개요 💭
신규 프로젝트 (아쿠아누리) 에서 실시간 데이터 처리 기능이 추가되었고,
이에 따라 서버 간 확장성과 클라이언트 연결 최적화가 중요한 과제가 되었습니다.
본 포스트에서는 SSE(Server-Sent Events) 와 Redis Stream을 활용하여 확장 가능한 실시간 통신 서버를 설계한 과정을 공유합니다.
요구사항 📃
기능 요구사항
- N 시간 주기로 생성되는 데이터를 실시간 처리해야 함
- 클라이언트는 실시간으로 이벤트를 수신해야 함
비기능 요구사항
- 서버 인스턴스가 증설(Scaling out) 되어도 안정적으로 동작해야 함
- SSE 연결 수를 최소화하여 불필요한 리소스 낭비를 방지해야 함
설계 🏗️
왜 SSE(Server-Sent Events)인가?
실시간 통신 방식으로는 WebSocket, SSE, Long Polling 등 다양한 선택지가 있습니다.
이번 설계에서는 아래 이유로 SSE를 선택했습니다.
✅ 단방향 스트리밍에 최적화 – 서버에서 클라이언트로만 데이터가 전달되므로 구현이 단순
✅ 브라우저 기본 지원 – EventSource API로 별도 라이브러리 없이 사용 가능
✅ HTTP 기반 – 방화벽, 프록시 환경에서도 안정적인 동작
✅ 가벼운 연결 유지 – WebSocket보다 리소스 사용량이 적음
SSE 는 연결을 한 번 하고 나면 연결한 대상에게 데이터를 푸시합니다.
아래와 같은 단계로 처리합니다.
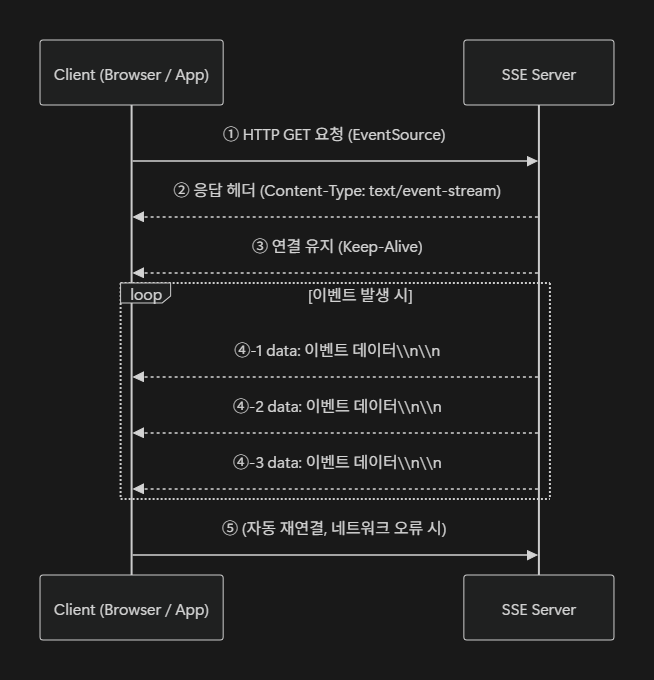
1️⃣ 클라이언트가 연결 요청
브라우저에서 new EventSource("/sse") 로 서버에 GET 요청을 보냅니다.
2️⃣ 서버는 이벤트 스트림 형식으로 응답
HTTP 헤더에 Content-Type: text/event-stream 을 포함하여 연결을 유지합니다.
3️⃣ 연결은 끊기지 않고 유지(Keep-Alive)
서버는 필요할 때마다 데이터를 전송할 수 있으며, 클라이언트는 실시간으로 이를 수신합니다.
4️⃣ 서버에서 이벤트 발생 시 데이터 전송
data: 로 시작하는 텍스트를 전송하며, 이벤트 간 구분을 위해 \\n\\n(빈 줄)을 보냅니다.
5️⃣ 네트워크 장애 시 자동 재연결
브라우저의 EventSource는 기본적으로 재연결 로직을 지원합니다.
SSE 처리방법
1. 서버 측 처리
스프링에서는 두 가지 방법으로 SSE 를 처리할 수 있습니다.
- Webflux → ServerSentEvent 클래스 사용
@GetMapping("/stream-sse") public Flux<ServerSentEvent<String>> streamEvents() { return Flux.interval(Duration.ofSeconds(1)) .map(sequence -> ServerSentEvent.<String> builder() .id(String.valueOf(sequence)) .event("periodic-event") .data("SSE - " + LocalTime.now().toString()) .build()); } - SpringMvc → SseEmitter 클래스 사용
@GetMapping("/stream-sse-mvc") public SseEmitter streamSseMvc() { SseEmitter emitter = new SseEmitter(); ExecutorService sseMvcExecutor = Executors.newSingleThreadExecutor(); sseMvcExecutor.execute(() -> { try { for (int i = 0; true; i++) { SseEventBuilder event = SseEmitter.event() .data("SSE MVC - " + LocalTime.now().toString()) .id(String.valueOf(i)) .name("sse event - mvc"); emitter.send(event); Thread.sleep(1000); } } catch (Exception ex) { emitter.completeWithError(ex); } }); return emitter; } TEXT_EVENT_STREAM타입으로 응답Flux를 사용해 비동기적으로 이벤트 스트리밍
2. 클라이언트 측 처리 (브라우저)
const eventSource = new EventSource("/sse");
eventSource.onmessage = (event) => {
console.log("Received:", event.data);
};
eventSource.onerror = (error) => {
console.error("SSE Error:", error);
};
onmessage를 통해 서버가 보낸 데이터를 수신- 네트워크 오류 시 자동 재연결
🔥 서버 증설 시 SSE 처리의 문제점
하지만 SSE 는 서버 증설 시 아래와 같은 문제점이 있는데요
- 클라이언트 연결 관리의 복잡성
- 도메인별로
/sse/order,/sse/chat,/sse/alert같은 여러 SSE 엔드포인트를 생성하면, 클라이언트는 각 엔드포인트마다 별도로 연결을 유지해야 합니다.
- 서버는 엔드포인트 수 × 클라이언트 수만큼 커넥션을 유지해야 하므로 리소스 사용량이 급증합니다.
- 도메인별로
- 중복된 DB 폴링으로 인한 부하 증가
- 만약 이벤트 발생 주체가 서버가 아니고 DB 를 폴링하는 방식이면, DB 부하의 문제가 발생 합니다.
- 여러 서버가 동일한 DB를 개별적으로 폴링하면 DB 쿼리가 중복 실행되어 부하가 커집니다.
- 데이터 순서 미보장
- 서버 인스턴스가 여러 대일 때, 전달되는 데이터의 순서를 멱등하게 보장하기 어렵습니다.
- 데이터 순서를 보장하기 위해 데이터 처리를 중앙화하여 관리하고, 이벤트 라우팅을 처리할 수 있는 별도의 브로커가 필요합니다.
어떻게 하면 이런 문제점들을 해소할 수 있을까요?
✅ 대안 방법
저는 리더 선출 방식과 브로커를 도입하여 이 문제를 해소하고자 하였습니다.
어떤 점들을 도입하고자 하였는지 기술해보겠습니다.
1. SSE 연결 단일화
- 하나의 SSE 통신으로 여러 도메인 데이터를 처리합니다.
- 이를 통해 엔드포인트 연결수를 최소화합니다.
2. Leader Election 기반의 폴링 역할 단일화
- 여러 서버 중 하나만 Leader로 선출하여 DB 폴링을 단일 서버에서 수행합니다.
- Leader 장애 시 다른 서버가 Leader로 승격될 수 있도록 Leader Election 메커니즘을 사용합니다.
3. 브로커를 통한 이벤트 중앙화
- Leader가 가져온 데이터를 브로커(중앙 이벤트 허브)에 기록합니다.
- 모든 서버 인스턴스는 브로커를 통해 이벤트를 구독하고, 자신과 연결된 클라이언트에게 SSE로 이벤트를 전달합니다.
- 이에 따라 확장성 및 멱등한 데이터 순서를 보장할 수 있습니다.
4. 토픽에 따른 이벤트 처리
- Leader 는 도메인 단위의 데이터(토픽 기반 메시지)를 브로커에 기록합니다.
- 도메인 단위의 데이터를 구독한 서버들만이 이를 수신받습니다.
- 이에 따라 관심 데이터들만 실시간 전달할 수 있습니다.
🏗️ 아키텍쳐
그렇다면 어떤 구조로 이를 처리할까요?
아래 다이어그램은 Leader Election → Leader DB 폴링 → 브로커 토픽별 발행 → Follower 토픽 구독 → SSE 전송 순서를 보여줍니다.
여기서 토픽(Topic) = 도메인(Domain) 으로 매핑되어, 각 서버는 자신이 담당하는 도메인에 해당하는 토픽만 구독하여 클라이언트에 이벤트를 전달합니다.
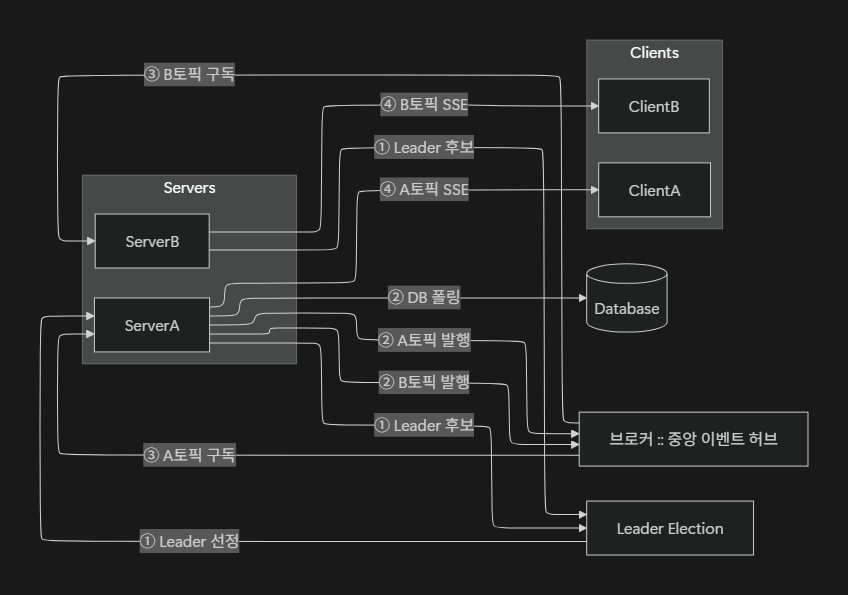
처리 단계 요약
1️⃣ Leader Election
서버 중 하나가 Leader로 선출됩니다.
2️⃣ Leader가 DB를 폴링
DB에서 모든 도메인(예: 도메인 A, 도메인 B)의 최신 데이터를 읽어옵니다.
3️⃣ Leader가 브로커에 토픽별 이벤트 발행
읽어온 데이터를 도메인별 토픽(Topic) 으로 브로커에 발행합니다.
예: A축구장 → Topic:A, B축구장 → Topic:B
4️⃣ 서버는 자신이 담당하는 토픽만 구독
각 서버는 필요한 토픽만 브로커에서 구독합니다.
예: ServerA → Topic:A, ServerB → Topic:B
5️⃣ 서버가 자신의 클라이언트에 SSE 전송
구독한 이벤트를 받아, 각 서버는 자신과 연결된 클라이언트에 SSE로 실시간 데이터를 전송합니다.
이 방식으로 구현하면 아래와 같이 해결할 수 있습니다.
✅ DB 폴링은 Leader 한 대만 수행 → 부하 최소화
✅ 브로커를 통해 모든 서버가 동일한 이벤트를 공유 → 일관성 확보
✅ Leader 장애 시 자동 승계 가능 → 고가용성 보장
✅ 서버 증설 시에도 추가 작업 없이 확장 가능
기술 선택 🛠️
이제 블루프린트를 설계하였으니 어떤 기술을 사용할지 선택할 차례입니다.
