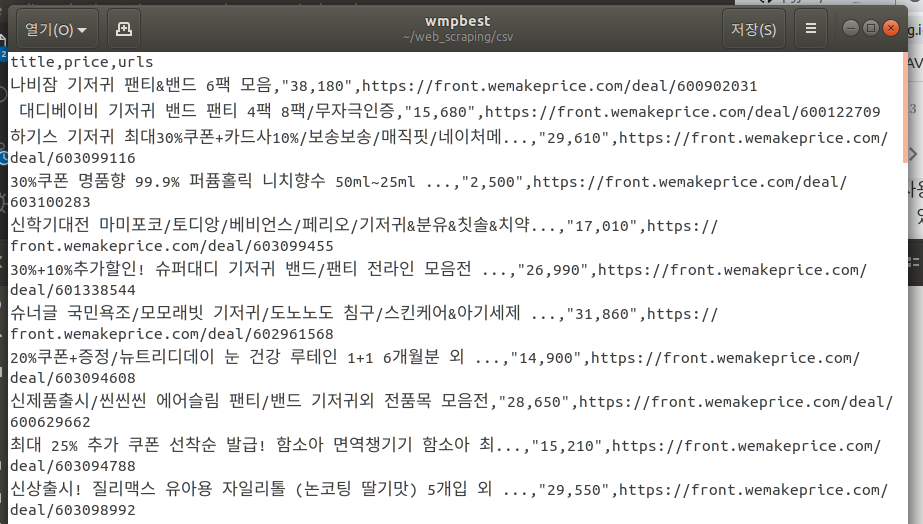
위메프 best section을 크롤링해서 csv파일로 저장해보자.
크롤링하는 방법은 여기서 자세히 다루므로 이번에는 csv파일 저장위주로 다뤄보고자 한다.(전체 코드는 맨 아래에서 확인)
prices = [price_chunk[i].text for i in range(0, len(price_chunk))]
titles = [img_chunk[i].text for i in range(0,len(img_chunk))]
urls = []
for i in range(0, len(url_chunk)):
a=url_chunk[i]['href']
scliced_url = a.replace('//front.wemakeprice.com', '')
urls.append("https://front.wemakeprice.com"+ scliced_url)selector로 끌어온 각각의 price, title, url들을 위와같이 리스트로 담는다.
wmp_best_info = []
for i in zip(titles,prices,urls):
wmp_best_info.append(
{
'title' : i[0],
'price' : i[1],
'urls' : i[2],
}
)zip파일로 각각의 리스트를 합쳐서 하나의 리스트로 만든다.
여기까지는 기존에하던 크롤링이고, 이제 csv파일로 저장하는법을 알아보자.
import csv
with open('./csv/wmpbest', mode='w') as wmpbest:우선 csv모듈을 import해오고 with open('저장하고싶은 파일경로와 파일이름', '사용모드') as 객체이름 으로 작성해준다. 여기서 경로는 지정해주지 않아도 되는데 지정해서 저장하고싶다면 미리 csv라는 디렉토리를 만들어놓아야 한다. 위의 with open scope는 csv파일은 만들어주지만 그 파일로가는 경로까지 만들어주지는 않는다.
이 코드를 풀어보자면 wmpbest.csv라는 파일을 w(쓰기)로 만들고 이 하나의 동작(scope)를 wmpbest라고 scope name을 붙혀준다. 즉, 이 scope를 wmpbest라는 이름으로 정의하겠다는 것이다.
wmpbest_writer = csv.writer(wmpbest)
wmpbest_writer.writerow(['title', 'price', 'urls'])이제 불러온 csv모듈을 사용할 차례이다. csv.writer(wmpbest)를 사용해서 wmpbest라는 scope를 writer라는 클래스안에 담아주고 이를 통해서 wmpbest_writer라는 인스턴스를 만들어준다.
이제 이 인스턴스(wmpbest_writer)의 매서드인 writerow를 사용하여 csv파일안에 데이터를 한줄씩 writing할 수 있다.
이제 객체화했으니 해당객체의 매서드를 사용할 수 있다. for문을 돌리기전에
wmpbest_writer.writerow(['title', 'price', 'urls'])를 해준 이유는 첫번째 줄에 column을 넣고싶어서 이다.
for i in zip(titles,prices,urls):
wmpbest_writer.writerow([i[0], i[1], i[2]])이제 for문을 통해서 csv파일에 한줄씩 데이터를 적어내려간다.
전체 코드
import requests, csv
from bs4 import BeautifulSoup
req = requests.get('https://front.wemakeprice.com/best')
html = req.text
soup = BeautifulSoup(html, 'html.parser')
def wmp_crawler():
url_chunk = soup.select('div.content_main > div > div.box_listwrap > div > a')
img_chunk = soup.select('div.content_main > div > div.box_listwrap > div > a > div > div.item_cont > div.option_txt > p')
price_chunk = soup.select('#_contents > div.content_main > div > div.box_listwrap > div > a > div > div.item_cont > div.option_txt > div > div.price_info > strong > em')
prices = [price_chunk[i].text for i in range(0, len(price_chunk))]
titles = [img_chunk[i].text for i in range(0,len(img_chunk))]
urls = []
for i in range(0, len(url_chunk)):
a=url_chunk[i]['href']
scliced_url = a.replace('//front.wemakeprice.com', '')
urls.append("https://front.wemakeprice.com"+ scliced_url)
wmp_best_info = []
for i in zip(titles,prices,urls):
wmp_best_info.append(
{
'title' : i[0],
'price' : i[1],
'urls' : i[2],
}
)
with open('./csv/wmpbest', mode='w') as wmpbest:
wmpbest_writer = csv.writer(wmpbest)
wmpbest_writer.writerow(['title', 'price', 'urls'])
for i in zip(titles,prices,urls):
wmpbest_writer.writerow([i[0], i[1], i[2]])
return wmp_best_info결과