
📍 강의 자료 출처 : LG Aimers
다양한 XAI 기법
1. Saliency map-based
Class Activation Map (CAM)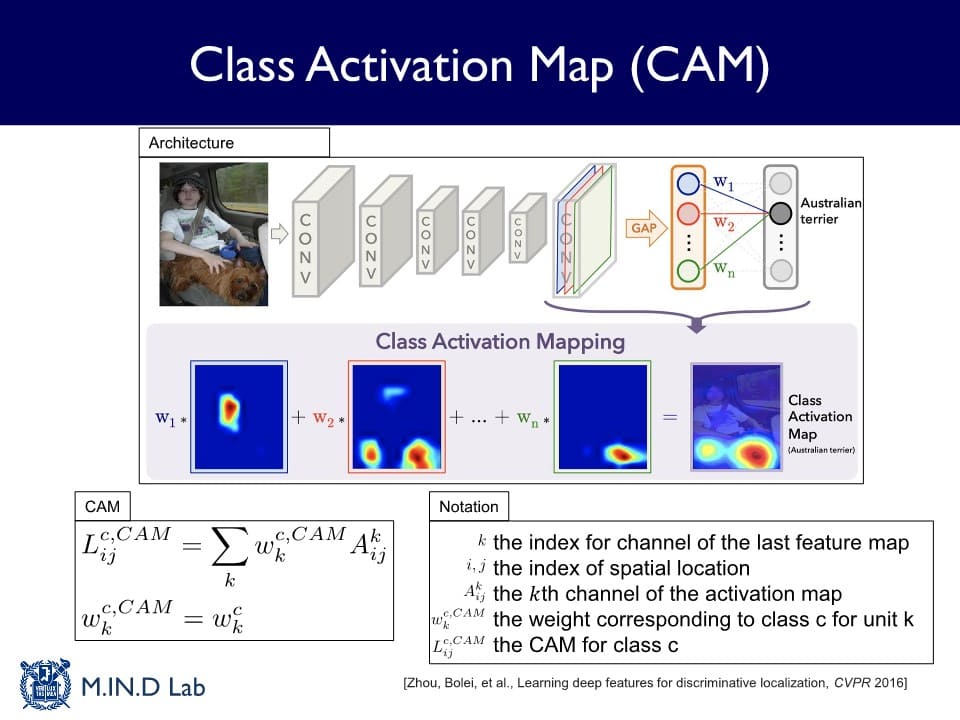
: global average pooling이라는 특정한 layer를 만들고 그것을 활용하여 설명을 제공하는 방법
Global Average Pooling (GAP) Layer
: 각 Activation map의 모든 Activation들을 평균을 내는 연산
Activation map 별 평균 Activation에 최종 softmax output layer를 붙여
(= 각 class마다 평균 낸 Activation들을 선형적으로 결합하여)
class별 확률을 계산하는 output 분류기를 만들어 학습한다.
→ 완성된 activation map과 입력 이미지를 겹쳐보았을 때, 이미지 내에서 분류하고자 했던 object를 highlighting하는 것을 확인할 수 있다.
+) Activation map에 Activation이 크게 된다 Map이 주어진 입력과 관련이 많다
+) Activation map을 결합하는 가 크다 최종 분류애 큰 영향을 주는 Activation이다
CAM을 구한 이미지의 해상도는 원래 이미지보다 떨어지기 때문에 upsampling을 통해 최종 시각화를 수행한다.
A : activation
Y^c: 최종 점수 (class c에 대한 output score)
CAM은 이미지 분류뿐만 아니라 Object detection, Semantic segmentation과 같은 더 복잡한 응용분양에도 적용 가능하다.
