
수업 정리
1. [NLP] Sequence to Sequence with Attention
- Sequence to Sequence
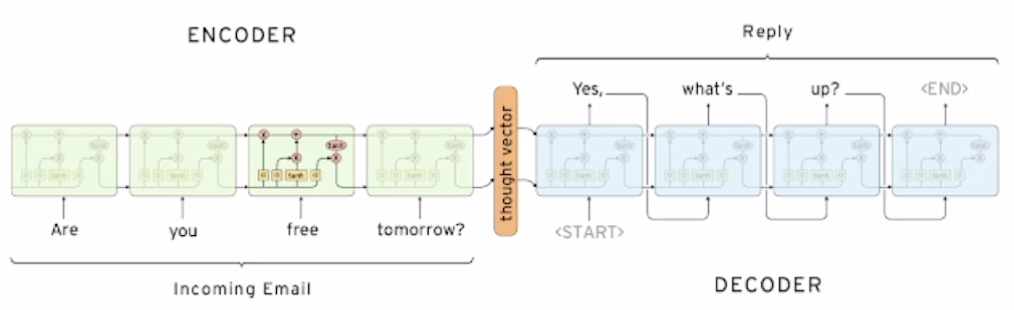
- it takes a sequence of words as input and gives a sequence of words as output
- it composed of an encoder and a decoder
- Sequence to Sequene with attention
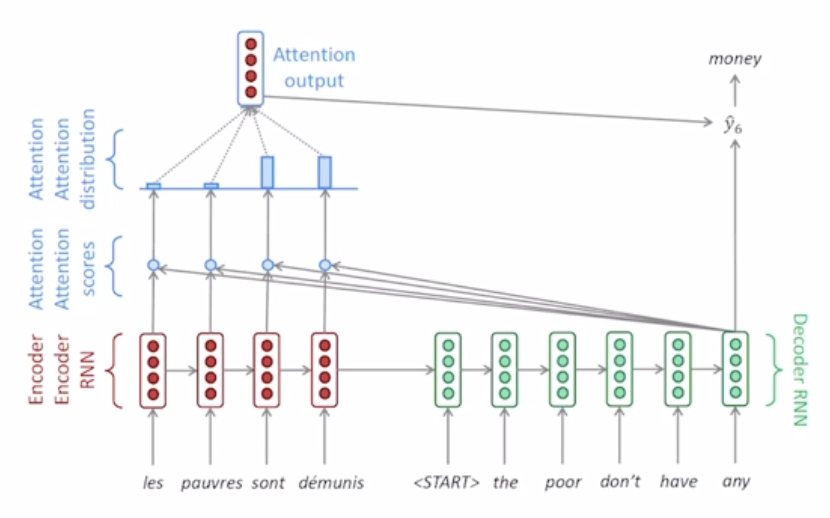
- Use the attention distribution to takse a weighted sum of the encoder hidden states
- The attention output mostly contains information the hidden states that received high attention
- Concatenate attention output with decoder hidden state, then use to compute as before
- Teacher forcing을 사용할 경우 학습이 더 빠르고 용이하게 진행되지만, test time에서 실제 모델을 사용하는 환경과는 다른 괴리를 갖기 때문에 적절하게 사용하는 학습방식도 존재(Teacher forcing ratio?)
- Attention significantly improves NMT performance
- It is useful to allow the decoder to focus on particular parts of the source
- Attention solves the bottleneck problem
- Attention allows the decoder to look directly at source; bypass the bottleneck
- Attention helps with vanishing gradient problem
- Provides a shortcut to far-away states
- Attention provides some interpretability
- By inspecting attention distribution, we can see what the decoder was focusing on
- The network just learned alignment by itself
- Differnet Attention mechanism
- Luong :
- they get the decoder hidden state at time , then calculate attention scores, and from that get the context vector which will be concatenated with hidden state of the decoder and then predict the output.
- Luong has different types of alignments. Bahdanau has only a concat-score alignment model.
- Bahdanau :
- At time , we consider the hidden state of the decoder at time . Then we calculate the alignment, context vectors as above. But then we concatenate this context with hidden state of the decoder at time . So before the softmax, this concatenated vector goes inside a LSTM unit.
