
수업 정리
1. [NLP] Transformer (1)
- Transformer: Scaled Dot-Product Attention
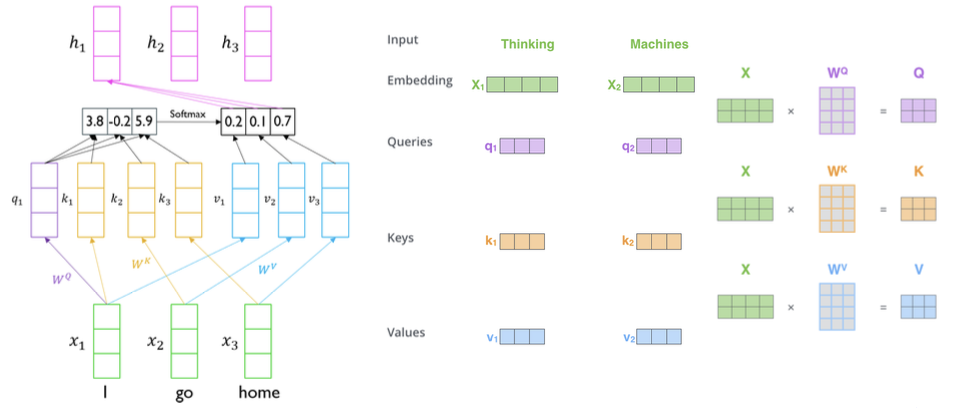
- Inputs: a query and a set of key-value pairs to an output
- Query, key, value, and output is all vectors
- Output is weighted sum of values
- Weight of each value is computed by an inner product of query and corresponding key
- Queries and keys have same dimensionality , and dimensionality of value is , but it doesn't have to be the same dimensionality
- When we have multiple queries , we can stack them in a matrix :
- Becomes:
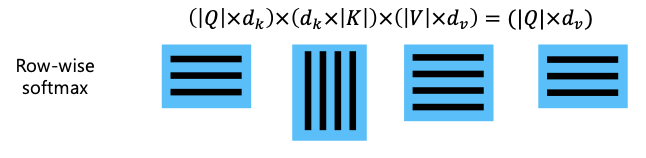
- Example from illustrated transformer
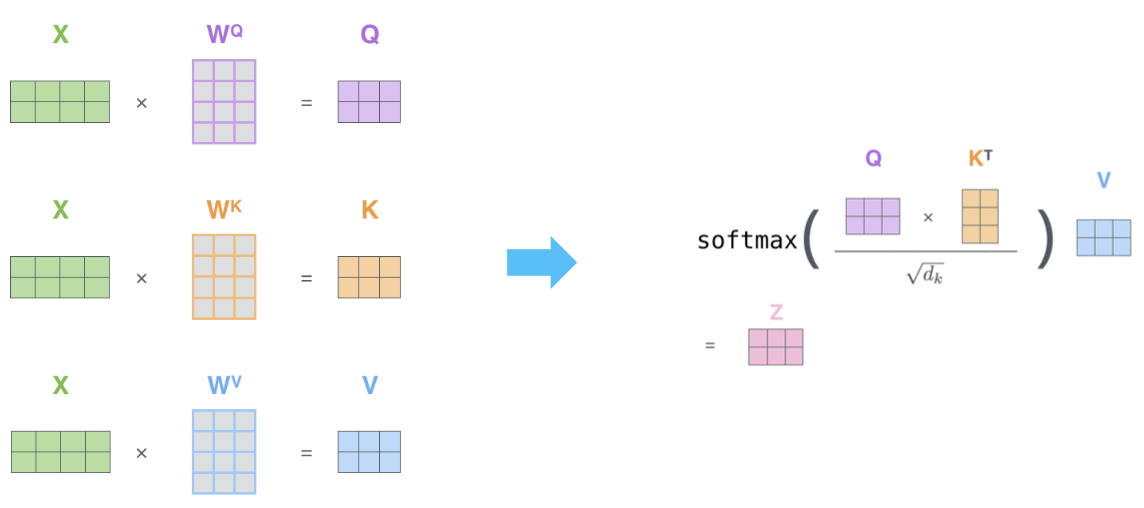
- Problem
- As gets large, the variance of increases
- Some values inside the softmax get large
- The softmax gets very peaked
- Hence, its gradient gets smaller
- Solution
- Scaled by the length of query / key vectors:
- Scaled by the length of query / key vectors:
2. [NLP] Transformer (2)
- Transformer: Multi-Head Attention
- The input word vectors are the queries, keys and values
- In other words, the word vectors themselves select each other
- Problem of single attention
- Only one way for words to interact with one another
- Solution
- Multi-head attention maps 𝑄, 𝐾, 𝑉 into the number of lower-dimensional spaces via 𝑊 matrices
- Then apply attention, then concatenate outputs and pipe through linear layer
- Maximum path lengths, per-layer complexity and minimum number of sequential
operations for different layer types- 𝑛 is the sequence length
- 𝑑 is the dimension of representation
- 𝑘 is the kernel size of convolutions
- 𝑟 is the size of the neighborhood in restricted self-attention

- Transformer: Block-Based Model Transformer
- Each block has two sub-layers
- Multi-head attention
- Two-layer feed-forward NN (with ReLU)
- Each of these two steps also has
- Residual connection and layer normalization:
- 𝐿𝑎𝑦𝑒𝑟𝑁𝑜𝑟𝑚(𝑥 + 𝑠𝑢𝑏𝑙𝑎𝑦𝑒𝑟(𝑥))
- Transformer: Layer Normalization Transformer
- Layer normalization changes input to have zero mean and unit variance, per layer and per training point (and adds two more parameters)
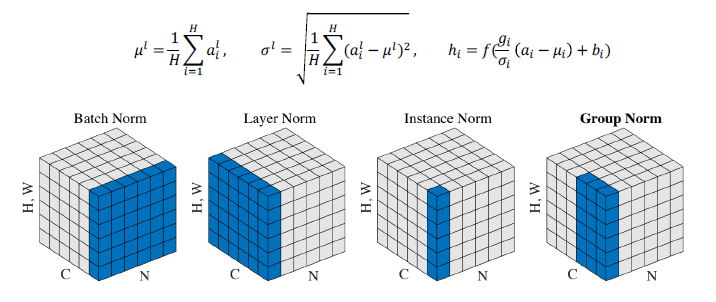
- Layer normalization consists of two steps:
- Normalization of each word vectors to have mean of zero and variance of one.