- 장점
- 모델이 이미지 내에서 중요하게 보고 있는 물체를 정확하게 잡아낼 수 있다
- 단점
- model-specific
- CAM의 설명은 마지막 conv layer의 activation map에서만 얻을 수 있으므로 visualization의 해상도가 많이 떨어진다
Grad-CAM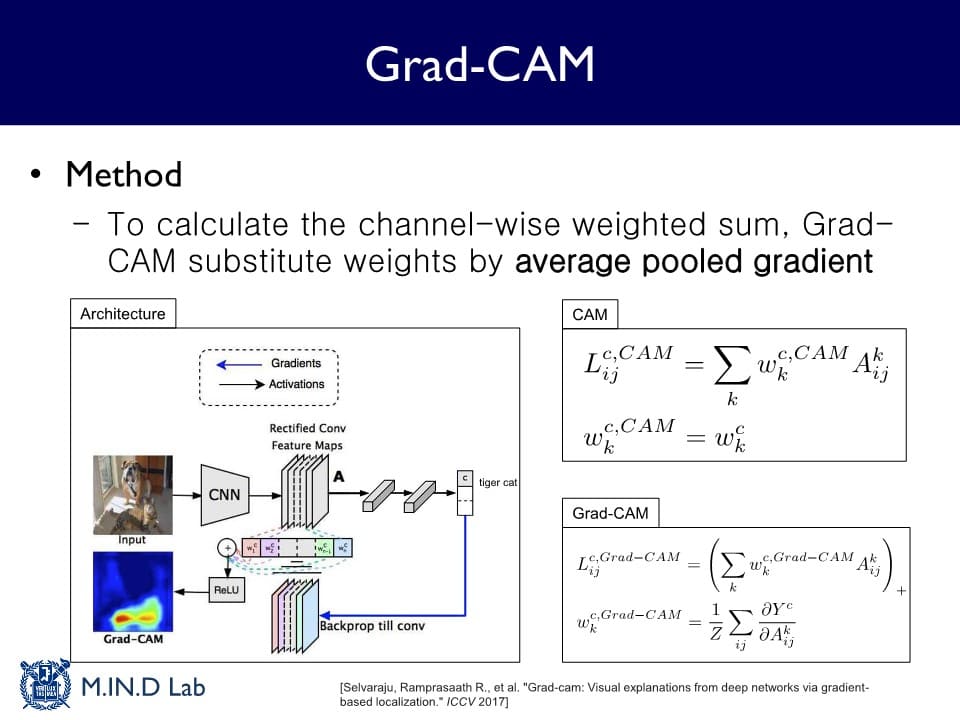
: CAM을 Gradient 정보를 활용해서 확장한 설명 방법
GAP layer가 없는 모델에도 적용 가능하기 때문에 CAM의 model-specific한 한계를 극복할 수 있다.
어떤 가 특정 모델 구조를 가지고 학습된 를 사용하는 것이 아니라
어느 Activation map에서도 그 Activation map의 Gradient를 구한 다음 그것의 Global Average Pooling 값을 로 적용한다.
Grad-CAM을 활용하면, 학습된 모델이 과연 제대로 예측을 하고 있는지 또는 이 모델의 예측에 편향성이 존재하는지도 알아낼 수 있다.
- 장점
- model-agnostic
- 단점
- Activation을 결합하는 로 사용되는 평균 gradient가 종종 정확하지 않을 수 있다
2. Perturbation-based
모델의 정확한 구조나 계수는 모르는 상태에서 그 모델에 대한 입출력 정보만 가지고 있는 경우 설명하는 방법
→ 입력 데이터를 조금씩 바꾸면서 그에 대한 출력을 보고 그 변화에 기반해서 설명하는 방식
Local Interpretable Model-agnostic Explanations (LIME)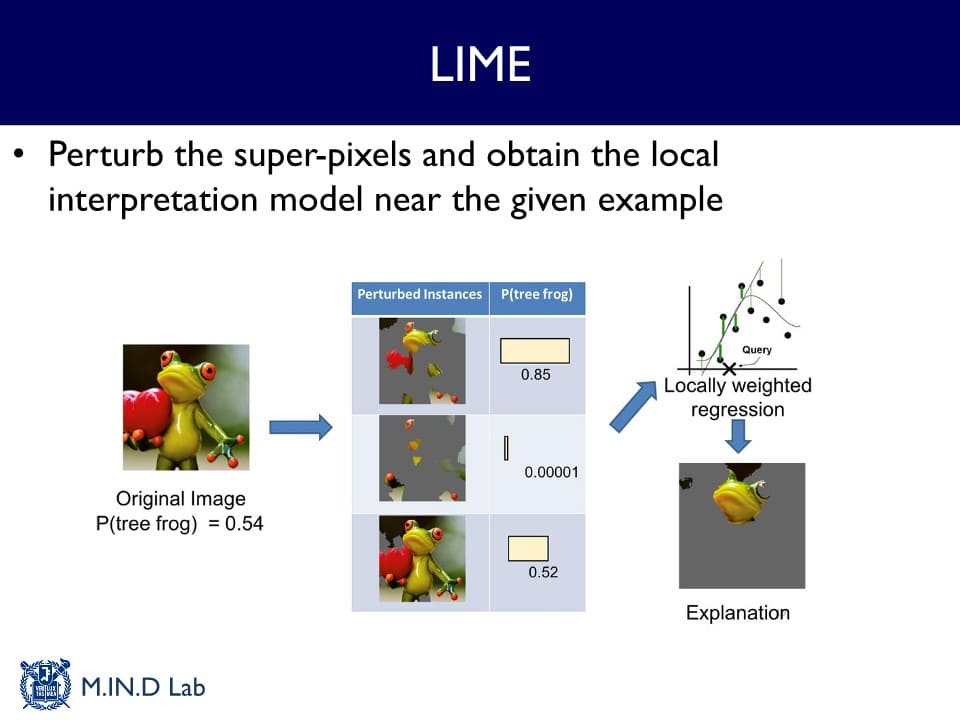
: 주어진 입력 데이터를 조금씩 교란(perturb)하고 그 교란된 입력 데이터를 모델에 여러 번 통과시킴으로써 나오는 출력을 구한 후, 이 입출력 쌍들을 간단한 선형 모델로 근사함으로써 설명을 얻어내는 방법
→ 교란된 이미지와 출력 확률의 pair를 이용해서 각 super pixel들을 잘 결합하는 선형 계수들을 학습할 수 있고, 그 계수들을 이용해서 super pixel들을 다시 결합했을 때 나오는 이미지가 최종 설명이 된다.