Kafka, RabbitMQ 와 같은 여러 옵션이 있었지만, 아래와 같은 사유로 Redis 를 선택하게 되었습니다.
-
운영 단순성: 이미 Redis 인프라가 구성되어 있어 추가적인 브로커 설치·운영 비용이 들지 않음.
-
충분한 성능: 현재 서비스는 초당 수백~수천 건 수준의 이벤트 처리면 충분하며, Redis Streams와 Pub/Sub으로 충분히 커버 가능.
-
다기능 지원: Leader Election(
SETNX+TTL), 이벤트 저장 및 재처리(Streams), Consumer Group 기반 메시지 분배를 하나의 Redis로 처리 가능. -
낮은 지연 시간: In-memory 기반이므로 실시간 SSE 환경에서 Kafka보다 빠른 전송 가능.
-
운영 부담 최소화: Kafka는 Zookeeper/KRaft, RabbitMQ는 Exchange/Queue 설정이 필요하지만, Redis는 비교적 단순한 구성으로 바로 적용 가능.
Redis 를 사용하면 각 구현요소들에 대해 아래와 같이 해결할 수 있습니다.
| 항목 | 처리방법 및 이점 |
|---|---|
| Leader Election | SETNX와 TTL을 활용해 간단하게 Leader를 선출할 수 있으며, 장애 시 TTL 만료로 다른 서버가 자동 승계 가능 |
| Broker(이벤트 허브) | Redis Stream 혹은 Redis Pub/Sub 을 사용해 중앙에서 이벤트를 저장하고, 여러 서버가 도메인 이벤트를 구독 가능 |
| 확장성 | 서버를 증설해도 Redis가 단일 이벤트 소스로 동작하므로 동기화 문제 없이 확장이 가능 |
| 장애 복구 | Leader가 죽더라도 TTL 만료 후 다른 서버가 Leader가 되며, Redis Stream은 데이터 유실 없이 이벤트를 유지 |
💡
Redis Stream vs Kafka
사실 Kafka 를 사용하면 아래에서 설명할 Redis Stream 의 여러 문제점을 해결할 수 있습니다.
하지만 아래와 같은 사유로 도입이 어려웠습니다.
- 기술공부가 덜 되었고
- 인프라 구성도 안 되어있을 뿐더러
- Redis 하나로 Leader Election 과 Broker 를 한 번에 처리할 수 있음
항목 Redis Stream Kafka Partition 없음 (단일 Stream, 병렬 처리는 Consumer Group이 담당) 있음 (Partition별로 병렬 처리 가능) 순서 보장 단일 Consumer에 대해서만 보장 Partition 내에서만 보장 저장소 In-Memory 중심 (Persistence 가능) Disk 기반 메모리 관리 Ack되지 않은 Pending 메시지 쌓일 수 있음 Consumer Offset으로 안정적 관리
🤔 Redis Pub/Sub vs Redis Stream
그렇다면 브로커에 대해 Pub/Sub, Stream 둘 중 무엇을 써야할까요?
Redis Pub/Sub은 단순하고 빠른 메시지 전달에는 적합하지만,
신뢰성 있고 확장성 있는 SSE 시스템을 구축하려 할 때는 여러 한계를 가지고 있습니다.
| 항목 | Pub/Sub 단점 | Redis Stream 비교 |
|---|---|---|
| 메시지 순서 보장 | ❌ 보장되지 않음 (동시 소비자에 따라 도착 순서 불일치) | ✅ 단일 Consumer 또는 Group 내 순서 보장 |
| 내결함성 (복구) | ❌ 메시지를 수신하지 못하면 재전송 불가 (미수신 시 유실) | ✅ Ack 기반 재처리 가능 (Pending 메시지 관리) |
| 클라이언트 재접속 시 처리 | ❌ 과거 메시지 재구독 불가 (stateless 방식) | ✅ XREAD 또는 XREADGROUP으로 재전송 가능 |
| 로드 밸런싱 | ❌ 모든 구독자에게 동일 메시지 전송 (Broadcast) | ✅ Consumer Group으로 메시지를 분산 처리 |
| 백프레셔 제어 | ❌ 불가능 (빠른 발행에 따른 수신 실패 발생) | ✅ Stream ID 단위로 소비 속도 조절 가능 |
| 모니터링 및 추적 | ❌ 메시지 전송 후 상태 추적 어려움 | ✅ 메시지 ID, Ack 여부로 상태 추적 용이 |
| 메시지 저장 | ❌ 메시지 저장 기능 없음 (발행 후 사라짐) | ✅ 메시지를 보존하고 처리 가능 기간 설정 가능 (XTRIM) |
특히 Redis Pub/Sub 은 메시지 순서가 보장되지 않아 실시간 데이터 처리에 부적합하다는 것이 가장 큰 부분입니다.
아래는 실제 Redis Pub/Sub 사용 시 메시지 처리 순서입니다.
# localhost:8080 <SSE API>
id:0dde8561-18b8-4340-88e1-43a44756a45d
event:weather-event
data:{"id":"0dde8561-18b8-4340-88e1-43a44756a45d","timestamp":"2025-08-04T11:23:16.3592316","location":"SEOUL","status":"RAIN","temperature":"HOT"}
id:fc67d981-b3d8-4dd9-a3c5-9bd696272b49
event:weather-event
data:{"id":"fc67d981-b3d8-4dd9-a3c5-9bd696272b49","timestamp":"2025-08-04T11:23:16.3658231","location":"SEOUL","status":"SNOW","temperature":"COLD"}
id:b1e44407-1a26-499c-ad15-86077929fb3b
event:weather-event
data:{"id":"b1e44407-1a26-499c-ad15-86077929fb3b","timestamp":"2025-08-04T11:23:16.3648219","location":"SEOUL","status":"RAIN","temperature":"COLD"}
id:9aa43b02-7af4-4793-b6eb-23589cd93f61
event:weather-event
data:{"id":"9aa43b02-7af4-4793-b6eb-23589cd93f61","timestamp":"2025-08-04T11:23:16.367077","location":"SEOUL","status":"SNOW","temperature":"HOT"}
# ========================
# localhost:8081 <SSE API>
id:0dde8561-18b8-4340-88e1-43a44756a45d
event:weather-event
data:{"id":"0dde8561-18b8-4340-88e1-43a44756a45d","timestamp":"2025-08-04T11:23:16.3592316","location":"SEOUL","status":"SNOW","temperature":"HOT"}
id:3e2c9126-d202-443d-86b5-d8d0e8132b15
event:weather-event
data:{"id":"3e2c9126-d202-443d-86b5-d8d0e8132b15","timestamp":"2025-08-04T11:23:16.3592316","location":"SEOUL","status":"SUNNY","temperature":"HOT"}
id:e910541d-3d26-495b-b35f-3475dc9bdbe8
event:weather-event
data:{"id":"e910541d-3d26-495b-b35f-3475dc9bdbe8","timestamp":"2025-08-04T11:23:16.3598524","location":"SEOUL","status":"RAIN","temperature":"M"}
id:4542cfec-67ed-4717-a2a9-15e92c1627ff
event:weather-event
data:{"id":"4542cfec-67ed-4717-a2a9-15e92c1627ff","timestamp":"2025-08-04T11:23:16.3598524","location":"SEOUL","status":"RAIN","temperature":"COLD"}보시다싶이 실제 처리되는 데이터들의 순서가 서로 상이한 것을 보실 수 있습니다.
반면 Redis Stream 을 사용하면 이러한 단점들을 해결할 수 있습니다.
- 클라이언트가 마지막 메시지 ID를 기억하여 재접속 시 이전 메시지부터 복구 가능
XREAD를 사용하여 서버 인스턴스 간 멱등한 데이터 제공 가능- 메시지 순서가 보장되어 일관된 SSE 스트림 제공
- 메시지 저장 기반으로 재처리 및 장애 분석 용이
📌 최종 구조 다이어그램
아키텍쳐와 기술설명이 끝났으니 어떻게 구현할지에 대해 설명드리겠습니다.
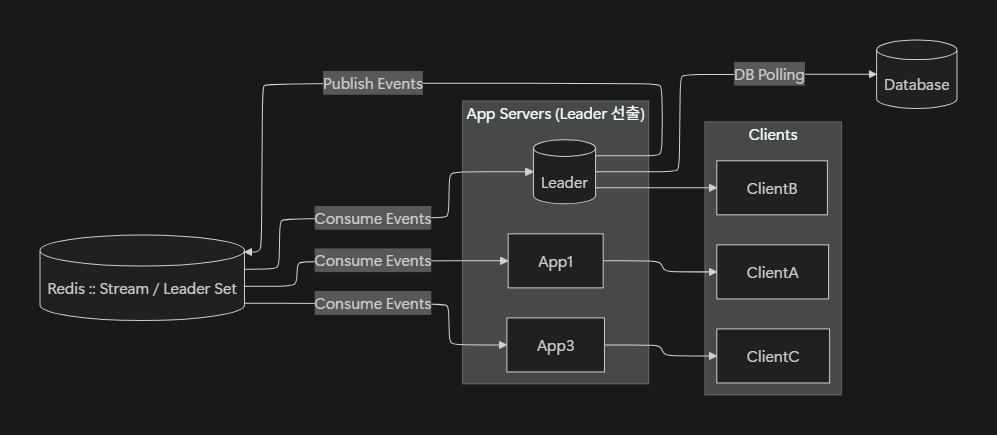
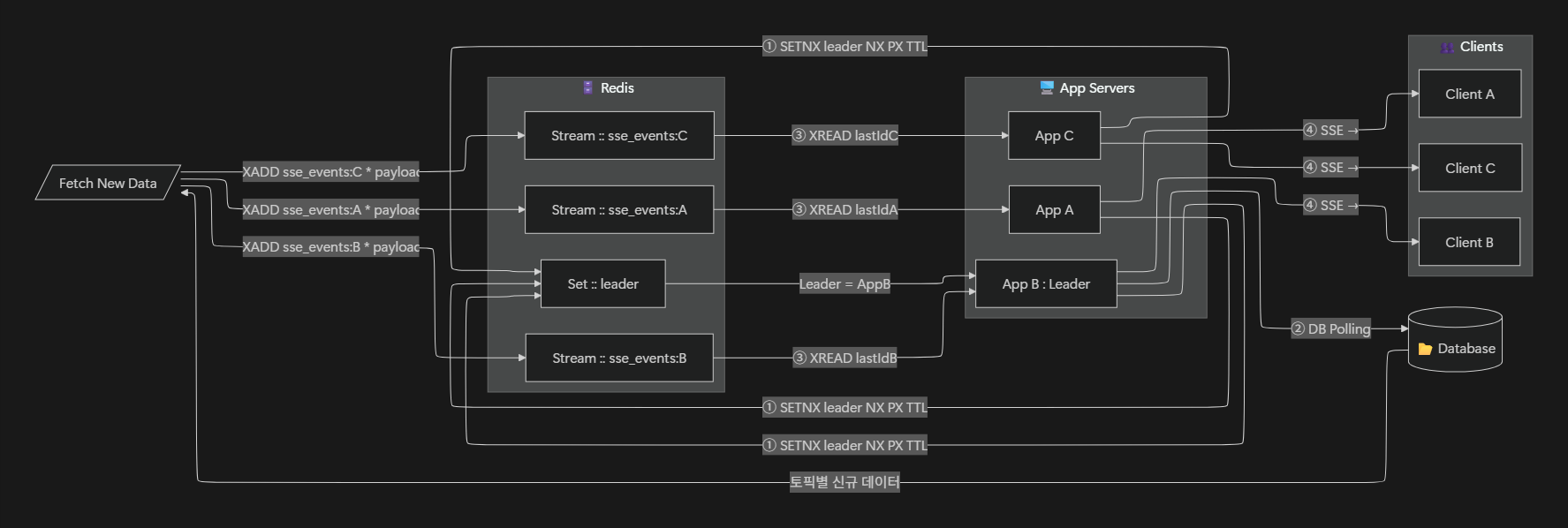
🔄 처리 순서 설명
1️⃣ Leader Election (Redis Set & 분산락)
- 모든 서버는
SETNX leader <server_id> NX PX <ttl>명령으로 Leader 선출을 시도 - 성공한 서버(AppB)가 Leader가 되고 TTL 만료 전까지
PEXPIRE또는SET ... XX PX방식으로 갱신(Heartbeat) - TTL이 만료되면 다른 서버가 새로운 Leader가 될 수 있음 (Failover 지원)
2️⃣ Leader → DB 폴링 → Redis Stream에 XADD
- Leader만 주기적으로 DB를 폴링하여 신규 데이터를 가져옴
- 가져온 데이터는 토픽별로 분리해
XADD sse_events:<topic>명령으로 Redis Stream에 기록 - 각 토픽별로 Stream Key를 분리하여, 불필요한 데이터 전달을 방지
3️⃣ SSE 연결된 서버들만 XREAD 실행
- 서버는 SSE 연결 요청이 들어오면, 해당 토픽에 대한 마지막으로 읽은 Stream ID(
lastId)를 기록 XREAD BLOCK <ms> STREAMS sse_events:<topic> <lastId>명령으로 새로운 이벤트를 대기하며 읽음- 이 방식은 Consumer Group 없이 모든 서버가 동일한 메시지를 읽을 때 적합
4️⃣ 각 서버 → 자신과 연결된 클라이언트에게 SSE 전송
- 서버는 Redis Stream에서 읽은 데이터를 연결된 클라이언트에게 바로 SSE로 전달
- 각 서버는 자신과 연결된 클라이언트 목록을 관리하고, 해당 토픽에 구독 중인 클라이언트에게만 푸시
5️⃣ 오류 및 재연결 처리 (추가 설명)
- 클라이언트가 끊어졌다가 재연결할 경우, 서버는
lastEventId를 활용해 끊긴 시점 이후의 메시지를 다시 전달 - 서버는 Stream Trim 정책(
XTRIM)을 통해 오래된 데이터를 삭제하여 메모리 관리 - Leader 장애 시, 다른 서버가 Leader Election에 참여해 DB Polling과 XADD를 이어서 수행
이제 처리방법도 정리가 되었고 뭔가 구현만 하면 될 거 같습니다.
