
수업 정리
1. [NLP] Self-supervised Pre-training Models
- Recent Trends
- Transformer model and its self-attention block has become a general-purpose sequence (or set) encoder and decoder in recent NLP applications as well as in other areas.
- Training deeply stacked Transformer models via a self-supervised learning framework has significantly advanced various NLP tasks through transfer learning, e.g., BERT, GPT-3, XLNet, ALBERT, RoBERTa, Reformer, T5, ELECTRA...
- Other applications are fast adopting the self-attention and Transformer architecture as well as self-supervised learning approach, e.g., recommender systems, drug discovery, computer vision, ...
- As for natural language generation, self-attention models still requires a greedy decoding of words one at a time.
- GPT-1
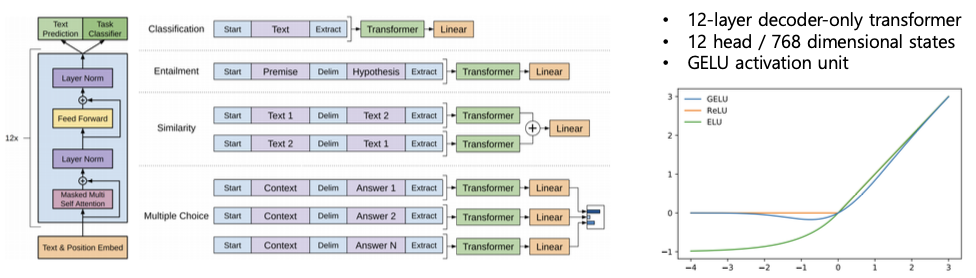
- It introduces special tokens, such as <S> /<E>/ $, to achieve effective transfer learning during fine-tuning
- It does not need to use additional task-specific architectures on top of transferred
- BERT
- Learn through masked language modeling task
- Use large-scale data and large-scale model
- Motivation
- Language models only use left context or right context, but language understand bi-directional
- If we use bi-directional language model?
- problem: Words can "see themselves" (cheating) in a bi-directional encoder
- Pre-training Task in BERT
- Masked Language Model(MLM)
- Mask some percentage of the input tokens at random, and then predict those masked tokens.
- 15% of the words to predict
- 80% of the time, replace with [MASK]
- went to the store >> went to the [MASK]
- 10% of the time, replace with a random word
- went to the store >> went to the running
- 10% of the time, keep the sentence as same
- went to the store >> went to the store
- 80% of the time, replace with [MASK]
- How to
- Mask out k% of the input words, and then predict the masked words
- Too little masking : Too expensive to train
- Too much masking : Not enough to capture context
- Problem
