
📍 강의 자료 출처 : LG Aimers
지금까지는 하나의 도메인에 대한 인과 추론 방법을 살펴 보았다.
그렇다면 만약 여러 종류의 데이터가 있다면, 한꺼번에 활용해서 우리가 원하는 인과 효과를 계산하면 더 효율적이지 않을까?
General Identifiability

: 어러 데이터가 한 도메인에 주어져 있을 때 그것을 활용해서 원하는 인과 효과를 계산하는 것
기계 학습에서는 "Train data와 Test data가 같은 환경에서 만들어진다"
즉, Distribution shift가 일어나지 않는다는 가정이 존재한다.
→ 주어진 Train data set으로 학습하면 Test set에 대해서도 모델을 그대로 적용할 수 있을 것이다.
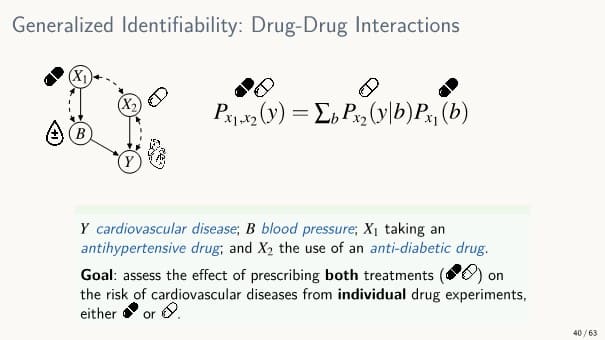
2개의 실험 데이터를 이용하는 경우
예) 각각의 약에 대해서 실험한 데이터가 있을 때 두 약을 혼용하면 어떤 효과가 나타날지 알고 싶은 경우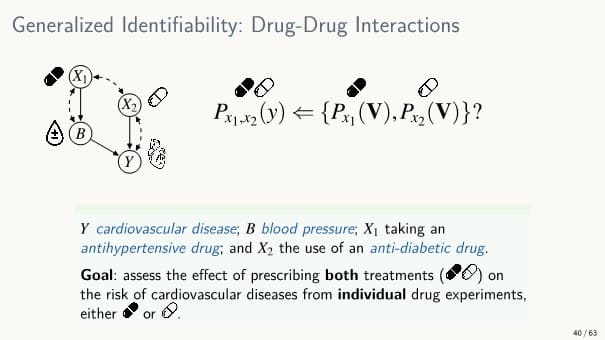


Transportability

: 주어져 있는 데이터의 소스와 인과 효과를 계산하고자 하는 타겟이 서로 다른 도메인일 때의 인과 추론을 구하는 것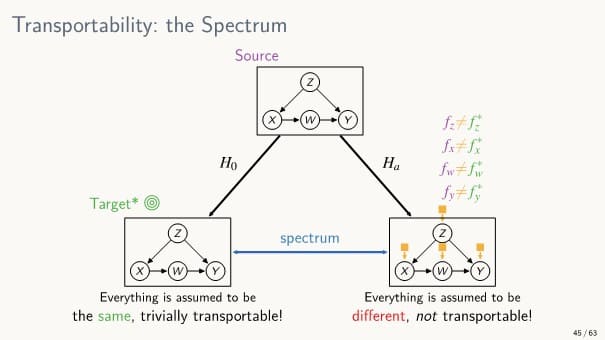
일반적인 추론에서 일반화를 어떻게 할 것인지 확장되면서 단순한 인과 추론을 넘어 "통계적 추론"으로 이어진다.
- 가정 1. 소스와 타겟이 모두 같다면 실험 결과를 원하는 타겟에 그대로 적용할 수 있다.
예) 쥐를 대상으로 한 실험(source)과 쥐(target)
- 가정 2. 소스와 타겟이 다르다면 실험 결과를 타겟에 적용할 수 없다.
예) 쥐를 대상으로 한 실험(source)과 사람(target)
현실적인 가정을 위해 두 경우의 중간을 생각해,
Source와 Target 간 어떤 공통점이 존재하지만 부분적으로 어떤 변수에 대해서는 다를 수 있는 상황에서 인과 추론을 어떻게 수행할 지가 Transportability의 목적이다.
Selection Bias (선택 편향)

