
지난번 GPT-1에 이어 이번엔 GPT-2에 대한 논문이다.
📍 Language Models are Unsupervised Multitask Learners
❗️개념을 정리하기 위해 작성한 글로, 내용상 잘못된 부분이 있을 수 있다는 점 참고 바랍니다.
논문에서는 순서가 아래와 같이 구성되어있다.
- Introduction
- Approach
- Training Dataset
- Input Representation
- Model
- Experiments
- Language Modeling
- Children's Book Test
- LAMBADA
- Winograd Schema Challenge
- Reading
이 글은 논문 순서를 그대로 따라가기보다는 내가 공부할 때 이해하기 편했던 흐름대로 작성하려고 한다.
Introduction
GPT-1을 포함하여 기존 연구들은 unsupervised pre-training과 supervised fine-tuning 2단계를 거쳐 모델을 학습시켰다. 이 방법은 특정 task에서 뛰어난 성능을 보이지만 'narrow expert'라는 점, 데이터의 분포가 조금이라도 바뀌면 결과가 불안정해지는 점에서 한계를 보였다.
따라서 GPT-2에서는 더 범용적인 Language Model(LM)을 만들고자 하였다. 이를 위해 fine-tuning 과정을 없애고 pre-train된 모델을 바로 task에 적용하는 zero-shot 방식을 채택하였다.
이 결과, supervise 과정이 없는 상태로, task과 무관하게 모델의 범용성이 높아지도록 할 수 있었다.
zero-shot
⇒ 모델에게 입력 데이터뿐만 아니라 task에 대한 설명도 함께 전달한다. 모델은 파라미터나 모델 구조를 업데이트하지 않고 설명된 task에 맞는 출력을 만들어낸다.

Approach
언어 모델은 아래와 같은 수식을 기반으로 고안되었다.
⇔ 이전에 주어진 토큰들을 바탕으로 다음에 올 토큰에 대한 비지도 분포를 추정하고 이 과정을 반복하여 문장을 생성하는 방식
기존의 single task의 경우 이미 task가 정해져 있고 이에 맞는 데이터를 입력하기 때문에 모델에는 그 입력 데이터만 제공해주면 되었다.
하지만 multu-task의 경우 모델에게 task에 대한 정보도 함께 제공해야 그게 맞는 결과를 추정할 수 있다.
따라서 GPT-2도 모델을 학습시킬 때 어떤 task를 수행할 지에 대한 정보를 입력 데이터와 함께 제공했다.
예)
translation : (translate to french, english text, french text)
reading comprehension : (answer the question, document, question, answer)
Training Dataset
기존의 연구에서는 news article, text book 등에서 데이터셋을 구축했는데,
이 경우 특정 도메인에 데이터가 편향되는 한계가 있었다.
따라서 GPT-2는 데이터가 하나의 도메인에 치우치지 않고 최대한 다양한 데이터를 모으고자 하였다. Common Crawl과 같은 웹스크랩 데이터셋이 있었지만 data quality 이슈가 있어 직접 WebText라는 대용량 데이터셋을 구축하였다.
Input Representation
GPT-2는 OOV 문제 완화에 효과적인 Byte-Pair-Encoding(BPE) 방식으로 토큰화를 진행했다.
기존의 BPE는 base character가 유니코드 단위였기 때문에 알파벳만을 포함하는 base vocabulary만으로도 크기가 상당해지는 한계가 있었다.
