개요
💡
으악 GROUP BY, ORDER BY 를 했는데 데이터가 겹쳐요!
사내에서 오프셋과 커서 페이징을 혼용해서 사용 중에 있다.
오프셋을 처리하는 경우 GROUP BY 와 ORDER BY 를 같이 쓸 때가 있는데
어느 날 페이지 1과 페이지2에 데이터가 중복된다는 문의가 들어왔다.
이 글에서는:
- SQL이 논리적으로 어떤 순서로 쿼리를 처리하는지,
- MySQL이 물리적으로 어떻게 실행 계획을 잡는지,
- 그 결과 왜 페이지 중복/누락이 발생하는지,
- 그리고 어떻게 방지해야 하는지
를 한 번 해부해 본다.
원리 & 원인
💡 TL;DR
예시 데이터:
orders테이블
id customer_id amount created_at 1 A 100 2024-01-01 2 A 200 2024-01-02 3 B 150 2024-01-01 4 B 250 2024-01-03 5 C 300 2024-01-02 6 D 300 2024-01-01
GROUP BY는 항상ORDER BY보다 먼저 논리적으로 수행된다.MySQL은
GROUP BY때문에Using temporary를 사용하여 임시 테이블에 결과를 쌓는다.
customer_id total A 300 B 400 C 300 D 300
ORDER BY total DESC가 있으면Using filesort로 별도 정렬 단계를 추가한다.하지만 정렬 키 값이 동일한 행들(A, C, D = 300) 사이의 순서는 보장되지 않는다.
실행 1 실행 2 B (400) B (400) A (300) D (300) C (300) A (300) D (300) C (300) 이 상태에서
LIMIT 2, 2를 쓰면 페이지별 결과에 중복/누락이 발생할 수 있다.
페이지 2 (실행 1) 페이지 2 (실행 2) C, D A, C ← C 중복
해결책:
ORDER BY total DESC, customer_id ASC처럼 고유 키를 추가하여 정렬 순서를 결정적으로 만든다.
SQL 논리적 처리 순서
우리가 작성하는 쿼리 순서 (SELECT ... FROM ... WHERE ... GROUP BY ... ORDER BY ...)와 DB가 논리적으로 처리하는 순서는 다르다.
논리적으로는 아래 순서로 처리된다.
FROM/JOINWHEREGROUP BYHAVINGSELECTORDER BYLIMIT / OFFSET
즉, 항상 GROUP BY가 끝난 뒤에 ORDER BY가 실행된다.
따라서 아래 쿼리의 의미는 다음과 같다.
- 먼저
m_idx기준으로 행들을 묶어 대표 행 하나로 만든 뒤 - 그 결과 집합을
m_seq기준으로 정렬한다
GROUP BY me1_0.m_idx
ORDER BY me1_0.m_seq
여기까지는 이론적으로 자연스럽다. 문제는 물리적인 정렬 방식과 정렬 키의 유일성이다.
문제의 실제 쿼리
SELECT
me1_0.m_idx,
me1_0.m_seq,
mce1_0.mc_channel,
mce1_0.mc_name,
mge1_0.mg_name,
me1_0.m_name,
me1_0.m_producer,
mce2_0.mcls_name,
mce2_0.mcls_hp,
CASE
WHEN (NOW()<me1_0.m_post_time_st)
THEN CAST(1 AS SIGNED)
WHEN (NOW() BETWEEN me1_0.m_post_time_st AND me1_0.m_post_time_ed)
THEN CAST(2 AS SIGNED)
ELSE CAST(3 AS SIGNED)
END,
me1_0.m_is_allow,
me1_0.m_post_time_st,
me1_0.m_post_time_ed,
me1_0.created_at,
me1_0.m_genre_type,
me1_0.m_uuid
FROM
dgm_media me1_0
JOIN
dgm_media_category mce1_0
ON mce1_0.mc_idx=me1_0.mc_idx
JOIN
dgm_media_by_so mbse1_0
ON mbse1_0.m_idx=me1_0.m_idx
JOIN
dgm_so_define sde1_0
ON sde1_0.sd_idx=mbse1_0.sd_idx
LEFT JOIN
dgm_media_genre mge1_0
ON mge1_0.mg_idx=me1_0.mg_idx
LEFT JOIN
dgm_media_class mce2_0
ON mce2_0.m_idx=me1_0.m_idx
LEFT JOIN
dgm_media_by_area mbae1_0
ON mbae1_0.m_idx=me1_0.m_idx
WHERE
me1_0.m_series_type=1
AND me1_0.m_use=1
AND CAST(mce1_0.mc_type AS CHAR)='CLASS'
GROUP BY
me1_0.m_idx
ORDER BY
me1_0.m_seq위에 대해서 페이지 1, 페이지 2 에 대해서 호출 시 m_idx 가 중복되는 것을 볼 수 있다.