: 데이터의 샘플이 선택적으로 포함되어 있는 경우에 발생되는 편향
(= 데이터의 sampling 과정에서 선택 편향이 생긴 경우)
예) 전쟁 후 돌아온 전투기에서 총알 자국의 위치를 보고 전투기를 보완하고자 할 때, 엔진이나 주요 부분이 고장나 돌아오지 못한 전투기는 고려하지 않아 오류가 생길 수 있음
기존 Causal diagram에 '샘플이 데이터에 포함됐는지'를 표현하는 새로운 Selection 변수 를 추가하여 Selection Bias 상황에서의 인과 추론을 수행할 수 있다.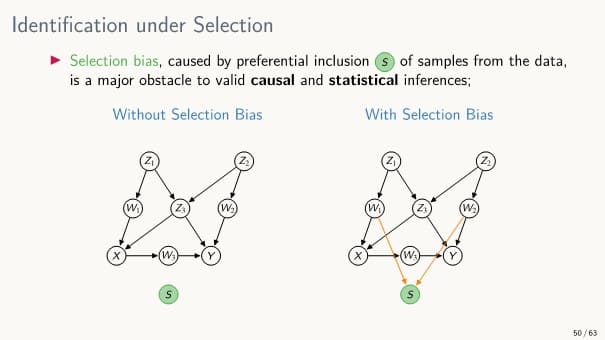
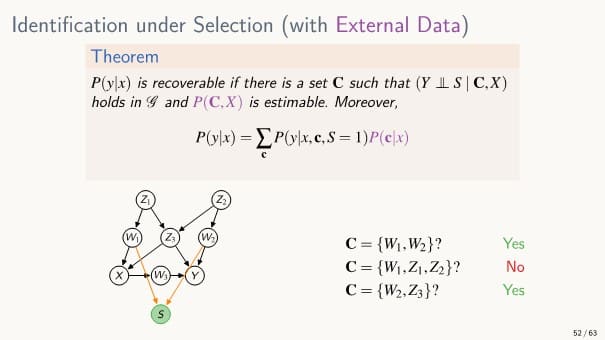
- selection bias가 일어나지 않았다면, 는 어떤 변수에도 영향을 받지 않는다.
샘플이 데이터에 포함될지 여부는 무작위로 결정된다
- selection bias가 있다면, 일부 변수에 가 영향을 받는다.
선택 편향이 있는 경우 조건부 확률을 계산하기 어려운데,
그렇다면 편향되지 않은 데이터를 활용해서 우리가 원하는 조건부 확률을 계산할 수 있을까?
데이터 누락

N/A로 누락 데이터가 발생하는 경우, 누락 메커니즘 변수 를 새로 만들어 N/A를 임의의 값으로 변환해줄 수 있다.
데이터가 누락되는 원인은 3가지로 분류할 수 있다.
- Missing Completely At Random (MCAR; 완전 무작위)
: 가 다른 변수들에 independent한 경우
- Missing at Random (MAR)
: 누락 메커니즘이 누락된 변수와 어떤 조건부 독립이 성립하는 경우
- Missing Not At Random (MNAR)
: 랜덤하지 않게 누락이 일어나는 경우
→ 보통 누락된 정보가 있는 줄들을 삭제하거나 빈 값들을 채우는 알고리즘을 사용하는데 이것은 MCAR, MAR에 부분적으로 동작하지만 MNAR에는 동작하지 않는다.

지금까지 다양한 데이터로부터 인과 추론을 하는 것, 인과 추론에 편향이 있을 때 통계적 추론을 제대로 하는 것에 대해 배웠다. 이 과정에서 데이터가 만들어지는 인과 과정을 이해했고 편향이 생기는 이유와 도메인이 어떻게 다른지 표현했다.