하지만 아직 Leader Election 처리와 Redis Stream 사용에 있어 고려해야할 부분이 남아있습니다.
각각에 대해 추가 고려사항과 대응방안을 살펴보겠습니다.
⚠️ Redis Set을 이용한 Leader Election 추가 고려 사항 및 현재 대응 방안
🔸 1️⃣ 분산락 처리
📌 문제점
- 여러 서버가 동시에
SETNX명령을 실행할 경우, 잠깐의 타이밍 차이로 인해 동시에 Leader 역할을 수행하게 될 가능성이 있습니다. - Redis 자체는 단일 스레드 기반이므로
SETNX연산 자체는 원자적이지만, TTL(만료 시간) 갱신 처리와 결합된 상황에서는 만료 시점에 여러 서버가 동시에 Leader가 될 수 있는 경쟁 상태(race condition)가 발생할 수 있습니다. - 이로 인해 동일한 이벤트가 중복 발행되거나, Leader가 여러 개 존재하여 시스템의 일관성이 깨질 위험이 있습니다.
✅ 현재 대응 방안
- 현재는
SETNX를 통한 단순 키 기반 Leader 선출,재획득(re-acquire),만료 시간 갱신 로직만 구현된 상태입니다. - SETNX 로 Leader 선출 동시성을 보장할 수 있지만, 단순히 Redis 에서 지원하는 동시성 보장입니다.
- 따라서 동시성 여부 테스트 작성 후 동시성 이슈가 발생하는 경우 분산락(lock) 을 적용 해야합니다.
- 아직은 테스트 작성 및 분산락 적용하지 않은 상태입니다.
- 향후에는 Redlock 알고리즘이나 갱신용 Lua 스크립트를 활용하여 TTL 갱신 및 재선출 과정에서의 경쟁 상태를 방지할 예정입니다.
- 또한, Leader 선출 실패 시 대기 및 재시도를 수행하는 백오프(backoff) 전략을 추가하여, Leader 중복 선출 가능성을 최소화할 계획입니다.
⚠️ Redis Stream 적용 시 추가 고려 사항 및 현재 대응 방안
🔸 1️⃣ 파티션(Partition) 부재
📌 문제점
- Redis Stream은 Kafka와 달리 파티션 개념이 없습니다.
- Kafka 에서의 토픽이 Redis Stream 에서는 하나의 키입니다.
- 따라서 도메인이 증설될수록
sse_events:<domain>형태의 Stream Key가 계속 증가합니다.
- Stream Key가 많아지면 Redis 메모리 사용량과 키 관리 복잡도도 증가합니다.
- 하나의 Stream을 여러 Consumer가 병렬로 처리할 수는 있지만, Redis Cluster 환경에서 샤딩된 노드 간 균등 분산이 어렵습니다.
- 균등한 분산 처리를 위해서는 N개의 Stream을 만들어 각 노드에 할당하는 추가 로직이 필요합니다.
✅ 현재 대응 방안
- 아직 샤드 과부하 정도의 트래픽 규모가 아니라고 판단해 추후 예정으로만 산정하였습니다.
- 네이버에서 공유해주신 쿠폰 수집가 전략을 채택할 수 있습니다.
🔸 2️⃣ 처리완료 순서 보장 불가
📌 문제점
- 여러 Consumer가 병렬로 이벤트를 처리할 경우, 수신메시지의 순서는 보장되지만 생산된 순서대로 메시지가 처리된다는 보장이 없습니다.
- 순서가 중요한 데이터(예: 금융 거래, 상태 변화 이벤트)에는 별도 순서 보장 로직이 필요합니다.
✅ 현재 대응 방안
- 이번 서비스는 SSE 서버를 통한 실시간 데이터 푸시가 목적으로, 메시지의 처리 순서를 보장할 필요가 없습니다.
- 따라서 추가 로직은 구현하지 않았습니다.
🔸 3️⃣ In-Memory 기반으로 인한 메모리 관리 필요
📌 문제점
- Redis는 메모리 기반 저장소이므로, Ack되지 않은 메시지가 Pending 상태로 계속 쌓이면 메모리가 부족해질 수 있습니다.
- 장기간 Ack되지 않은 메시지를 방치하면 메모리 Full로 인한 장애가 발생할 수 있습니다.
✅ 현재 대응 방안
-
추후 주기적으로 Pending 메시지를 조회 및 재처리하는 로직을 추가할 예정입니다.
-
아래와 같이 1분마다 Pending 메시지를 점검하고 Ack하는 스케줄러를 도입할 계획입니다.
@Scheduled(fixedRate = 60000) public void PendingMessagesSummaryScheduler() { PendingMessagesSummary pendingSummary = redisOperator.pendingSummary(streamKey, consumerGroupName); if (pendingSummary != null && pendingSummary.getTotalPendingMessages() > 0) { PendingMessages pendingMessages = redisOperator.pending(streamKey, consumerGroupName); pendingMessages.toList().forEach(pendingMessage -> { List<ObjectRecord<String, String>> messages = redisOperator.read(streamKey, consumerGroupName, consumerName, pendingMessage.getIdAsString()); messages.forEach(recordMessage -> { // 메시지 처리 로직 }); redisTemplate.opsForStream().acknowledge( streamKey, consumerGroupName, pendingMessage.getIdAsString()); }); } }
🔸 4️⃣ 메시지 중복 처리 가능성
📌 문제점
- Redis Stream 은 Ack 이전에 Consumer가 죽으면 동일 메시지가 다른 Consumer에게 전달될 수 있습니다.
- 이로 인해 중복 처리가 발생할 수 있으며, Idempotent 설계가 필요합니다.
✅ 현재 대응 방안
- 위 문제는 그룹 단위 처리일 때의 이야기이고, XREAD 시에는 문제가 없으므로 추가 로직은 구현하지 않았습니다.
🔸 5️⃣ TTL 및 Stream 트리밍 필요
📌 문제점
- Redis Stream은 기본적으로 메시지를 무제한으로 저장하므로, 장기간 사용 시 메모리가 고갈될 수 있습니다.
MAXLEN옵션을 통해 Stream 크기를 제한하거나 TTL을 설정하는 관리가 필요합니다.
✅ 현재 대응 방안
- XADD 시 MAXLEN 을 정하여 길이 제한 임계값을 넘어가면 자동 방출되도록 처리해두었습니다.
코드를 보여줘 💸 🤌
윤곽을 잡았으니 이제부터 실제 코드를 통해 어떻게 구성하였는지 설명드리겠습니다.
Leader Election 🗳️
Leader Election 은 아래와 같이 수행됩니다.
- 리더 여부 확인 (
isLeader)- 현재 서버가 리더인지 Redis에서 확인
- 리더라면 TTL 연장 (
renewLeader)- 리더라면 Redis Key의 TTL을 갱신하여 리더 권한을 유지
- 리더가 아니라면 리더 획득 시도 (
tryAcquireLeader)SETNX방식(setIfAbsent)으로 리더 Key를 선점
- 리더 획득 성공 시 로그 출력 / 실패 시 다른 서버가 리더임을 기록
이에 대해 좀 더 자세하게 풀어쓰자면 아래와 같습니다.
-
리더 여부 검증
public boolean isLeader() { String serverId = streamRedisTemplate.opsForValue().get(leaderKey); return SERVER_ID.equals(serverId); }- Redis에서
leaderKey를 조회 - Key의 value가 현재 서버의 ID와 동일한지 확인
- 동일하면 현재 서버가 리더, 아니면 팔로워
- Redis에서
-
리더라면 TTL 연장
private void renewLeader() { if (isLeader()) { Duration timeout = DurationStyle.detectAndParse(leaderHeartbeatPeriod); streamRedisTemplate.expire(leaderKey, timeout); } }- 현재 서버가 리더라면 Key의 TTL을 연장
- TTL 연장을 통해 리더 권한을 유지 (Heartbeat 역할)
-
리더가 아니라면 리더 획득 시도
private boolean tryAcquireLeader() { Duration timeout = DurationStyle.detectAndParse(leaderAcquirePeriod); return Boolean.TRUE.equals( streamRedisTemplate.opsForValue().setIfAbsent(leaderKey, SERVER_ID, timeout) ); }setIfAbsent→ Redis의SET NX동작과 동일- Key 가 없으면 현재 서버 ID를 value로 설정하고 TTL 부여
- 성공 시 현재 서버가 리더가 됨
-
주기적인 Leader Election 실행
@Scheduled(fixedRateString = "#{T(org.springframework.boot.convert.DurationStyle).detectAndParse('${sse.leader.schedule-period}')}") public void leaderTask() { if (isLeader()) { renewLeader(); log.info("Leader 역할 수행 중..."); return; } if (tryAcquireLeader()) { log.info("Leader 권한 획득 성공!"); return; } log.debug("다른 서버가 Leader입니다."); }- 일정 주기(
schedule-period)마다 실행 - 리더라면 → TTL 갱신 + 리더 역할 수행
- 리더가 아니면 →
SETNX로 리더 권한 획득 시도 - 성공 시 "Leader 권한 획득 성공!" 로그 출력
- 실패 시 "다른 서버가 Leader입니다." 로그 출력
- 일정 주기(
이에 대한 전체코드는 아래와 같습니다.
