
📍 Improving Language Understanding by Generative Pre-Training
❗️개념을 정리하기 위해 작성한 글로, 내용상 잘못된 부분이 있을 수 있다는 점 참고 바랍니다.
논문에서는 순서가 아래와 같이 구성되어있다.
- Introduction
- Related Work
- Framework
- Unsupervised pre-training
- Supervised fine-tuning
- Experiments
- SetUp
- Supervised fine-tuning
- Analysis
- Conclusion
이 글은 논문 순서를 그대로 따라가기보다는 내가 공부할 때 이해하기 편했던 흐름대로 작성하려고 한다.
Introduction
NLP 분야는 labeled data가 한정적이기 때문에 raw text로부터 효율적으로 학습하는 것이 중요하다.
(∵ manually labeling하기 어려움 + 나라마다 언어가 다르다는 문제점)
따라서 지도학습 의존도를 줄이고자 Unsupervised learning에 집중하기 시작했다.
하지만 비지도학습으로는 단어 수준 이상의 정보를 얻기 어려웠는데, 이유는 아래 2가지와 같다.
- pre-train으로 text-representation을 학습시킬 때, 어떤 최적화 목적을 써야 할 지 불분명함
- 학습된 text-representation을 target task에 적용할 때 가장 효율적인 전달 방식이 정해지지 않음
이 2가지 모호성 때문에 비지도학습에서 어려움을 겪었지만
최근 연구에 따라 1번 문제의 경우, language modeling, machine translation, discourse coherence가 성능이 좋다는 것이 밝혀졌다.
⇒ GPT는 대용량의 unlabeled text로 language modeling objective에 대해 pre-training하고 사전 학습된 파라미터를 labeled data로 fine-tuning하는 semi-supervised learning 방식을 진행했다.
Language Modeling
= being trained to predict the next word in a sequence of words
= 다음 단어 예측 task
Framework
GPT는 별도의 input이 존재하지 않기 때문에 Transformer 중 Decoder만을 사용하여 모델을 구성했다.
Transformer는 LSTM이나 기존 RNN에 비해 아래와 같은 측면에서 더 우수한 성능을 보였다.
- 구조화된 메모리로 long-term dependencies(= 참조할 문맥의 범위가 더 넒음)에 제약이 적음
- 다양한 task에 robust하게 transfer 가능함
Unsupervised pre-training
: 대용량의 unlabeled corpus로 language model 만들기
→ 다음 단어 예측
- : 현재 토큰 이전의 모든 토큰에 대한 context vector들을 모아둔 행렬
- , : embedding 가중치, position 가중치
→ self-attention을 통해 context 행렬 가 개의 transformer block을 거쳐 예측하고자 하는 토큰의 확률 분포 구하기
결과적으로는
⇒ k번째 이전 단어부터 직전 단어까지 주어졌을 때, 현재 단어가 나올 확률이 최대가 되도록 사전 학습 단계에서 모델을 학습시켜야 한다.
Supervised fine-tuning
: labeled data를 이용해 모델을 특정 task에 적용하기
- : input token
- : label
- : labeled data
결과적으로는
⇒ 입력 토큰들이 주어졌을 때 정답 라벨(= 다음에 나타날 단어)로 예측할 확률이 최대가 되도록 모델을 학습시킨다.
fine-tuning을 할 때 별도로 필요한 파라미터는 라벨에 대한 가중치인 하나로, pre-train과 fine-tuning 시 모델의 구조가 거의 달라지지 않는 장점이 있다.
pre-trained된 모델에 labeled data를 넣어 pre-train 방식대로 모델을 한 번 더 학습시키고 이후 fine-tuning을 하기도 한다.
이 경우, supervised model에 대한 일반화 성능이 향상된다는 장점이 있다.
+) generalization
: 같은 데이터로 다른 task를 한다 (X)
: 같은 task에 다른 새로운 데이터를 사용한다 (O)
⇒ 위와 같이 language modeling을 fine-tuning의 보조 목적으로 사용하면 완전히 새로운 데이터를 넣었을 때도 같은 task에 대해서는 성능이 잘 나오게 된다.
task-specific input transformations
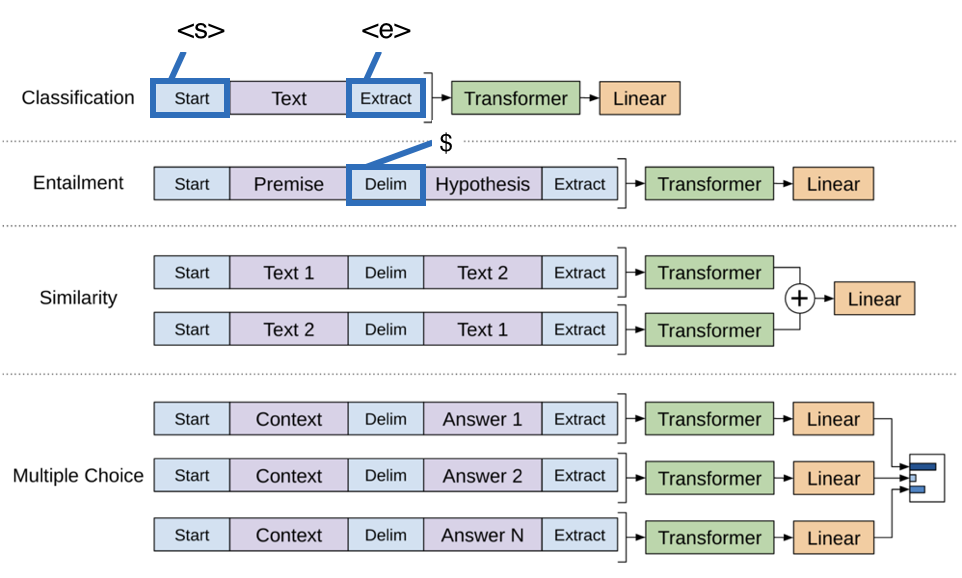
task마다 구조화된 input을 모델 입력용 sequence로 변환하는 과정이 필요하다.
Input : structured inputs → token sequences
이때 task마다 변환 형태가 약간 달라지지만
공통적으로 문장의 시작과 끝에 <s>, <e> 토큰을 넣어줘야 한다.
Conclusion
GPT vs. Transformer vs. BERT
GPT와 BERT 모두 Transformer에서 파생된 모델이지만 목적과 구조가 확연히 다르다.
Transformer
기계 번역을 목적으로 만들어진 모델로,
『언어 A에 대한 특징을 파악하는 Encoder + 언어 B에 대한 특징을 파악하고 이를 Encoder에서 얻은 특징과 결합해 A → B로 번역하는 Decoder』 로 구성되었다.
BERT
딥러닝으로 word embedding을 효과적으로 수행하기 위해 만들어진 모델로,
『Encoder의 self-attention + masking된 입력』으로 구성되어 양방향 참조를 통해 문맥을 파악할 수 있다.
GPT
생성을 위한 모델로,
『Linear, softmax layer가 포함된 Decoder』만을 사용해 다음 단어가 나올 확률을 잘 예측하도록 설계되었다.
References
📍 Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
ㄴ GPT 뿐만 아니라 전반적인 NLP에 대해 정말 설명이 잘 되어있다. 읽어보면서 많은 도움이 되었다 👍🏻
📍 Improving Language Understanding by Generative Pre-Training (GPT1)
📍 트랜스포머 기반 자연어처리 모델 간략하게 훑어보기
📍 Transformer (Attention Is All You Need) 구현하기 (1/3)
