
수업 정리
1. [NLP] Intro to NLP, Bag-of-Words
- Bag-of-Words Representation
- Step 1. Constructing the vocabulary containing uniqe words
- Example sentences : "John really loves this movie", "Jane really likes this song"
- Vocabulary : {"John", "really", "loves", "this", "movie", "Jane", "likes", "song"}
- Step 2. Encoding unique words to one-hot vectors
- Vocabulary : {"John", "really", "loves", "this", "movie", "Jane", "likes", "song"}
- Jone : [1 0 0 0 0 0 0 0]
- really : [0 1 0 0 0 0 0 0]
- loves : [0 0 1 0 0 0 0 0]
... - likes : [0 0 0 0 0 0 1 0]
- song : [0 0 0 0 0 0 0 1]
- For any pair of words, the distance is
- For any pair of words, cosine similarity is 0
- Vocabulary : {"John", "really", "loves", "this", "movie", "Jane", "likes", "song"}
- A sentence/document can be represented as the sum of one-hot vectors
- Vocabulary 상에 존재하는 각 word 별로 bag을 준비한 다음 특정 문장에서 나타난 word들을 순차적으로 해당하는 가방에 넣어준 후, 최종적으로 각 차원에 해당하는 가방에 들어간 word의 수를 세어 최종 벡터로 나타냄
- Sentence 1 : "John really really loves this movie"
- Jonh + really + reall + loves + this + moive : [1 2 1 1 1 0 0 0]
- Sentence 2 : "Jane really likes this song"
- Jane + really + likes + this + song : [0 1 0 1 0 1 1 1]
- NaiveBayes Classifier for Document Classification
- Bag-of-Words for Document Classification
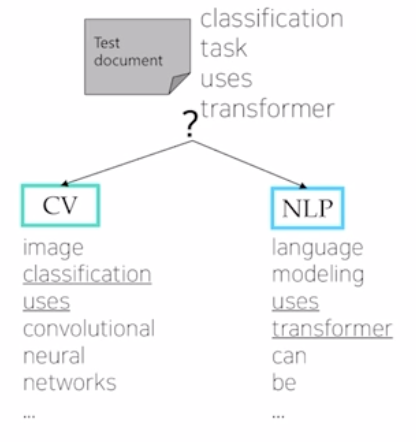
- Bayes' Rule Applied to Documents and Classes

- For a document , which consists of a sequence of words , and a class
- The probability of a document can be represented by multiplying the probability of each word appearing
- (by conditional independence assumption)
2. [NLP] Word Embedding
-
What is Word Embedding
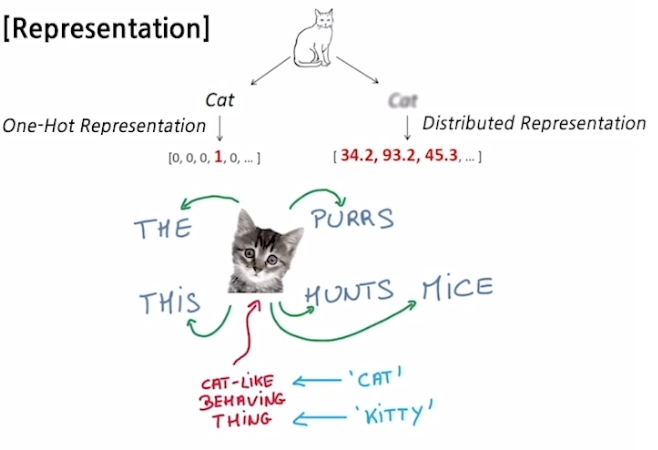
- Express a word as a vector
- 'cat' and 'kitty' are similar words, so they have simialr vector representations short distance
- 'hamburger' is not similar with 'cat' or 'kitty', so they have different vector representations far distance
-
Word2Vec
- An algorithm for training vector representation of a word from context words(adjacent words)
- Assumption : words in similar context will have similar meanings
- e.g.,
- The cat purrs.
- This cat hunts mice.
-
Idea of Word2Vec
- "You shall know a word by the company it keeps" -J.R. Firth 1957
- Suppose we read the word "cat"
- what is the probability that we'll read the word w nearby?

- what is the probability that we'll read the word w nearby?
