
Today's Wrap-up
-
모델 성능 개선 방안
-
Label Smoothing(Customized)
- GT index에서 떼어낸 작은 값을 모든 index에 동일하게 나누는 기존의 방식과 달리, 레이블 간의 유사성에 따라 나누었다. Mask, Gender task에서는 큰 상관관계가 없다고 판단됐을 뿐 더러, 이미 모델의 정확도가 97~99%를 달성하고 있었기 때문에 해당 기법을 적용하지 않았고, Age task에만 적용하였다.
- Age task는 총 3개의 클래스(young : 0~29세, middle : 30~59세, old : 60세 이상)로 구성되어 있는데, 데이터 특성 상 1살 차이로 레이블이 바뀔 수 있기 때문에 인접한 클래스에만 0.1~0.2씩 나누어 Label Smoothing을 주었다.
-> Age class를 기존 3개에서 조금 더 세분화 했으면 어땠을까 하는 아쉬움이 남는다.
-
Pseudo Labeling
- Pseudo Labeling을 선택한 가장 큰 배경은 결과적으로 18-classification task치고 데이터셋이 부족하다고 판단되었다. Pseudo Labeling을 수렴할 때까지 돌려보진 못하고 한번밖에 적용하진 못 했다는 것이 아쉽다. 대회 종료 후 김태진 마스터님께서 양날의 검이니 주의해서 사용해 볼 것을 당부하셨다.
-
Facecrop by FaceNet(MTCNN) and RetinaFace
- 모델이 데이터를 이해하고 분류한는 데 얼굴 부분이 많은 영향을 주고 있다고 판단했고, Facecrop을 진행하였다. 지금 생각해보니 Grad cam을 통해 모델이 데이터의 어느 부분에 많은 영향을 받고 있는지 확인해보지도 않고 당연하게 판단한 것 같다.
- Dataset을 불러오는 과정에 crop을 진행하게 되면 시간이 오래걸릴 뿐 아니라, 모델 학습 과정에서 매번 반복되어야 하다 보니 facecrop된 이미지를 따로 저장해두고 해당 이미지를 불러오는 방식으로 진행하였다.
-
K-fold 및 Ensemble(soft voting)
- 1사람 당 7장의 데이터(마스크 착용 5장, 미착용 1장, 이상하게 착용 1장)로 구성이 되어있었고, 아무런 기준 없이 임의로 나눌 경우 같은 사람의 데이터가 train_set과 validation_set에 나뉠 수 있는 상황이었다. 그렇게 되면 train에서 학습된 age, gender를 바탕으로 validation에서 cheating이 발생할 가능성이 높다고 판단되었고, 동일한 사람의 데이터는 train 또는 validation에만 들어가도록 grouping을 해주어야 했다. 뿐만 아니라, 데이터가 imbalance 하기 때문에 모든 Fold가 Stratified 해야 했기 때문에 ’pandas_streaming’이라는 library를 통해 위와 같은 사안들을 고려하여 해당 기능을 구현하였다.
- Ensemble 코드가 대회 종료를 1시간 앞두고 완료되었고, 구현 과정에서 상대경로로 잡아주지 않아 다른 팀원 분이 사용했을 때 에러가 발생되었고, K-fold로 학습된 모델의 앙상블을 진행해보진 못 했다.
-
외부 데이터셋 추가
- Age task에서 모델 성능이 나오지 않는 이유 중 하나가 old class의 데이터가 60세 밖에 없어서 임의로 old class를 58세로 낮추었지만, 추가적인 데이터가 필요하다고 판단되어 AAFD(All-Age-Face-Dataset)을 활용하여 데이터를 보강하였다.
-
Backbone 다양화
- 최초에 팀원들과 Backbone 모델(VGG, ResNet, DenseNet, EfficientNet, ViT 등)을 나누어 approach하였고, 깊은 모델은 오버피팅이 발생되어서 그런 것인지 확실치는 않지만 얕은 모델이 더 효과적이라고 판단되었다. 결과적으로 추후에 여러 실험을 거치면서 ResNet152으로 확정지었다.