@Slf4j
@Component
@RequiredArgsConstructor
public class RedisLeaderElection {
private final static String SERVER_ID = UUID.randomUUID().toString();
@Qualifier("streamRedisTemplate")
private final RedisTemplate<String, String> streamRedisTemplate;
@Value("${sse.leader.key}")
private String leaderKey;
@Value("${sse.leader.acquire-period}")
private String leaderAcquirePeriod;
@Value("${sse.leader.heartbeat-period}")
private String leaderHeartbeatPeriod;
@Value("${sse.leader.schedule-period}")
private String leaderSchedulePeriod;
@Scheduled(fixedRateString = "#{T(org.springframework.boot.convert.DurationStyle).detectAndParse('${sse.leader.schedule-period}')}")
public void leaderTask() {
if (isLeader()) {
renewLeader();
log.info("Leader 역할 수행 중...");
return;
}
if (tryAcquireLeader()) {
log.info("Leader 권한 획득 성공!");
return;
}
log.debug("다른 서버가 Leader입니다.");
}
private void renewLeader() {
if (isLeader()) {
Duration timeout = DurationStyle.detectAndParse(leaderHeartbeatPeriod);
System.out.println("리더 연장 주기 = " + timeout);
streamRedisTemplate.expire(leaderKey, timeout);
}
}
private boolean tryAcquireLeader() {
Duration timeout = DurationStyle.detectAndParse(leaderAcquirePeriod);
System.out.println("리더 요청 주기 = " + timeout);
return Boolean.TRUE.equals(streamRedisTemplate.opsForValue().setIfAbsent(leaderKey, SERVER_ID, timeout));
}
public boolean isLeader() {
String serverId = streamRedisTemplate.opsForValue().get(leaderKey);
return SERVER_ID.equals(serverId);
}
}
하지만 리더인 경우에만 리더 업무 (DB 폴링) 를 수행해야합니다.
리더 업무를 리더만 수행할 수 있도록 AOP 와 어노테이션을 활용하겠습니다.
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface SseLeaderTask {
}@Slf4j
@Aspect
@Component
@RequiredArgsConstructor
@Order(Ordered.HIGHEST_PRECEDENCE + 1) // 분산락 Aspect 다음에 실행
public class SseLeaderTaskAspect {
private final RedisLeaderElection redisLeaderElection;
/**
* SSE 리더만 처리해야하는 메서드 수행 (e.g. DB 폴링)
*/
@Around("@annotation(SseLeaderTask)")
public Object lockAndProceed(ProceedingJoinPoint pjp) throws Throwable {
boolean isLeader = redisLeaderElection.isLeader();
if (isLeader) {
log.debug("Executing leader task: {}", pjp.getSignature().getName());
return pjp.proceed();
} else {
log.debug("Skipping leader task (not leader): {}", pjp.getSignature().getName());
Class<?> returnType = ((org.aspectj.lang.reflect.MethodSignature) pjp.getSignature()).getReturnType();
if (returnType == void.class || returnType == Void.class) {
return null;
}
return null;
}
}
}위와 같은 어노테이션을 활용하여 스케줄러 프로세스를 만들면 리더만 이에 대해서 처리합니다.
Redis Stream 🔊
아키텍처 구성 요소
크게 Core / Wrapper / Application 세 파트로 나누어서 처리합니다.
- ⚙️ Core : Redis 에 명령어를 실행
- 🎁 Wrapper : Core 와 Application 을 이어주는 브릿지
- 📦 Application : 도메인 서비스 및 비즈니스 로직 실행
아래는 그룹과 그에 속한 컴포넌트들의 구조도입니다.
이제 각각의 그룹에서 어떻게 처리되는지 확인해보겠습니다.
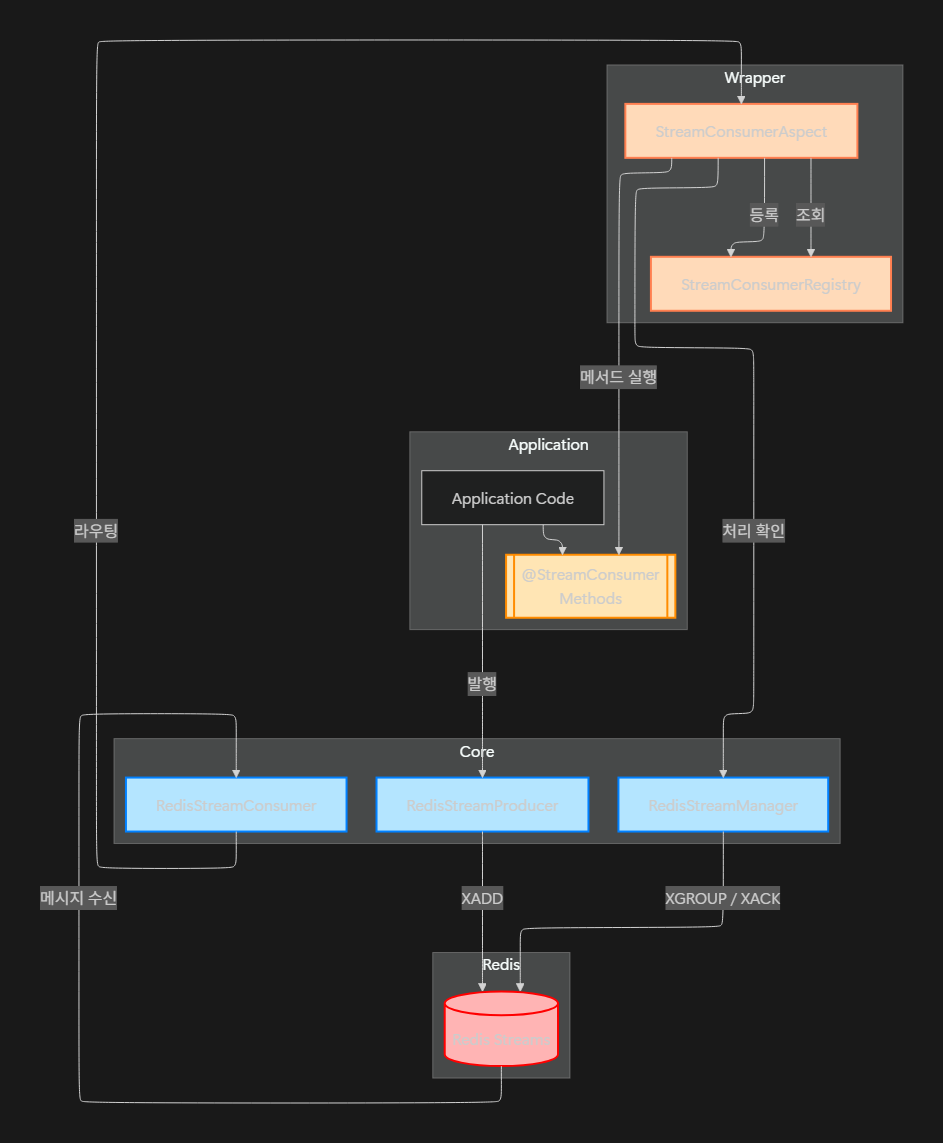
⚙️ Core
코어에는 redis stream 에 직접 명령어를 수행하는 Manager, Producer, Consumer 컴포넌트들이 있습니다.
-
RedisStreamManager
역할: Redis Streams 인프라스트럭처 운영 관리
- 컨슈머 그룹 생성/관리 (XGROUP CREATE/DESTROY)
- 메시지 승인 처리 (XACK)
- 스트림 정보 조회 (XINFO GROUPS/STREAMS)
- 동적 컨슈머 그룹 생성 (ensureConsumerGroup)
- 컨슈머 제거 (XGROUP DELCONSUMER)
// 동적 스트림 등록을 위한 컨슈머 그룹 생성 public boolean ensureConsumerGroup(String streamName, String consumerGroup) // 메시지 승인 처리 (XREADGROUP 시에만 호출됨) public void acknowledgeMessage(String streamName, String consumerGroup, String messageId) // 스트림 정보 조회 public Map<String, Object> getStreamInfo(String streamName) -
RedisStreamProducer
역할: 메시지 발행 전담
- 객체 → JSON → Map 변환 자동화
- XADD 명령어로 스트림에 메시지 추가
- 타입 안전한 발행 지원
// StreamDataDto 발행 publishData(String streamKey, StreamDataDto dto) // 임의 객체 발행 (JSON 직렬화) publishData(String streamKey, Object data) -
RedisStreamConsumer
역할: 메시지 수신 및 라우팅 게이트웨이
- StreamListener 인터페이스 구현
- StreamMessageListenerContainer와 통합
- @StreamConsumer 핸들러로 메시지 라우팅
- 레거시 시스템 호환성 제공
@Override public void onMessage(MapRecord<String, String, String> message) { // 1. 스트림명, 메시지ID 추출 // 2. StreamConsumerAspect로 라우팅 // 3. 어노테이션 기반 핸들러 자동 호출 }
🎁 Wrapper
데이터 수신부인 RedisStreamConsumer 은 StreamListener 인터페이스를 처리함으로써 구현할 수 있습니다.
다만 전통적인 StreamListener 구현은 도메인 로직이 Consumer 클래스에 고정되게 됩니다.
이로 인해 도메인 로직과 인프라가 강결합되게 됩니다.
@Slf4j
@Component
@RequiredArgsConstructor
public class RedisStreamConsumer implements StreamListener<String, MapRecord<String, String, String>> {
,,,
@Override
public void onMessage(MapRecord<String, String, String> message) {
try {
// 1. 메시지 기본 정보 추출
String streamName = message.getStream();
String messageId = message.getId().getValue();
// 2. 도메인 로직 처리
,,,
} catch (Exception e) {
log.error("스트림 메시지 처리 중 오류: {}", message.getId(), e);
}
}
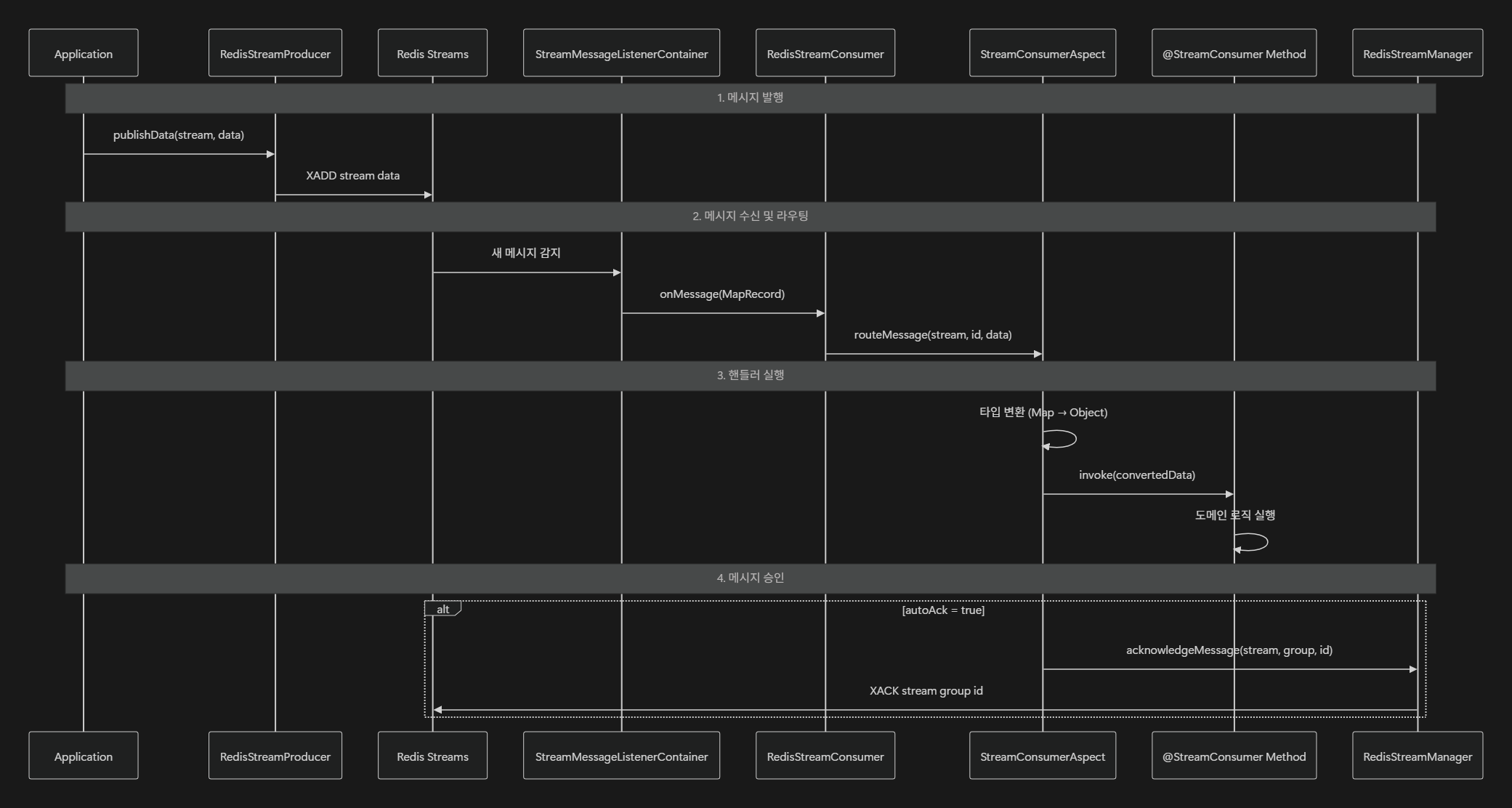
}따라서 이를 해결하고자 AOP 를 활용하여 @StreamConsumer 이 적용된 메서드를 런타임에 자동 탐색·호출 하게 하였습니다.
