get 요청이 오면 크롤링한 데이터를 뿌려주는 app을 만들어보자.
웹페이지에서 '뉴스'를 클릭하면 주식과 관련된 실시간 TOP10 기사를 보여주는 페이지가 나온다고 가정해보자. 이 경우 TOP10 기사는 실시간으로 바뀔 것이기 때문에 데이터베이스에 저장하기 보다는 get요청이 들어올 때 바로바로 크롤링결과를 리턴해주는 것이 좋다.
-
프로젝트 안의 다양한 기능 중 crawling이라는 앱을 따로 만들어준다. 크롤링해온 데이터의 성격이 다르고 하나의 기능을 담당하기 때문에 다른 기능과 구분되는 앱으로 이 기능을 구현하는 것이 좋다.
-
크롤링한 데이터를 데이터베이스에 저장 할 경우를 생각해 models.py를 모델링해준다. get이 오면 db를 거치지않고 바로 크롤러가 작동해 값을 리턴해주지만 db에 저장해야할 다른 경우를 대비해 만들어준다.
-
로직으로서 크롤러가 들어갈 views.py를 작업해준다. 코드는 아래와같다.
import json, requests
from django.db import IntegrityError
from django.views import View
from django.http import HttpResponse, JsonResponse
from bs4 import BeautifulSoup
from .models import Crawling
# Create your views here.
class CrawlingView(View):
def get(self, request):
url = 'https://search.naver.com/search.naver?sm=tab_hty.top&where=news&query=python&oquery=%ED%8C%8C%EC%9D%B4%EC%8D%AC&tqi=UC4jcsprvTossThcjQZssssssT0-093442'
# 검색어가 정해진 페이지의 실시간 기사가 필요하기 때문에 url을 미리 넣어둔다.
html = requests.get(url).text # requests로 해당 url의 html을 text로 가져온다
soup = BeautifulSoup(html, 'html.parser') # BeautifulSoup으로 가져온 html text를 parsing한다.
title=[] # 가져온 title을 리스트에 담는다
linked_url=[] # 가져온 url을 리스트에 담는다
result=[] # url과 title을 하나의 딕셔너리 key와 value로 만든 결과를 담는다
a=soup.find_all(class_="_sp_each_url _sp_each_title") # find_all 매서드를 사용해 class가 _sp_each_url _sp_each_title인 태그를 찾아 전부 불러온다.
for i in a:
title.append(i.attrs['title']) # class가 _sp_each_url _sp_each_title인 태그 안의 title 속성만 가져와 title 리스트에 넣는다
for i in a:
linked_url.append(i.attrs['href']) # class가 _sp_each_url _sp_each_title인 태그 안의 title 속성만 가져와 linked_url 리스트에 넣는다
for i in zip(title,linked_url): # python zip내장함수를 통해 결과를 인덱스별로 추출해 하나의 리스트로 만들어준다.
result.append( # zip으로 만든 리스트중 하나의 인자인 i를 인덱싱을 통해 result리스트에 dictionary형태로 추가한다.
{
'title' : i[0],
'url' : i[1]
}
)
return JsonResponse({'crawling list' : result}, status = 200) # 결과를 JsonResponse 규격에 맞는 dictionary형태로 return해준다.
크롤링 한 결과를 get요청이 들어오면 위와같이 바로 JsonResponse로 return해준다.
- get 매서드를 보내서 결과를 확인한다.
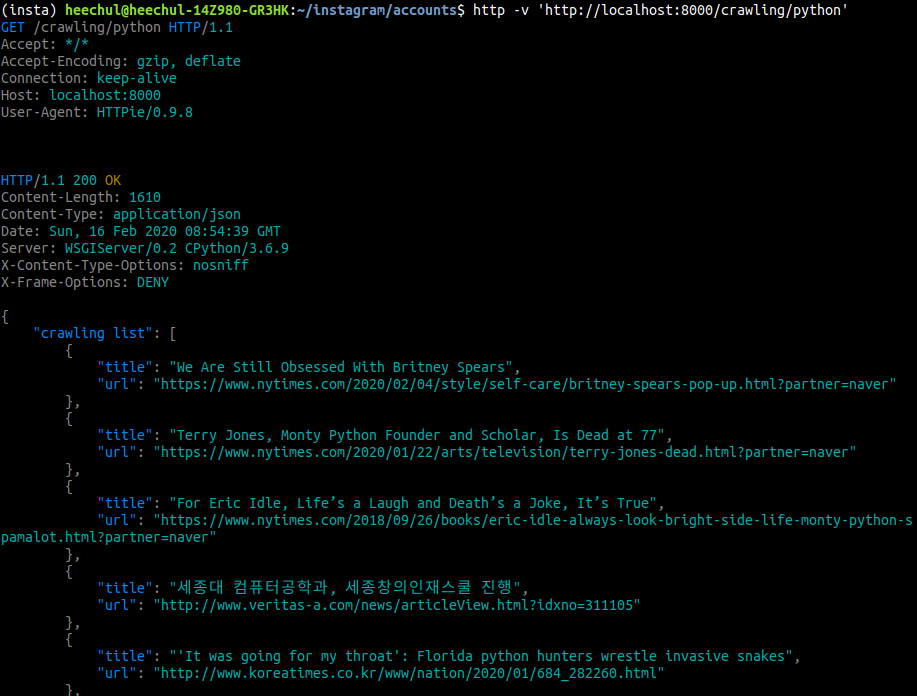
위와같이 python이라는 end-point에 get매서드를 보내자마자 크롤링한 데이터가 리턴되어 왔음을 확인한다.

Quit talking, Begin doing