+) Self Attention도 ResNet처럼 Skip connection을 수행한다.
→ 입력 vector와 output vector의 dimension의 크기를 동일하게 유지한다.
Position Encoding
현재까지의 Self Attention model은 순서를 구분하지 못하는 단점이 있다.
sequence의 내용은 동일한데 입력 vector들의 순서만 바뀐 경우 결과는 항상 동일하다.
→ positional encoding을 통해 각 입력 vector에 순서 정보를 부여하여 이러한 단점을 개선하고 있다.
사전에 정의된 서로 다른 주파수 성분을 가지는 , 함수를 이용하기도 하고
특정 task나 loss function에 기반하여 자체적으로 학습 및 최적화를 수행하기도 한다.
2. Transformer를 활용한 Decoding
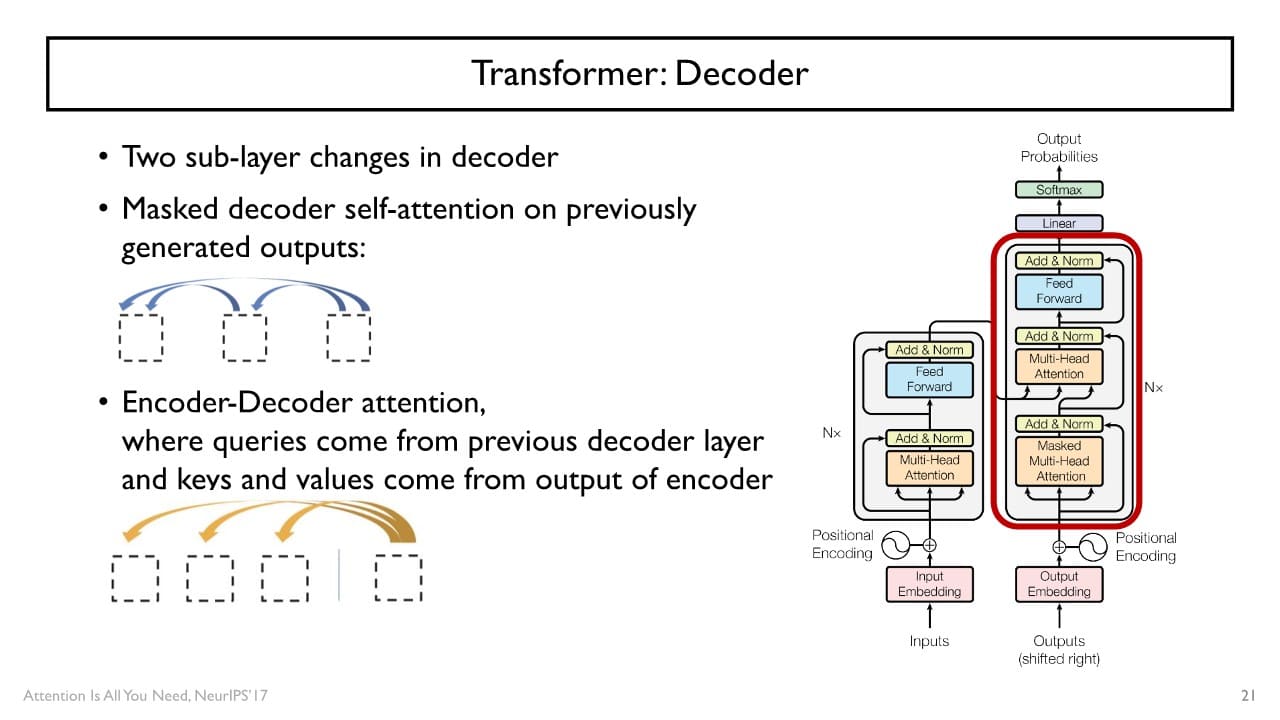
N번의 self attention을 수행하여 얻은 encoder hiddent state vector와 <SOS(start of sentence)> token을 Decoder의 입력으로 사용하고
예측 sequence와 <EOS(end of sentence)> token까지 출력되도록 self attention을 수행하여 학습시킨다.
