
수업 정리
강의 목록
[DL Basic] Optimization
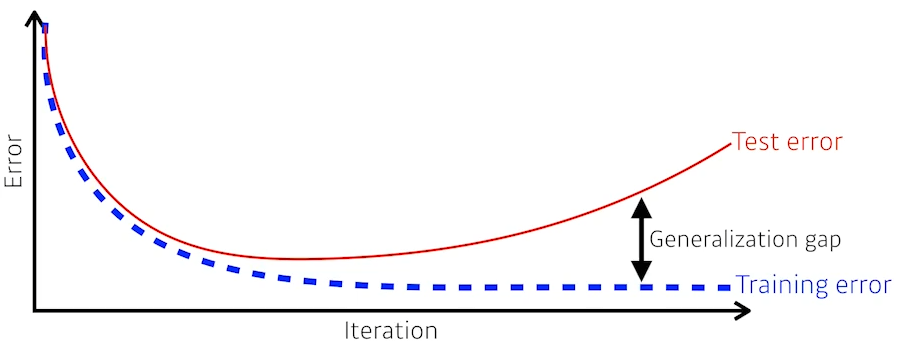
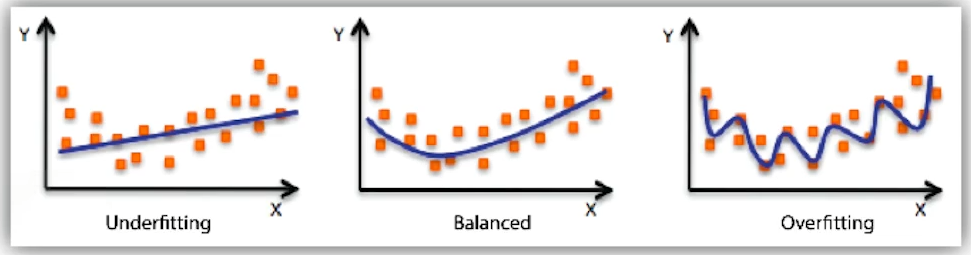
- Generalization
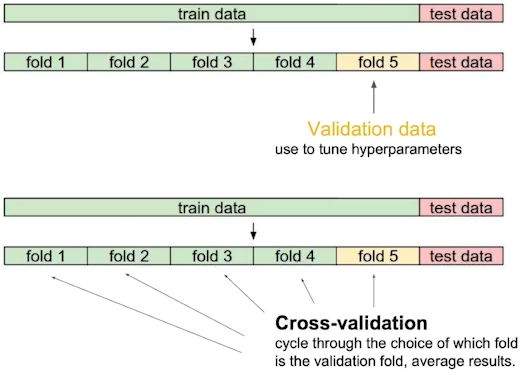
- Cross-validation(k-fold validation)
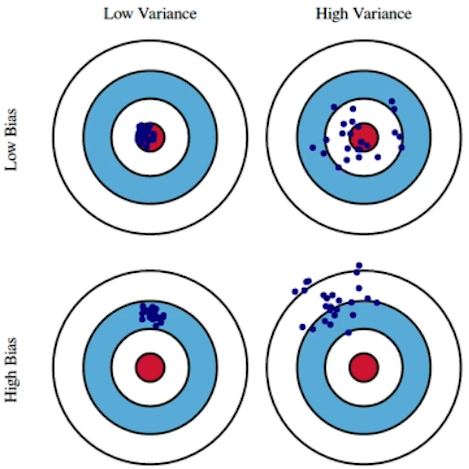
- Bias and Variance
- 학습데이터에 noise가 껴있을 경우, bias와 variance는 trade-off 관계에 있다
- Bootstrapping
- 학습데이터의 일부를 활용해 여러 개의 모델을 만들어 예측하는 기법
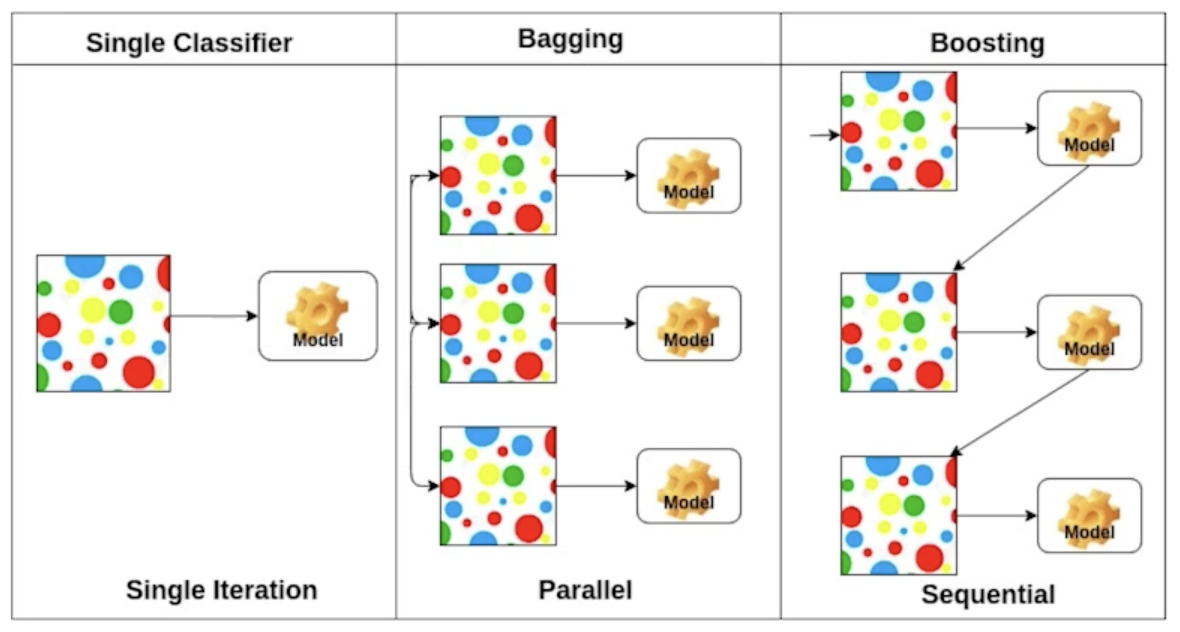
- Bagging vs Boosting
- Bagging : Bootstrapping aggregating, 복원 임의 추출을 통해 만든 여러 개의 모델을 앙상블하여 예측하는 기법
- Boosting : 모델이 예측하지 못하는 데이터에 대해 잘 동작하는 모델을 만들어 sequential하게 모델을 합쳐 하나의 모델을 만드는 기법
