
7장에서는 리액티브 마이크로서비스 개발 방법 (==스프링을 사용해 논블로킹 동기 REST API 및 비동기 이벤트 기반 서비스를 개발하는 방법)을 배우고, 이 두 가지 방식의 선택 기준도 배운다. 끝으로 리액티브 마이크로서비스 환경을 위한 수동 및 자동 테스트를 작성하고 실행하는 방법을 살펴본다.
논블로킹
- 논 블로킹 : 처리되어야 하는 한 작업이 전체적인 작업의 흐름을 안막는다
- 블로킹 : 막는다
다른 작업을 수행하는 주체가 어떻게 상대하는지에 따라 달라짐동기와 비동기
처리해야 할 작업들을 어떤 흐름으로 처리 할 것인가에 대한 관점
- 동기 : 호출되는 함수의 작업 완료 여부를 신경쓴다
- 비동기 : 안쓴다.
참고 https://velog.io/@hayeon/%EB%8F%99%EA%B8%B0-%EB%B9%84%EB%8F%99%EA%B8%B0-%EB%B8%94%EB%A1%9C%ED%82%B9-%EB%85%BC%EB%B8%94%EB%A1%9C%ED%82%B9
이번 장에서 사용한 소스 코드는
https://github.com/PacktPublishing/Hands-On-Microservices-with-Spring-Boot-and-Spring-Cloud/tree/master/Chapter07
버전 :
스프링 클라우드 2.1.0
스프링 부트 2.1.2, 스프링 5.1.4
논블로킹 동기 API와 이벤트 기반 비동기 서비스의 선택 기준
리액티브 마이크로서비스를 개발 시 1. 논블로킹 동기 API와 2. 이벤트 기반 비동기 서비스 중 어떤걸 사용할지 정해져잇는 것 XX 자율적 OO
if ) 런타임 의존성 최소화(=느슨한 결합) ==>동기 API << 이벤트 기반 비동기 메시지 전달 방식 선호
b/c 런타임에 다른 여러 서비스에 메시징 시스템에만 접근하면 되기 때문
if2 ) 최종 사용자가 응답을 기다리는 읽기 작업 ==> 논블로킹 동기 API >> 이벤트 기반 비동기 서비스
if 3 ) 모바일 앱이나 SPA 웹 애플리케이션처럼 동기 API가 알맞은 클라이언트 플랫폼 ==> 논블로킹 동기 API >> 이벤트 기반 비동기 서비스
if 4 ) 클라이언트가 다른 조직의 서비스에 연결할 시 ==> 논블로킹 동기 API >> 이벤트 기반 비동기 서비스
(b/c 여러 조직이 공통 메시징 시스템을 공유불가 )
이번에 시스템 환경구성은
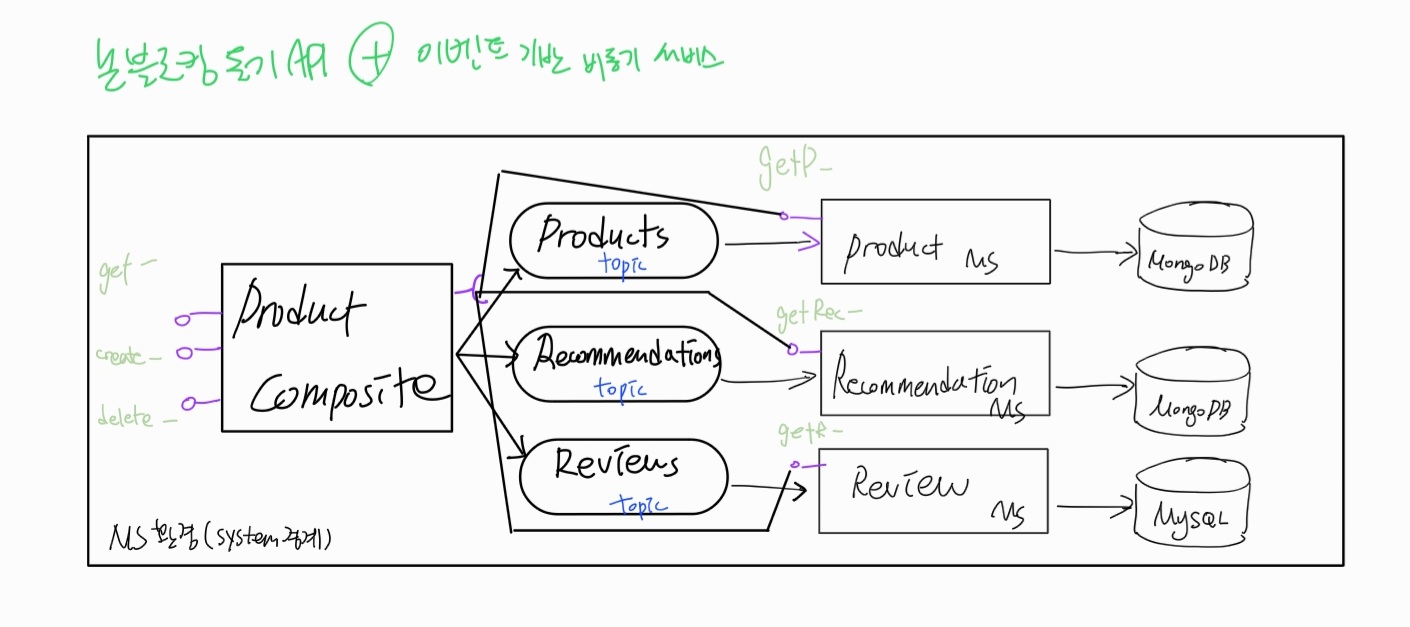
-
product-composite : 동기 api (b/c1 복합 마이크로서비스는 웹 및 모바일 플랫폼을 대상 + b/c2 시스템 환경을 운영하는 조직이 아닌 다른 조직의 클라이언트를 주로 상대한다고 가정)
-
핵심 마이크로서비스가 제공하는 읽기 서비스 : 논블로킹 동기 API (b/c 응답을 기다리는 최종 사용자가 있기 때문)
-
핵심 마이크로서비스의 생성/ 삭제 서비스 : 이벤트 기반 비동기 서비스 ( 복합 마이크로서비스가 제품 집계 정보의 생성 및 삭제를 위해 제공하는 동기 API는, 핵심 서비스가 수신하는 토픽에 생성 및 삭제 이벤트를 게시한 후 바로 200(OK) 응답을 반환)
스프링을 사용해 논블로킹 동기 REST API 개발
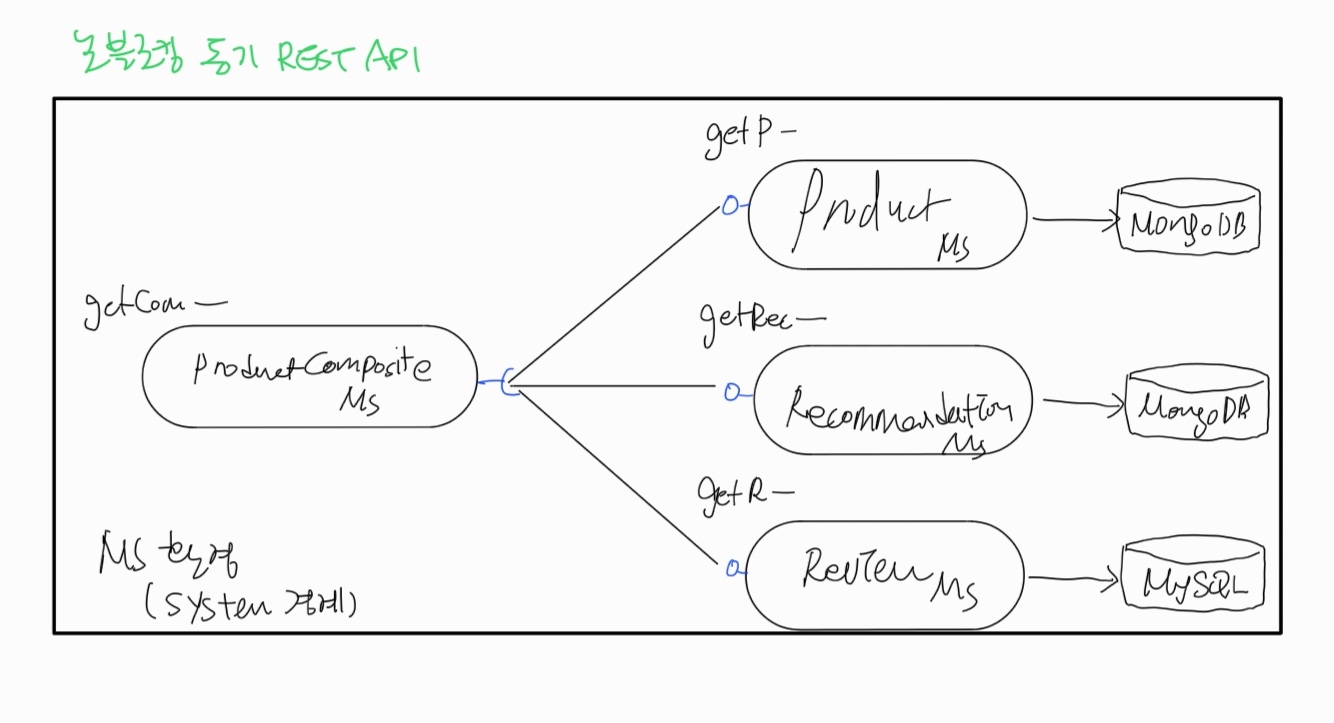
Spring Reactor 소개
스프링 5의 리액티브 지원은 project reactor 기반이다.
project reactor는 reactive 애플리케이션 구축의 표준인 reactive stream 사양을 기반으로 한다.