- Distributional Hypothesis : the meaning of "cat" is captured by the probability distribution
-
How Word2Vec Algorithm Works
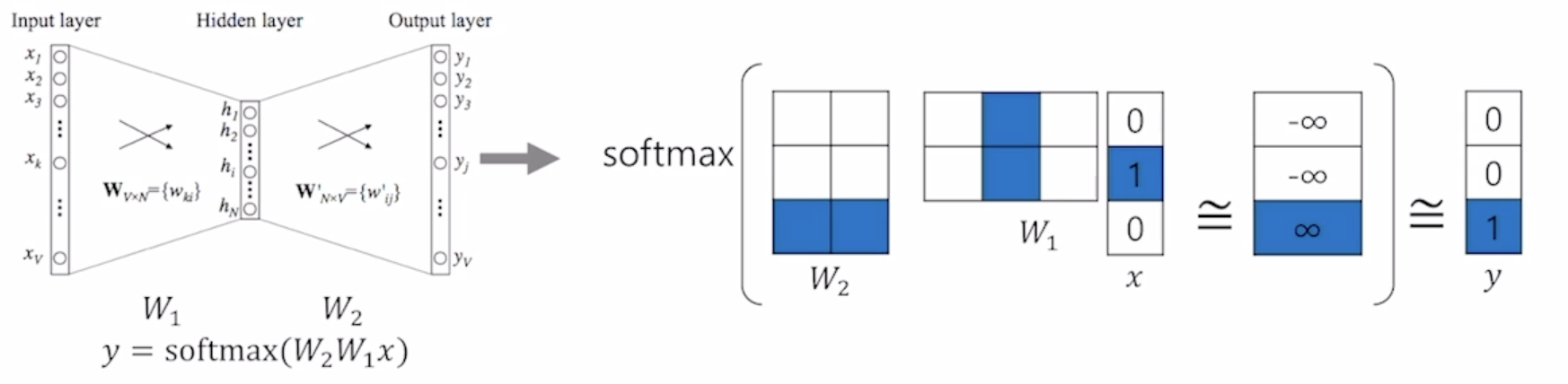
- Sentence : "I study math"
- Vocabulary : {'I', 'study', 'math'}
- Input : 'study' [0, 1, 0]
- Output : 'math' [0, 0, 1]
- Columns of and rows of represent each word
- E.g., 'study' vector : 2nd column in , 'math' vector : 3rd row in
- The 'study' vector in and the 'math' vector in should have a high inner-product value.
-
Another Example
- Word2Vec 로직 시각화
- Word2Vec Analogy Reasoning
- Word2Vec Analogy Reasoning2
- Word2Vec Intrusion Detection
- Instrusion : 여러 단어 중 의미가 가장 상이한 단어 찾는 것
-
GloVe : Global Vector for Word Representation
- Rather than going through each pair of an input and an output words, it first computes the co-occurrence matrix, to avoid training on identical word pairs repetitively.
- Afterwards, it performs matrix decomposition on this co-occurent matrix.
- Fast training
- Works well even with a small corpus
피어세션 정리
강의 내용 질의응답
- GloVe, 참고자료
- Word2Vec
- Negative sampling : softmax를 취할 때, 전체에 대해서 계산하는 것이 아니라 [정답 + 정답아닌 몇개 샘플링]으로 계산
- 질문) 2강 18분 19초에서, Input vector 하고 Output vector가 각각 뭘 나타내는지? 의미하는지? 모르겠습니다.
- random initialization 후에 학습하는 것?
- 답변) W1이 임베딩 역할, W2가 아웃풋을 만들기 위한 것?
- Word2Vec에서 꼭 원핫벡터를 사용할 필요는 없다?! → 멘토링 질문
Further Questions
- Word2Vec과 GloVe 알고리즘이 가지고 있는 단점은 무엇일까요?
과제 코드 리뷰
- 선택과제1번 : 돌리는데 2~30분
- 필수과제1번
- spacy 3.0 최신버전에서는 tokenizer에서 s(복수형)을 지워버리기 때문에 answer하고 맞지 않게 된다.
- 경험담) 많은 기능이 있어서 (성능은 좋을 수 있지만) 시간이 오래 걸린다. (다시 실험해보시고 공유해주신다고 함)
- 한국어 전처리
- mecab : 훨씬 빠르고, 제일 많이 사용됨
- twitter → okt : normalize, stemming 가능
자연어 처리 공부 추천
- ratsgo님 블로그
- 딥러닝을 이용한 자연어 처리 입문
- 한국어 임베딩 도서
기타
- 회의록 기록 : ClovaNote
- 컴퓨터 녹음 : obsproject
- SQL : hackerrank
- vscode 에서 실습하는 git : Youtube 링크
- 이번 주 계획
- 큰 문제가 없다면 목요일에 Transformer 논문 리뷰를 위해 4시 정도에 보는 것으로
느낀점
새로운 Ustage가 시작했습니다. 새로운 팀원들과 모여 공부할 기회가 주어졌고, 첫 피어세션을 하면서 다양한 시각과 생각으로 오늘 수업 내용을 이야기 나눠볼 수 있었습니다. 약 2주간 운영될 피어세션에서 다른 팀원 분들에게 많은 도움이 될 수 있도록 화이팅하겠습니다!!
NLP12조 화이티이이이이잉!!