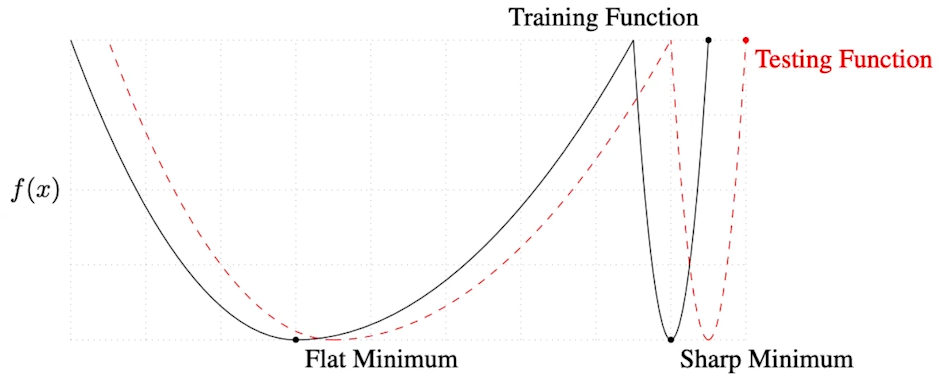
- Batch-size Matters
- sharp minimizer(large batch) vs flat minimizer(small batch)
- 이슈가 많은 부분으로 사료된다.
- Gradient descent methods
- SGD(Stochastic gradient descent)
- : learning rate, : gradient
- Momentum
- : accumulation, : momentum
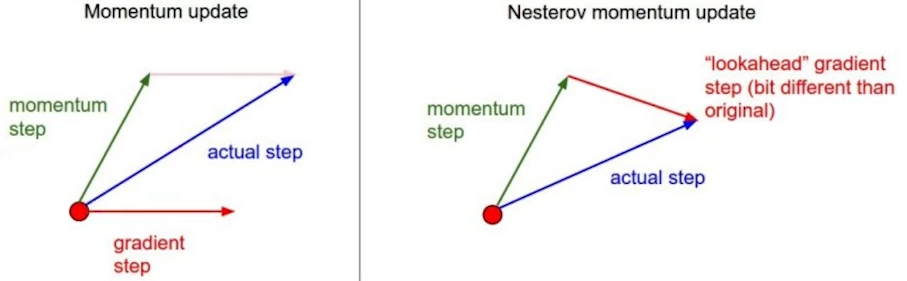
- Nestrov Accelerated Gradient
- : Lookahead gradient
- Adagrad
- : Sum of gradient squares, : for numerical stability
- 결국 학습이 진행될수록 는 계속해서 커지기 때문에 점점 학습이 이뤄지지 않게된다.
- Adadelta
- : EMA(exponential moving average) of gradient squares, : EMA of difference squares
- There is no learning rate!
