
수업 정리
1. [NLP] Recurrent Neural Network and Language Modeling
- Recurrent Neural Network
- Basic structure
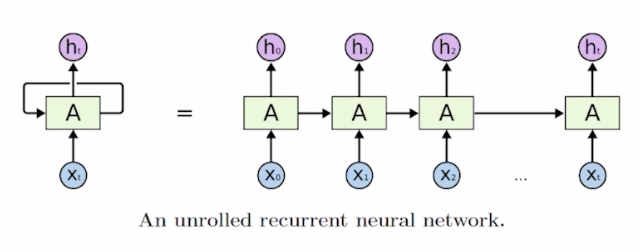
- Inputs and outputs of RNNs(rolled version)
- We usually want to predict a vector at some time steps
- How to calculate the hidden state of RNNs
- We can process a sequence of vectors by applying a recurrence formula at every time step
- The same function and the same set of parameters are used at every time step
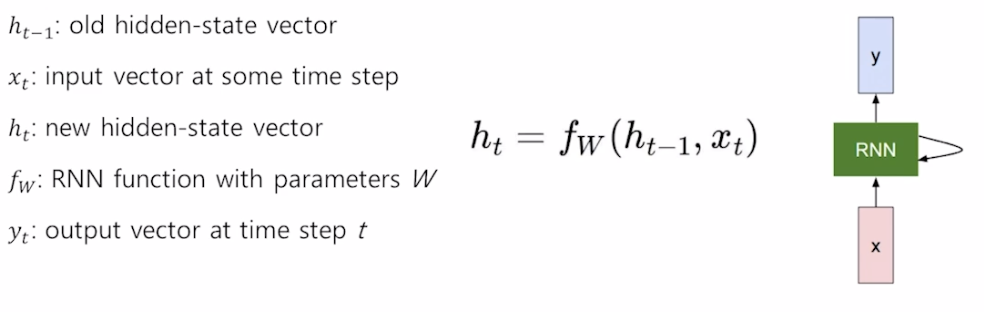
- The state consists of a single "hidden" vector
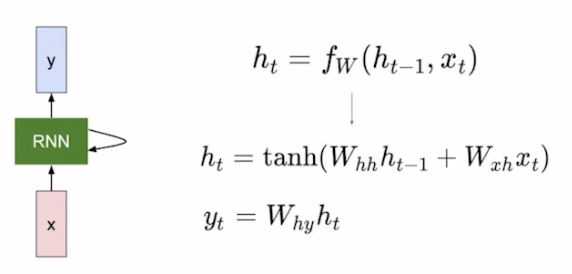
- Types of RNNs
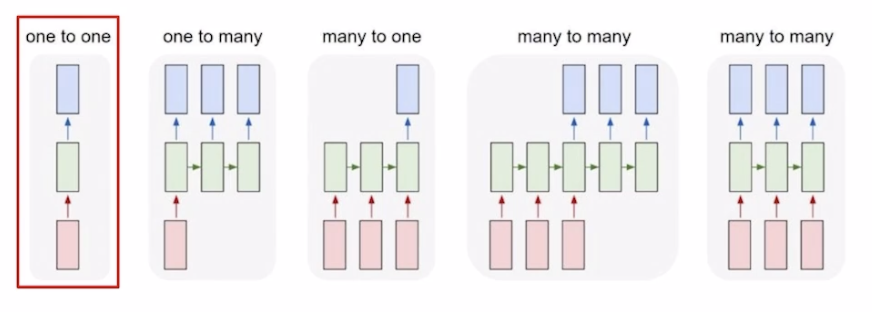
- One-to-one
- Standard Neural Networks
- One-to-many
- Image Captioning
- Many-to-one
- Sentiment Classification
- Many-to-many(Seq2Seq)
- Machine translation
