Image Segmentation
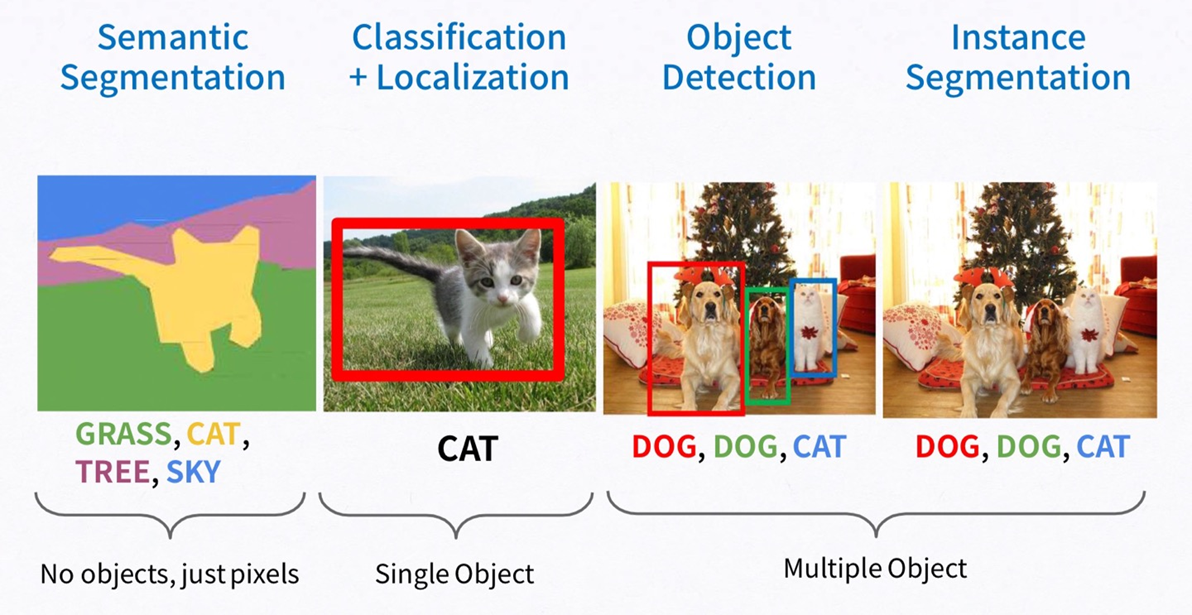
이번 여름동안 중점적으로 공부하게 될 분야는 Image Segmentation입니다. Computer Vision 분야 중 하나로 이미지 내에서 픽셀 수준으로 물체를 구분하는 기술입니다. Segmentation은 크게 두가지 방식으로 다음과 같이 나뉘게 됩니다:
- Semantic Segmentation: 같은 class에 해당하는 object들은 같은 영역으로 분할한다.
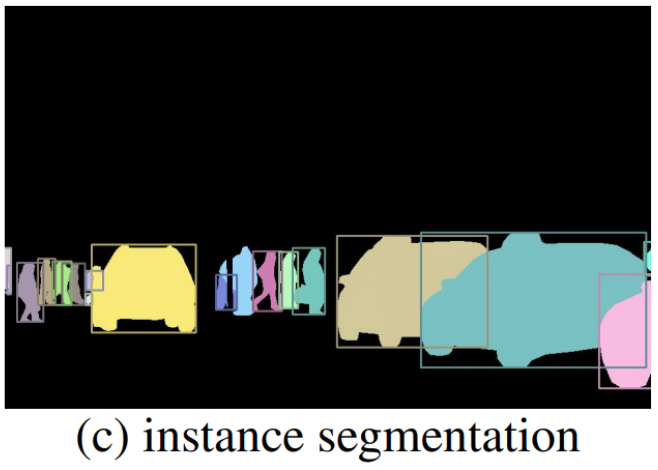
- Instance Segmentation: 같은 class여도 서로 다른 instance로 구분하여 분할한다.
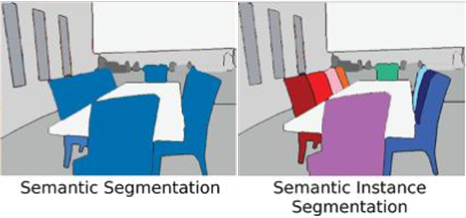
Semantic Segmentation vs. Instance Segmentation
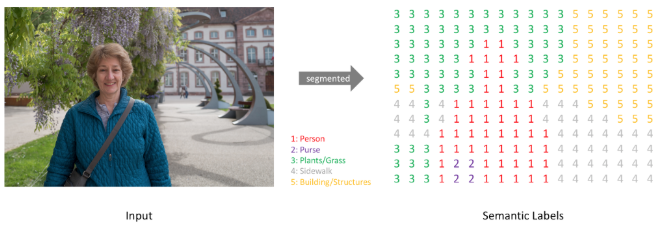
Semantic Segmentation의 경우 각 픽셀별로 어떤 class에 속하는지 라벨링을 해주어야 한다. 따라서, 각 class에 대해 class의 갯수만큼 output map을 만들어, 각각의 픽셀이 어느 class에 속하는지 One-Hot encoding을 통해 output을 출력한다. 따라서, 만약 class의 갯수가 10개라면, output은 {image의 크기} x 10개의 output을 갖게 되는 것이다.
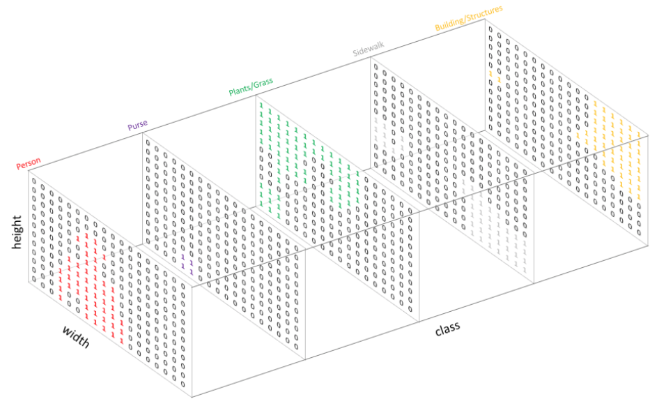
Semantic Segmentation의 단점으로는 같은 class의 다른 object들에 대해서는 서로 구분할 수 없다는 것이다. 하지만, 이번 연구에서는 object들을 서로 구분하는 것이 최종 목표에 크게 의미가 없기 때문에, 비교적 간단한 Semantic Segmentation을 사용하게 될 것이다.
참고로 Instance Segmentation과 결과물을 비교해 봤을 때에는 다음과 같다:

Reference
https://ganghee-lee.tistory.com/44

대학원생(진)