스프링 webflux, 스프링 webclient, 스프링 data ==> 스프링 리액터를 사용해 리액티브 및 논블로킹 기능을 제공
@Test
public void TestFlux() {
List<Integer> list = new ArrayList<>();
Flux.just(1, 2, 3, 4)
.filter(n -> n % 2 == 0)
.map(n -> n * 2)
.log()
.subscribe(n -> list.add(n));
assertThat(list).containsExactly(4, 8);
}1,2,3,4 정수로 스트림 시작-> 홀수만 filer -> 스트림 값에 *2 해서 변환(map) -> map 끝나면 log에 스트림 데이터 기록 -> 스트림을 처리하려면 구독자가 있어야 한다.!! 호출된 subscribe 메서드로 구독자를 등록. 스트림에서 받은 각 요소에 람다 lambda 함수를 적용하며, 스트림에서 받은 각 요소를 list에 add -> 스트림 처리 결과가 담긴 list에 assertThat 예상 값인 정수 4, 8이 있는지 검증 containsExactly
출력 로그
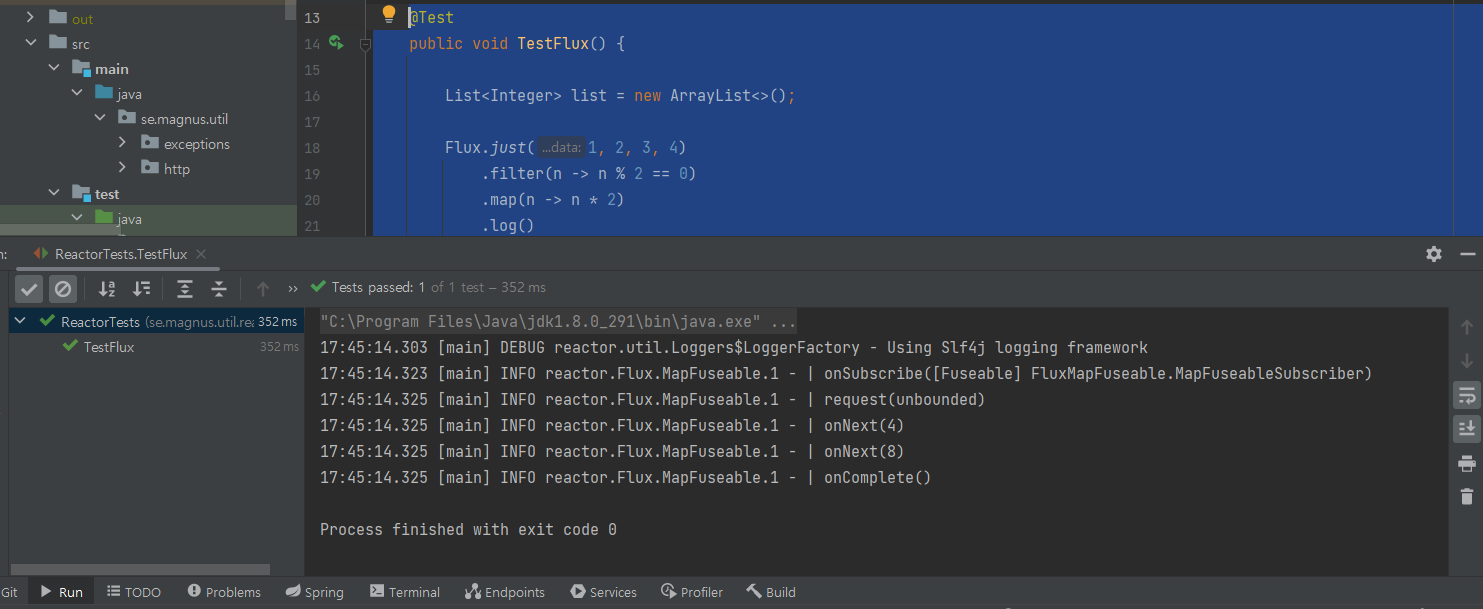
onSubscribe([Fuseable] FluxMapFuseable.MapFuseableSubscriber) : 스트림을 구독하는 구독자가 스트림 처리를 시작하고 스트림 콘텐츠를 요청
onComplete() : 구독자가 onComplete() 호출해 스트림 종료를 알리면 처리가 종료
스프링 데이터 MongoDB를 사용한 논블로킹 영속성
- repository 기본 클래스를 CrudRepository<RecommendationEntity, String>에서 ReactiveCrudRepository로 변경
- 사용자 정의 쿼리 메서드가 Mono 또는 Flux 객체를 반환하도록 변경
를 통해서 product 및 recommendation 서비스의 MongoDB 기반 리포지토리를 reactive 하게 만듦
변경해주니까 테스트 코드가 에러나고 난리났느데 테스트 코드도 변경해주자
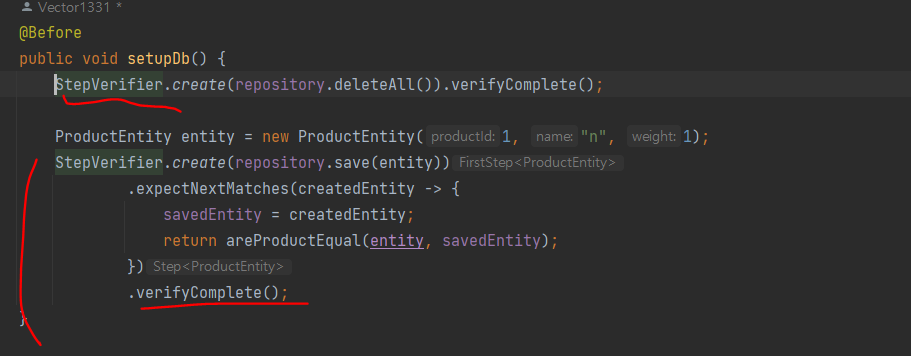
영속성 메서드가 Mono나 Flux 객체를 반환하므로 테스트 메서드는 반환된 리액티브 객체에서 결과를 받을 때까지 기다려야 함
StepVerifier 클래스를 사용해 repository 검색하고 결과를 확인하는 처리 절차를 설 정하는 방법도 있음
설정을 다 하고 verifyComplete() 메서드를 호출하면 시퀀스 시작함
핵심 서비스의 논블로킹 REST API 및 블로킹 방식의 JPA 영속성 계층
핵심서비스도 코드 변경해야함
- api를 리액티브 데이터 유형을 반환하도록
- 서비스 구현변경으로 블로킹 코드 제거
- 리액티브 서비스를 테스트할 수 있도록 테스트를 변경한다.
- 논블로킹 코드와 계속 블로킹 방식을 사용해야 하는 코드를 분리한다.
-
