pandas
python에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈, 단일 프로세스에서는 최대효율
스테로이드 맞은 엑셀.... , 버전에 따라 문법이나 옵션이 달라 확인해야함
from MODULE import function : MODULE에 포함된 function 하나만 사용!
- 통상 csv는 띄어쓰기로 구분되니 pd.read_csv(경로,encoding="utf-8") 명령으로 읽기만 해도 됨
cd Documents 이런식으로 현재 위치 지정 가능! // .. : 상위폴더로 이동
-
파일명,위치 입력할 때 적당한 곳에서 TAB키 누르면 자동완성기능 뜸!
pandas read_excel documentation 처럼 검색하면 자세한 설명문서 나옴
- 변수명 = pd.read_excel(경로,header=2, usecols="A,B"), header: 자료를 읽기 시작할 행 지정, usecols:읽어올 col 지정(A,B이건 엑셀 기준!)
변수명 = pd.read_excel(
"../data/어쩌구저쩌구",header=2,usecols="B, C, D, "
)-
Series : Pandas의 데이터형을 구성하는 기본
-
column 이름 변경 : 변수명.rename(columns={변수명.columns[바꿀인덱스] : "바꿀이름"}, inplace=True) // 한줄에 쓰면 읽기 쉽지 않으니 가독성고려해서 입력!
Data.rename(columns={Data.columns[0] : "바꿀이름",
Data.columns[1] : '바꿀이름2'},
inplace=True)
- date_range : 날짜(시간)를 이용할 수 있음
x = pd.Series([1,3,5, np.nan])
dates = pd.date_range("20210916", periods=6) #periods : n일 날짜생성
output : DatetimeIndex(['2021-09-16', '2021-09-17', '2021-09-18', '2021-09-19',
'2021-09-20', '2021-09-21'],
dtype='datetime64[ns]', freq='D')
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=["A","B","C","D"])
#6 by 4 매트릭스 생성
# 컬럼추가, 기존컬럼이 없으면 추가하고 있으면 수정
df["이름"] = ["내용","내용1","내용2"]- df["컬럼명"],df.컬럼명 으로 해당 컬럼 조회가능, 컬럼을 숫자로 하면 조회X "1"처럼해도 X
두개 이상의 컬럼 선택시에는 df[["A","B]] 처럼 리스트에 담으면 됨 - .loc[행,열] : index이름으로 특정 행,열을 선택 , ex) df.loc["2021-09-17",["A","B"]]
df.loc[:,["A","B"]]
# pandas의 보편적인 slice 옵션
# 위 처럼하면 모든행, "A","B"열을 출력
# 일반적으로 n:m이면 n부터 m-1 까지만 index나 이름으로 하는경우 끝도 포함-
.iloc[row인덱스,col인덱스] 로 해당 정보 조회가능 , ex)df.iloc[[1,2,4],[0,2]]
-
.head(보고싶은 갯수) 명령어 : 상위 5개의 정보 나타내줌, R이랑 똑같은듯 , tail()도 똑같음
-
.info() : DataFrame의 기본 정보 확인, 보통 col의 크기 데이터의 형태를 확인함
-
.columns로 column 조회가능

-
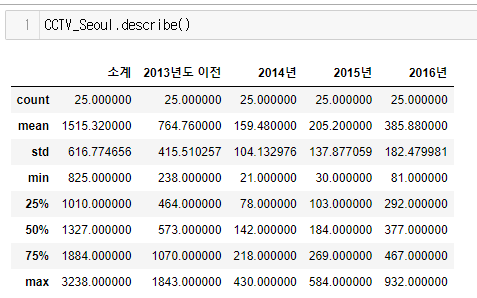
.describe() : DataFrame의 통계적 기본 정보 확인
-
.corr() : 상관계수를 나타내줌
-
.sort_valuese(by="기준이 될 컬럼", ascending=False) // 선택 컬럼기준으로 내림차,오름차순 정렬
-
.unique() 로 중복된건 제거, ex) x.unique()
Pandas Slice under condition