2. [NLP] Beam Search and BLEU score
Beam Search
-
Greedy decoding
- Greedy decoding has no way to undo decisions!
- input : il a m’entarté (he hit me with a pie)
→ he
→ he hit
→ he hit a ___ (whoops, no going back now...)
- input : il a m’entarté (he hit me with a pie)
- How can we fix this?
- Greedy decoding has no way to undo decisions!
-
Exhaustive search
- Ideally, we want to find a (length ) translation that maximizes
- We could try computing all possible sequences
- This means that on each step of the decoder, we are tracking possible partial translations, where is the vocabulary size
- This complexity is far too expensive!
- Ideally, we want to find a (length ) translation that maximizes
-
Beam search
- Core idea : on each time step of the decoder, we keep track of the k most probable partial translations (which we call hypothesis)
- is the beam size(in practice around 5 to 10)
- A hypothesis has a score of its log probability:
- Scores are all negative, and a higher score is better
- We search for high-scoring hypotheses, tracking the top k ones on each step
- Beam search is not guaranteed to find a globally optimal solution.
- But it is mych more efficient than exhaustive search!
- Core idea : on each time step of the decoder, we keep track of the k most probable partial translations (which we call hypothesis)
-
Beam search: Example
- Beam size :
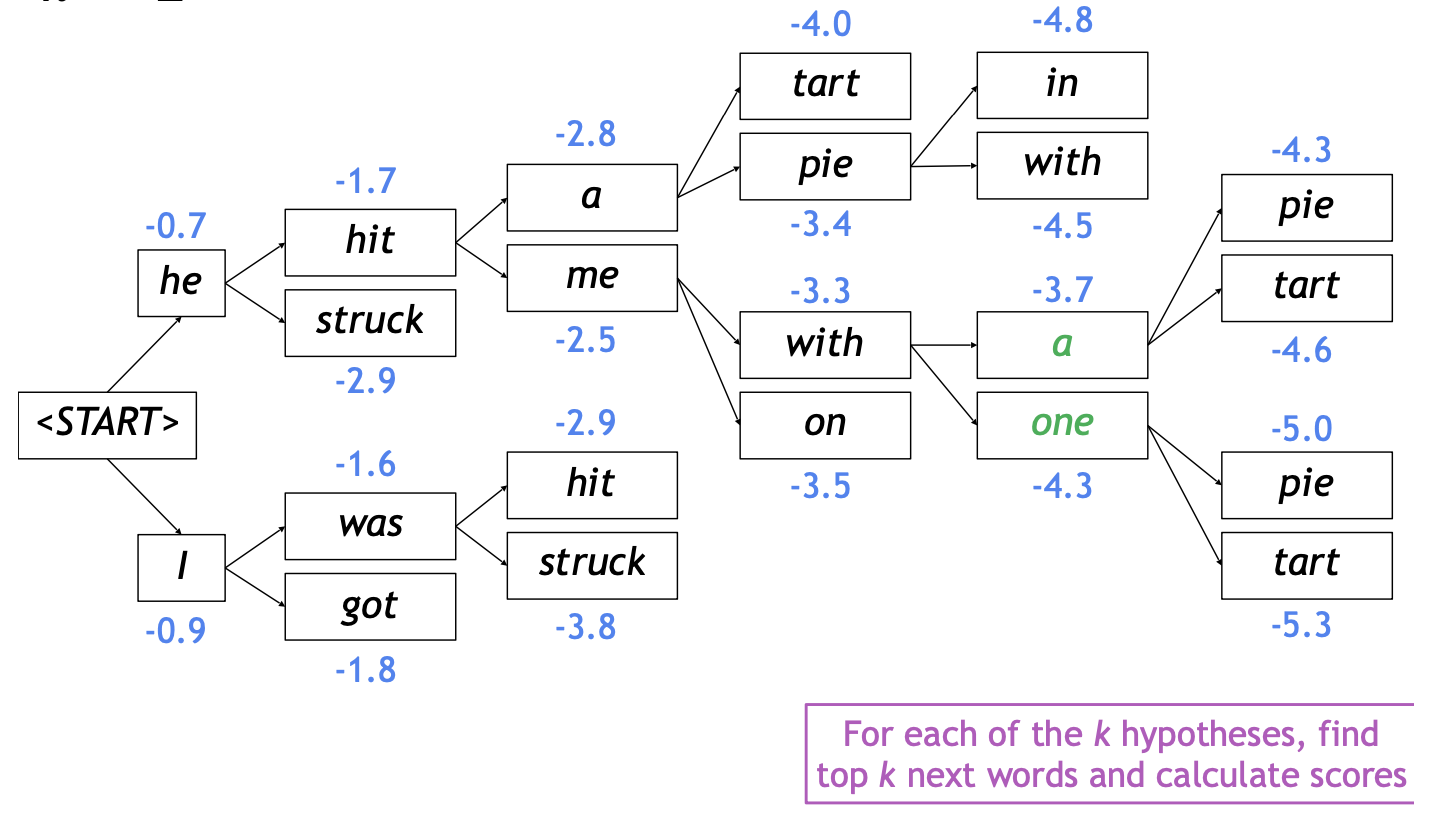
- Beam size :
-
Beam search: Stopping criterion
- In greedy decoding, usually we decode until the model produces a <END> token
- For example: <START> he hit me with a pie <END>
- In beam search decoding, different hypotheses may produce <END> tokens on different timesteps
- When a hypothesis produces <END>, that hypothesis is complete
- Place it aside and continue exploring other hypotheses via beam search
- Usually we continue beam search until:
- We reach timestep 𝑇 (where 𝑇 is some pre-defined cutoff), or
