빌보드 hot100차트의 랭킹, 곡제목, 가수이름을 크롤링해보자.
import requests
from bs4 import BeautifulSoup우선 웹사이트로 http request중 get매서드를 보낼 requests 라이브러리를 import해준다.
그리고 불러온 http 객체를 해석(parsing)할 bs4라이브러리 중 BeautifulSoup을 불러온다.
req = requests.get('https://www.billboard.com/charts/hot-100')
req라는 변수에 http request를 통해 get한 객체를 담아준다.
html = req.text
그리고 그 값을 .text 매서드를 이용해서 html 텍스트로 가져온다.
soup = BeautifulSoup(html, 'html.parser')BeautifulSoup이라는 parser에 값을 넣어서 soup이라는 인스턴스를 만든다.
이제 원하는 값을 가져오기 위해서
해당웹페이지 -> 개발자도구 -> elements 코드를 분석한다.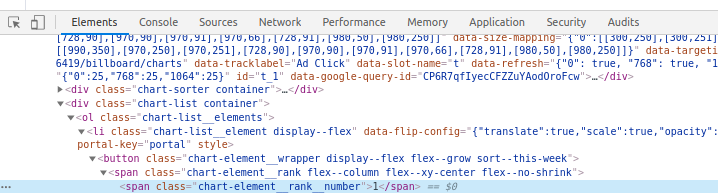
랭킹이 표시된곳에서 마우스오른쪽 버튼을 누르고 검사를 누르면 해당 html의 위치가 사진과같이 개발자도구를 통해서 표시된다.
그리고 해당 html코드에서 마우스오른쪽 버튼을 눌러 copy -> copy selector 을 해준다.
카피한 코드를 살펴보자
#charts > div > div.chart-list.container > ol > li:nth-child(1) > button > span.chart-element__rank.flex--column.flex--xy-center.flex--no-shrink > span.chart-element__rank__number해당 html코드의 절대경로(?)를 표시해준다.
id부터시작해서 div>ol>...>span으로 이어지는 경로를 표시한다.
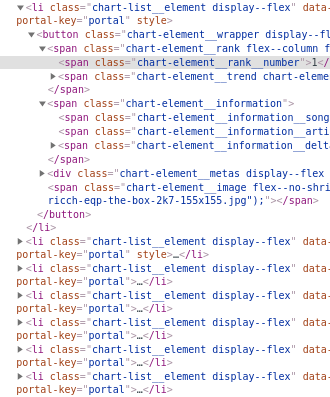
우선 우리가 필요한 것은 하나의 랭킹이 아니라 1~100까지 의 랭킹이다.
이를위해서 우리는 1~100에 공통으로 해당되는 html패턴을 찾아야한다.
사진에서 보면 li 태그에 class를 주면서 패턴이 반복되는 것을 볼 수 있다.
우리가 필요한 공통성을 맞춰서 1~100까지에 해당하는 모든 랭킹을 가져오기 위해 singularity되는 정보는 경로에서 지워준다.
rank = soup.select('li > button > span.chart-element__rank.flex--column.flex--xy-center.flex--no-shrink > span.chart-element__rank__number')select매서드를 통해서 경로에 해당하는 값을 rank변수로 만들어준다.
rank를 프린트해보면
[<span class="chart-element__rank__number">1</span>, <span class="chart-element__rank__number">2</span>, <span class="chart-element__rank__number">3</span>, <span class="chart-element__rank__number">4</span>, <span class="chart-element__rank__number">5</span>, <span class="chart-element__rank__number">6</span>, <span class="chart-element__rank__number">7</span>, <span class="chart-element__rank__number">8</span>, <span class="chart-element__rank__number">9</span>, <span class="chart-element__rank__number">10</span>,.......위와같이 리스트 형태로 span태그를 포함한 값으로 나온다.
우리가필요한 것은 span태그를 포함한 값이 아니라 랭킹(숫자) 그자체이다.
for i in rank:
print(i.text)개별 span태그에 .text 속성을 주면 랭킹(숫자)그자체를 얻을 수 있다.
위와같은 과정으로 title과 name을 얻어준다
title = soup.select('li> button > span.chart-element__information > span.chart-element__information__song.text--truncate.color--primary')
name = soup.select('li > button > span.chart-element__information > span.chart-element__information__artist.text--truncate.color--secondary')이제 우리가 필요한 것은 랭킹, 제목, 이름의 정보가 합쳐진 묶음이다.
ex. (rank1, title1, name1), (rank2, title2, name2) ...
위와같은 형태로 데이터를 가공하기 위해서는 파이썬 내장함수인 zip()함수가 필요하다. zip함수는 길이가 같은 자료형을 같은 인덱스별로 묶어준다. zip()
result=[]
for i in zip(rank, title, name):
result.append(
{
'rank' : i[0].text,
'title' : i[1].text,
'name' : i[2].text,
}
)
print(result)나중에 데이터베이스에 넣을 것을 생각하여 데이터를 dictionary화 시켜준다.
[{'rank': '1', 'title': 'The Box', 'name': 'Roddy Ricch'}, {'rank': '2', 'title': 'Life Is Good', 'name': 'Future Featuring Drake'}, {'rank': '3', 'title': 'Circles', 'name': 'Post Malone'}, {'rank': '4', 'title': 'Memories', 'name': 'Maroon 5'}, {'rank': '5', 'title': 'Dance Monkey', 'name': 'Tones And I'}, {'rank': '6', 'title': 'Someone You Loved', 'name': 'Lewis Capaldi'}, {'rank': '7', 'title': 'Roxanne', 'name': 'Arizona Zervas'}, {'rank': '8', 'title': '10,000 Hours', 'name': 'Dan + Shay & Justin Bieber'}, {'rank': '9', 'title': "Don't Start Now", 'name': 'Dua Lipa'}, {'rank': '10', 'title': 'everything i wanted', 'name': 'Billie Eilish'}, ...위와같이 결과가 나왔다면 성공