Masked Multi-head Attention
<SOS> token 다음 단어를 쉽게 예측할 수 있는 cheating의 문제를 개선하고자 Decoder에서는 masking 이라는 연산을 추가적으로 수행한다.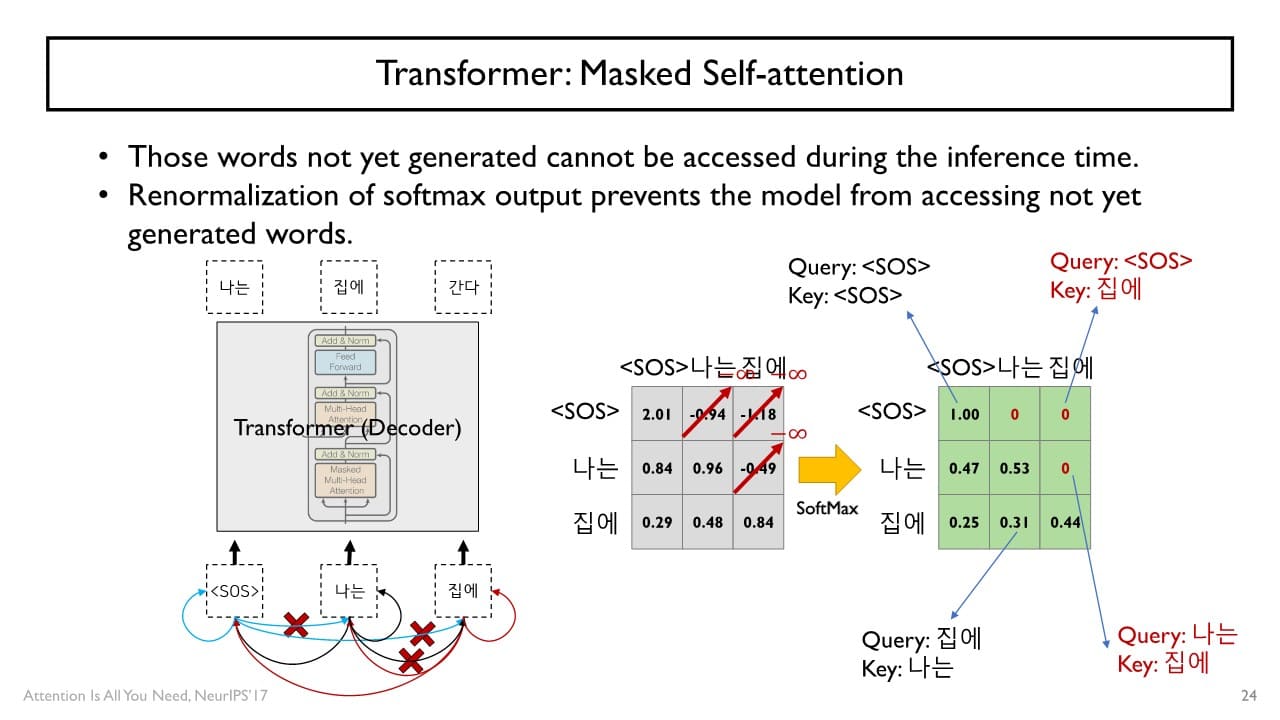
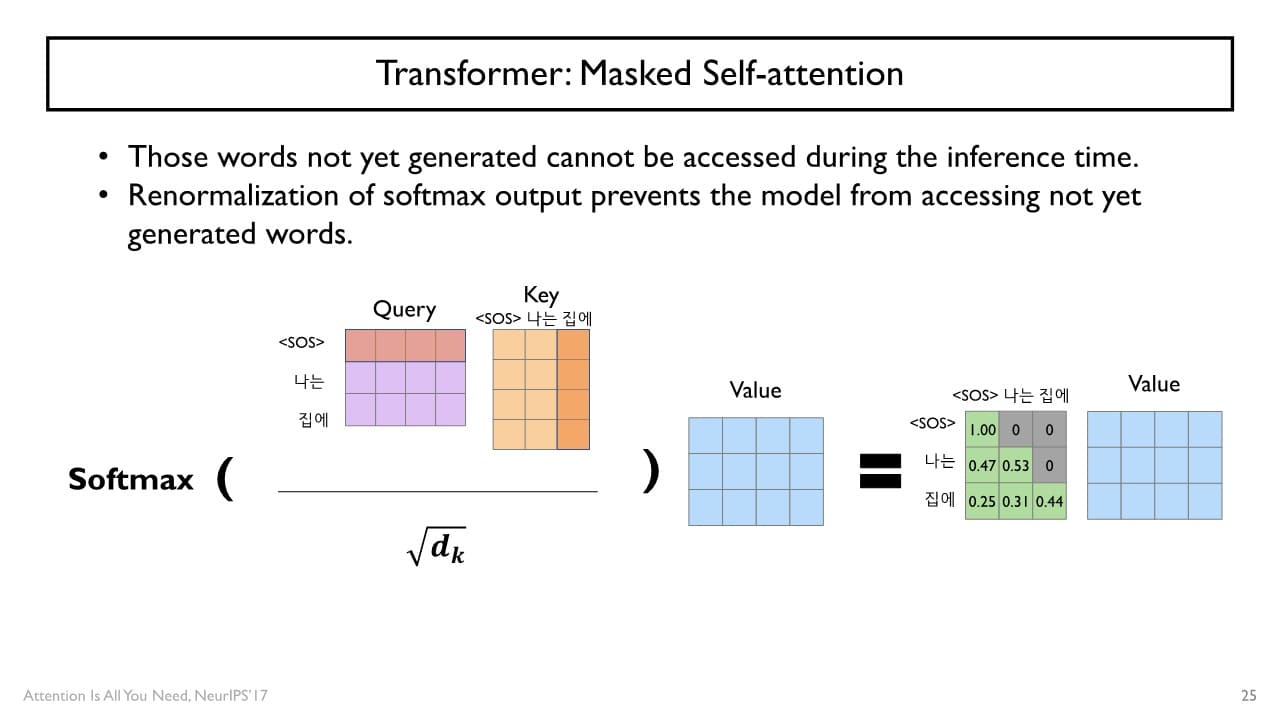
masking : 특정 decoder time step에서 현재 단어와 그 이전에 나타난 단어들만을 encoding할 수 있도록 해당 단어 다음에 나타나는 쿼리에 대해 softmax의 입력으로 주어지는 값을 로 대체하여 attention weight을 0으로 설정하는 방식
Multi-head Attention
Decoder에서 encoding된 hidden state vector들이 쿼리 로, Encoder의 output인 hidden state vector를 key 로 사용된다.
한계
Self attention 기반의 transformer가 Decoder에서 학습은 각 time step에 있는 단어들을 한 번에 예측하는 형태로 동작하더라도
model이 다 학습되고 난 이후 inference time에서는 <SOS> token을 decoder의 첫 time step에 입력으로 주어 다음 단어를 예측하고 그 결과를 다시 다음 time step decoder에 입력으로 주는 autoregressive model의 제약 조건에서는 벗어나지 못한다는 한계점을 여전히 지니고 있다.