- We have at least 𝑛 completed hypotheses (where 𝑛 is the pre-defined cutoff)
- In greedy decoding, usually we decode until the model produces a <END> token
-
Beam search: Finishing up
- We have our list of completed hypotheses
- How to select the top one with the highest score?
- Each hypothesis on our list has a score
- Problem with this: longer hypotheses have lower scores
- Fix: Normalize by length
BLEU score
-
Precision and Recall
- Reference : Half of my heart is in Hanvana ooh na na
- Predict : Half as my heart is in Obama ooh na

- Reference : Half of my heart is in Havana ooh na na
- Predict(from model 1) : Half as my heart is in Obama ooh na
- precision - 78% / recall - 70% / F-measure - 73.78%
- Predict(from model 2) : Havana na in heart my is Half ooh of na
- precision - 100% / recall - 100% / F-mesuere - 100%
-> Flaw : no penalty for reordering
- precision - 100% / recall - 100% / F-mesuere - 100%
-
BiLingual Evaluation Understudy (BLEU)
- N-gram overlap between machine translation output and reference sentence
- Compute precision for n-grams of size one to four
- Add brevity penalty (for too short translations)
- Typically computed over the entire corpus, not on single sentences
- F-meaure는 조화평균 BLEU는 기하평균(조화평균의 경우 크기가 작은 값에 지나치게 큰 가중치를 주기 때문)
피어세션 정리
강의 내용 관련
Further Question
- BLEU score가 번역 문장 평가에 있어서 갖는 단점은 무엇이 있을까요?
- 참고: Tangled up in BLEU: Reevaluating the Evaluation of Automatic Machine Translation Evaluation Metrics
- 단점 : 어순이 반대인 언어인 경우, 한국어의 경우 동의어 문제, 한국어는 어순이 자유로운 편
과제 내용 관련
- 질문) 필수과제 4번에서, process 함수 만들 때, try, except을 활용해서 조금 더 빠르게 동작하는 코드를 작성하라고 했는데 어떤 식으로 가능한지 궁금합니다.
- Bucketing
- 트랜스포머 내에서도 배치 단위 안에서 유사한 길이로 하면 행렬 연산할 때 이점이 있을 것 같다.
- Tensorflow에서는 RNN의 cell 개수를 fix 하기 때문에 헷갈리기 쉬웠다.
- Batch_first = True 자주 쓰이는지 → 멘토님께 질문
기타

- 구현 후 테스트해보기 좋은 데이터셋
느낀점
오늘부터 다음 p_stage에서 함께할 조원들 명단을 받기 시작했습니다... 알아서 팀을 구성하라고 하는데 이런거 잘 못하지만,,,,,, 남은 부스트캠프를 전부 함께해야하는 팀이니깐 화이팅,,,,