api 변경 (ProductService, RecommendationService, ReviewService)
원래처럼 Product 객체를 반환하는게 아니라
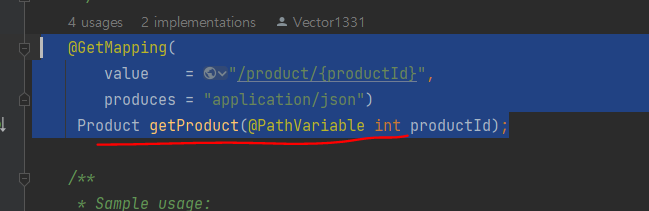
Mono 객체 반환하도록 변경
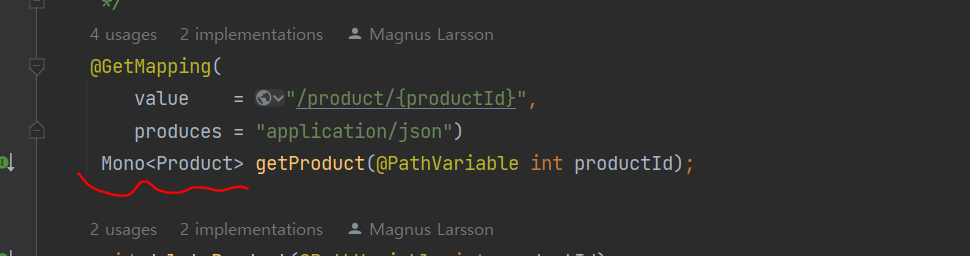
-
서비스 구현 변경 (ProductServiceImpl, RecommendaionServiceImpl)
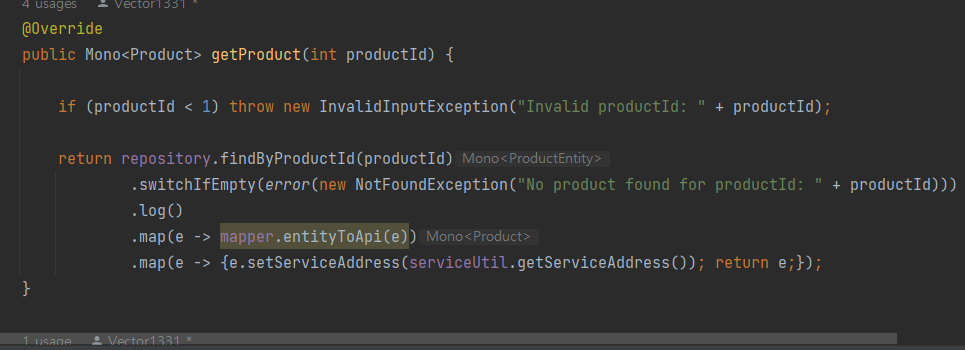
기존의 repository 에서 findByProductId를 통해서 가져와서 List< RecommendationEntity>로 저장했던 거에서
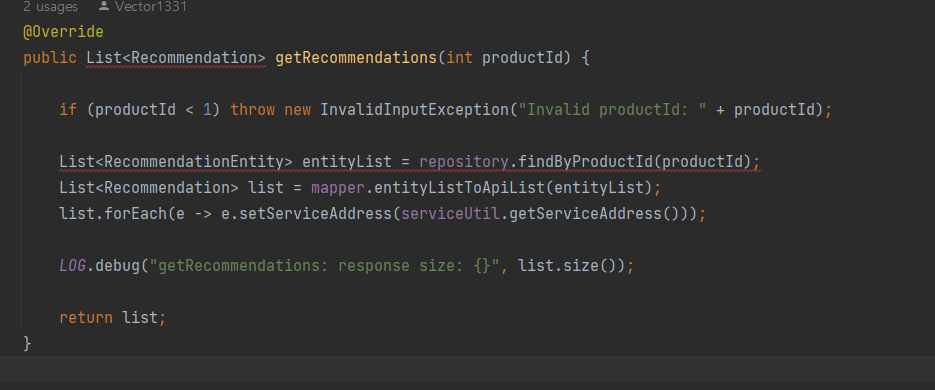
가져와서 log찍고
mapper.entityToApi() 메서드를 호출해 영속성 계층에서 가져온 엔티티를 API모델 객체로 변환 -> 모델 객체의 serviceAddress 필드에 요청을 처리한 마이크로서비스의 DNS 이름과 IP 주소를 설정하는 map 까지
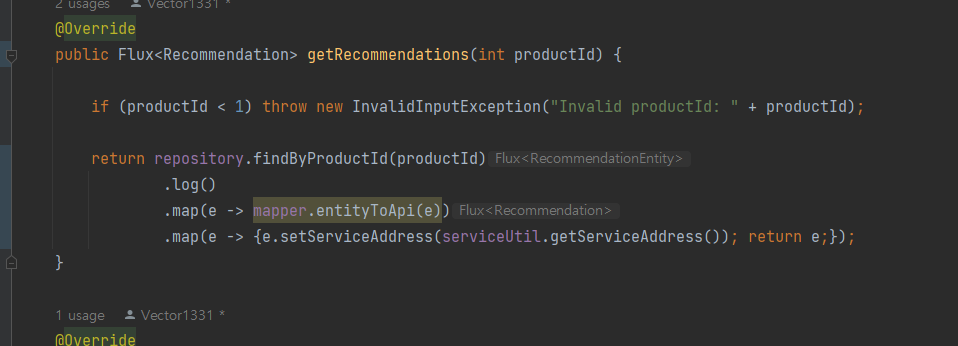
getProduct도 동일하다
-
테스트 코드 변경
비동기 동작을 처리하고자 Mono 및 Flux를 반환(리액티브 객체)하고, 테스트 코드 block() 메서드를 호출하거나 StepVerifier 헬퍼 클래스 사용
기존의
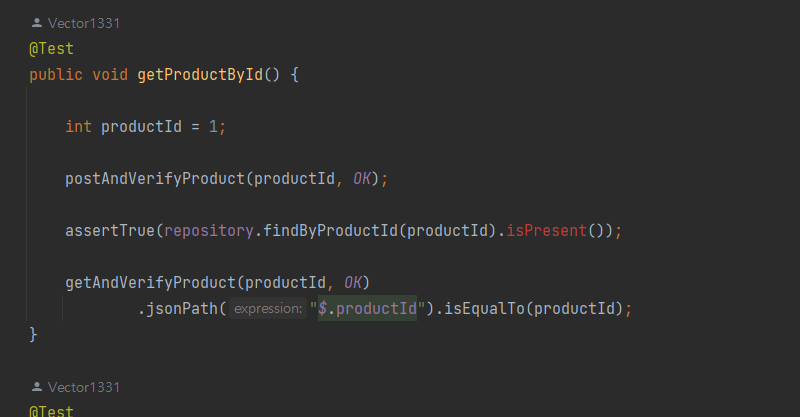
에서
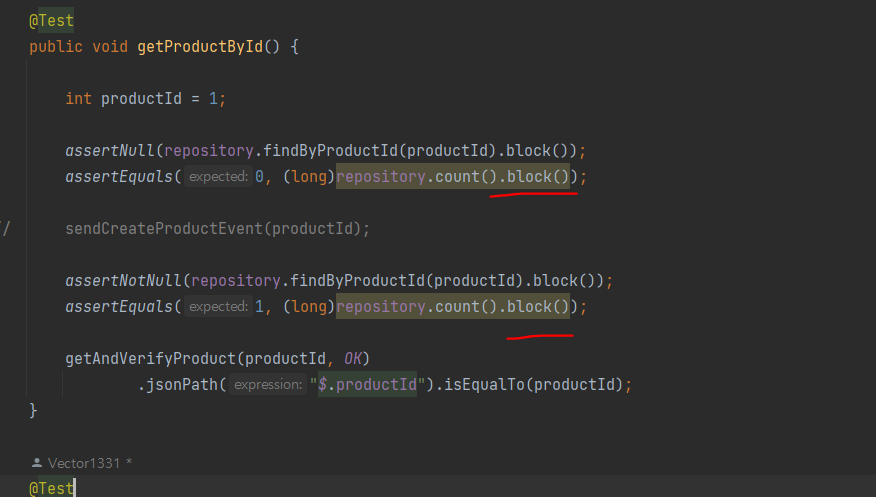
등으로 바꾸는건데
책에서는 너무 설명을 안해준다 ㅡㅡ
블로킹 코드 처리
jpa 이용하는 관계형 db에 접근한는 review는 논블로킹 프로그래밍 모델을 사용하지 않고 Scheduler를 사용해 블로킹 코드를 실행
스케줄러는 일정 수의 스레드를 보유한 전용 스레드 풀의 스레드에서 블로킹 코드를 실행 (마이크로서비스의 논블로킹 처리에 영향없음 b/c 스레드의 고갈을 방지하므로)
메인 클래스에 스레드 풀 구성
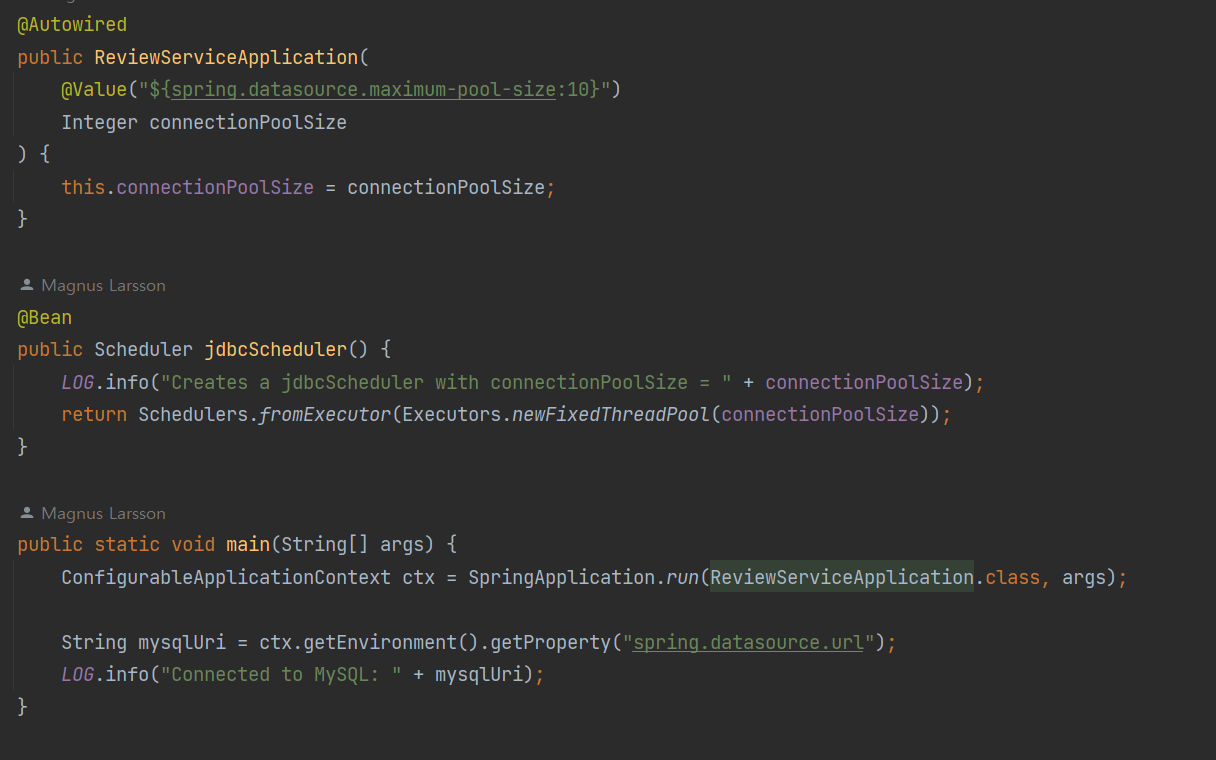
-> 서비스 구현 클래스에 scheduler 주입
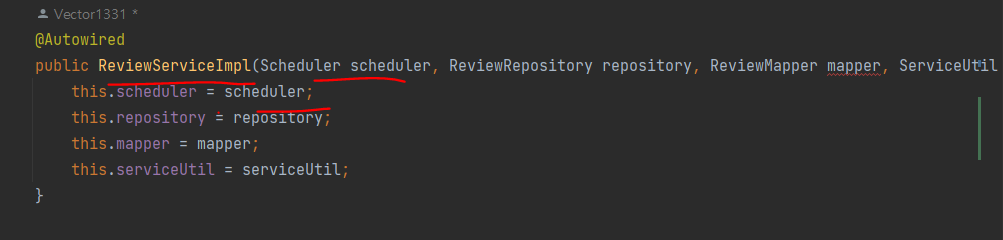
근데 책이랑 코드가 좀 다르다 뒤에 내용이랑 합쳐진건가..
암튼
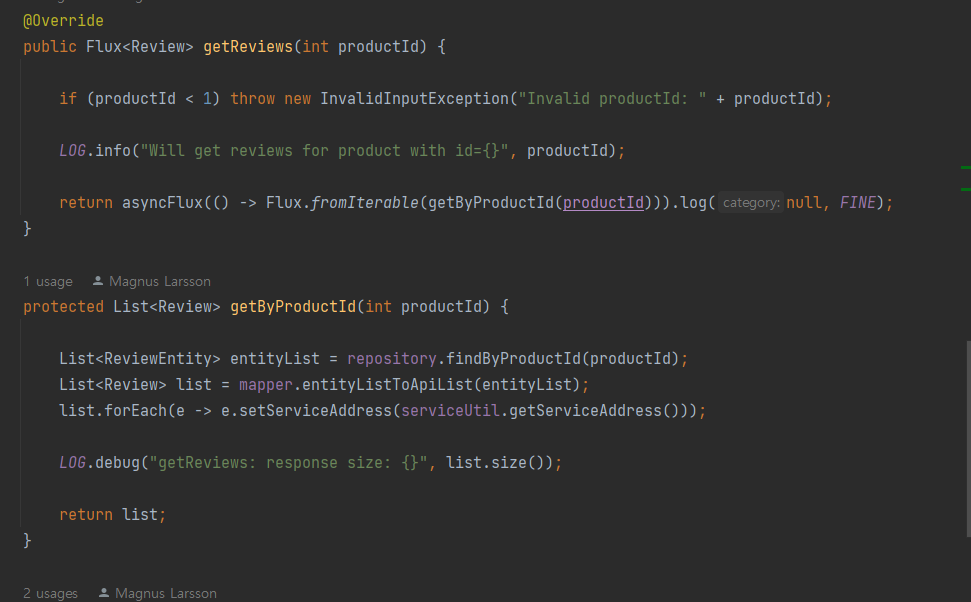
asyncFlux (getByProductId (productId)).log(); 로 getByProductId() 메서드에 블로킹 코드를 구현하고
getReviews() 메서드는 asyncFlux() 메서드를 사용해 스레드 풀의 스레드에서 블로킹 코드를 실행하게 된다.
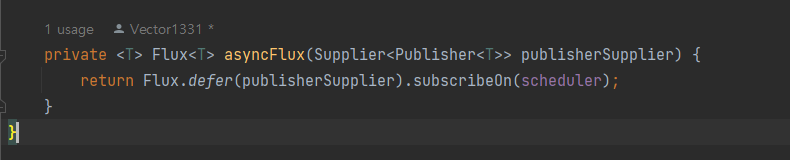
복합 서비스 -> 논블로킹 REST API 변경
- 리액티브 데이터 유형을 반환하도록 API를 변경한다.
- 논블로킹 http 클라이언트 사용가능하도록 통합계층 변경