- Affine transformation of each sequence vector with learnable parameters
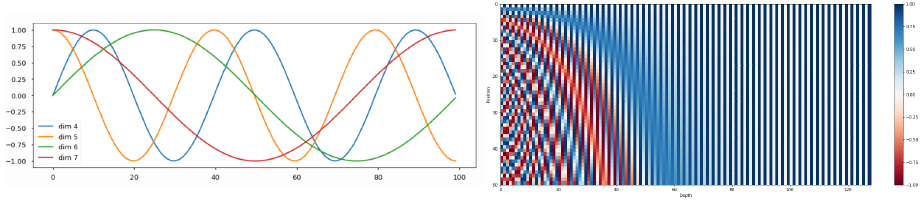
- Transformer: Positional Encoding Transformer
- Use sinusoidal functions of different frequencies
- Easily learn to attend by relative position, since for any fixed offset 𝑘,
can be represented as linear function of
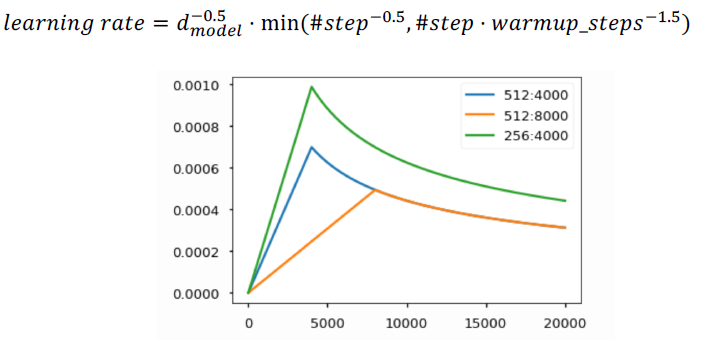
- Transformer: Warm-up Learning Rate Scheduler
- Transformer: Decoder
- Two sub-layer changes in decoder
- Masked decoder self-attention on previously generated outputs
- Encoder-Decoder attention,
where queries come from previous decoder layer and keys and values come from output of encoder
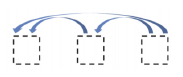
- Transformer: Masked Self-Attention Transformer
- Those words not yet generated cannot be accessed during the inference time
- Renormalization of softmax output prevents the model from accessing ungenerated words
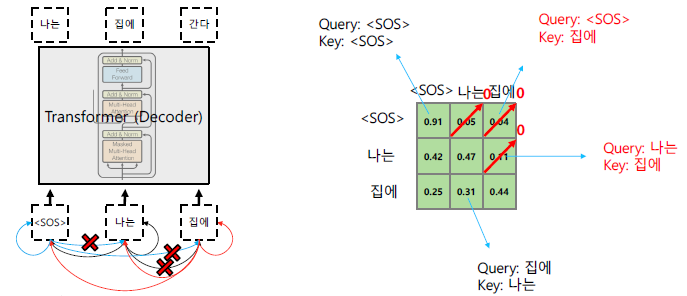
- 실제로는 softmax를 하기 전에 mask부분에 -inf를 취한 후, softmax를 적용
피어세션 정리
강의 내용관련
-
트랜스포머에서 Q,K의 입력 차원이 달라도 상관이 없나요?
- Q와 K의 입력차원이 다르더라도 계산할 때 열의 차원만 맞춰준다면 상관이 없다. 그러나 트랜스포머에서는 인코더에서 Q,K,V의 입력이 같고 디코더에서는 Q,K의 입력이 같기 때문에 둘의 차원은 동일하게 주어진다.
-
어텐션의 인코더와 디코더의 시퀀스 길이가 다른데 어떻게 어텐션이 이루어지나요?
- 디코더의 Q, 인코더의 K, V를 활용하여 계산하더라도 Q * K transpose 이기 때문에 시퀀스 길이가 아닌, hidden dimension의 크기만 맞으면 계산이 가능하다.
-
batch normalization이 좋은 성능을 보이는 이유?
- batch normalization을 통해 스무딩을 해준다는 의견이 있다. 이에 대해서는 반론도 존재하는 것 같다. 성능이 좋아지는 이유에 대해서는 논란이 있지만 batch normalization을 통해 성능이 좋아진다는 것은 많은 사람들이 공감하는 것 같다.
-
subword tokenize에서 의미없는 단어로 tokenize를 해 성능이 낮아질수도 있지 않을까?
- subword tokenize에서 성능이 낮아질 수도 있겠지만 단어를 subword로 나누기 때문에 테스트에서 \ 토큰이 줄어들어서 성능 자체는 더 좋을 것 같다.
느낀점
트랜스포머에 대해 다시 정리할 수 있었고, 피어세션을 진행하며 서로 다른 관점에서 이해한 내용들을 공유하다 보니 미처 생각하지 못했던 부분들에 대해서도 이야기 나눠 볼 수 있었다.
추가적으로, batch normalization이 텍스트에서는 어떻게 이뤄지는지 다시 정리해야겠다. 관련 참고자료