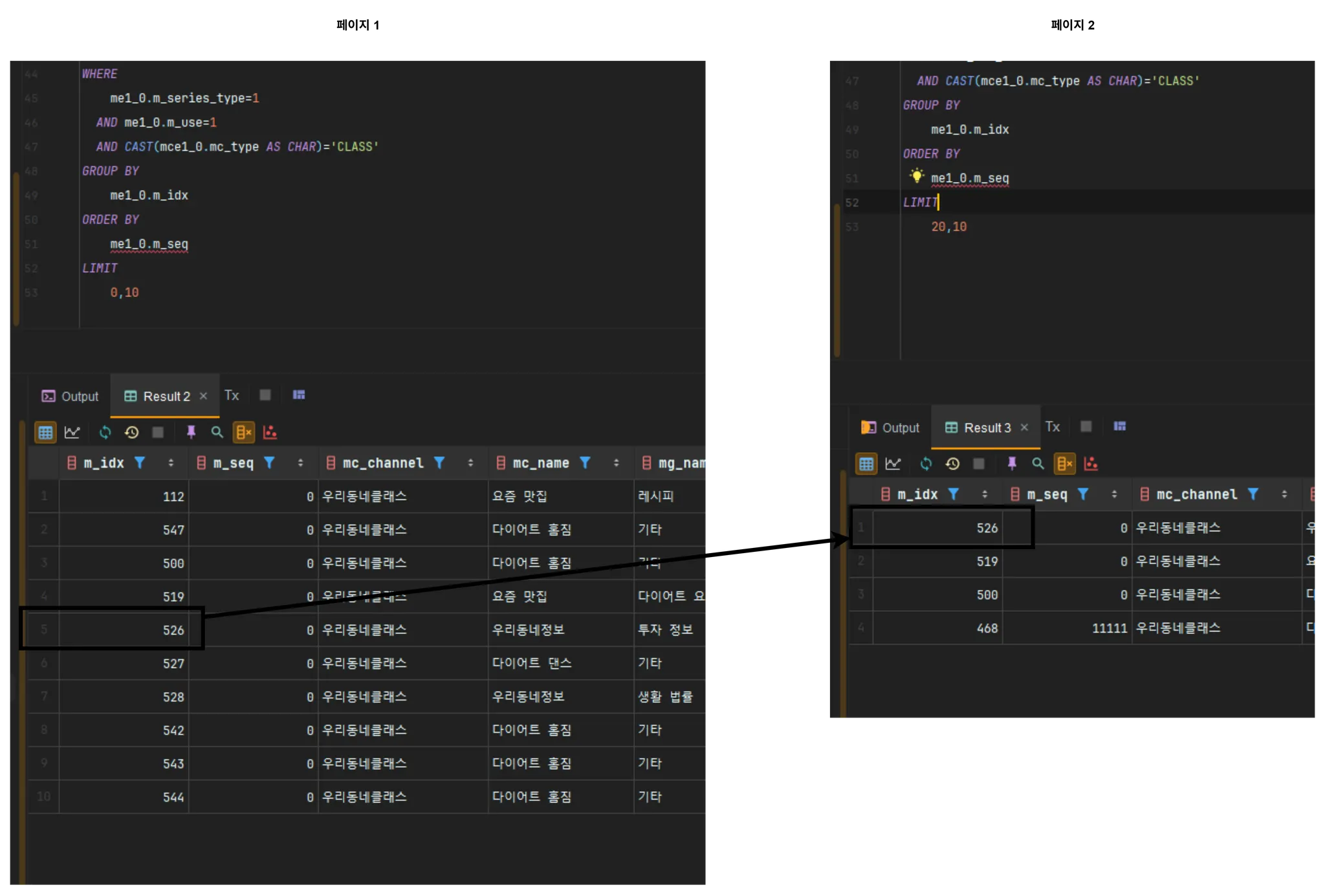
위에 대한 EXPLAIN 과 EXPLAIN ANALYZE 는 각각 다음과 같다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| -- | ----------- | ------- | ---------- | ----------- | ------------------------------------------------------------------------- | ----------- | ------- | ----------------------------------- | ---- | -------- | ------------------------------------------------------------------------- |
| 1 | SIMPLE | me1_0 | | index_merge | PRIMARY,INDEX_CATEGORY,use,series,status,allow,start_time,end_time,MEMBER | series,use | 1,2 | | 11 | 97.15 | Using intersect(series,use); Using where; Using temporary; Using filesort |
| 1 | SIMPLE | mce1_0 | | eq_ref | PRIMARY | PRIMARY | 4 | rainbow_tv_dev_local.me1_0.mc_idx | 1 | 100 | Using where |
| 1 | SIMPLE | mge1_0 | | eq_ref | PRIMARY | PRIMARY | 4 | rainbow_tv_dev_local.me1_0.mg_idx | 1 | 100 | |
| 1 | SIMPLE | mce2_0 | | ref | INDEX_MEDIA | INDEX_MEDIA | 5 | rainbow_tv_dev_local.me1_0.m_idx | 1 | 100 | |
| 1 | SIMPLE | mbse1_0 | | ref | media,sd_idx | media | 4 | rainbow_tv_dev_local.me1_0.m_idx | 6 | 100 | |
| 1 | SIMPLE | sde1_0 | | eq_ref | PRIMARY | PRIMARY | 4 | rainbow_tv_dev_local.mbse1_0.sd_idx | 1 | 100 | Using where; Using index |
| 1 | SIMPLE | mbae1_0 | | ref | media | media | 4 | rainbow_tv_dev_local.me1_0.m_idx | 14 | 100 | Using index |
-> Sort: me1_0.m_seq (actual time=35.9..35.9 rows=24 loops=1)
-> Table scan on <temporary> (cost=403590..428811 rows=2.02e+6) (actual time=35.9..35.9 rows=24 loops=1)
-> Temporary table with deduplication (cost=403590..403590 rows=2.02e+6) (actual time=35.9..35.9 rows=24 loops=1)
-> Left hash join (mbae1_0.m_idx = mbse1_0.m_idx) (cost=201839 rows=2.02e+6) (actual time=15..28.1 rows=4488 loops=1)