- Many-to-many
- Video classification on frame level
- NER, POS
Character-level Language Model
- Example of training of training sequence "hello"
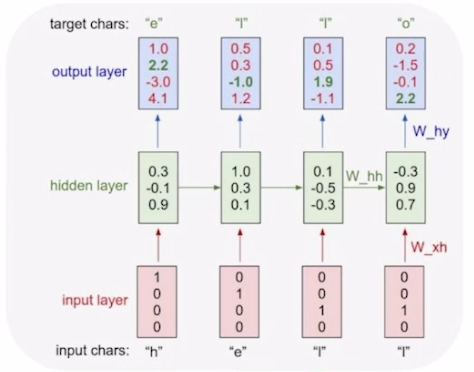
- Vocabulary : [h, e, l, o]
- Example training sequence : "hello"
- At test time, sample characters one at a time, feed back to model
Backpropagation through time(BPTT)
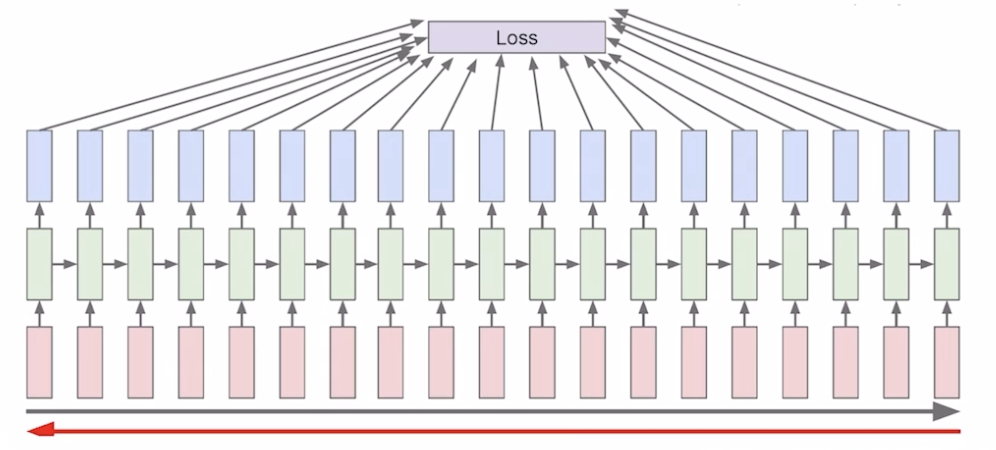
- Forward through entire sequence to compute loss, then backward through entire sequence to compute gradient
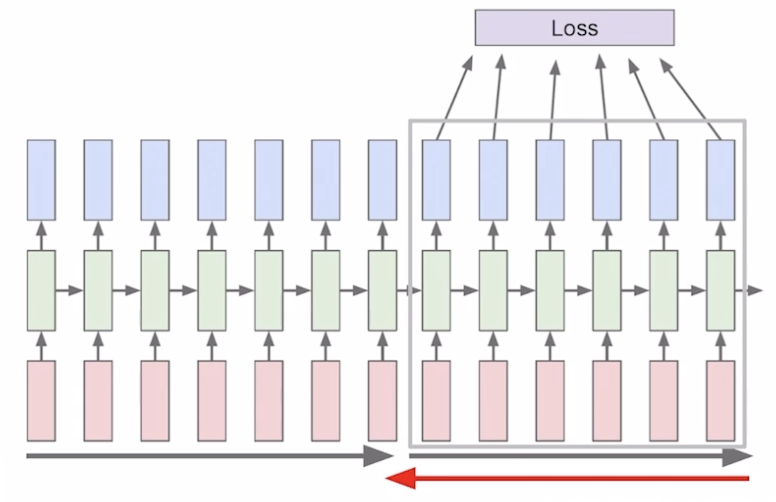
- Run forward and backward through chunks of the sequence of whole sequnce and carry hidden states forward in time forever, but only backpropagate for some smaller number of steps
Vanishing/Expolding Gradient Problem in RNN
- RNN is excellent, but...
