Module 4. 『딥러닝(Deep Learning)』 6. Self-Supervised Learning and Large-Scale Pre-Trained Models
LG Aimers

📍 강의 자료 출처 : LG Aimers
6. 자가지도학습 및 언어 모델을 통한 대규모 사전 학습 모델
1. Self-Supervised Learning (자가지도학습)
사람이 일일이 해야 하는 Labeling 과정 없이
원시 data(별도의 추가적인 label이 없는 data)에서 일부를 가려놓고 입력했을 때 가려진 부분을 잘 복원 혹은 예측하도록 하여 주어진 데이터의 일부를 출력 대상으로 삼고 model을 학습하는 방식
예) 컴퓨터비전 분야에서의 in-painting task
대규모 data를 통한 자기지도학습 모델은 원하는 task를 해결하기 위해 transfer learning 형태로 활용될 수 있다.
transfer learning
: 한 분야의 문제를 해결하기 위해서 얻은 지식과 정보를 다른 문제를 푸는데 사용하는 방식→ 대량의 데이터셋으로 이미 학습이 되어있는 pretrained model을 앞단에 그대로 두고 뒷단에는 원하는 task를 수행하기 위한 새로운 layer를 추가하여 학습 속도를 개선할 수 있다.
BERT
: Pre-training of Deep Bidirectional Transformers for Language Understanding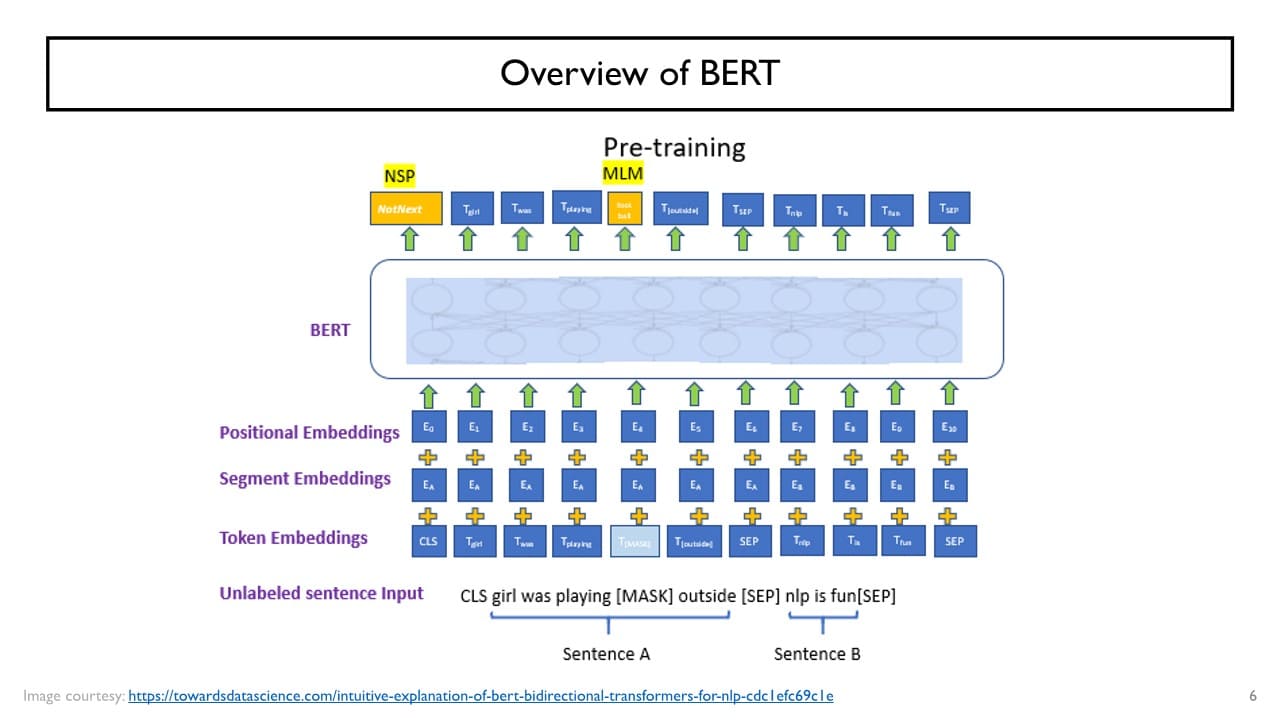 Transformer model을 기반으로, BERT는 Transformer model에서의 Encoder 부분에 해당한다. masked language modeling & next sentence prediction 2가지 task로(= Bidirectional) 자가지도학습을 수행한다.
Transformer model을 기반으로, BERT는 Transformer model에서의 Encoder 부분에 해당한다. masked language modeling & next sentence prediction 2가지 task로(= Bidirectional) 자가지도학습을 수행한다.

- Masked Language Modeling (MLM)
대규모 data로 자가지도학습을 진행하는데, 입력 sequence 중 일부를 가리고 (= [MASK] token) 해당 부분을 예측하도록 model을 학습시킨다.
- Next Sentence Prediction (NSP)
: "[CLS] token + 문장1 + [SEP] token + 문장2 + [SEP] token" 형태로 입력을 주고 두 문장 간 의미 관계가 밀접한지 판단하도록 model을 학습시킨다.
→ 각 단어별로 encoding된 hidden state vector가 생성될 것이고 그 vector를 output layer에 입력으로 넣어 2가지 task를 수행한다.