-> Nested loop left join (cost=7941 rows=235) (actual time=5.46..18 rows=264 loops=1)
-> Nested loop left join (cost=7683 rows=220) (actual time=5.44..17 rows=264 loops=1)
-> Nested loop inner join (cost=7441 rows=220) (actual time=5.43..16.8 rows=264 loops=1)
-> Nested loop inner join (cost=7200 rows=220) (actual time=0.878..16.1 rows=748 loops=1)
-> Nested loop inner join (cost=5275 rows=4392) (actual time=0.065..11.2 rows=4348 loops=1)
-> Table scan on mbse1_0 (cost=444 rows=4392) (actual time=0.039..1.76 rows=4348 loops=1)
-> Filter: (sde1_0.sd_idx = mbse1_0.sd_idx) (cost=1 rows=1) (actual time=0.00188..0.00196 rows=1 loops=4348)
-> Single-row covering index lookup on sde1_0 using PRIMARY (sd_idx=mbse1_0.sd_idx) (cost=1 rows=1) (actual time=0.00171..0.00174 rows=1 loops=4348)
-> Filter: ((me1_0.m_use = 1) and (me1_0.m_series_type = 1) and (me1_0.mc_idx is not null)) (cost=0.338 rows=0.05) (actual time=996e-6..0.00101 rows=0.172 loops=4348)
-> Single-row index lookup on me1_0 using PRIMARY (m_idx=mbse1_0.m_idx) (cost=0.338 rows=1) (actual time=684e-6..712e-6 rows=1 loops=4348)
-> Filter: (cast(mce1_0.mc_type as char charset utf8mb4) = 'CLASS') (cost=1 rows=1) (actual time=685e-6..714e-6 rows=0.353 loops=748)
-> Single-row index lookup on mce1_0 using PRIMARY (mc_idx=me1_0.mc_idx) (cost=1 rows=1) (actual time=294e-6..328e-6 rows=1 loops=748)
-> Single-row index lookup on mge1_0 using PRIMARY (mg_idx=me1_0.mg_idx) (cost=1 rows=1) (actual time=751e-6..779e-6 rows=1 loops=264)
-> Index lookup on mce2_0 using INDEX_MEDIA (m_idx=mbse1_0.m_idx) (cost=1.07 rows=1.07) (actual time=0.00271..0.00357 rows=1 loops=264)
-> Hash
-> Table scan on mbae1_0 (cost=4.03 rows=8602) (actual time=0.0766..7.75 rows=8300 loops=1)그렇다면 어떤 것들이 문제를 일으켰을까?