- Multiplying the same matrix() at each time step during backpropagation causes gradient vanishing or exploding
- Toy Example
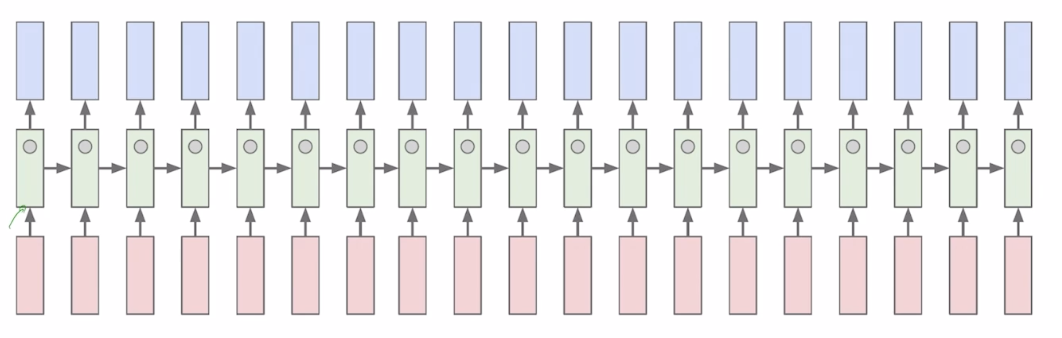
- The reason why the vanishing gradient problem is import tant(참고 링크)
- 이미지는 를 의미하고, 숫자는 timestep을 의미하며, 회색이 되가는 것은 0이 되는 것을 의미
2. [NLP] LSTM and GRU
- Long Short-Term Memory(LSTM)
- What is LSTM(Long Short-Term Memory)?
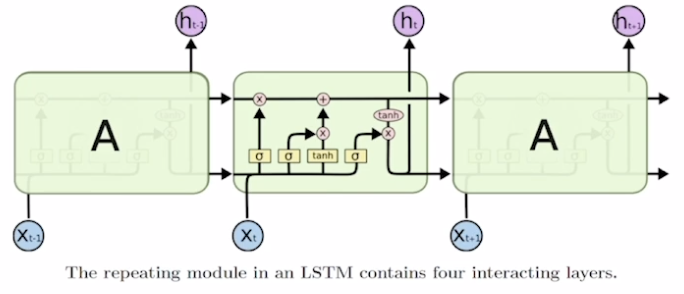
- Long short-term memory
- i : Input gate, Whether to write to cell
- f : Forget gate, Whether to erase cell
- o : Output gate, How much to reveal cell
- g : Gate gate, How much to write to cell
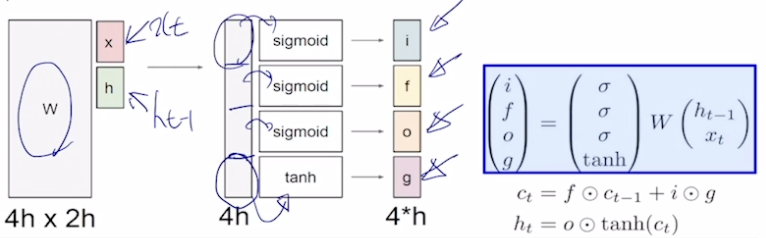
- A gate exits for controlling how much information could flow from cell state
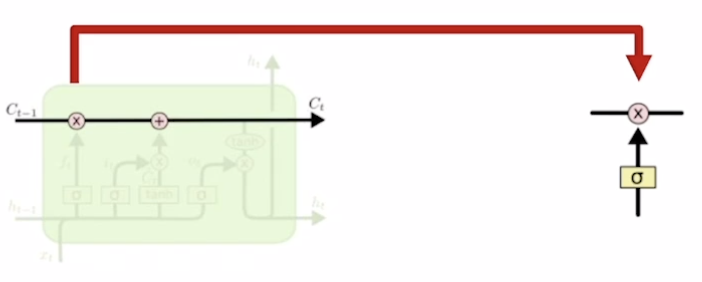
- 1) Forget gate
- 2) Generate information to be added and cut it by Input gate
- 3) Generate new cell state by adding current information to previous cell state
- 4) Generate hidden state by passing cell state to tanh and Output gate
- 5) Pass this hidden state to next time step, and output or next layer if needed
- 1) Forget gate
Gated Recurrent Unit(GRU)
- What is GRU?
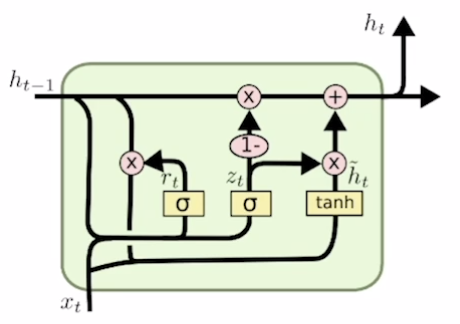
- c.f) in LSTM
Backpropagation in LSTM, GRU
- Uninterrupted gradient flow!