+) Position Embedding
: 기존에 주어지는 각각의 단어들의 입력 vector에 해당 단어가 몇번째 position에 나타났는가에 대한 정보를 더해주는 과정
+) Segment Embedding
: 해당 단어가 2개의 문장으로 구성된 입력 데이터 중 첫번째 문장에서 나온 것인지 두 번째 문장에서 나온 것인지에 대한 정보를 더해주는 과정
Masked Language Modeling
주어진 입력 문장에 대해 랜덤한 특정 비율을 사용하여 mask token으로 대체할지/말지에 대한 전처리를 수행한다.
예) 전체 100개의 단어가 있다면 15%만큼은 mask token으로 대체하여 해당 단어들 예측
단,
- 15개 중 80%만 실제로 mask token으로 바꿔 입력 sequence에 반영
- 15개 중 10%는 mask token이 아닌 랜덤한 다른 단어로 대체
- 15개 중 마지막 10%는 해당 단어를 그대로 유지하여
골고루 변형된 유형에 대해 model이 학습을 진행할 수 있도록 설계한다.
mask token으로 대체할 비율을
너무 작게 설정하면
→ 학습량에 비해 해결해야 할 예측 수가 적어 학습의 효율성이 떨어진다.
너무 크게 설정하면
→ 주어진 문장 상에 온전히 남아 있는 단어의 수가 얼마 되지 않아 학습에 필요한 단어 수가 부족할 수 있다.
Next Sentence Prediction
: 두 문장을 주고 두 번째 문장이 코퍼스 내에서 첫 번째 문장의 바로 다음에 오는지 여부를 예측하도록 하는 방식
GPT
: Generative Pre-Trained Transformer
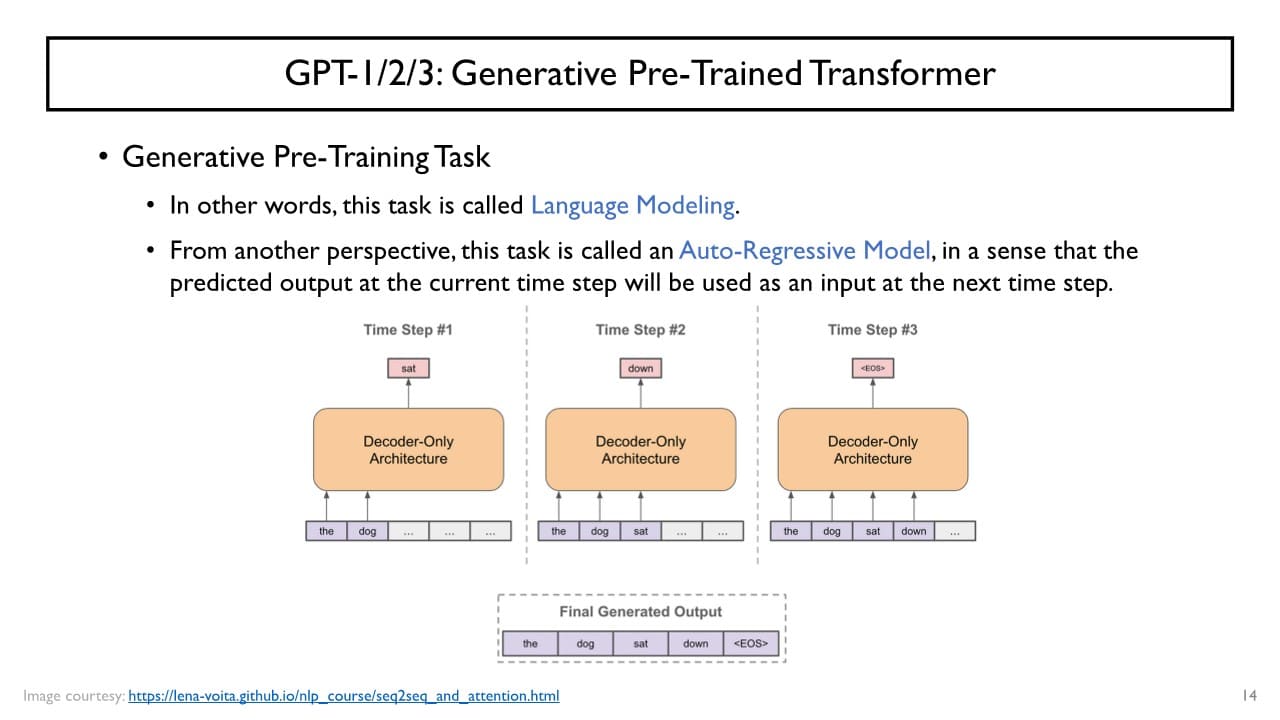 → 대규모의 text data로부터 문장들을 가져오고 단어 단위로 입력하였을 때 다음 단어를 실시간으로 예측하는 모델
→ 대규모의 text data로부터 문장들을 가져오고 단어 단위로 입력하였을 때 다음 단어를 실시간으로 예측하는 모델
- zero shot
: downstream task의 data를 전혀 사용하지 않고 pre-trained model로 downstream task를 바로 수행하는 방식
→ GPT-2 - one shot
: downstream task의 data를 1건만 사용하여 어떻게 수행되는지 참고한 후 downstream task를 진행하는 방식
→ 각 class에 따른 하나의 training image만으로 모델을 만든다. - few shot
: 매우 적은 학습 데이터(Support set)으로 평가 데이터(Query set)를 올바르게 예측하도록 학습하는 방식
→ GPT-3