- 병렬 및 논블로킹 방식으로 핵심 서비스 API를 호출하도록 서비스 구현 변경
- 리액티브 서비스를 테스트할 수 있도록 테스트를 변경
- api 변경 ProductAggregate로 반환하던 메서드의 반환 유형을
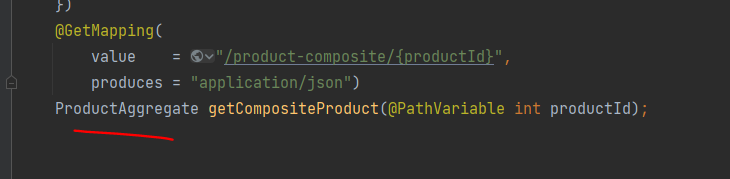
Mono< ProductAggregate >로 바궈야함
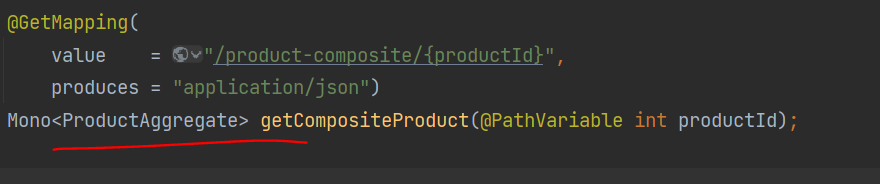
-
통합계층 변경
ProductCompositeIntegration 통합 클래스에서 사용하는 블로킹 방식 HTTP 클라이언트
인 RestTemplate 스프링 5에서 제공하는 논블로킹 방식 HTTP 클라이언트인 WebClient
로 대체한다.
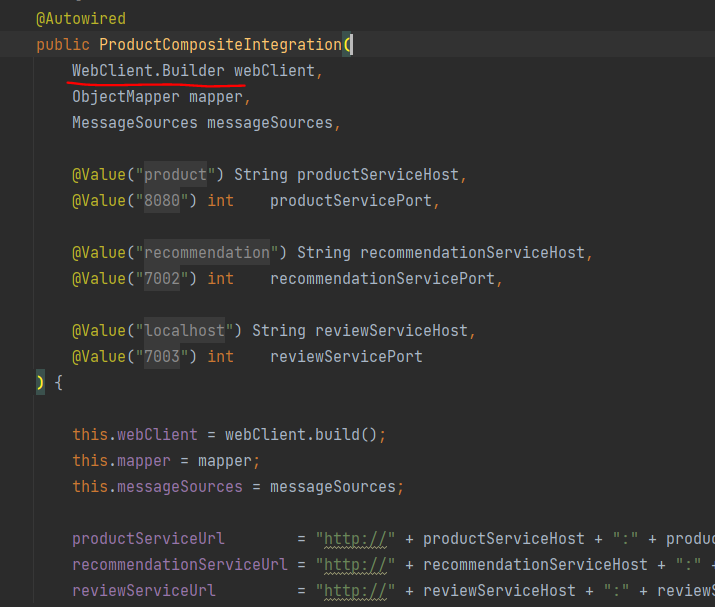
그리고 기존의
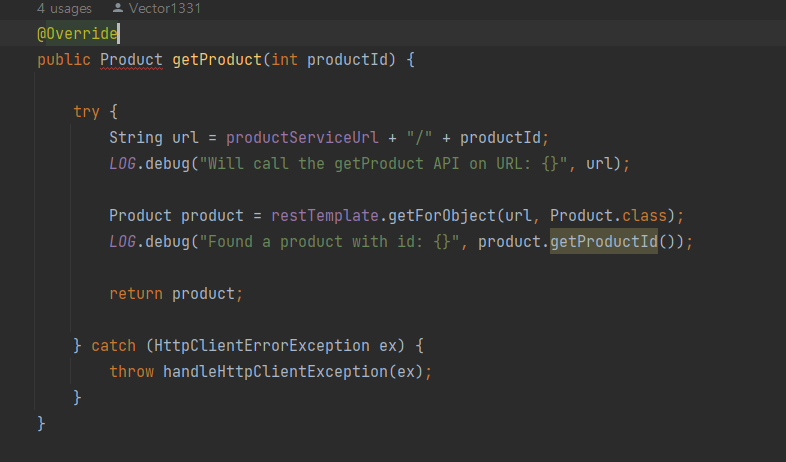
에서
-> webclient 인스턴스 사용한 논블로킹 방식으로 product 서비스 호출

-
서비스 구현 변경
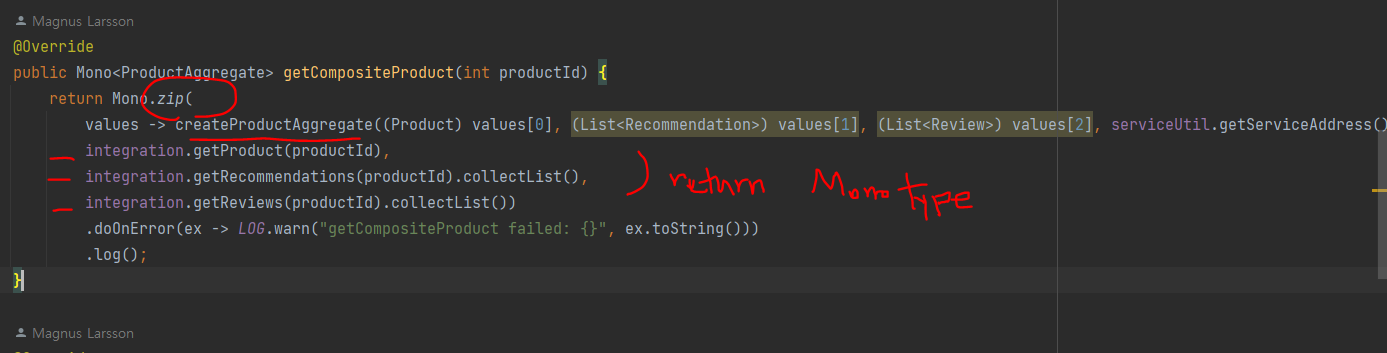
zip 메서드로 다수의 병렬 요청을 처리. 처리 완료 시 하나로 압축
createProductAggregate 헬퍼 메서드로 3개의 api 호출 결과를 집계
각각은 mono객체 반환 -
테스트 코드 변경
기존의 코드에서
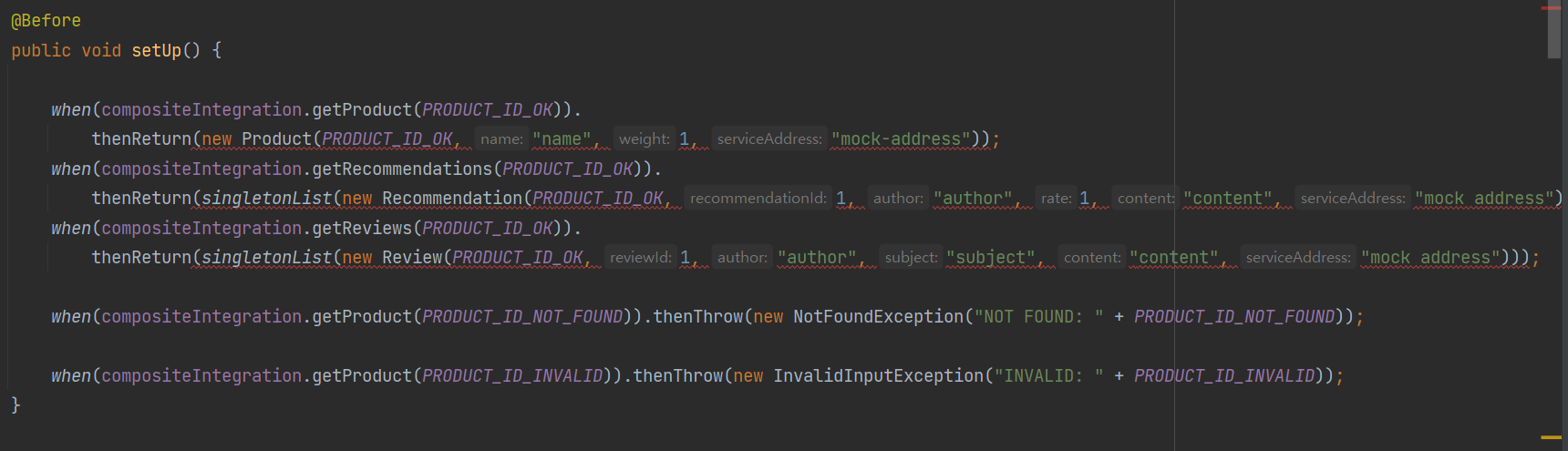
통합 클래스를 대체하는 모의 객체의 설정을 변경한다 (helper 메서드인 Mono.just() 메서드와 Flux.fromIterable() 메서드를 사용해 Mono 및 Flux 객체를 반환하도록)
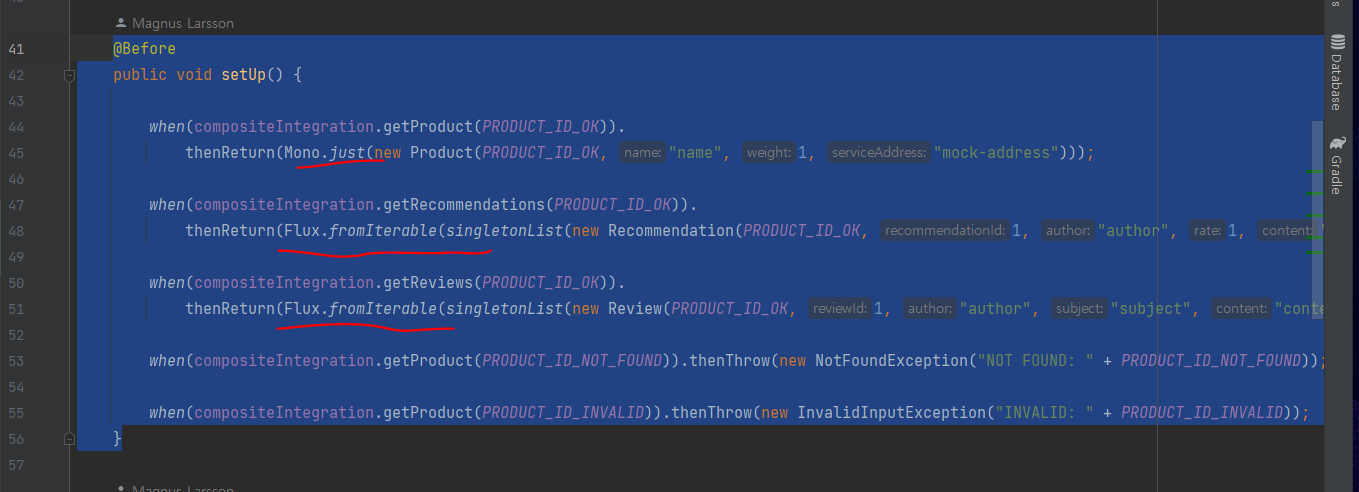
이벤트 기반 비동기 서비스 개발
이벤트 기반의 비동기 생성 서비스와 삭제 서비스를 개발
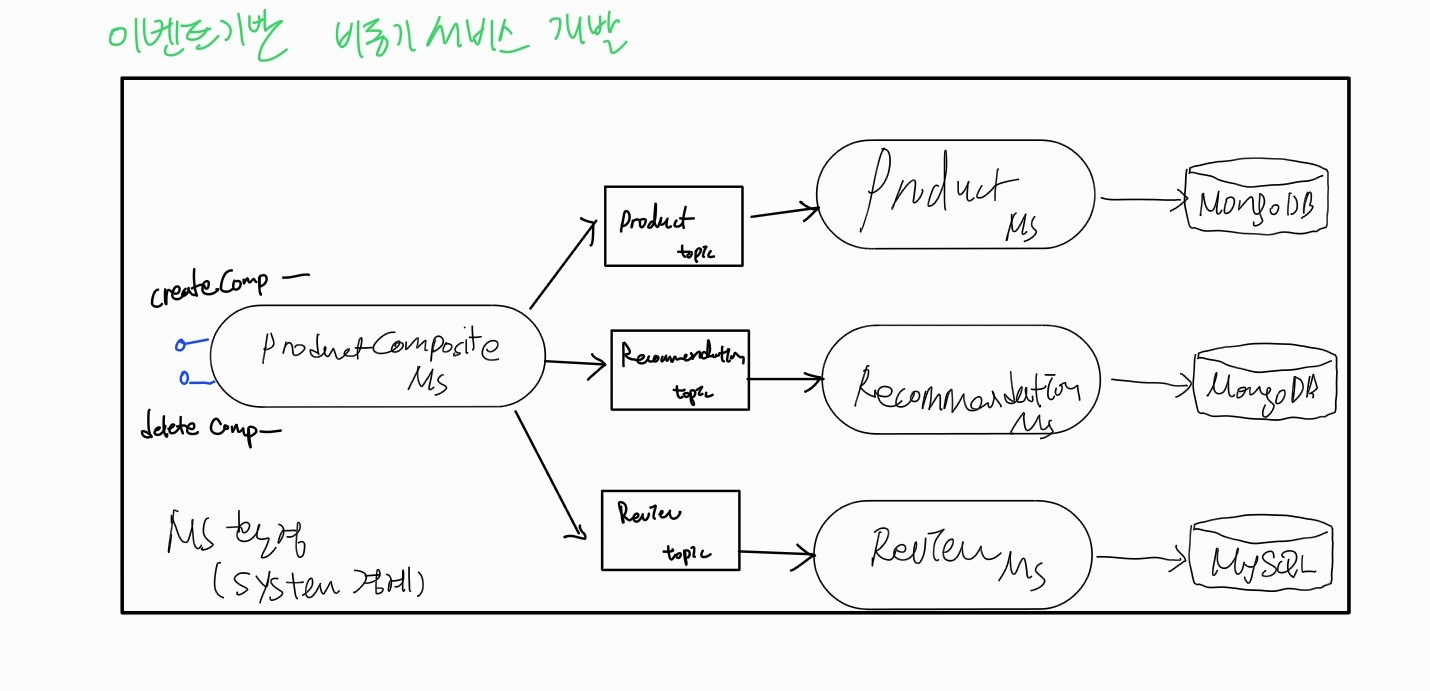
복합 서비스는 create / delete 이벤트를 각 핵심 서비스의 topic에 게시한 후 핵심 서비스의 처리를 기다리지 않고 호출자에게 OK 응답을 반환
- 메시징 관련 문제를 처리하도록 스프링 클라우드 스트림 구성
스프링 클라우드 스트림으로 이벤트 기반의 생성 및 삭제 서비스 구현
topic에 메시지 게시(publish) 하는 코드는
mysource.output().send(MessageBuilder.withPayload(message).build());
메시지 소비하는 코드
@StreamListener(target = Sink.INPUT)
public void receive(MyMessage message) {
LOG.info("Received: {}",message);
이 프로그래밍 모델은 rabbitMQ나 kafka같은 메시징 시스템 과 독립적으로 사용.
동기 API 호출보다는 비동기 메시지 방식이 갖는 문제가 있어서 스프링 클라우드 스트림으로 문제 처리 방법 알아본다.