이를 통해 원하는 토픽에 맞춰 데이터를 받아 인프라 코드와 분리된 도메인 로직을 실행할 수 있습니다.
처리 순서는 아래와 같습니다.
- 발행:
RedisStreamProducer→XADD - 수신: Redis Streams →
StreamMessageListenerContainer→RedisStreamConsumer - 라우팅 & 실행:
StreamConsumerAspect→@StreamConsumer메서드 - 승인:
autoAck→RedisStreamManager.XACK
@StreamConsumer
- Consume 데이터를 받아 도메인 로직 호출
- 옵션 지정에 따라 redis stream 의 행동을 지정
- stream / streams : 대상 스트림(들)
- consumerGroup : 그룹 이름(없으면 XREAD)
- consumerName : 그룹 내 컨슈머 ID
- messageType : 전달 타입(Map·객체)
- autoAck : 자동 ACK 여부
- priority : 실행 순서(숫자↓ = 우선)
- usingEnv / usingRawStream : 스트림명 해석 방식
// ① 타입 안전
@StreamConsumer(stream="sensor-data", messageType=SensorData.class)
void handle(SensorData data);
// ② 메시지 ID 포함
@StreamConsumer(stream="audit-log", consumerGroup="auditors")
void handle(String id, Map<String,String> data);
// ③ 레거시 호환
@StreamConsumer(stream="legacy")
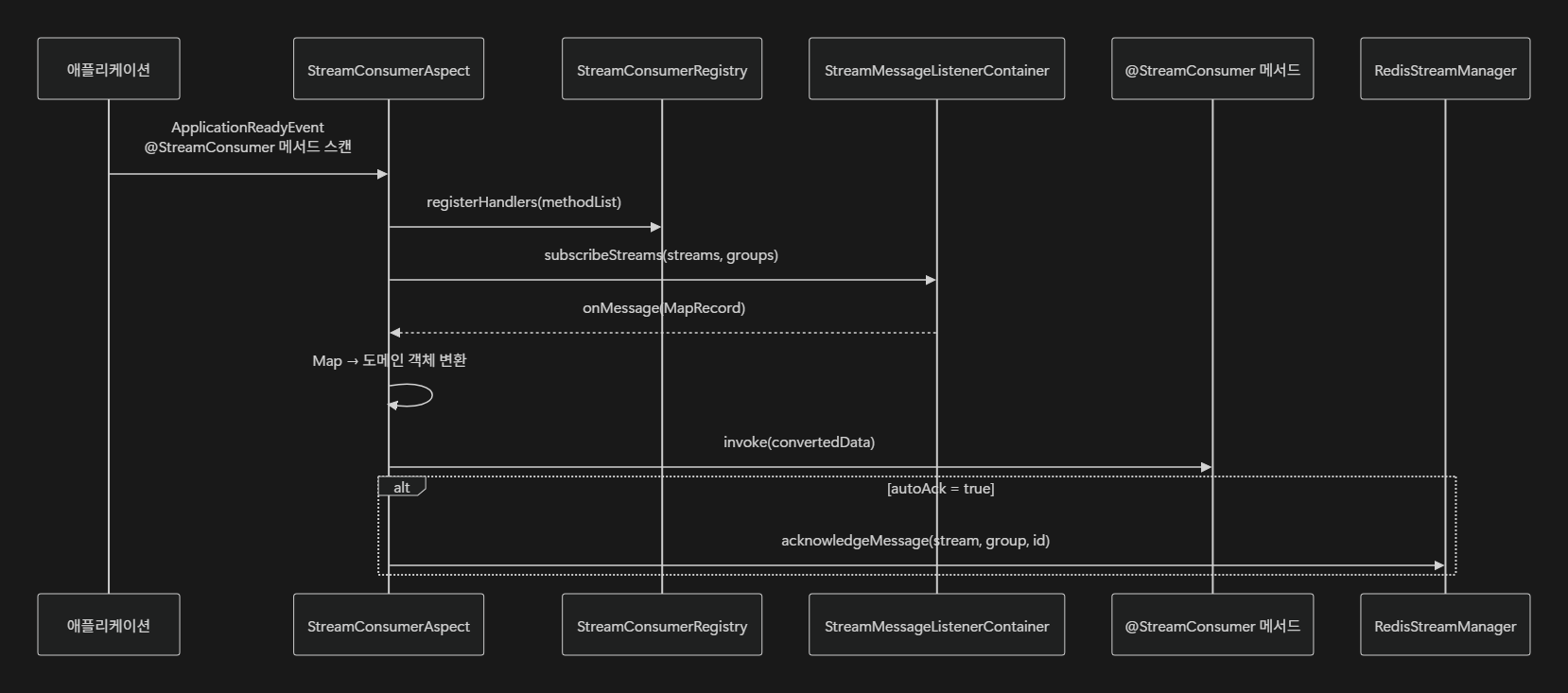
void handle(String stream, String id, Map<String,String> data);StreamConsumerAspect
- @StreamConsumer 메서드 자동 발견 및 실행 관리
- ApplicationReadyEvent에서 전체 빈 스캔
- 메시지 타입 자동 변환 (Map → 도메인 객체)
- 우선순위 기반 순차 실행
- 자동 ACK 처리
- 동적 컨슈머 그룹 생성
처리 흐름도는 아래와 같습니다.
- 애플리케이션 시작 시 @StreamConsumer 메서드 스캔
- StreamConsumerRegistry에 핸들러 등록
- StreamMessageListenerContainer에 스트림 구독 설정
- 메시지 수신 시 적절한 타입으로 변환 후 메서드 호출
- autoAck=true인 경우 자동 승인 처리
StreamConsumerRegistry
- 컨슈머 메타데이터 중앙 관리소
- 스트림별 핸들러 목록 관리
- 컨슈머 그룹별 분류 저장
- 직접 읽기/그룹 읽기 구분 관리
- 우선순위 기반 정렬
- 동적 핸들러 검색
@Slf4j
@Component
public class StreamConsumerRegistry {
/**
* 스트림명별 모든 컨슈머 목록
* Key: 스트림명, Value: 컨슈머 목록
*/
private final Map<String, List<StreamConsumerInfo>> streamHandlers = new ConcurrentHashMap<>();
/**
* 컨슈머 그룹별 스트림별 컨슈머 목록
* Key: 컨슈머 그룹명, Value: {스트림명: 컨슈머 목록}
*/
private final Map<String, Map<String, List<StreamConsumerInfo>>> groupHandlers = new ConcurrentHashMap<>();
/**
* 직접 읽기 컨슈머 목록 (컨슈머 그룹 없이)
* Key: 스트림명, Value: 직접 읽기 컨슈머 목록
*/
private final Map<String, List<StreamConsumerInfo>> directHandlers = new ConcurrentHashMap<>();
,,,
}📦 Application
이제 도메인 코드와 함께 사용 예제를 살펴보겠습니다.
우선 SSE API 를 작성합니다. (Flux 기준)
@Tag(name = "센서 엔드포인트", description = "센서 관련 API")
@RestController
@RequiredArgsConstructor
@RequestMapping("/api/v1/permitall") // ToDo : 테스트용도로 API 열어 놓음
public class SensorEndpoint {
private final SensorUseCase sensorUseCase;
@CustomExceptionDescription(SwaggerResponseDescription.SENSOR_SSE)
@Operation(summary = "센서 SSE 스트림")
@GetMapping("/sensor/sse")
public Flux<ServerSentEvent<SensorData>> getSensorSse(
) {
return sensorUseCase.findSensors()
.map(sensorData -> ServerSentEvent.<SensorData>builder()
.id(sensorData.getId())
.event("sensor-event")
.data(sensorData)
.build());
}
}
후에 리더가 DB 폴링하여 Redis Stream 에 Produce(적재) 하는 로직을 작성합니다.
@Service
public class SensorUseCase {
private final RedisStreamProducer producer;
// 리더만 n 초씩 주기적 DB 폴링 하여 발행합니다.
@SseLeaderTask
@Scheduled(fixedRateString = "#{T(org.springframework.boot.convert.DurationStyle).detectAndParse('${sensor.stream.schedule-period}')}")
public void publish(SensorData data) {
producer.publishData("sensor:stream", data);
}
}
이후 Redis Stream 의 메시지를 Consume(소비) 하여 SSE 에 내보내는 도메인 로직을 작성합니다.
위 예제에서는 Flux 를 사용하고 있으므로 Sinks 를 사용하여 내보내겠습니다.
@Component
public class SensorUseCase {
private final static Sinks.Many<SensorData> SENSOR_SINK = Sinks.many().multicast().onBackpressureBuffer();
// 자동 타입 변환 및 ACK
@StreamConsumer(
stream = "sensor:stream",
consumerGroup = "processors",
messageType = SensorData.class
)
public void process(SensorData data) {
SENSOR_SINK.tryEmitNext(data);
}
/**
* Leader 의 DB 폴링에 의해 가져온 센서 데이터를 SSE 로 푸시
*/
public Flux<SensorData> findSensors() {
return SENSOR_SINK.asFlux();
}
}
이에 따라 Redis Stream 을 Consume 한 데이터를 Sinks 에 담아두고,
SSE API 호출에 따라 Spring Netty 가 Sinks 를 구독하게되면
구독 시점 이후부터의 데이터를 받을 수 있게 됩니다.
즉, 구독 시점 이후의 Redis Stream 데이터를 실시간으로 받을 수 있게 되는 것이죠.
이슈 사항 해결 🚨
SSE 연결 구현은 완료되었지만 실제 사용에 있어 여러가지 이슈사항이 있었습니다.
특히 커넥션 문제와 Sinks 처리에 대해 문제가 있었는데요
어떤 문제가 있었고, 어떻게 해결했는지 기술해보겠습니다.
Nginx를 이용한 SSE 전용 설정
사내 인프라에서는 Nginx를 사용하여 DNS 처리, 롤링 업데이트, 라우팅 등을 수행하고 있습니다.