-
전처리 및 Augmentation 기법 다양화
- Blur, Gaussian noise, Cutmix, Normalization, Facecrop 등 다양하게 적용해보았으나, 최종 제출 모델에서는 Facecrop, Normalization만 적용
-
-
대회 결과
- Private LB(2nd/38team) / Public LB(6th/38team)
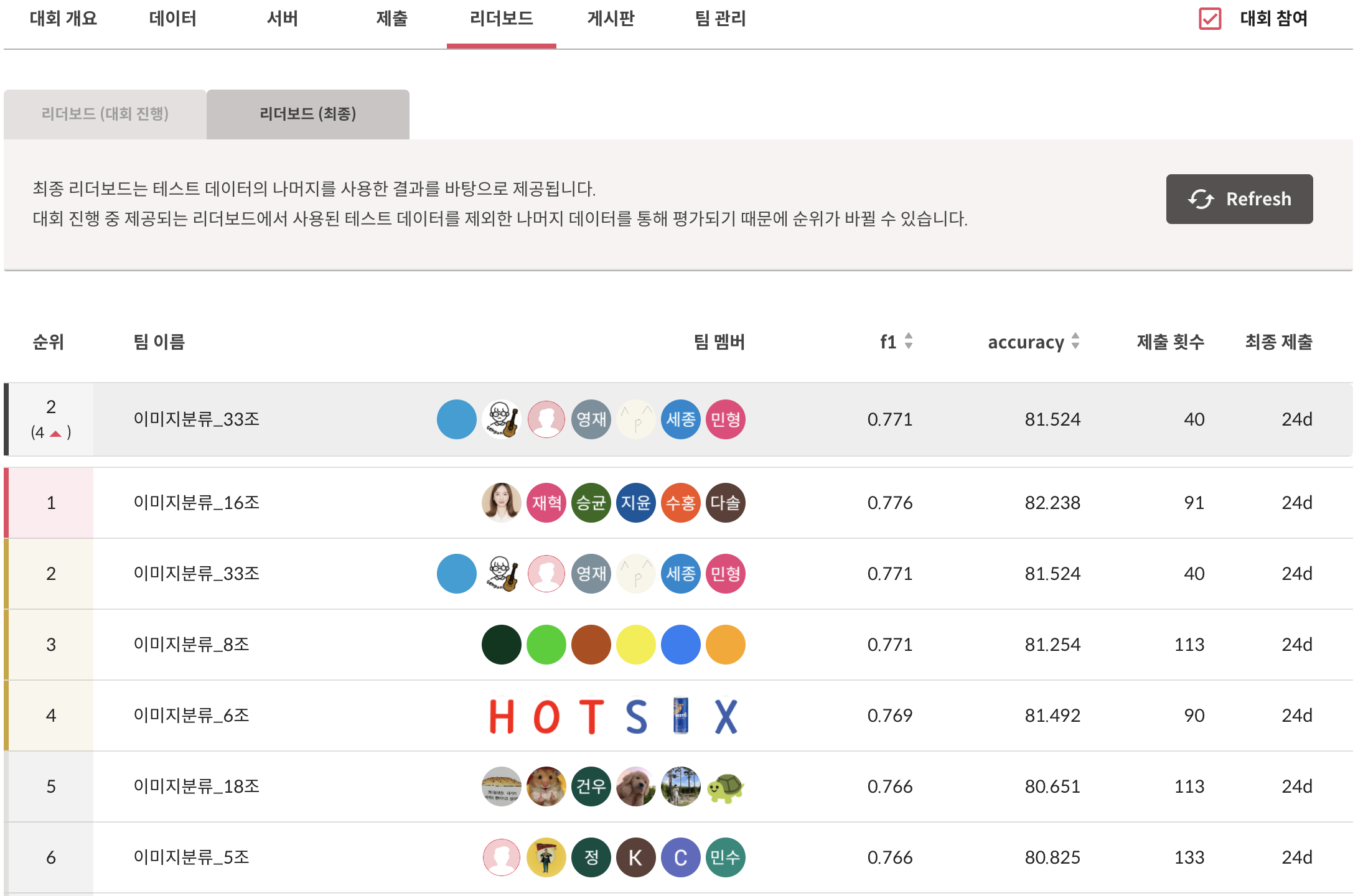
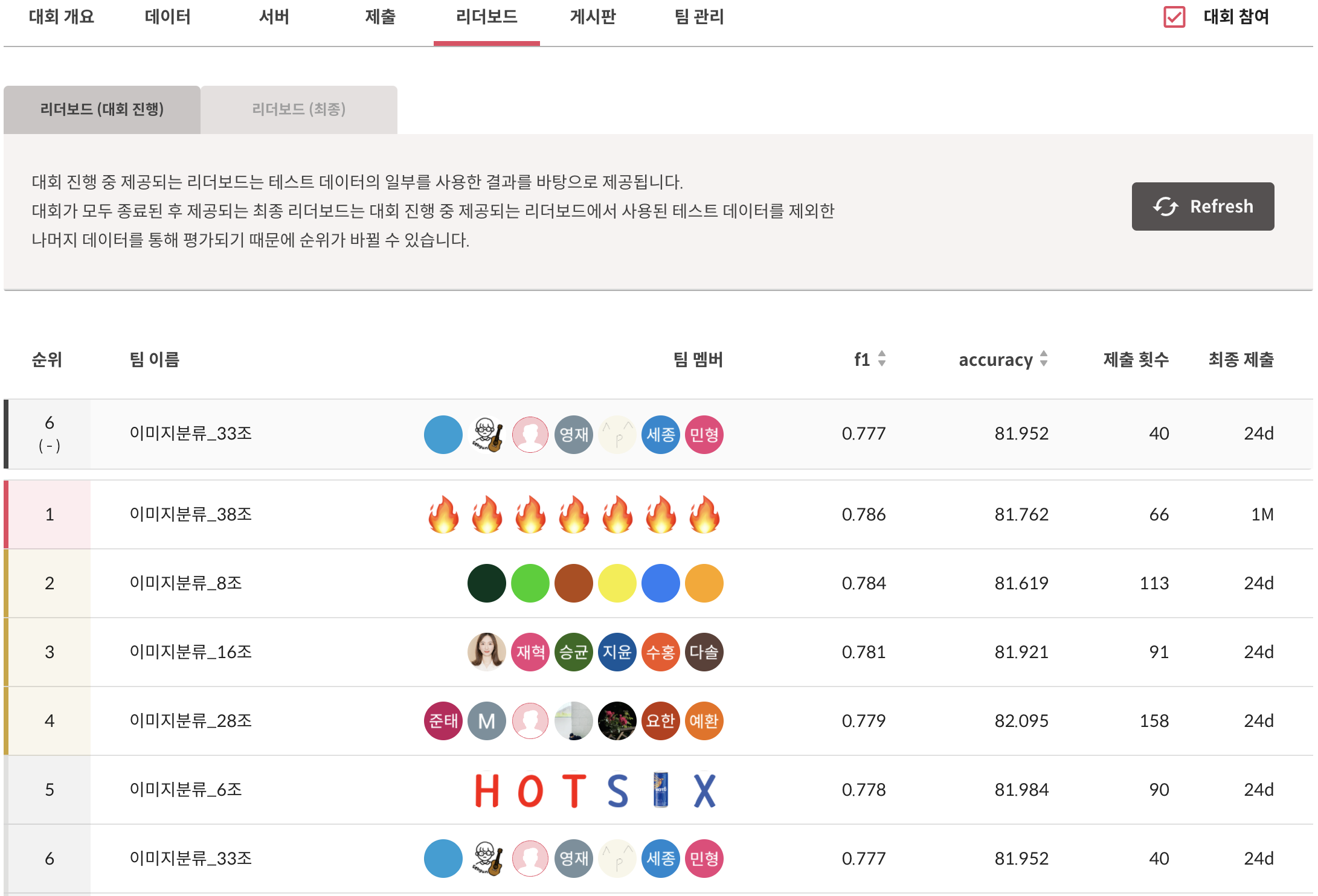
- Private LB(2nd/38team) / Public LB(6th/38team)
느낀점
일단 이번 P-stage에서 협업의 힘을 경험했고, 다음 스테이지에서도 팀원들과 분업과 협업을 통해 다각도로 appoach를 해보면서 그 과정과 발생한 insight나 내용들을 공유할 생각이다. 무엇보다 baseline을 구축 후, 동일한 baseline에서 팀원들이 각자 디벨롭할 수 있는 부분들을 나눠 작업했던 게 이번 P-stage에서 높은 성적을 기록할 수 있었던 이유라고 생각되기 때문에 baseline을 빠르게 구축할 수 있도록 할 것이다.
무엇보다 가장 아쉬웠던 것이 뒤늦게 적용을 해보려고 했던 것들이 시간이 부족해 적용해보지 못했다는 것이고, 가장 큰 이유가 자는 시간 동안 서버에서 wandb 스윕을 통해 돌려보지 못한 것이 원인이라 생각된다. 다음 스테이지에서 파라미터 실험은 자는 동안 돌아가도록 하고, 일어나 있는 시간은 기능 구현과 디버깅에 집중해 볼 것이다.