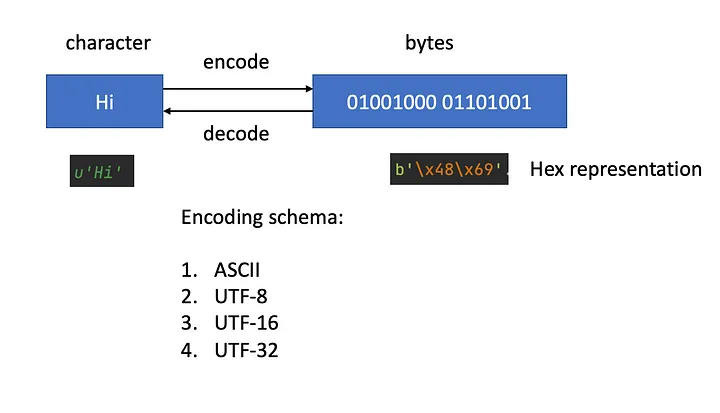
따라서 base-character를 byte 단위로 지정하는 byte-level BPE를 선택하였고
한정된 사이즈의 vocabulary를 효율적으로 사용하고자 반드시 일정 수준 이상의 단위로 병합하여 추가하는 과정을 포함시켰다.
Model
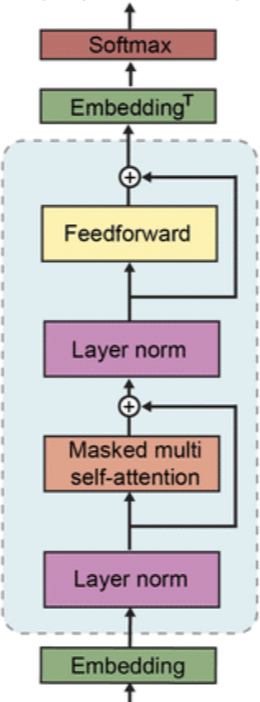
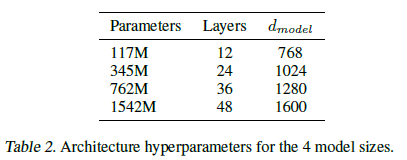
GPT-2는 파라미터 수와 모델의 크기를 늘렸을 뿐 GPT-1과 거의 똑같은 구조의 모델을 사용했다.
Layer Normalization block을 각각 Attention block과 FFN block 앞으로 옮겼는데,
이를 통해 gradient가 vanishing 되거나 exploding 되지 않도록 하였다. 또 Residaul connecntion 시 파라미터들을 으로 scaling하여 층이 깊어져도 gradient vanishin을 완화할 수 있도록 하였다.
Experiment
GPT-2는 zero-shot 방식으로도 다양한 NLP task에서 기존의 SOTA 모델과 비슷하거나 더 좋은 성능을 기록하였다.
하지만 일부 task에서는 좋지 않은 성능을 보였는데 그 예는 아래와 같다.
-
Summarization
task에 대해 추가적으로 'TL;DR' 토큰을 추가하지 않은 경우, 본문에서 랜덤하게 3문장을 뽑았을 때보다 더 엉터리로 요약하였다. -
Translation
'english sentence = french sentence'라는 설명을 주고 'english sentence = '와 같이 입력했을 때, 기존 번역 모델보다 훨씬 낮은 BLEU 점수를 기록했다.
하지만 영어로만 이루어진 WebText로 학습시켰음에도 영-불, 불-영 번역을 수행할 수 있었다는 점에서 유의미한 실험이었다.
Generalzation vs Memorization
WebText 데이터셋의 크기가 워낙 크기 때문에 GPT-2가 이 데이터를 외워서 답을 뱉어내는 것이 아닌지에 대한 실험을 진행하였다.
8-grams Bloom filterin 방식을 통해
기존의 학습데이터를 통해 만들어진 모델이 생성한 출력이 인터넷에 이미 존재하는 출력과 같은(overlap) 경우보다 GPT-2가 생성한 출력이 인터넷에 이미 존재하는 출력과 겹치는 경우가 훨씬 적은 것을 확인할 수 있었다.
이를 통해 GPT-2는 데이터를 외워서 답을 뱉어내는 것(Memorization)이 아니라 추정을 통해 답을 생성하는 Generalization 방식임을 입증하였다.
또, 모델의 크기가 증가함에 따라 성능이 꾸준히 향상되는 모습을 통해 Generalzation임을 추가적으로 언급했다.