MySQL 실행 계획에서 보이는 것들
EXPLAIN 결과를 보면 두 케이스 모두 이런 힌트가 찍힌다.
Using temporaryGROUP BY me1_0.m_idx때문에 중복 제거/그룹화를 위한 임시 테이블이 만들어짐
Using filesort(ORDER BY가 있는 경우 추가)- 최종 결과를
ORDER BY me1_0.m_seq로 정렬하기 위해 파일 정렬(filesort) 수행
- 최종 결과를
즉,
GROUP BY만 있는 경우
→ 임시 테이블에 “어떤 순서로든” 그룹 대표 행이 쌓인다 (정렬 보장 ❌)GROUP BY + ORDER BY인 경우
→ 임시 테이블의 결과를 다시 정렬한다
여기까지만 보면 “정렬했으니 순서가 항상 같지 않나?” 라고 생각하기 쉽다.
하지만 정렬 키 값이 동일한 행들 사이의 순서는 보장되지 않는다는 게 핵심이다.
ORDER BY가 있어도 “순서가 불안정한” 이유
그렇다면 GROUP BY 가 있음에도 왜 데이터가 중복될까?
이유는 임시테이블에 대한 동일 행 순서 미보장에 있다.
1️⃣ Filesort의 불안정성 (Unstable Sort)
MySQL의 filesort 알고리즘은 기본적으로 unstable sort 이다.
정렬 키가 같은 경우:
- 원본 순서가 보장되지 않음
- 내부 알고리즘(quicksort 등)에 따라 순서가 바뀔 수 있음
- 실행할 때마다 결과가 달라질 수 있음
- MySQL 5.7 이전: 주로 quicksort 사용 (unstable)
- MySQL 8.0+: std::sort 또는 std::stable_sort 혼용
- 하지만 기본적으로는 unstable sort
- 정렬 키가 같은 행들의 순서는 여전히 불확정
2️⃣ MySQL 공식 문서: ORDER BY Optimization
MySQL 8.0 Reference Manual에서 명확히 언급하고 있다.
"If multiple rows have identical values in the
ORDER BYcolumns, the server is free to return those rows in any order, and may do so differently depending on the overall execution plan. In other words, the sort order of those rows is nondeterministic with respect to the nonordered columns."
즉, ORDER BY 컬럼 값이 동일한 행들의 순서는 보장되지 않으며, 실행 계획, 버퍼 상태, 파일시스템 등에 따라 매번 달라질 수 있다.
이를 Non Deterministic Order 라고 한다.
예시를 살펴보자. 아래와 같이 쿼리 결과가 있다. 이에 대해서 LIMIT 절을 처리하면 어떻게 될까?
mysql> SELECT * FROM ratings ORDER BY category;
+----+----------+--------+
| id | category | rating |
+----+----------+--------+
| 1 | 1 | 4.5 |
| 5 | 1 | 3.2 |
| 3 | 2 | 3.7 |
| 4 | 2 | 3.5 | <-- 중복
| 6 | 2 | 3.5 | <-- 중복
| 2 | 3 | 5.0 |
| 7 | 3 | 2.7 |
+----+----------+--------+category 의 값에 따라 결과가 변경될 것이다.
즉 동일한 category 값을 여러 row 가 가지고 있으므로 순서가 불안정하다.
mysql> SELECT * FROM ratings ORDER BY category LIMIT 5;
+----+----------+--------+
| id | category | rating |
+----+----------+--------+
| 1 | 1 | 4.5 |
| 5 | 1 | 3.2 |
| 4 | 2 | 3.5 |
| 3 | 2 | 3.7 |
| 6 | 2 | 3.5 |
+----+----------+--------+그렇다면 이게 우리의 문제상황과 무슨 관계가 있다는 것인가?
앞서 보았듯이 GROUP BY 와 같이 사용하게 되면
GROUP BY 에 의해 생성된 Temporary table 에 대한 ORDER BY 처리를 하게된다.
이미 중복된 데이터를 가지고 있는 Temporary table 에 대해서 처리하다보니 순서보장이 안 되는 것이다.
즉, 결과적으로 위 예시와 같은 처리를 하게 된다는 것이다.
그렇다면 이런 Non-Determistic Order By 는 어떻게 해결해야할까?