그러나 SSE(Server-Sent Events) 연결은 일반 HTTP 요청과 달리 장시간 지속되는 스트리밍 방식이므로,
기본 설정만으로는 원활하게 동작하지 않을 수 있습니다.
이를 해결하기 위해 /sse가 포함된 경로(/api/${와일드카드}/sse)에 대해 전용 설정을 nginx.conf에 추가하였습니다.
# SSE 엔드포인트 전용 설정
# /api/${와일드카드}/sse
location ~ ^/api/.*/sse$ {
proxy_pass http://aquanuri-api:8080;
# HTTP/1.1 사용 및 Connection 헤더 초기화
proxy_http_version 1.1;
proxy_set_header Connection "";
# 버퍼링 및 캐싱 비활성화 (실시간 전송 보장)
proxy_buffering off;
proxy_cache off;
# 청크 전송 인코딩 활성화
chunked_transfer_encoding on;
# 클라이언트 정보 및 캐시 무효화 헤더 전달
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Cache-Control "no-cache";
proxy_set_header X-Accel-Buffering "no";
# SSE 장기 연결을 위한 타임아웃 확대
proxy_connect_timeout 10s;
proxy_send_timeout 86400s; # 24시간
proxy_read_timeout 86400s; # 24시간
# SSE 응답 헤더 지정
add_header Cache-Control "no-cache";
add_header Content-Type "text/event-stream";
}
-
HTTP/1.1 강제 적용
SSE는 지속적인 연결이 필요하므로
proxy_http_version 1.1을 사용하고,Connection헤더를 비워 연결이 끊기지 않도록 설정합니다. -
버퍼링·캐싱 비활성화
proxy_buffering off,proxy_cache off로 즉시 데이터가 전달되도록 보장합니다. -
장기 타임아웃
proxy_read_timeout과proxy_send_timeout을 24시간으로 설정하여 끊김 없이 장시간 연결을 유지합니다. -
캐시 방지 및 실시간 전송 보장
Cache-Control: no-cache와X-Accel-Buffering: no를 통해 브라우저와 프록시 모두에서 캐시를 방지합니다.
이렇게 하면 Nginx 환경에서도 안정적으로 SSE 스트리밍이 가능하며, 실시간 데이터 전송 품질이 향상됩니다.
Sinks 버퍼
해당 설계에서는 브로커(Broker)에서 발행된 데이터를 Sinks에 담아 SSE(Server-Sent Events)로 전송하는 구조를 사용합니다.
이때 주의할 점은, Sinks가 무제한 버퍼(unbounded buffer) 특성을 가질 수 있다는 것입니다.
즉, 소비자가 느리게 데이터를 처리하면, 버퍼에 데이터가 계속 쌓여 메모리 사용량이 증가할 수 있으므로 관리가 필요합니다.
따라서 버퍼 용량을 지정 및 백프레셔 설정이 추가적으로 필요합니다.
아래와 같이 directBestEffort() 를 사용하여 메모리 최적화를 지킴과 동시에 구독자의 처리속도에 따라 최신 데이터만 처리될 수 있게 하였습니다.
// 전역 SSE 싱크 (하위 호환성 유지 목적)
private static final Sinks.Many<SseResponse<?>> GLOBAL_SINK =
Sinks.many()
.multicast()
.directBestEffort();
토큰 기반 SSE 처리
단일 SSE API에서 모든 사용자 데이터를 브로드캐스트하면, 로그인한 사용자가 본인과 무관한 다른 사람의 데이터까지 수신하게 됩니다.
이 방식은 보안상 취약점을 초래할 수 있으며, 민감한 데이터가 노출될 위험이 있습니다.
이를 방지하기 위해 사용자 토큰(또는 Actor 단위) 별로 SSE 스트림을 관리하는 방식을 적용했습니다.
즉, 각 사용자·역할(Role)·식별자(actorIdx) 조합에 대해 전용 Sinks를 생성하고, 해당 Sink로만 메시지를 전달합니다.
주요 구현 방식
- 전역(Global) Sink
- 모든 사용자에게 브로드캐스트하는 전역 채널.
- 하위 호환성을 위해 유지.
Sinks.many().multicast().onBackpressureBuffer(FLUX_BUFFER_SIZE)방식으로 생성.
- Actor 전용 Sink
"ROLE_FISHFARM:ff123"와 같이 Role과 actorIdx를 조합해 고유 키 생성.- 각 Actor 전용 메시지 또는 전역 메시지만 필터링해 전송.
- 구독자 해제 시 빈 Sink를 안전하게 정리(Double-check 방식, 최대 3회 재검사).
- 메시지 라우팅
- Redis Stream에서 수신한 메시지를 전역 및 해당 Actor Sink에 전달.
- 전역 메시지(
isGlobalBroadcast = true)의 경우, 모든 Actor Sink에도 전송. - 특정 Actor 전용 메시지는 해당 Sink로만 라우팅.
- 버퍼 오버플로우(
FAIL_OVERFLOW)나 종료(FAIL_TERMINATED) 시 안전하게 제거.
- 에러 및 재시도 처리
onErrorContinue로 SSE 연결 중 오류 발생 시 로그 기록 및 Sentry 전송.Retry.backoff로 최대 3회 재시도, 지연 시간 점진적 증가.- 재연결 시도 및 구독자 수 모니터링 포함.
/**
* SSE 메시지 스트림 관리자 Redis Stream에서 수신한 메시지를 클라이언트들에게 전달
*/
@Slf4j
@Component
public class SseSinkManager implements SseSinkPort {
private static final int FLUX_BUFFER_SIZE = 1_000;
// 전역 SSE 싱크 (하위 호환성)
private static final Sinks.Many<SseResponse<?>> GLOBAL_SINK = Sinks.many().multicast().directBestEffort();
// Actor별 SSE 싱크: "ROLE_FISHFARM:ff123" -> Sink
private static final ConcurrentHashMap<String, Sinks.Many<SseResponse<?>>> ACTOR_SINKS = new ConcurrentHashMap<>();
/**
* SSE 클라이언트를 위한 스트림 등록
* <p> - 에러 발생 시 연결 유지를 위한 처리 추가 (재귀호출 처리)
* <p> - 재연결 및 백프레셔 처리 포함
*/
@Override
public Flux<SseResponse<?>> registerSink() {
return GLOBAL_SINK.asFlux()
.doOnSubscribe(subscription -> {
int currentCount = GLOBAL_SINK.currentSubscriberCount();
log.info("새로운 전역 SSE 클라이언트 연결됨 - 연결 후 예상 구독자 수: {}", currentCount + 1);
})
.doOnCancel(() -> {
int remainingCount = GLOBAL_SINK.currentSubscriberCount();
log.info("전역 SSE 클라이언트 연결 해제됨 - 남은 구독자 수: {}", Math.max(0, remainingCount - 1));
})
.doOnNext(response -> {
log.info("전역 SSE 메시지 전송: ID={}, Type={}", response.getId(), response.getSseType());
})
.onErrorContinue((e, v) -> {
log.info("[재시도 처리 중,,] 전역 SSE 에러 발생: {}", e.toString(), e);
Sentry.captureException(e);
})
.retryWhen(
Retry.backoff(3, Duration.ofSeconds(1))
.maxBackoff(Duration.ofSeconds(10))
.doBeforeRetry(rs -> log.info("전역 SSE 재시도 #{}: {}",
rs.totalRetries() + 1, rs.failure().toString()))
)
.doOnError(e -> {
log.info("[재시도 불가능] 전역 SSE 스트림 터미널 에러", e);
Sentry.captureException(e);
})
.share();
}
/**
* Actor별 SSE 스트림 등록 (양식장, 직원, 관리자 모두 지원)
*/
@Override
public Flux<SseResponse<?>> registerActorSink(Role role, String actorIdx) {
Sinks.Many<SseResponse<?>> sink = getActorSink(role, actorIdx);
String actorKey = createActorKey(role, actorIdx);
log.info("Actor SSE 등록 - Role: {}, ActorIdx: {}, ActorKey: {}, 총 등록된 Sink 수: {}",
role, actorIdx, actorKey, ACTOR_SINKS.size());
log.info("현재 등록된 모든 ActorKey 목록: {}", ACTOR_SINKS.keySet());
return sink.asFlux()
// 해당 액터용 메시지 또는 전역 메시지만 필터링
.filter(response -> {
boolean isGlobalBroadcast = response.isGlobalBroadcast();
boolean isForThisActor = response.isForActor(actorIdx, role);
boolean shouldPass = isGlobalBroadcast || isForThisActor;
log.info("메시지 필터링 검사 - 등록된 ActorKey: {}, {}, 전역 메시지 여부: {}, Actor 전용 여부: {}, 통과여부: {}",
actorKey,
response,
isGlobalBroadcast,
isForThisActor,
shouldPass
);
return shouldPass;
})
.doOnSubscribe(sub -> {
log.info("{} {} Actor 전용 SSE 클라이언트 연결 완료 - ActorKey: {}, 구독자 수: {}",
role.name(), actorIdx, actorKey, sink.currentSubscriberCount());
})
.doOnCancel(() -> {
log.info("{} {} Actor 전용 SSE 클라이언트 연결 해제 시작 - ActorKey: {}, 해제 전 구독자 수: {}",
role.name(), actorIdx, actorKey, sink.currentSubscriberCount());
cleanupEmptySink(actorKey);
})
.doOnNext(response -> {
log.info("Actor 전용 SSE 메시지 전송: ID={}, Type={}", response.getId(), response.getSseType());
})
.onErrorContinue((e, v) -> {
log.info("[재시도 처리 중,,] Actor 전용 SSE 에러 발생: {}", e.toString(), e);