(∵ Memorization 방식이라면 모델의 크기가 아무리 증가해도 일정 수준 이상부터는 성능이 향상되지 않는 형태를 보일 것)
Conclusion
GPT-2는 fine-tuning 없이 unsupervised pre-traing만을 통해 zero-shot으로 downstream task를 수행할 수 있는 범용 언어 모델을 만들고자 하였다.
GPT-1 vs GPT-2
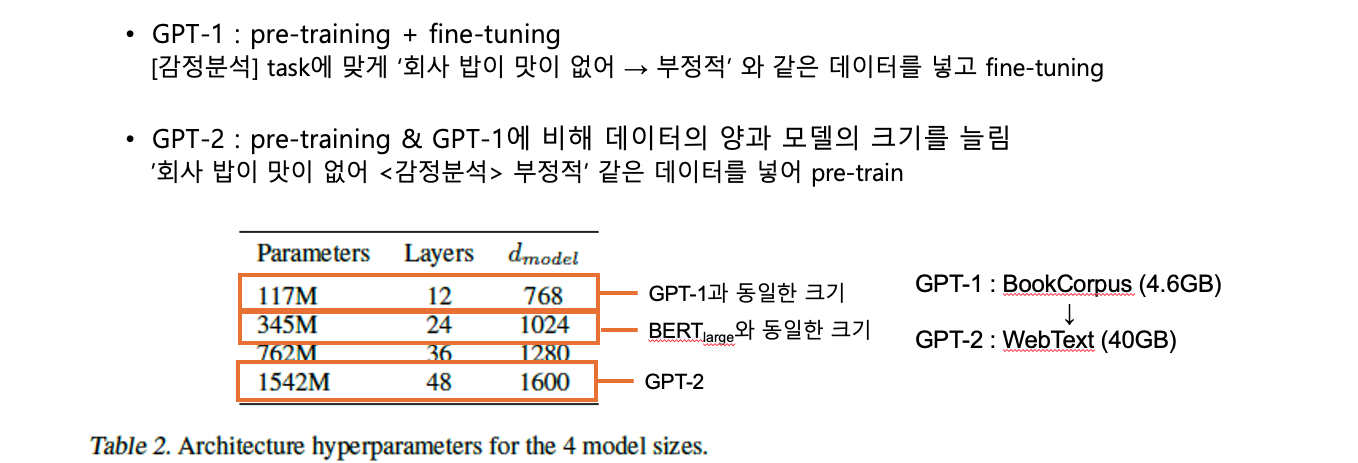
Why GPT uses only decoder?
The cases when we use encoder-decoder architectures are typically when we are mapping one type of sequence to another type of sequence, e.g. translating French to English or in the case of a chatbot taking a dialogue context and producing a response. In these cases, there are qualitative differences between the inputs and outputs so that it makes sense to use different weights for them.In the case of GPT-2, which is trained on continuous text such as Wikipedia articles, if we wanted to use an encoder-decoder architecture, we would have to make arbitrary cutoffs to determine which part will be dealt with by the encoder and which part by the decoder. In these cases therefore, it is more common to just use the decoder by itself.
모델의 구조는 '모델의 목적'에 따라 달라진다.
예를 들어 Transformer는 '기계 번역'을 목표로 만들어졌고, 따라서 언어A에 대한 문맥을 학습하는 Encoder와 언어B에 대한 생성을 학습하는 Decoder가 결합한 형태를 가진다. Encoder는 하나의 sequence가 들어왔을 때, '전체를 참조'하여 어떤 단어가 문장 내 다른 어떤 단어와 연관이 있는지를 파악한다. Decoder는 (Encoder에서 얻은 context vecotr)와 (언어B의 소스 문장 중 생성할 토큰 이전에 나타는 토큰)에 대한 정보를 이용해 다음에 올 토큰을 예측하면서 언어B에 대한 문장을 생성한다. 또 언어A와 언어B에 대해 가중치가 각각 달라야 하기 때문에 서로 다른 두 구조를 결합하는 방식을 선택했다.반면 GPT는 모든 NLP task를 텍스트 생성 방식으로 풀 수 있다고 생각해 '텍스트 생성'을 목표로 만들어졌다. 토큰을 예측할 때는 미래 토큰을 참조하면(=컨닝) 안되기 때문에 '이전 토큰들만 참조'하여 학습을 진행한다. 이때 이전 토큰에 대한 attention 정보들은 이미 다음 토큰 예측을 하면서 Decoder에 저장이 되어 있기 때문에(= masked가 적용되긴 했으나 이미 encoder의 역할을 수행) 별도의 Encoder가 없어도 다음 토큰 추정이 가능하다.