- RMSprop
- : EMA of gradient squares, : stepsize
- Adam
- : Momentum, : EMA of gradient squares, : stepsize
- effectively combines momentum with adpative learning rate approach
- Regularization
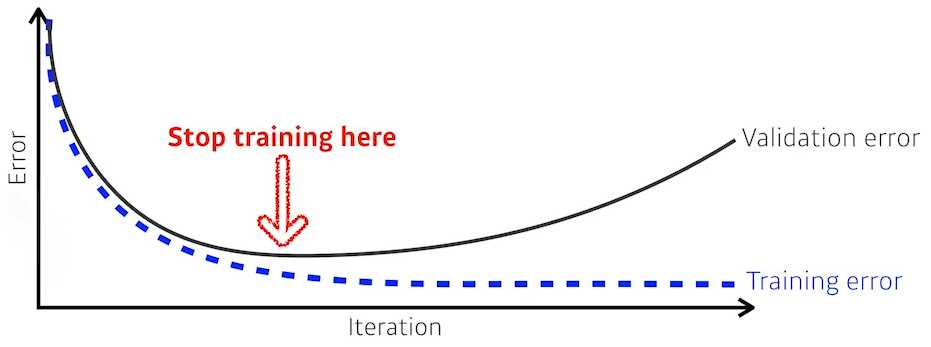
- Early stopping
- validation error가 튀는 부분에서 학습 종료
- Parameter norm penalty
- Weight Decay라고도 불리며, 파라미터가 너무 커지지 않게 하는 것
- 부드러운 함수일수록 generalization performance가 높을 것이라 가정
- total cost = loss
- Data augmentation
- Noise robustness
- noise를 데이터 뿐만 아니라 weight 값에도 넣어준다.
- 원인불명확
- Label smoothing
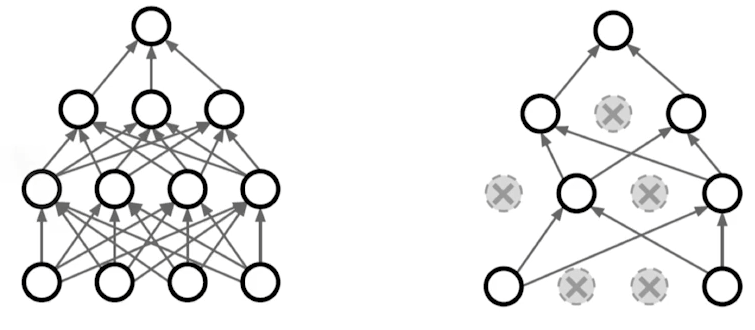
- Dropout
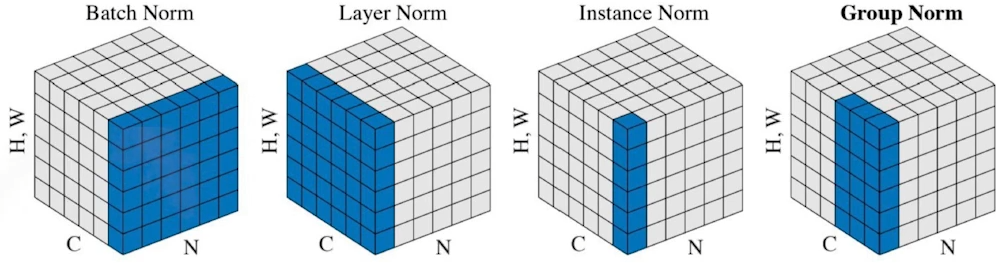
- Batch normalization
과제
- Optimization
- 실습 강의 보면서 완료
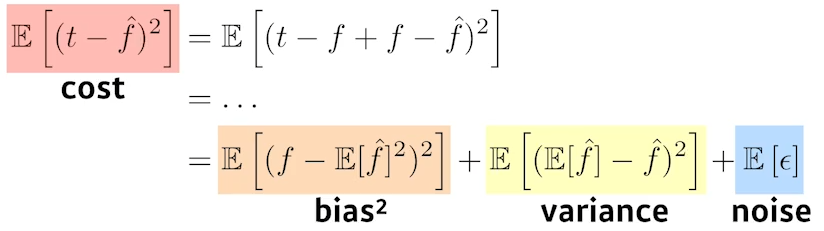


피어세션 정리
- NAG 개념 및 수식 이해
- Batch norm, Layer norm 개념 이해(추가적인 학습 필요)
- 이번주에 배울 RNN, Seq2Seq attn, Transformer 개념 선행학습 진행
느낀점
수식 쓰는 게 고생스럽다고 생각했는데, 직접 쓰면서 정리하다보니 머리에 더 남는듯합니다.
그리고 오늘까지는 강의 분량이 적어 수월했지만, 뭔가 폭풍전야 같은 느낌입니다...
내일 생활코딩 이고잉님의 특강이 있는데, 완전 기대중입니다!!
오늘 하루도 다들 수고많으셨습니다:)