Sentry.captureException(e);
})
.retryWhen(
Retry.backoff(3, Duration.ofSeconds(1))
.maxBackoff(Duration.ofSeconds(10))
.doBeforeRetry(rs -> log.info("Actor 전용 SSE 재시도 #{}: {}",
rs.totalRetries() + 1, rs.failure().toString()))
)
.doOnError(e -> {
log.info("[재시도 불가능] Actor 전용 SSE 스트림 터미널 에러", e);
Sentry.captureException(e);
})
.share();
}
/**
* Actor 식별자 생성 (Role + actorIdx 조합)
*/
private String createActorKey(Role role, String actorIdx) {
return String.format("%s:%s", role.getFullRoleName(), actorIdx);
}
/**
* 특정 Actor의 SSE 싱크를 가져오거나 생성
*/
private Sinks.Many<SseResponse<?>> getActorSink(Role role, String actorIdx) {
String actorKey = createActorKey(role, actorIdx);
return ACTOR_SINKS.computeIfAbsent(actorKey, key -> {
log.info("{} {} 전용 SSE 싱크 생성", role.name(), actorIdx);
return Sinks.many().multicast().directBestEffort();
});
}
/**
* 사용하지 않는 싱크 정리
*/
private void cleanupEmptySink(String actorKey) {
// 다단계 검증으로 안전한 정리 수행
reactor.core.scheduler.Schedulers.single().schedule(() -> {
performSafeCleanup(actorKey, 1); // 첫 번째 시도
}, 200, java.util.concurrent.TimeUnit.MILLISECONDS); // 200ms 지연으로 확실한 타이밍 확보
}
private void performSafeCleanup(String actorKey, int attempt) {
Sinks.Many<SseResponse<?>> sink = ACTOR_SINKS.get(actorKey);
if (sink == null) {
log.info("Actor {} 싱크가 이미 제거됨 (시도 #{})", actorKey, attempt);
return;
}
int currentSubscribers = sink.currentSubscriberCount();
log.info("정리 검사 #{} - ActorKey: {}, 구독자 수: {}, Sink 해시: {}",
attempt, actorKey, currentSubscribers, sink.hashCode());
// 구독자가 0명일 때만 정리 (더 엄격한 조건)
if (currentSubscribers == 0) {
// Double-check 를 위한 재검증
reactor.core.scheduler.Schedulers.single().schedule(() -> {
Sinks.Many<SseResponse<?>> recheckSink = ACTOR_SINKS.get(actorKey);
if (recheckSink != null && recheckSink.currentSubscriberCount() == 0) {
Sinks.Many<SseResponse<?>> removedSink = ACTOR_SINKS.remove(actorKey);
if (removedSink != null) {
log.info("Actor {} SSE 싱크 안전 정리 완료 - 남은 Sink 수: {}", actorKey, ACTOR_SINKS.size());
removedSink.tryEmitComplete();
}
} else {
log.info("Actor {} 재검증에서 구독자 발견 - 정리 중단", actorKey);
}
}, 50, java.util.concurrent.TimeUnit.MILLISECONDS);
} else if (attempt < 3) {
// 최대 3번까지 재시도 (구독자가 남아있는 경우)
log.info("Actor {} 구독자 {}명 존재 - {}초 후 재검사 (시도 #{}/3)",
actorKey, currentSubscribers, attempt, attempt);
reactor.core.scheduler.Schedulers.single().schedule(() -> {
performSafeCleanup(actorKey, attempt + 1);
}, attempt * 500L, java.util.concurrent.TimeUnit.MILLISECONDS); // 점진적 지연
} else {
log.info("Actor {} 정리 포기 - 구독자 {}명이 지속적으로 존재함", actorKey, currentSubscribers);
}
}
/**
* Redis Stream 에서 수신한 메시지를 SSE 클라이언트들에게 전송
* <p> - 버퍼 오버플로우 상황 처리 추가
*/
@StreamConsumer(stream = "${sse.stream.key}", messageType = SseResponse.class)
public void sinkSseResponse(SseResponse<?> sseResponse) {
log.info("SSE 메시지 수신 처리 시작 - ID: {}, Type: {}, ActorIdx: {}, ActorRole: {}, GlobalBroadcast: {}",
sseResponse.getId(), sseResponse.getSseType(), sseResponse.getActorIdx(),
sseResponse.getActorRole(), sseResponse.isGlobalBroadcast());
// 1. 전역 브로드캐스트 처리
// 모든 actor sinks 에도 전송
if (sseResponse.isGlobalBroadcast()) {
log.info("전역 브로드캐스트 메시지 처리 - 활성 Actor Sink 수: {}", ACTOR_SINKS.size());
GLOBAL_SINK.tryEmitNext(sseResponse);
ACTOR_SINKS.values().forEach(sink -> sink.tryEmitNext(sseResponse));
return;
}
// 2. 특정 Actor 라우팅
emitToActor(sseResponse);
// 3. 전역 SSE 에도 전송 (하위 호환성)
Sinks.EmitResult globalResult = GLOBAL_SINK.tryEmitNext(sseResponse);
log.info("전역 SSE 전송 결과: {}, 전역 구독자 수: {}", globalResult, GLOBAL_SINK.currentSubscriberCount());
}
/**
* SSE 클라이언트에게 전송
*/
private void emitToActor(SseResponse<?> sseResponse) {
String actorIdx = sseResponse.getActorIdx();
Role actorRole = sseResponse.getActorRole();
if (actorIdx == null || actorRole == null) {
log.info("Actor 정보 누락 — 전송 없이 종료 (actorIdx={}, actorRole={})", actorIdx, actorRole);
return;
}
String actorKey = createActorKey(actorRole, actorIdx);
log.info("Actor 라우팅 시도 - ActorKey: {}, 현재 등록된 Actor Sink 키들: {}",
actorKey, ACTOR_SINKS.keySet());
Sinks.Many<SseResponse<?>> actorSink = ACTOR_SINKS.get(actorKey);
if (actorSink == null) {
log.info("활성 SSE 연결 없음 - ActorKey: {}, 등록된 Sink 수: {}", actorKey, ACTOR_SINKS.size());
return;
}
log.info("Actor Sink 발견 - ActorKey: {}, 구독자 수: {}", actorKey, actorSink.currentSubscriberCount());
Sinks.EmitResult result = actorSink.tryEmitNext(sseResponse);
if (result.isFailure()) {
log.info("{} {} SSE 메시지 전송 실패: {}", actorRole.name(), actorIdx, result);
if (result == Sinks.EmitResult.FAIL_OVERFLOW) {
log.info("{} {} SSE 버퍼 오버플로우 - 메시지 버림", actorRole.name(), actorIdx);
} else if (result == Sinks.EmitResult.FAIL_TERMINATED) {
log.info("{} {} SSE 싱크가 종료됨 - Map에서 제거", actorRole.name(), actorIdx);
ACTOR_SINKS.remove(actorKey);
}
} else {
log.info("Actor SSE 전송 성공 - ActorKey: {}, 결과: {}", actorKey, result);
}
}
}
이를 통해 아래와 같은 이점을 확보할 수 있었습니다.
- 보안성 강화: 타 사용자의 데이터 접근 차단.
- 리소스 효율화: 각 Actor별로 필요한 데이터만 전송.
- 유연성: 전역/개별 Actor 대상 브로드캐스트 모두 지원.
- 안정성: 버퍼 오버플로우 및 연결 종료 시 자동 정리.
처리 완료된 Stream Message 삭제 처리
XREAD로 소비만 하고 삭제를 안 하면 Redis Stream에 불필요한 메시지가 계속 적재되어 메모리 사용량이 증가합니다.
이에 따라 발행 시점에 길이 기반 트리밍(MAXLEN) 을 적용해 스트림을 상시 유한 크기로 유지합니다.
// 3. Redis Stream에 레코드 추가 (XADD 실행)
streamRedisTemplate.opsForStream().add(record, XAddOptions.maxlen(sseStreamEvictLength));테스트 🧪
💡
아래 테스트 환경을 사용하여 테스트 하였습니다.
- 가상의 날씨 데이터를 1초 단위로 계속 생성
- Docker swarm 을 이용하여 인프라 스케일링
- 앱 서버
- 레디스 클러스터
- MySQL
- k6 로 테스트 스크립트 작성
Smoke Test 💨
Leader Election
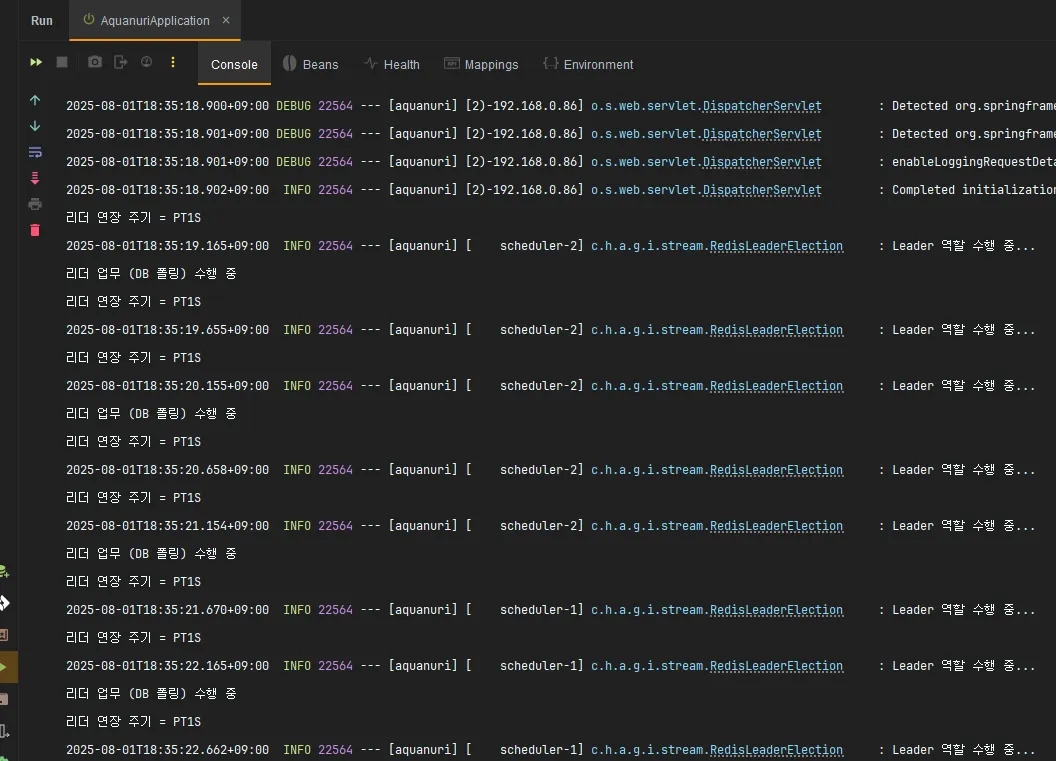
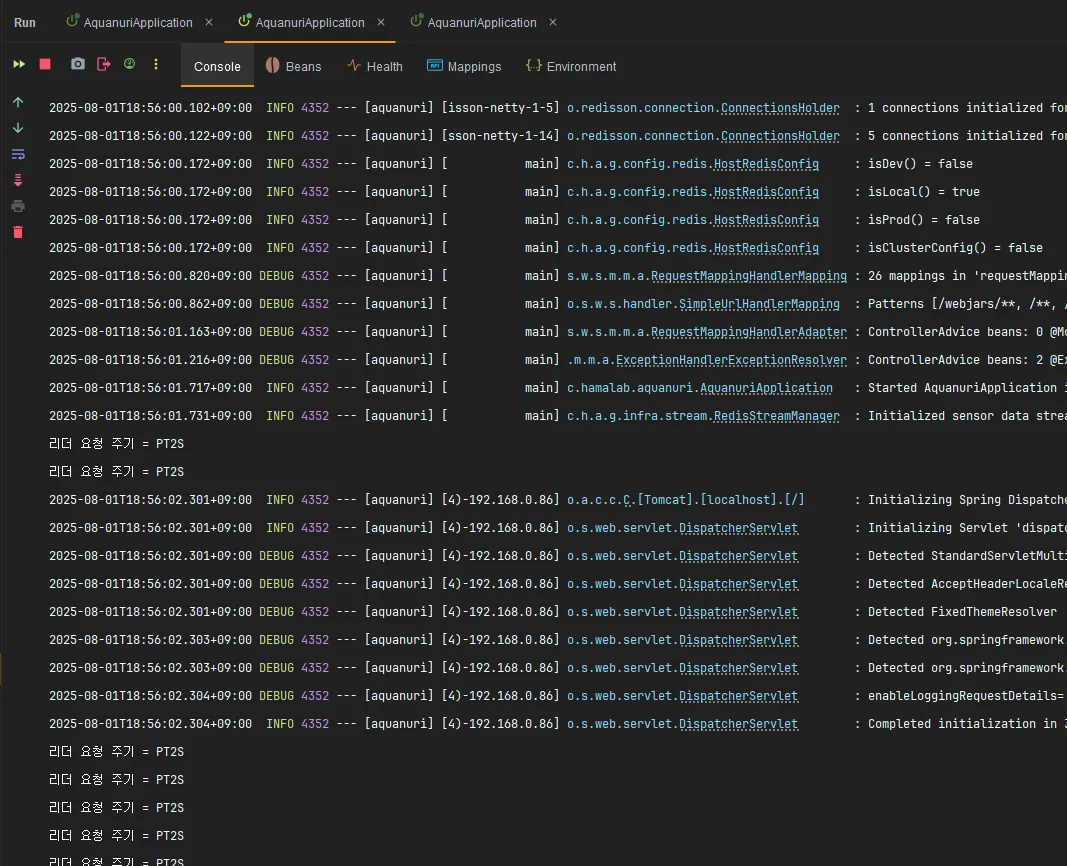
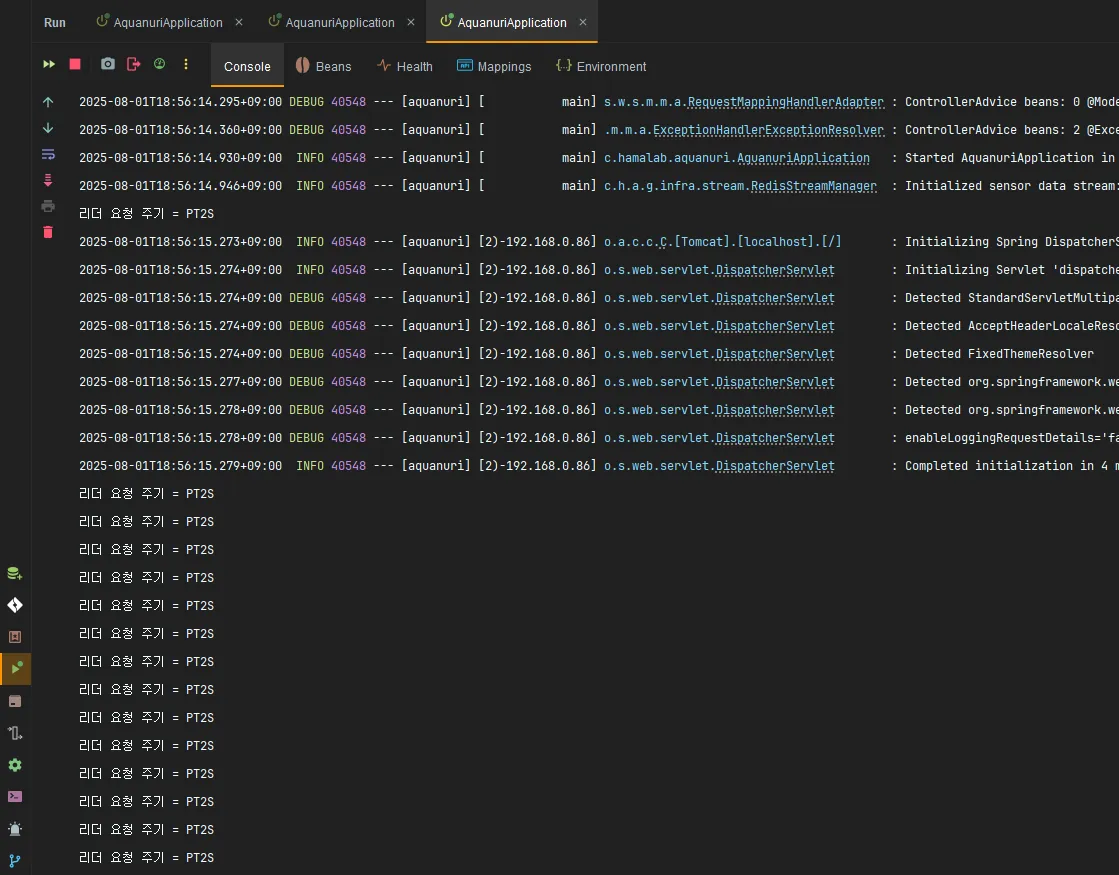
인스턴스를 여러 개 실행하여 하나의 인스턴스만 리더인지를 로그를 통해 확인하였습니다.