- Mask token never seen during fine-tuning
- Solution
- 15% of the words to predict, but don't replace with [MASK] 100% of th time. Instead:
- Next Sentence Prediction(NSP)
- Predict whether Sentence B is an actual sentence that proceeds Sentence A, or a random sentecne
- To learn the relationships among sentences, predict whether Sentence B is an actual sentence that proceeds Sentence A, or a random sentence
- Masked Language Model(MLM)
- Summary
- Model Architecture
- BERT BASE: L=12,H=768, A=12
- BERT LARGE: L=24,H=1024, A=16
- Input Representation
- WordPiece embeddings (30,000 WordPiece)
- Learned positional embedding
- [CLS] – Classification embedding
- Packed sentence embedding [SEP]
- Segment Embedding
- Pre-training Tasks
- Masked LM
- Next Sentence Prediction
- Model Architecture
- Input Representation
- The input embedding is the sum of the token embeddings, the segmentation embeddings and the position embeddings
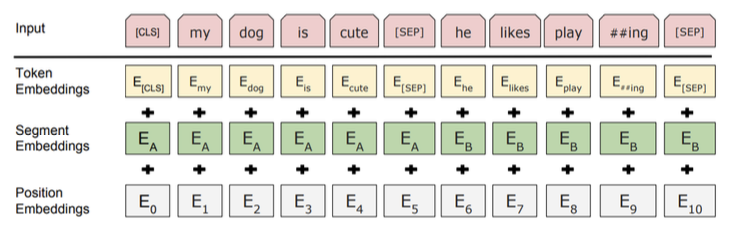
- The input embedding is the sum of the token embeddings, the segmentation embeddings and the position embeddings
- Fine-tuning Process
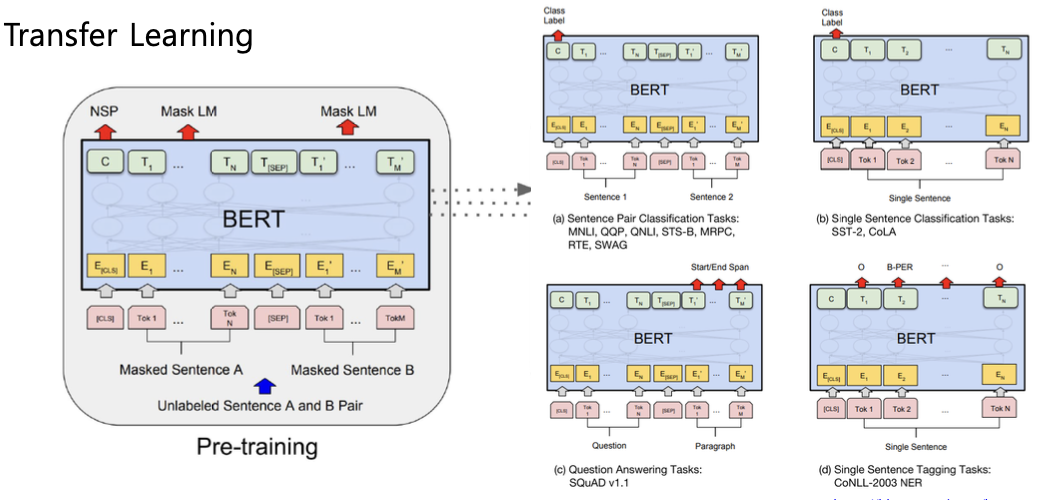
피어세션 정리
-
positional embedding
- bert에서는 positional embedding을 학습가능한 파라미터로 두어 학습하면서 positional embedding을 하는데 이렇게 되면 orthonormality가 사라져 positional에 대한 정보가 희석된는 것은 아닐까요?
- 종속적인 값이 될 수 있기 때문에 해당 word에서 position정보를 가져오지는 못하는 것은 맞는 것 같다. 다만 embeddingm을 통해 positional한 정보 단어사이의 전후관계에 대한 정보를 부여해주거나 position에 대한 가중치로 주어지는 것 같다.
-
gpt에서도 teacher forcing이 일어나나요?
- 트랜스포머에서는 기계번역을 통해 학습을 하기 때문에 디코더단계에서 순서대로 생성이 되어야하기 때문에 teacher forcing이 필요할 수 있지만 gpt에서는 전단계의 출력이 아니라 전단계까지의 입력을 가지고 다음 출력을 예측하는 것이기 때문에 학습단계에서 이전 단계의 출력이 필요하지 않기에 teacher forcing이 필요하지 않다. 모든 단계의 학습은 병렬적으로 동시에 일어난다.
-
albert와 bert의 차이
- bert에서는 임베딩 단계에서 v(존재하는단어의수) X H(트랜스포머의 차원) 의 임베딩이 필요하고 그래서 v*h개의 파라미터가 필요하다. 그러나 albert는 이런 임베딩에서 어느정도의 representaion을 포기하고 v X e, e X H의 행렬이 필요해 가중치가 v*e+e*h 개만 존재하기 때문에 파라미터 수를 크게 줄일 수 있다. 또한 각각의 트랜스포머 layer가 가중치를 공유해서 이때 필요한 파라미터 수도 크게 줄어 bert에 비해 크게 파라미터 수를 줄여 경량화할 수 있었다.