어떤 분류기가 딥러닝 모델처럼 매우 복잡한 비선형적 특징을 가지고 있더라도 주어진 데이터 포인트들에 대해서는 아주 local하게는 다 선형적인 모델로 근사화 가능하다는 관찰에서 기인하였다.
- 장점
- Black-box 설명 방법이다
→ 딥러닝 모델뿐만 아니라 주어진 입력과 그에 대한 출력만 얻을 수 있다면 어떤 모델에 대해서도 다 적용할 수 있는 설명 방법
- Black-box 설명 방법이다
- 단점
- 계산복잡도가 매우 높다
= 모델의 구조를 알지 못하는 Black-box 방법의 한계 - 실제 모델이 여전히 local하게 비선형적이다
→ 선형 함수로 근사화가 잘 되지 않는 경우 설명 능력이 떨어지게 된다. - 객체의 분류가 아니라 이미지 전체의 특성에 대한 분류를 하는 경우 성능이 좋지 않다
- 계산복잡도가 매우 높다
Randomized Input Sampling for Explanation (RISE)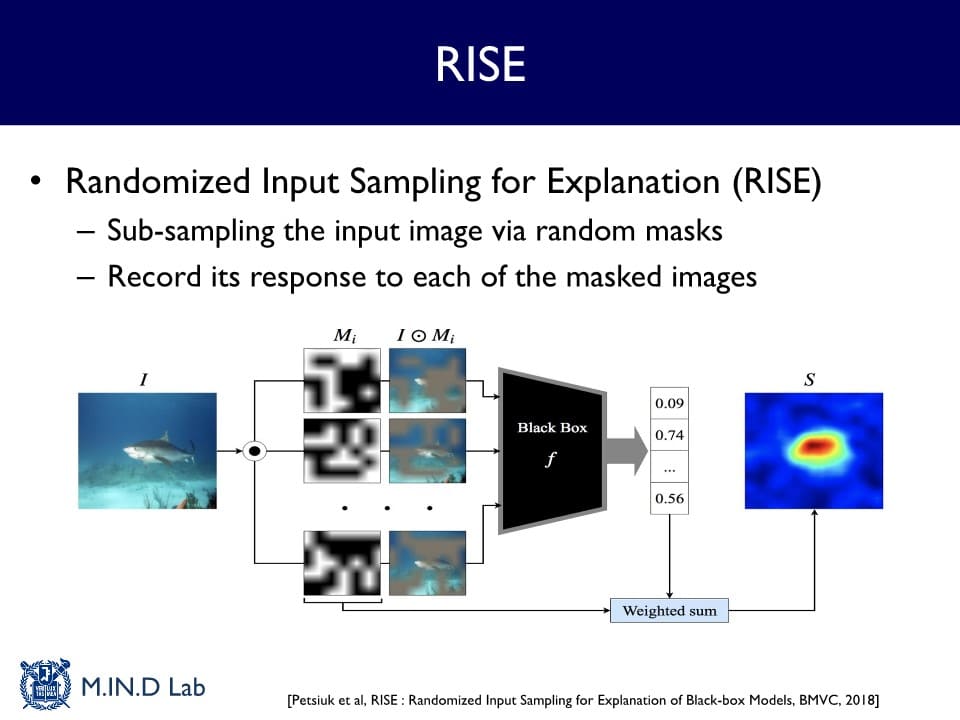
: random한 mask를 만들어 이 mask를 씌운 입력이 모델을 통과했을 때 해당 class에 대한 예측 확률이 얼마나 떨어지는지를 보고 설명하는 방식
→ 여러 개의 random masking이 되어 있는 입력에 대한 출력 스코어(= 확률)를 구하고, 그 값을 가중치로 평균을 냈을 때 설명 Map을 구할 수 있다.
- 장점
- LIME보다 명확한 설명 map을 만들 수 있다
- 단점
- 계산복잡도가 매우 높다
- random mask를 몇 번 만드느냐에 따라 해당 설명이 달라질 수 있다 (= random noise 존재)
3. Influence function-based

모델 데이터셋에 있는 Training image들의 함수
( 주어진 모델이 어떤 Training set으로부터 학습한 것)
→ 각 테스트 이미지를 분류하는데 가장 큰 영향을 미친 Training image가 해당 분류에 대한 설명이라고 제공하는 방식
Influence function
training image 없이 모델을 훈련시켰을 때 해당 Test image의 분류 스코어가 얼만큼 변할 것인지를 근사화하는 함수
→ 함수 값을 가지고 각 training image마다 영향력을 계산하고 영향력이 가장 큰 이미지를 설명으로 제공한다.