scheduler-1,scheduler-2모두 리더 선출 로직을 실행- 한 인스턴스가
Leader 역할 수행 중...로그 반복적으로 출력 → 리더 자격 유지 확인 - 나머지 인스턴스들은
리더 요청 주기 = PT2S만 주기적으로 출력 → 팔로워(비리더) 상태 유지
Leader
Follower
Redis Stream
SSE 연결을 맺을 때 서로 다른 서버가 동일한 순서의 메시지를 가져오는지 확인하였습니다.
| 항목 | 8080 포트 응답 | 8081 포트 응답 | 일치 여부 |
|---|---|---|---|
| HTTP 헤더 | Content-Type: text/event-stream 등 동일 | 동일 | ✅ |
| 이벤트 개수 | 8개 | 8개 | ✅ |
| 이벤트 ID 순서 | 42c2dcf5 → a0ab34ac → 3fa16cbc → … → 2c4ac462 | 동일한 순서 | ✅ |
| event 타입 | 모두 weather-event | 동일 | ✅ |
| 데이터(payload) | 각 ID별 location‧status‧temperature 값이 완전 동일 | 동일 | ✅ |
두 서버(8080, 8081)에서 받아온 스트림을 비교해보면
① 헤더 구성, ② 이벤트 개수, ③ ID와 전송 순서, ④ 이벤트 유형, ⑤ JSON payload가 모두 같았습니다.
즉 퍼블리셔가 하나의 Redis Streams 소스에서 동일 메시지를 전파하고 있기 때문에,
어느 인스턴스에 접속해도 동일한 순서로 동일 데이터를 수신함을 확인할 수 있습니다.
GET http://localhost:8080/api/v1/permitall/weather/sse
HTTP/1.1 200
Vary: Origin
Vary: Access-Control-Request-Method
Vary: Access-Control-Request-Headers
X-Content-Type-Options: nosniff
X-XSS-Protection: 0
Cache-Control: no-cache, no-store, max-age=0, must-revalidate
Pragma: no-cache
Expires: 0
X-Frame-Options: DENY
Content-Type: text/event-stream
Transfer-Encoding: chunked
Date: Mon, 04 Aug 2025 10:47:10 GMT
Response code: 200; Time: 167ms (167 ms)
id:42c2dcf5-7a83-4d24-b9e4-10d67bc23d6e
event:weather-event
data:{"id":"42c2dcf5-7a83-4d24-b9e4-10d67bc23d6e","timestamp":"2025-08-04T19:47:25.7455959","location":"SEOUL","status":"SNOW","temperature":"M"}
id:a0ab34ac-1032-43e1-8b9a-808a03050bc1
event:weather-event
data:{"id":"a0ab34ac-1032-43e1-8b9a-808a03050bc1","timestamp":"2025-08-04T19:47:25.7455959","location":"SEOUL","status":"SUNNY","temperature":"COLD"}
id:3fa16cbc-208b-4cfb-a4dd-ed91a2e6806b
event:weather-event
data:{"id":"3fa16cbc-208b-4cfb-a4dd-ed91a2e6806b","timestamp":"2025-08-04T19:47:25.7455959","location":"SEOUL","status":"RAIN","temperature":"COLD"}
id:a02fc403-6309-4373-97b1-082d683c96fe
event:weather-event
data:{"id":"a02fc403-6309-4373-97b1-082d683c96fe","timestamp":"2025-08-04T19:47:25.7455959","location":"SEOUL","status":"RAIN","temperature":"COLD"}
id:6b7576d2-a22f-42ba-babf-1061b5f9deee
event:weather-event
data:{"id":"6b7576d2-a22f-42ba-babf-1061b5f9deee","timestamp":"2025-08-04T19:47:25.7455959","location":"SEOUL","status":"SUNNY","temperature":"M"}
id:c3d2c117-8de3-4469-838a-c4fd1378d44a
event:weather-event
data:{"id":"c3d2c117-8de3-4469-838a-c4fd1378d44a","timestamp":"2025-08-04T19:47:25.7455959","location":"SEOUL","status":"SUNNY","temperature":"HOT"}
id:ceacc28c-70c2-49c9-94ca-360a6da67774
event:weather-event
data:{"id":"ceacc28c-70c2-49c9-94ca-360a6da67774","timestamp":"2025-08-04T19:47:25.7467891","location":"JEJU","status":"SNOW","temperature":"HOT"}
id:2c4ac462-de44-44cc-aa62-80fcd1815f3b
event:weather-event
data:{"id":"2c4ac462-de44-44cc-aa62-80fcd1815f3b","timestamp":"2025-08-04T19:47:25.7467891","location":"JEJU","status":"SUNNY","temperature":"COLD"}GET http://localhost:8081/api/v1/permitall/weather/sse
HTTP/1.1 200
Vary: Origin
Vary: Access-Control-Request-Method
Vary: Access-Control-Request-Headers
X-Content-Type-Options: nosniff
X-XSS-Protection: 0
Cache-Control: no-cache, no-store, max-age=0, must-revalidate
Pragma: no-cache
Expires: 0
X-Frame-Options: DENY
Content-Type: text/event-stream
Transfer-Encoding: chunked
Date: Mon, 04 Aug 2025 10:47:07 GMT
Response code: 200; Time: 177ms (177 ms)
id:42c2dcf5-7a83-4d24-b9e4-10d67bc23d6e
event:weather-event
data:{"id":"42c2dcf5-7a83-4d24-b9e4-10d67bc23d6e","timestamp":"2025-08-04T19:47:25.7455959","location":"SEOUL","status":"SNOW","temperature":"M"}
id:a0ab34ac-1032-43e1-8b9a-808a03050bc1
event:weather-event
data:{"id":"a0ab34ac-1032-43e1-8b9a-808a03050bc1","timestamp":"2025-08-04T19:47:25.7455959","location":"SEOUL","status":"SUNNY","temperature":"COLD"}
id:3fa16cbc-208b-4cfb-a4dd-ed91a2e6806b
event:weather-event
data:{"id":"3fa16cbc-208b-4cfb-a4dd-ed91a2e6806b","timestamp":"2025-08-04T19:47:25.7455959","location":"SEOUL","status":"RAIN","temperature":"COLD"}
id:a02fc403-6309-4373-97b1-082d683c96fe
event:weather-event
data:{"id":"a02fc403-6309-4373-97b1-082d683c96fe","timestamp":"2025-08-04T19:47:25.7455959","location":"SEOUL","status":"RAIN","temperature":"COLD"}
id:6b7576d2-a22f-42ba-babf-1061b5f9deee
event:weather-event
data:{"id":"6b7576d2-a22f-42ba-babf-1061b5f9deee","timestamp":"2025-08-04T19:47:25.7455959","location":"SEOUL","status":"SUNNY","temperature":"M"}
id:c3d2c117-8de3-4469-838a-c4fd1378d44a
event:weather-event
data:{"id":"c3d2c117-8de3-4469-838a-c4fd1378d44a","timestamp":"2025-08-04T19:47:25.7455959","location":"SEOUL","status":"SUNNY","temperature":"HOT"}
id:ceacc28c-70c2-49c9-94ca-360a6da67774
event:weather-event
data:{"id":"ceacc28c-70c2-49c9-94ca-360a6da67774","timestamp":"2025-08-04T19:47:25.7467891","location":"JEJU","status":"SNOW","temperature":"HOT"}
id:2c4ac462-de44-44cc-aa62-80fcd1815f3b
event:weather-event
data:{"id":"2c4ac462-de44-44cc-aa62-80fcd1815f3b","timestamp":"2025-08-04T19:47:25.7467891","location":"JEJU","status":"SUNNY","temperature":"COLD"}총평 💬
SSE 는 다루기 어려운 프로토콜이고, 특히 토큰 별로 처리하려다보니
메모리 리소스도 많아 관리요소가 높다고 생각합니다.
여러 난관이 있었고, 아직 처리해야할 게 많습니다.
이후 추가적으로 아래 사항들에 대해 보완할 예정입니다.
- Load Test
- Dynamic Stream Message Trimmer
- Redis Stream Monitor Bot
레퍼런스
- https://docs.spring.io/spring-data/redis/reference/redis/redis-streams.html
- https://github.com/jonathan-foucher/spring-boot-redis-stream-example/blob/master/src/main/java/com/jonathanfoucher/redisstreamexample/
- https://kjwit.tistory.com/entry/Spring-Data-Redis-Streams
- https://www.baeldung.com/spring-server-sent-events
- https://mattwestcott.org/blog/redis-streams-vs-kafka
- https://dev.gmarket.com/113
- https://blog.stackademic.com/redis-stream-with-go-from-queue-creation-to-reliable-message-retries-65ad5ac71c0c