일반적으로 df[condition]과 같이 필터링해서 사용
df[df>0] , df["A">0] 처럼 필터링가능
# A 컬럼에서 0보다 큰 숫자만 선택
df["A"]>0
output -> True,False 마냥 뜸
# 필터링된거 출력
df[df["A"]>0]
df[df>0] # NaN까지 출력-
df["컬럼"].isin(["요소"]) : 특정 요소가 있는지 확인
#예시 df["E"].isin(["two","four"]) output -> True,False 마냥 뜸 #특정 요소가 있는 행만 선택 df[df["E"].isin(["two","four"])]컬럼 삭제
del 지우고싶은 컬럼 ex) del df["E"]
df.drop(지우고싶은 행 또는 열 ,axis=) , ex) df.drop(["D"],axis=1) ,축 설정안할시 디폴트는 row임
df.apply(함수) : 특정 함수를 적용가능, ex) df.apply(np.cumsum)
offset index : [n:m] : n부터 m-1 까지, 인덱스나 컬럼의 이름으로 slice하는경우 끝도 포함
Pandas Index 지정
index를 재지정하는 명령어이다.
.set_index("기준",inplace=True)
#예시
data.set_index("구별",inplace=True)유니크한 데이터를 인덱스로 잡으면 그래프 그릴 때 편함!
데이터 합치기
concat(), merger(), join() 세 가지 방법으로 합칠 수 있음.
-
merge : .merge(data1,data2,how="기준데이터",on="기준")
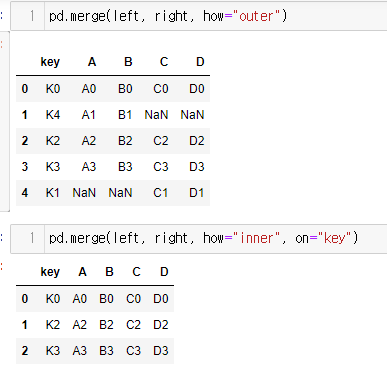
ex) pd.merge(left,right,how='left',on='key'), left는 다 살아있고 left와 right끼리 겹치는 것 만 합침
how='outer' 로 할 시 둘 다 손상되지 않도록 병합,
how='inner' 로 할 시 두 데이터의 공통분모만 병합 // inner가 디폴트
Analysis Seoul CCTV
import numpy as np
import pandas as pd
CCTV_seoul = pd.read_csv(
"주소",encoding="utf-8"
)
CCTV_seoul.rename(columns={CCTV_seoul.columns[0] : "구별"}, inplace=True)
pop_Seoul = pd.read_excel("C:/Users/PH/data/01. Seoul_Population.xls")
pop_Seoul = pd.read_excel("C:/Users/PH/data/01. Seoul_Population.xls",header=2,usecols="B, D, G, J, N")
pop_Seoul.rename(columns={pop_Seoul.columns[0]:"구별",pop_Seoul.columns[1]:"인구수",pop_Seoul.columns[2]:"한국인",pop_Seoul.columns[3]:"외국인",pop_Seoul.columns[4]:"고령자"},inplace=True)
pop_Seoul['외국인비율'] = pop_Seoul["외국인"] / pop_Seoul["인구수"] * 100
CCTV_seoul["최근증가율"] = (CCTV_seoul["2016년"] + CCTV_seoul["2015년"]) / CCTV_seoul["2013년도 이전"] * 100
data_result = pd.merge(CCTV_seoul, pop_Seoul, on="구별")
data_result["CCTV 비율"] = data_result["소계"] / data_result["인구수"] * 100
del data_result["2014년"]
del data_result["2015년"]
del data_result["2016년"]
del data_result["2013년도 이전"]
data_result.set_index("구별", inplace=True)
data_result.head()