문제1 소비자 그룹
문제 :소비자 인스턴스 수 늘리면 product 마이크로서비스의 모든 인스턴스가 같은 메시지를 소비한다
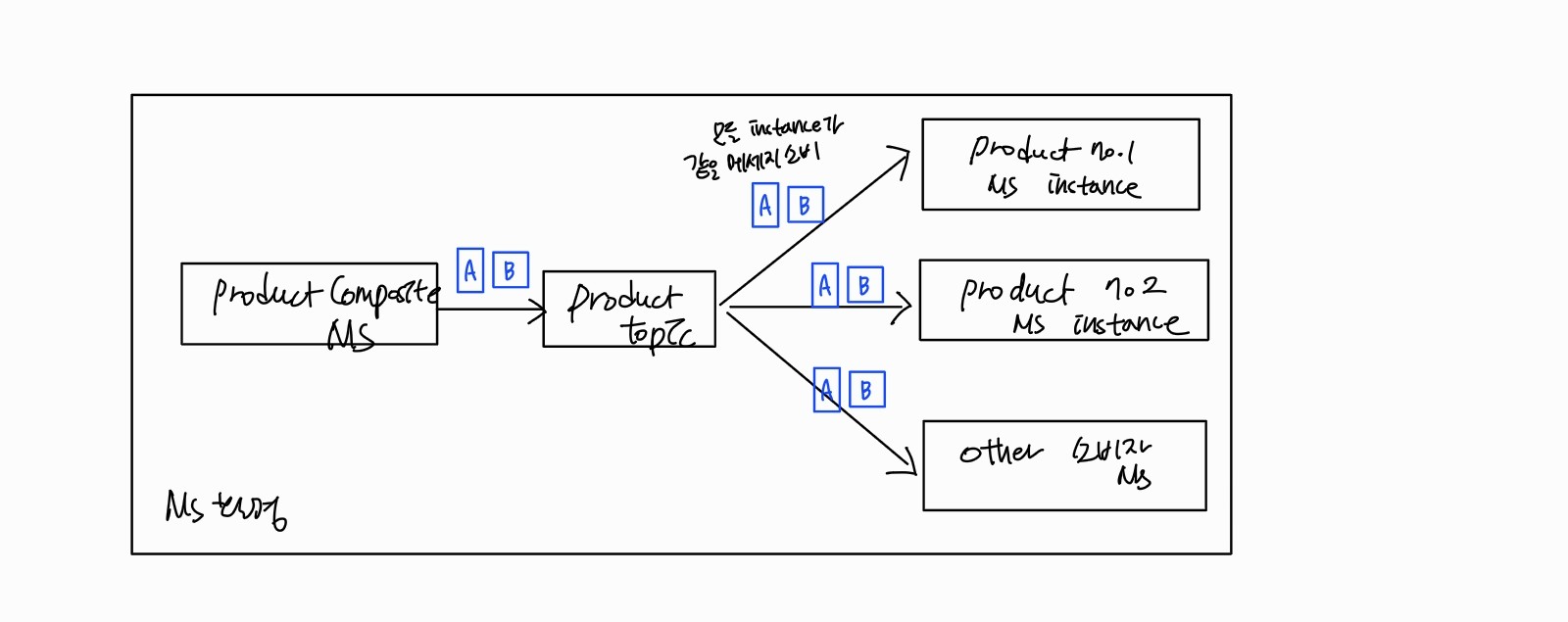
해결 : 소비자 유형별로 하나의 인스턴스가 메시지를 처리하게 한다
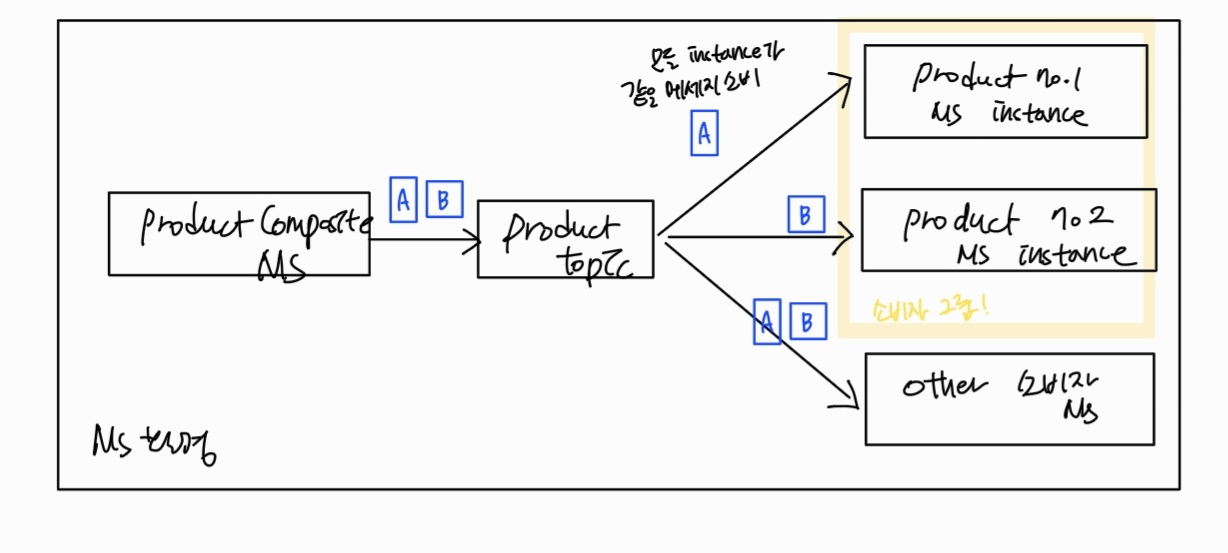
스프링 클라우드 스트림의 소비자 그룹은 소비자 쪽에서 구성
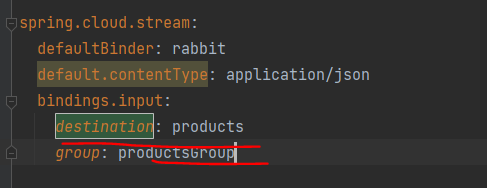
소비자 그룹은 group: 으로 묶는다 -> 스프링 클라우드 스트림은 product 마이크로서비스 인스턴스 중 한 인스턴스로만 product 토픽에 게시된 메시지를 전달
문제 2 재시도 및 데드 레터 대기열
문제 :
소비자가 메시지 처리 실패시 -> 메시지는 성공할때까지 대기열로 다시 보내지거나 사라짐
내용이 잘못된 메시지(=포이즌 메시지 poison message)인 경우 수동으로 메시지를 제거할 때까지 다른 메시지를 처리하지 못하도록 소비자를 차단
참고 :
- 일시적인 문제로 실패 한 경우(ex 네트워크 오류로 db에 연결할 수 없는 경우) 에는 여러 번의 재시도로 처리가 성공할수 있음
- 실패한 메시지는 보통 데드 레터 대기열이라는 전용 대기열로 이동.
- 일시적인 오류로 인프라 과부하를 피하려면 재시도 횟수를 정하고 재시도 간격을 넓히는 게 바람직
해결 : 결함 분석 및 수정을 위해 메시지를 다른 저장소로 이동하기 전에 수행할 재시도 횟수를 지정
문제 3 순서 보장 및 파티션
문제 : 비즈니스 로직에서 메시지가 전송된 순서대로 메시지를 소비하고 처리해야 하는 경우엔 소비자 그룹을 사용불가 (=여러 개의 소비자 인스턴스를 사용해 처리 성능을 높일 수 없음) --> 들어오는 메시지를 처리할 때 발생하는 지연 시간이 지나치게 길어질 수 있는 문제 존재
참고 : 파티션 == 하위ㅣ토픽
메시징 시스템이 같은 key를 가진 메시지 사이의 순서를 보장하고자 사용할 키를 각 메시지에 지정. -> 메시징 시스템은 키 기준으로 특정 파티션에 메시지 배치 (=같은 키 가지는 메시지는 always 같은 파티션에 배치)
->메시지 순서 보장을 위해 소비자 그룹 안의 각 파티션마다 하나의 소비자 인스턴스가 배정
파티션 수가 늘어나면 소비자 인스턴스를 추가해 전달 순서를 유지하면서 성능을 향상 가능
해결 : 파티션을 사용하면 성능과 확장성을 잃지 않으면서도 전송됐을 때의 순서 그대로 메시지 전달 가능
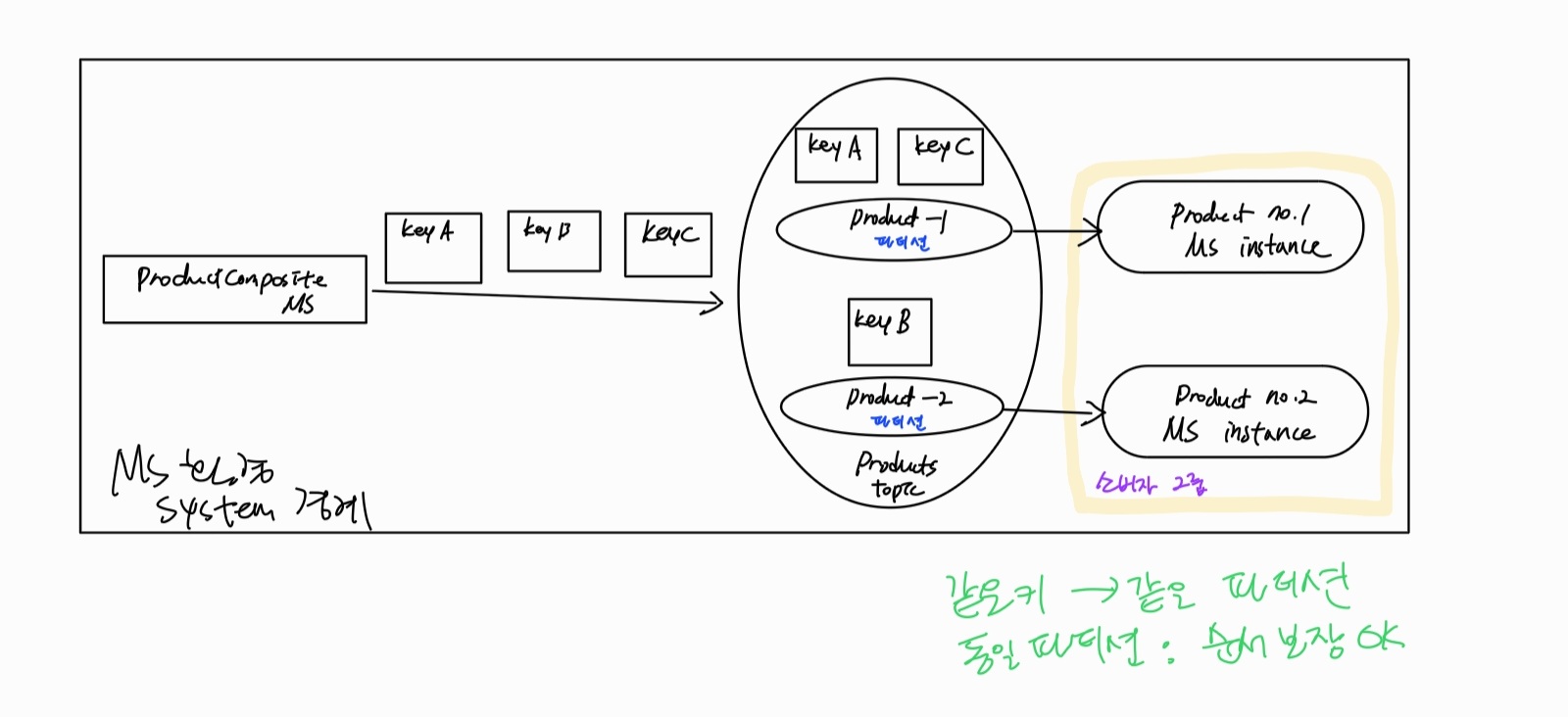
- 토픽 및 이벤트 정의
스프링 클라우드 스트림은 게시 및 구독 패턴을 기반
: publisher는 topic에 메시지 게시하고, subscriber는 관심있는 topic 구독해 메시지 수신
메시징 시스템은 보통 헤더와 본문으로 구성된 메시지를 다룸
event : 어떤 상황이 발생했다는 것을 설명하는 메시지
이벤트 메시지 본문 ⊂ 이벤트 유형 (type) , 이벤트 데이터 (data), 타임스탬프(이벤트 발생 시간)(timestamp), 데이터 식별을 위한 키(key)