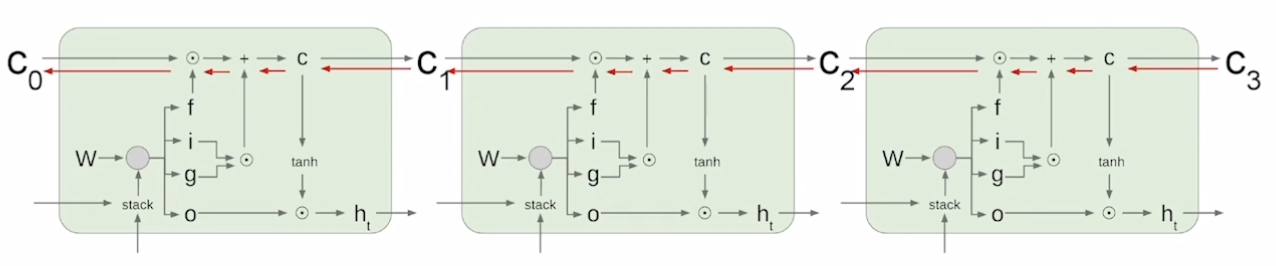
- 가 아닌 gate를 활용해 필요로 하는 정보를 덧셈을 통해 만들어주기 때문에 gradient vanishing/exploding 문제를 해결
- 여기서 덧셈은 backpropagation을 수행할 때, gradient를 복사하는 역할을 하기 때문에 더 긴 타임 스텝까지 정보를 전달
Summary on RNN/LSTM/GRU
- RNNs allow a lot of flexiblity architecture design
- Vanilla RNN are simple but don't work very well
- Backward flow of gradient in RNN can explode or vanish
- Common to use LSTM or GRU : their additive interactions improve gradient flow
피어세션 정리
강의 내용 관련
-
BPTT 이외에 RNN/LSTM/GRU의 구조를 유지하면서 gradient vanishing/exploding 문제를 완화할 수 있는 방법이 있을까요?
- truncated-BPTT
- weight 초기화 : xavier, kaiming
-
RNN/LSTM/GRU 기반의 Language Model에서 초반 time step의 정보를 전달하기 어려운 점을 완화할 수 있는 방법이 있을까요?
-
질문1) text input 길이가 변하면 rnn cell이 늘어나면서, 모델 구조가 바뀌게 되는 것인가요?
- input 길이가 변한다고 하더라도 rnn cell이 반복적으로 적용되는 것이기 때문에 모델 구조가 바뀌지는 않는 것 같습니다!
-
질문2) rnn output이 각각 뭘 의미하는 건가요?
- hidden_state 는 모든 time step에 대한 것, h_n은 마지막 time step에 대한 것
-
질문3) batch_emb를 transpose를 하는 이유?
- time step에 대해서 계산하기 위해서
-
질문4) 필수과제2번 forward에서 LSTM/GRU 나눠서 처리해야하는지
- weight initialization을 train 함수에서 하기 때문에 그렇게 안 하셔도 될 것 같습니다.
-
질문5) pack_padded_sequence 의 결과가 무슨 뜻인지
- 문장길이대로 sorting 후 계산하니까 연산량을 효율적으로 만들 수 있다.
- Packedsequnce 참고 자료
- 이걸 transformer에서도 적용할 수 있을까? → 멘토님께 질문
과제 내용 관련
- 현재 코드는
train,dev,test데이터를 모두 dictionary 에 포함하고 있습니다. 이때 발생할 수 있는 문제점은 무엇일까요? - 1에서 발생한 문제점을 해결하기 위해서는 어떻게 바꿔야 할까요?
이번 주 계획
pytorch 내에 rnn, lstm, gru 구현된 코드를 보고 이해하기- 직접 한국어 데이터셋에 적용해서 학습시켜보기
- 네이버 영화리뷰 데이터셋 : NSMC data link
- 목요일까지 rnn 코드 구현 후 공유
- 금요일까지 학습까지 완료 후 공유
느낀점
노트 정리부터 하다가 과제를 끝내지 못한 채 피어세션에 들어가다 보니 팀원들과 의견을 나눌 때 어려운 부분이 있었던 것 같습니다. 앞으로는 과제부터 수행한 후에 저녁 시간을 이용해 노트 정리를 하려 합니다!
