
📍 강의 자료 출처 : LG Aimers
XAI 비교 및 평가
-
Human-based visual assessment
: 사람들이 직접 XAI 방법들이 만들어낸 설명을 보고 비교 평가하는 방법
-
Human annotation
: 이미 만들어진 annotation을 활용하여 설명 가능 기법들을 평가하는 방법
-
Pointing Game
 : Bounding box를 활용해서 평가하는 방법
: Bounding box를 활용해서 평가하는 방법
→ "가장 영향력이 큰 pixel이 bounding box 안에 포함된다면 좋은 설명이라 할 수 있다"는 가정에서 출발하였다. -
Weakly supervised semantic segmentation
: 어떤 이미지에 대해서 classification label만 주어져 있을 때 그것을 활용하여 픽셀별로 객체의 Label을 예측하는 semantic segmentation을 수행하는 방법
+) 픽셀별로 정답 Label이 다 주어져 있지 않기 때문에 Weakly supervised 라 한다.
IoU(Intersection over Union)을 평가 지표로 활용하는데, 이것은 만들어진 Segmenatation map이 정답 Map과 얼마나 겹치는지를 평가하는 Metric이다.
- Pixel perturbation
: pixel들을 교란함으로써 그 모델의 출력값이 어떻게 변하는지를 직접 테스트해보는 방법
-
AOPC (Area Over the MoRF Perturbation Curve)
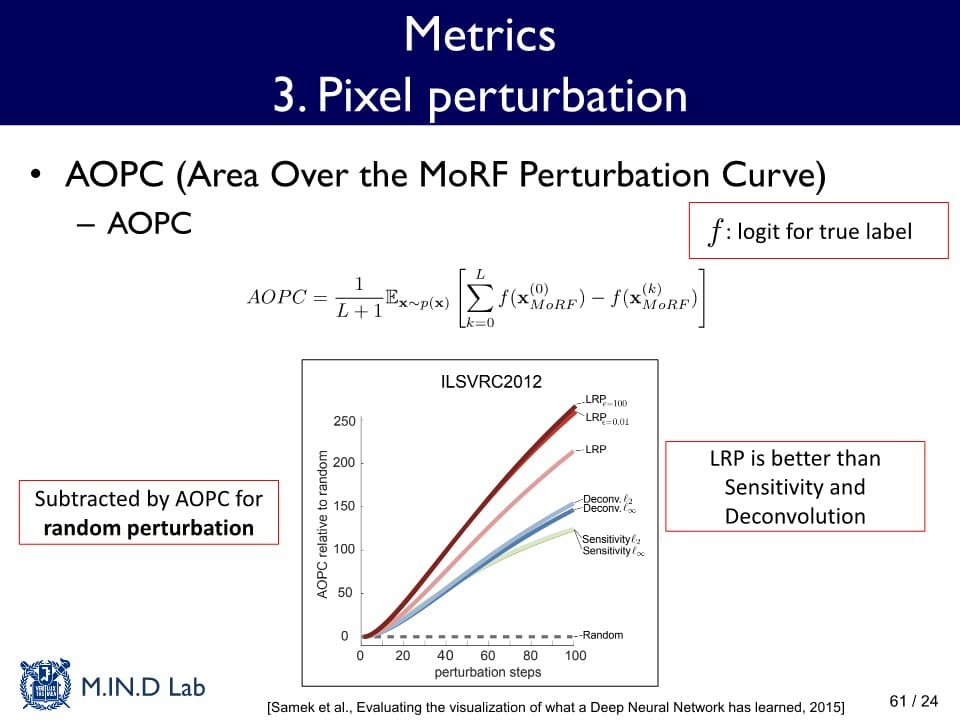 : 주어진 이미지에서 중요도 순서대로 pixel들을 교란하였을 때 원래 예측한 분류 스코어 값이 얼마나 빨리 바뀌는지 측정하는 방법
: 주어진 이미지에서 중요도 순서대로 pixel들을 교란하였을 때 원래 예측한 분류 스코어 값이 얼마나 빨리 바뀌는지 측정하는 방법
+) 교란 = 해당 Pixel을 랜덤한 값으로 바꾸는 것
→ AOPC가 클수록 더 잘 설명하는 기법임을 알 수 있다.- Insertion
: 백지 상태의 이미지에서 중요한 순서대로 pixel을 추가해가는 방식
→ 분류기의 출력 스코어 값이 올라가는 그래프의 Curve 아래쪽 면적을 구한다.
⇒ Insertion 값이 클수록 더 잘 설명하는 모델이다. - Deletion
: 중요한 순서대로 pixel을 지워가면서 얼마나 분류 확률 값이 떨어지는지 측정하는 방식
→ AOPC와는 반대로 Curve 아래쪽의 면적을 구한다.
⇒ Deletion 값이 낮을수록 더 잘 설명하는 모델이다.
- Insertion
- ROAR (RemOve And Retrain)
: XAI 기법이 생성한 중요한 pixel을 아예 지운 후 그 데이터를 활용하여 모델을 재학습한 뒤 정확도가 얼마나 떨어지는지를 평가하는 방법
XAI 방법의 신뢰성에 대한 연구들
- Sanity checks
-
Model randomization
: 주어진 분류 모델에서 계수들을 순차적으로 randomize한 뒤 얻어지는 설명을 비교해보는 방법
→ 원하는 객체를 Highlighting한 설명이 단순하게 edge-detector로 작용해서 얻은 결과는 아닌지 판단할 수 있다. -
Adversarial attack
적대적 공격
: 입력 이미지에 약간의 변형을 가하게 되면 분류기의 예측 결과를 완전히 다르게 만들 수 있다.XAI에서는 일반적인 개념과는 조금 다르게,
분류기의 예측을 그대로 유지하면서 설명 방법을 완전히 이상하게 공격할 수 있다는 내용으로 사용된다.
→ ReLU 대신 Softplus function을 사용함으로써 개선 가능하다. -
Adversarial model manipulation
모델이 편향되어있다는 것을 알았을 때, 모델을 새로 만드는 것이 아니라 계수만 변경함으로써
정확도는 유지하고 공정한 모델을 새롭게 만든 것처럼 설명을 조작할 수 있다.