- 그래들 빌드 파일 변경
스프링 클라우드 스트림과 RabbitMQ, Kafka 바인더를 사용하려면 spring-cloud-starter-stream-rabbit 및 spring-cloud-starter-stream-kafka 스타터 의존성과 테스트에 필요한 spring-cloud-stream-test-support 의존성을 추가필요
- 복합 서비스에서 이벤트 게시
-
메시지 소스를 선언하고 통합 계층에서 이벤트를 게시
이벤트를 다른 토픽에 게시하려면 토픽별 MessageChannel을 선언한 자바 인터페이스를 만들고, EnableBinding 애노테이션을 선언해 활성화해야 함
ProductCompositeIntegration에 메세지 채널 선언하고, 인스턴스를 생성자로 주입
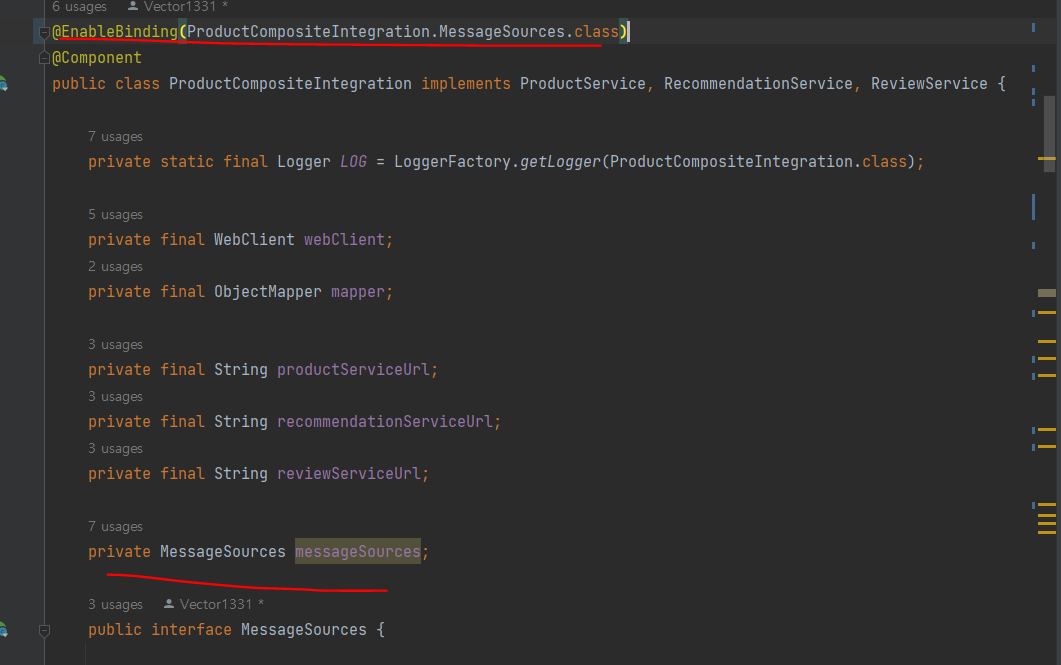
주입된 messageSources 객체로 이벤트 게시
ex) 제품 삭제 이벤트-> outputProducts() 메서드로 제품 토픽을 위한
messageChannel을 가져온 다음 send() 메서드로 이벤트를 게시
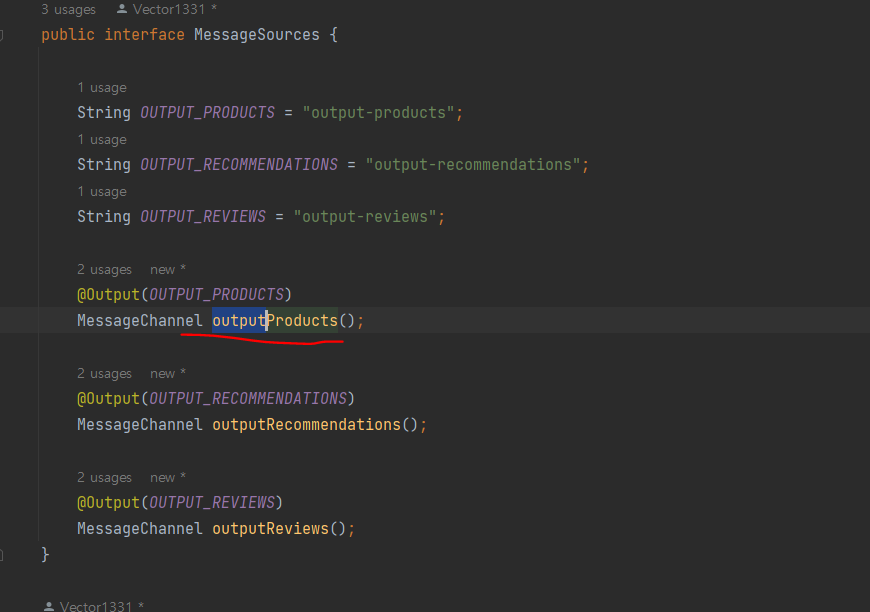
MessageBuilder 클래스를 사용해 이ㅣ벤트 담긴 메시지 작성

-
이벤트 게시를 위한 구성을 추가
기본 메시징 시스템 : rabbit mq
기본 컨텐츠 유형 : application/json
출력 채널과 토픽이름 bind (output)
rabbitMQ, kafka 연결정보 선언 -
이벤트 게시를 테스트할 수 있도록 테스트를 변경
스프링 클라우드 스트림이제공하는 TestSupportBinder를 사용하면 테스트 중에 메시징 시스템을 사용하지 않아도 어떤 메시지가 전송됐는지 확인가능
MessageCollector 헬퍼 클래스를 사용하면 테스트 중에 전송된 모든 메시지 가져올 수 있음
- 핵심 서비스에서 이벤트 소비
- 토픽의 이벤트 수신을 위해 message processor를 선언
product 와 recommendation, review 에 message processor를 선언
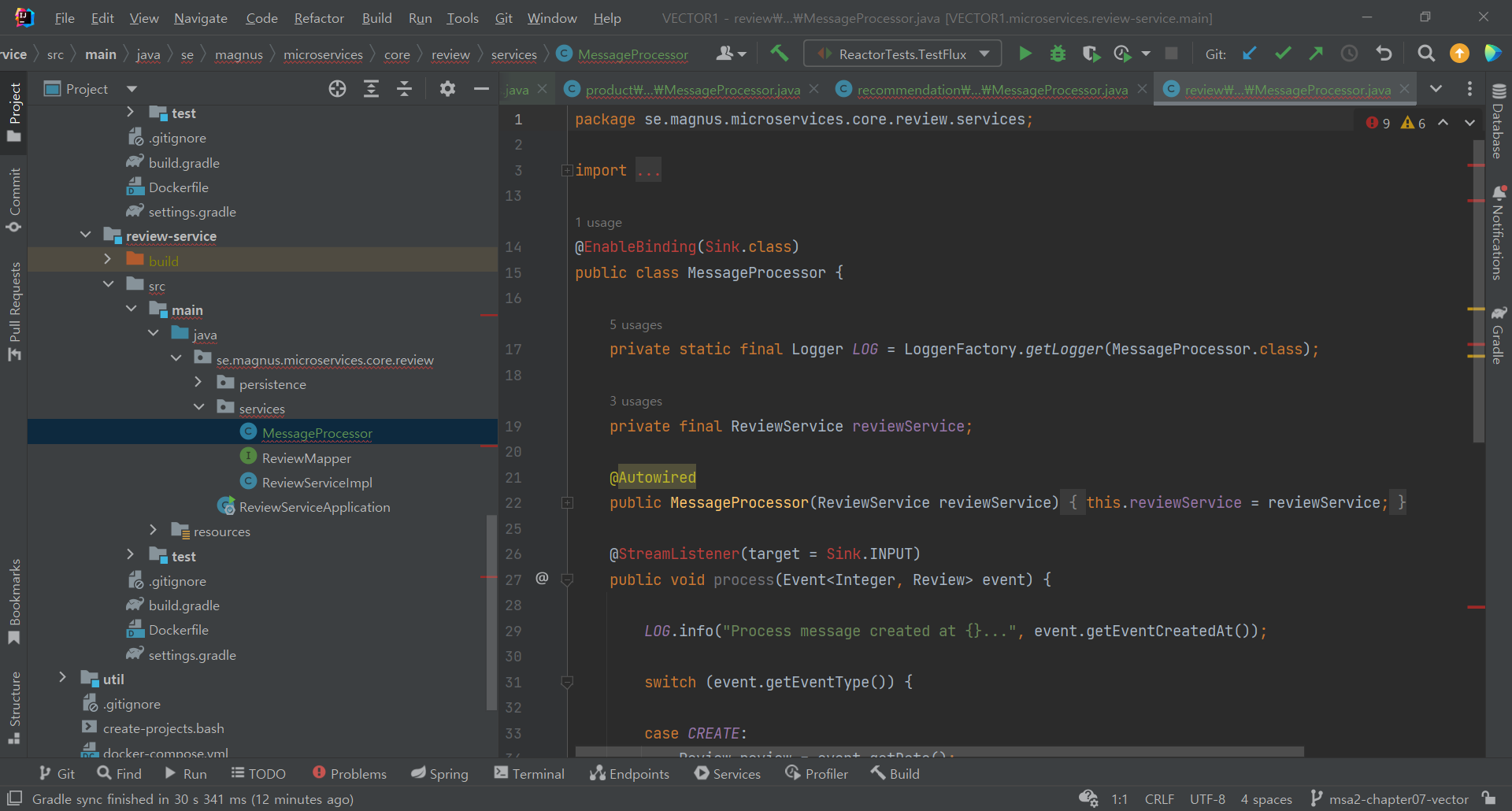
근데 아까 의존성 추가를 product-composite-service에만 하라고 되어있었는데 그러면 안되는가보다 -> 각각 프로젝트 build.gradle에 의존성 추가해줌
생성 이벤트가 발생하면 productservice.createProduct() 이, 삭제 이벤트 발생시 productService.deleteProduct() 메서드가 호출된다.
이벤트 유형이 CREATE나 DELETE 이벤트가 아니면 EventProcessingException
- 리액티브 영속성 계층을 올바르게 사용하도록 서비스 구현을 변경
MongoDB를 위한 논블로킹 리액티브 영속성 계층을 사용하도록 product 및 recommendation 서비스의 생성 및 삭제 메서드를 새로 작성