해결방법
실무에서 쿼리를 안전하게 쓰기 위해 취해야 할 액션 위주로 정리하면 아래와 같다.
항상 “결정적인 ORDER BY”를 사용하자
정렬에 사용하는 컬럼이 유일하지 않다면, PK나 유니크 키를 보조 정렬 컬럼으로 반드시 붙인다.
-- 나쁜 예
ORDER BY me1_0.m_seq
-- 좋은 예 (m_idx가 PK라고 가정)
ORDER BY me1_0.m_seq ASC, me1_0.m_idx ASC;
이렇게 하면:
- (
m_seq,m_idx) 쌍이 모든 행에서 유일해지고 - 각 행의 위치가 완전히 결정된다
- OFFSET 페이징을 하더라도 1페이지, 2페이지, 3페이지…에 어떤 row가 들어갈지 항상 동일하게 유지된다
지금 쓰고 있는 쿼리에 바로 적용한다면 아래와 같을 것이다.
SELECT
me1_0.m_idx,
me1_0.m_seq,
...
FROM ...
WHERE ...
GROUP BY me1_0.m_idx
ORDER BY me1_0.m_seq ASC, me1_0.m_idx ASC
LIMIT ?, ?;
가능한 경우, 커서 기반 페이징으로 전환
OFFSET은 페이지가 뒤로 갈수록 비용이 커지고, 방금 말한 Non-Determistic Order 이슈까지 있다.
가능하다면 “커서 기반 페이징”으로 넘어가는 게 좋다.
예를 들어, 프론트에 다음 커서 정보를 내려주고:
last_seqlast_idx
다음 페이지는 이렇게 호출하게 할 수 있다.
SELECT
me1_0.m_idx,
me1_0.m_seq,
...
FROM ...
WHERE ...
AND (
me1_0.m_seq > :lastSeq
OR (me1_0.m_seq = :lastSeq AND me1_0.m_idx > :lastIdx)
)
GROUP BY me1_0.m_idx
ORDER BY me1_0.m_seq ASC, me1_0.m_idx ASC
LIMIT :pageSize;
커서 페이징을 쓰면 아래와 같은 장점을 보장할 수 있다.
- OFFSET을 쓰지 않으니 페이지가 뒤로 갈수록 느려지는 문제를 줄일 수 있다.
- (
m_seq,m_idx) 조합을 기준으로 “다음 페이지의 시작점”을 정확히 지정하므로, 중복/누락 없이 안정적인 페이징이 가능하다.
EXPLAIN 볼 때 체크 포인트
이번 케이스와 같이 GROUP BY + ORDER BY + 페이징이 섞여 있는 쿼리를 튜닝할 때,
EXPLAIN을 보면 특히 아래를 본다.
Using temporaryGROUP BY로 인해 임시 테이블이 생성되는지 확인- 필요하다면 쿼리 구조나 인덱스를 조정
Using filesort- 정렬 비용이 큰지, 인덱스로 커버 가능한지 확인
ORDER BY조건과 인덱스 구성(col1, col2...)을 맞출 수 있는지 고민
rows,filtered- 조인 순서, 필터링이 적절히 되는지 확인
이번 문제의 핵심 이슈는 성능보다는 결과의 안정성이지만,
실제로는 둘을 함께 보게 되므로 EXPLAIN을 보는 습관을 같이 가져가는 게 좋다.
실무에서 바로 적용할 체크리스트
만약 페이지네이션을 처리하는 경우 아래와 같은 체크리스트를 확인하면 좋다.
-
ORDER BY에 유일한 컬럼(PK/UNIQUE) 을 항상 포함시켰는가? - OFFSET 페이징을 사용한다면, 정렬 키가 결정적(deterministic) 인가?
- 장기적으로는 커서 기반 페이징으로 옮길 수 있는 구조인가?
-
EXPLAIN에서Using temporary,Using filesort의 의미를 이해하고 있는가?
이 네 가지만 체크해도,
“페이지마다 데이터가 바뀌어요”, “중복돼요”, “어제랑 오늘 결과가 달라요” 같은 문의의 절반은 막을 수 있다.
Reference
- https://dev.mysql.com/doc/refman/8.4/en/order-by-optimization.html
- https://dev.mysql.com/doc/refman/8.4/en/limit-optimization.html
- https://github.com/wjdrbs96/Today-I-Learn/blob/master/MySQL/MySQL%20GROUP%20BY%EC%97%90%20%EB%8C%80%ED%95%B4%20%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90.md
- https://bugs.mysql.com/bug.php?id=69732