Code

🔧 참고한 GitHub
모델에 start_token 또는 context가 입력되면 이를 바탕으로 다음 토큰을 예측하고 예측된 토큰들을 이어 length만큼의 길이를 갖는 문장을 생성한다. 이 때 예측되는 토큰은 가장 확률이 높은 k개의 토큰 중 하나이다.
[Python 문법 정리]
torch.where(condition, x, y)
: condition이 참(True)이면 x에서, 거짓(False)이면 y에서 값을 불러온다.
위의 코드에서는 전체 로짓값들 중 k번째 로짓값보다 작은 부분은 로, 그게 아니라면 원래 로짓값을 반환하여 top-k개의 로짓값만 불러오도록 하였다.
assert {condition}, "error message"
:raise와 같은 예외 처리 역할로, condition을 보장하지 못하는 경우 error message를 출력한다.
위의 코드에서는 입력으로 start token 또는 context 중 하나만 오도록 상황을 설정하기 위해
start token과 context가 둘 다 함께 입력되는 경우와 둘 다 입력되지 않는 경우,
"Specify exactly one of start_token and context!"를 출력한다.
torch.full(size, value)
: size만큼 value로 채워진 텐서를 반환한다.
위의 코드에서는 start_token 값이 (batch_size, 1)만큼 복제되어 모든 sample이 start_token 값을 사용해 다음 단어를 예측하도록 초기화하게 된다.
torch.no_grad()
: 순전파 진행 시 불필요한 기울기 계산을 방지해준다.
torch.multinomial(input, num_samples)
: input 텐서의 확률 분포대로 num_samples만큼 샘플링한 인덱스의 텐서를 반환한다.
예를 들어torch.multinomial([0.2, 0.8], 1)이라면, 첫번째 단어가 나올 확률 20%, 두번째 단어가 나올 확률 80%로 단어 하나를 선택한다.
위의 코드에서는 top-k 로짓들의 확률 분포에 따라 다음 단어를 예측하기 위해 사용된다.
temperature
(블로그 참고) [NLP] Temperature
: 로짓값을 평활화하여 확률분포를 다양하게 만드는 데 사용한다.
사용자가 임의로 설정할 수 있는 하이퍼 파라미터로,
- temperature > 1 : 로짓값을 작게 만들어 모델이 다양한 선택을 하도록 함
- temperature < 1: 로짓값을 크게 만들어 모델이 일관된 선택을 하도록 함
References
📍 The Illustrated GPT-2 (Visualizing Transformer Language Models)
📍 [번역] 그림으로 설명하는 GPT-2 (Transformer Language Model 시각화)
📍 Tokenization algorithms in Natural Language Processing (NLP)
📍 Too long, didn’t read: AI for Text Summarization and Generation of tldrs
📍 Byte pair encoding 설명 (BPE tokenizer, BPE 설명, BPE 예시)
📍 Language Models are Unsupervised Multitask Learners (GPT-2)
Written on May 29th, 2021 by taekyoon.choi
📍 Step-by-Step Illustrated Explanations of Transformer
📍 Decoder-only Transformer model
📍 N_2. GPT-2 from scratch - Model Only
📍 Language Models: GPT and GPT-2
📍 GPT-1부터 ChatGPT까지… 그리고 GPT-4에 대한 전망
📍 토크나이저 정리(BPE,WordPiece,SentencePiece)
📍 Text generation with GPT-2

유익한 글이었습니다.