ProductServiceImpl과 RecommendationServiceImpl코드에서
메시지 프로세서는 블로킹 프로그래밍 모델을 기반으로 하므로 영속성 계층에서 받은 Mono 객체의 block() 메서드를 호출한 후에 메시지 프로세서로 결과를 반환해야 한다.
if ) block() 메서드를 호출하지 않으면 : 메시징 시스템이 서비스 구현에서 발생한 오류를 처리하지 못하므로 이벤트가 대기열로 다시 들어가지 못하고 데드 레터 대기열로 이동하게 되기 때문이다.
review 는 jpa 블로킹 방식이므로 변경X
-
이벤트 소비를 위한 구성을 추가
이전과 동일함 기본 메시징 시스템 rabbitmq, json이 기본 -
이벤트의 비동기 처리를 테스트할 수 있도록 테스트를 변경
create / delete이벤트를 수신하므로 (이전의)REST API를 호출하는 대신 이벤트를 보내게 해야 한다.
-- input 메서드 채널의 send() 메서드를 사용해 이벤트를 전송
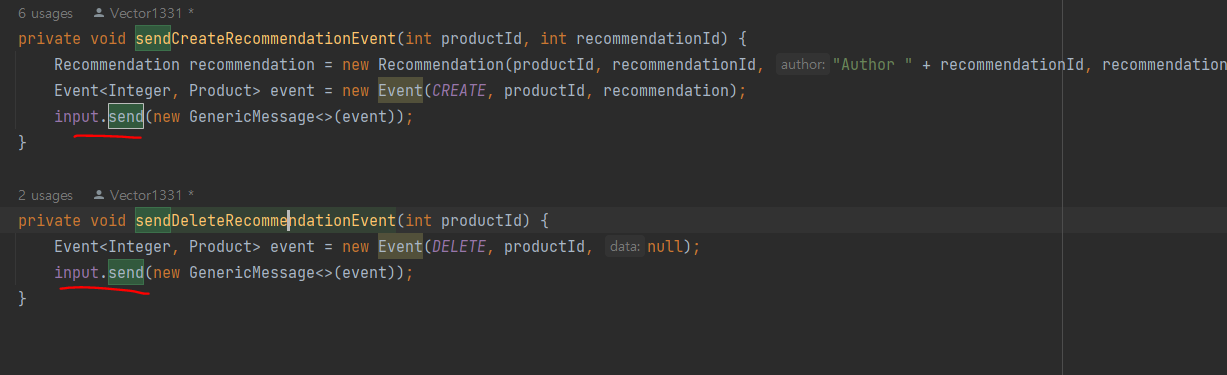
input 채널의 send() 메서드 호출 : 메시지 프로세서에 의한 동기 방식 처리
=== 메시지 프로세서의 process() 메서드를 직접 호출하는 것과 다를 바 없음
-> 테스트 코드가 이벤트를 비동기로 처리하고자 동기화 로직이나 wait Logic을 구현할 필요가 없음
리액티브 마이크로서비스 환경의 수동 테스트
docker compose 파일 3가지 구성으로 테스트
파티션 없이 RabbitMQ 사용
토픽당 2개의 파티션으로 RabbitMQ 사용
토픽당 2개의 파티션으로 카프카 사용
마이크로서비스 테스트 위해서 환경 단순화
- RabbitMQ를 사용하는 경우 추후 검사를 위해 이벤트 저장
products 토픽에 게시된 이벤트를 별도의 소비자 그룹인 auditGroup에 저장하도록 구성함 (product-composite)
- 마이크로서비스 환경의 상태를 모니터링하기 위한 상태 API 추가
동기 API와 비동기 메시징을 조합해 사용하는 마이크로서비스의 시스템 환경을 테스트 하는 것이 쉽지 않기 때문에 메시지를 처리할 준비가 됐는지 확인하기 위해서 모든 ms에 상태 점검 api 추가
--> 상태 점검 API는 스프링 부트 actuator 모듈에서 제공하는 상태 점검 endpoint 기반으로 작동 (Health)
product-composite 서비스의 health 엔드포인트는 product
composite 서비스 자신과 3가지 핵심 마이크로서비스 모두가 정상인 경우에만 UP으로 응답 (=http 200)
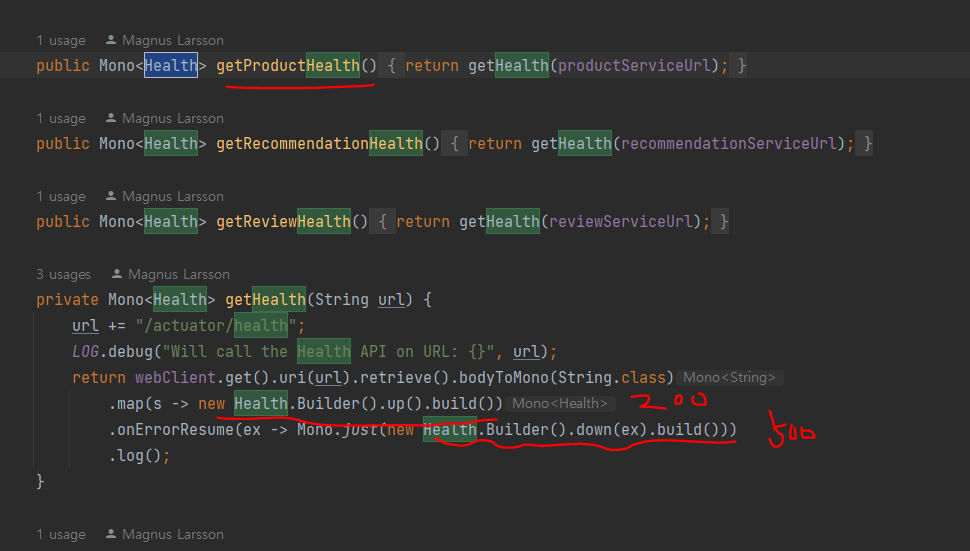
그리고 헬퍼 메서드를 사용해 세 가지 핵심 마이크로서비스의 상태 정보를 등록
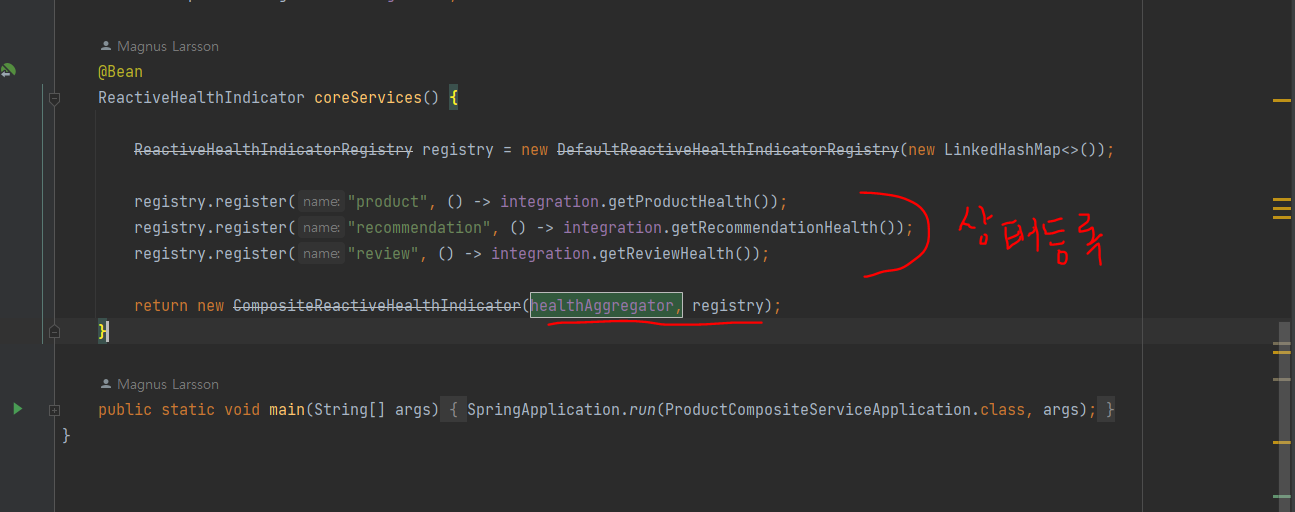
이제 curl 테스트 해봐야함
일단 빌드
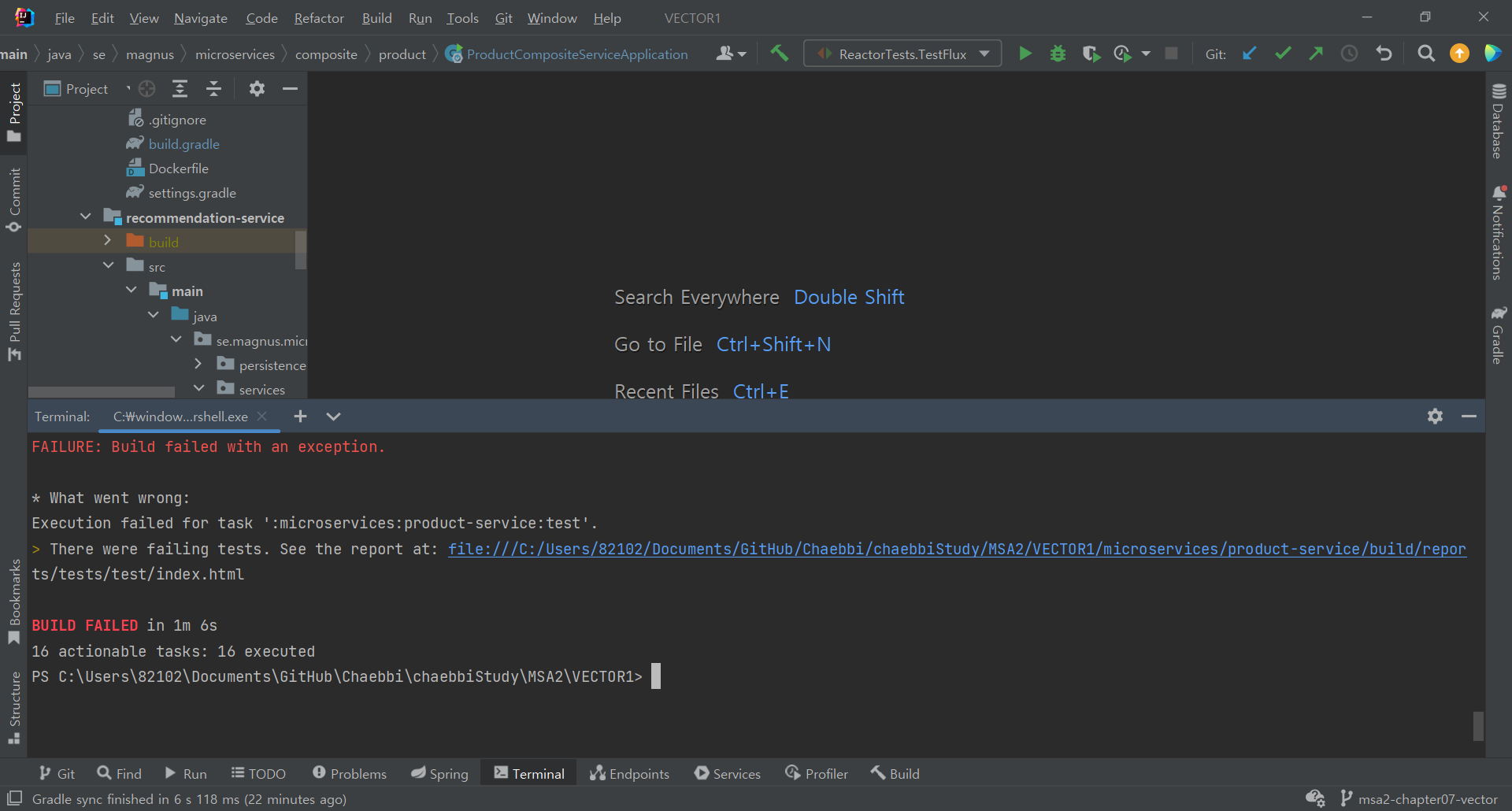
아하 역시 한방에 될리가 없쥬?
bean 이 없다고 하는 에러다
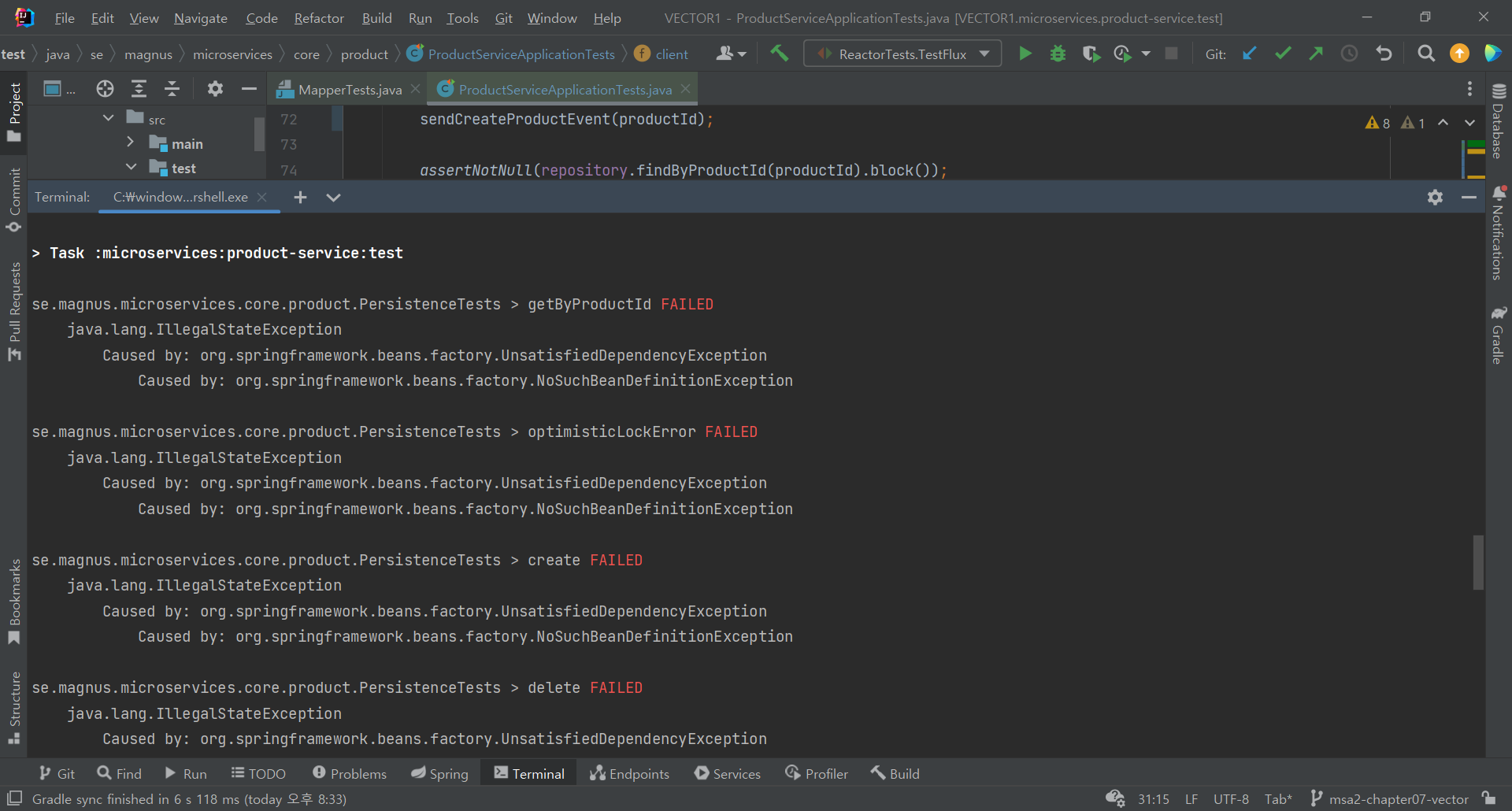
일단 기본코드랑 비교해보면
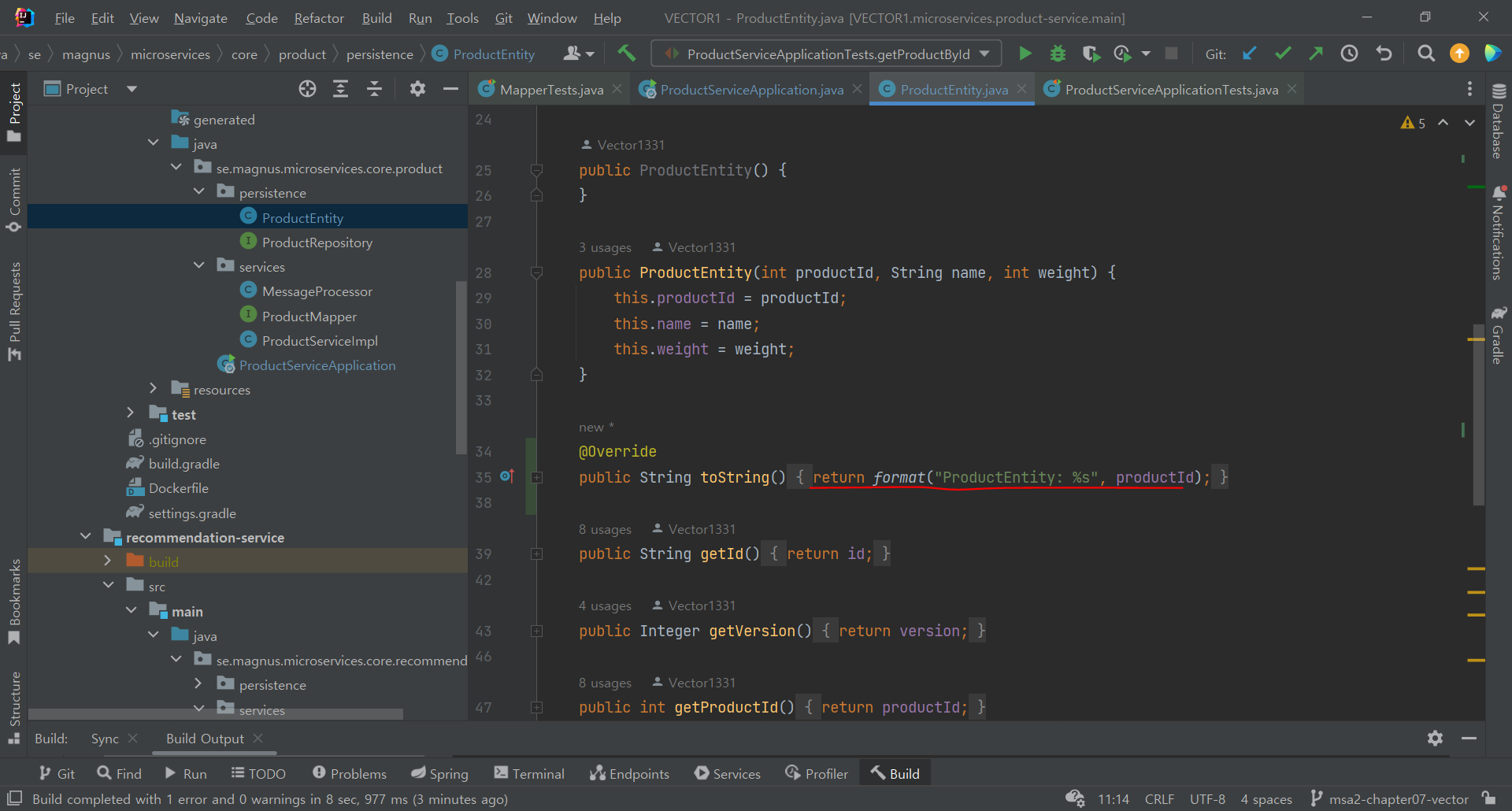
product의 persistence에 이부분이 없었고
메인 메소드 쪽에 template 가 안바뀌어있었다
이 후에 다시 build해보면
동일하게 recommendation도 같은 애러가 난다
product의 persistence에 이부분이 없었고
메인 메소드 쪽에 template 가 안바뀌어있던 부분 변경해줬음
*책내용 그대로 따라한다고 한거같은데 왜 안되어있엇지 🤯
암튼 빌드 성공
컨테이너 띄우고
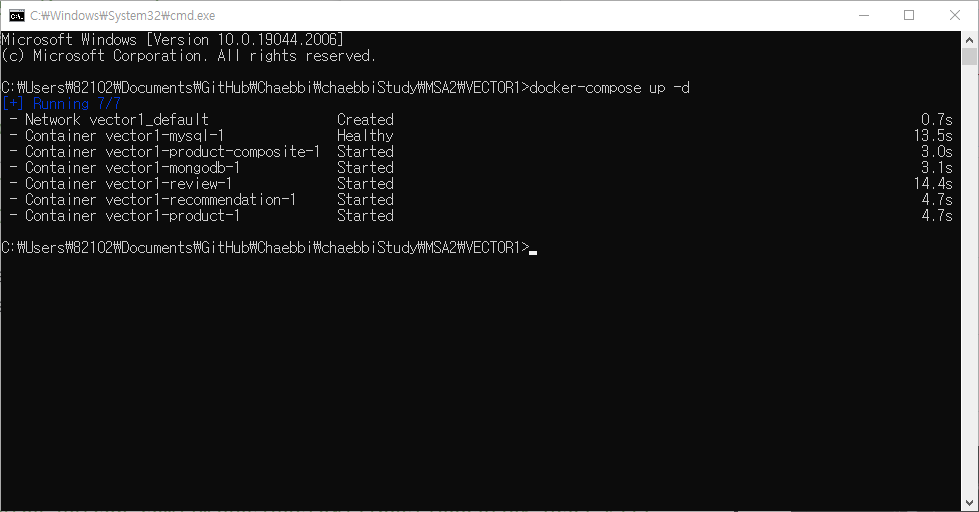
curl localhost:8080/actuator/health -s 를 해보면 up은 나오지만 책처럼은 안나온다
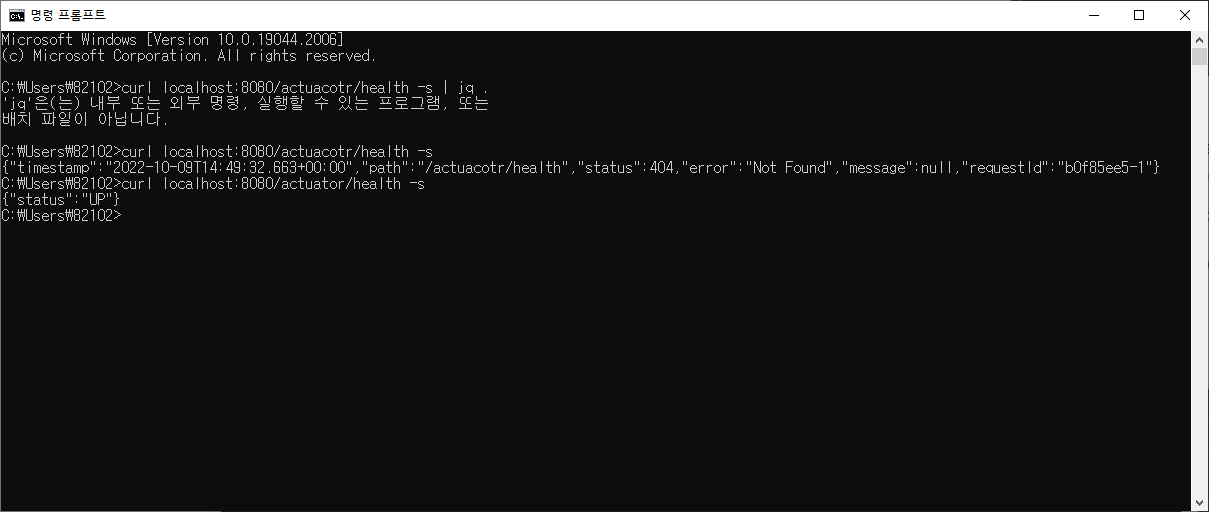
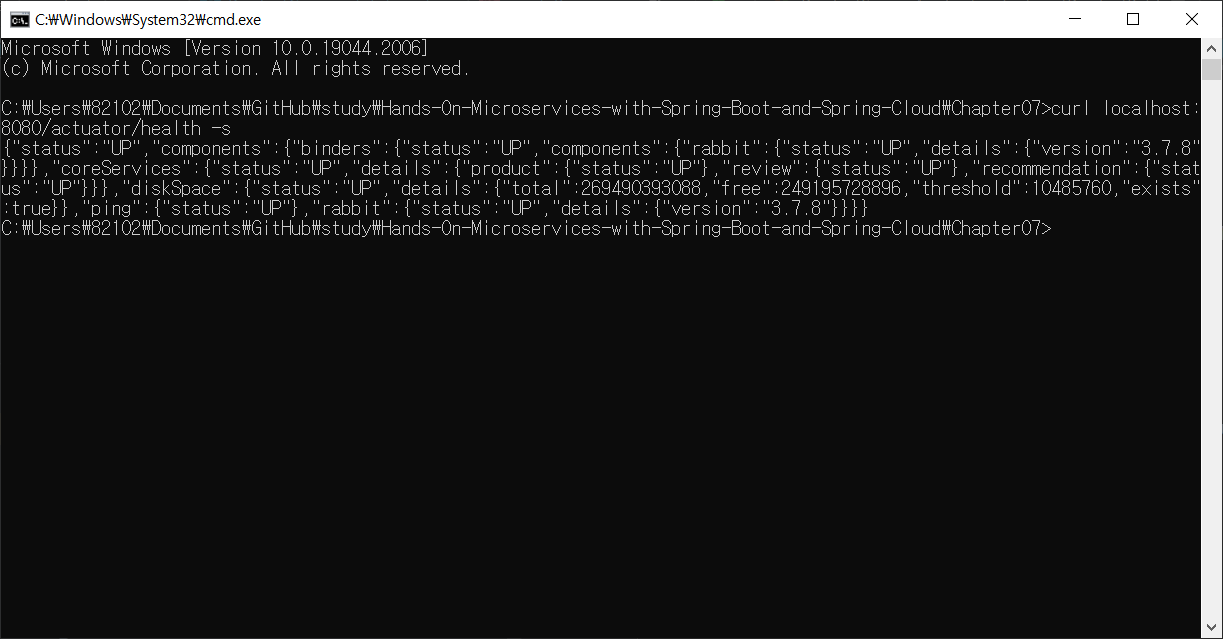
저자 코드를 이용해서 해보면 책처럼 나온다 🤔 무엇이 문젤까 🤔
했는데 에러가 나오길래
코드 차이를 분석해서 여러개 빠트린 것을 채워넣어서 해봤다
책 순서대로 따라한다고 했는데 중간에 정신을 놓았던 모양이다..
음. .
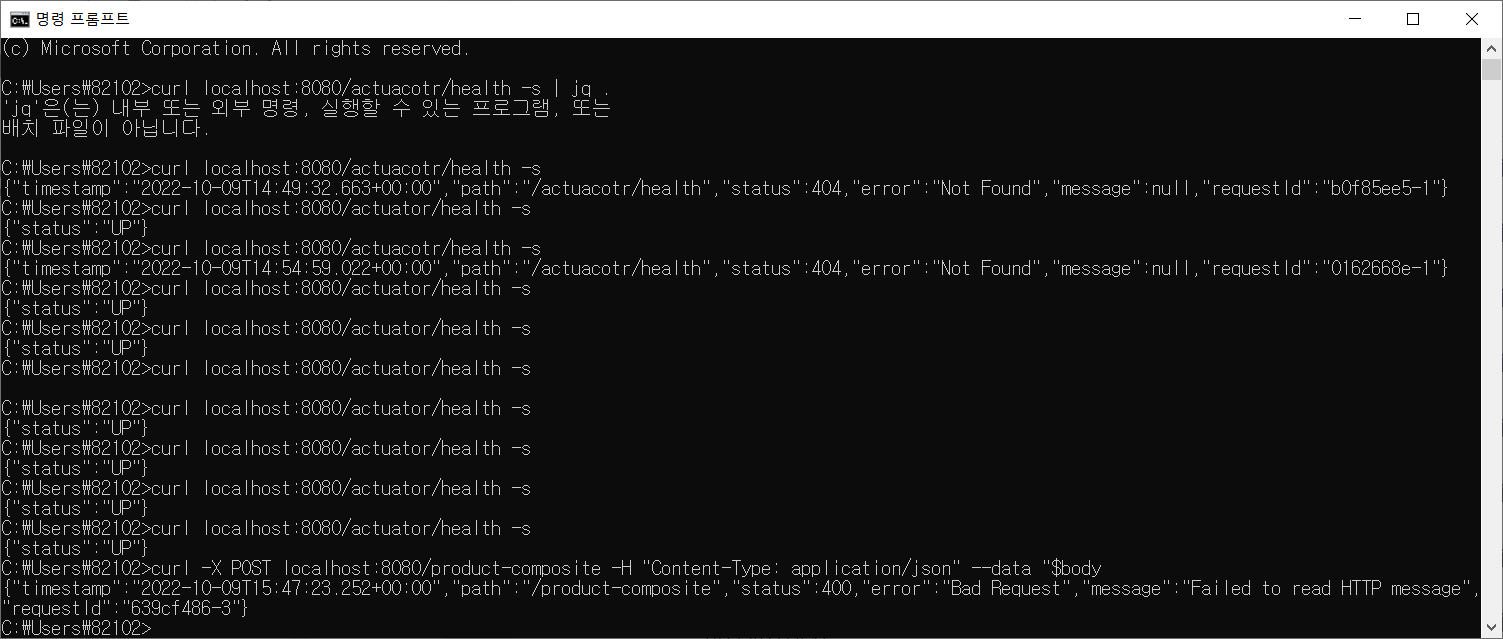
.....
일단 저자 코드로 하겟다. ..
참내...



body='{"productId":1,"name":"product name C","weight":300, "recommendations":[
{"recommendationId": 1, "author": "author 1","rate": 1, "content":"content 1"},
{"recommendationId":2,"author":"author 2","rate":2,"content":"content 2"},
{"recommendationId":3,"author":"author 3","rate":3,"content":"content 3"}
], "reviews":[
{"reviewId": 1, "author": "author 1", "subject":"subject 1","content":"content
1"},
{"reviewId":2,"author":"author 2","subject":"subject 2","content":"content
2"},
{"reviewId":3,"author":"author 3","subject":"subject 3","content":"content
3"}
]}'
curl -X POST localhost:8080/product-composite -H "Content-Type: application/
json" --data "$body"curl로 하려고 했는데 많은 양은안된다 -> postman으로한다
rabiitmq 페이지간다 -> 아이디 페스워드 guest , guest 로 로그인한다
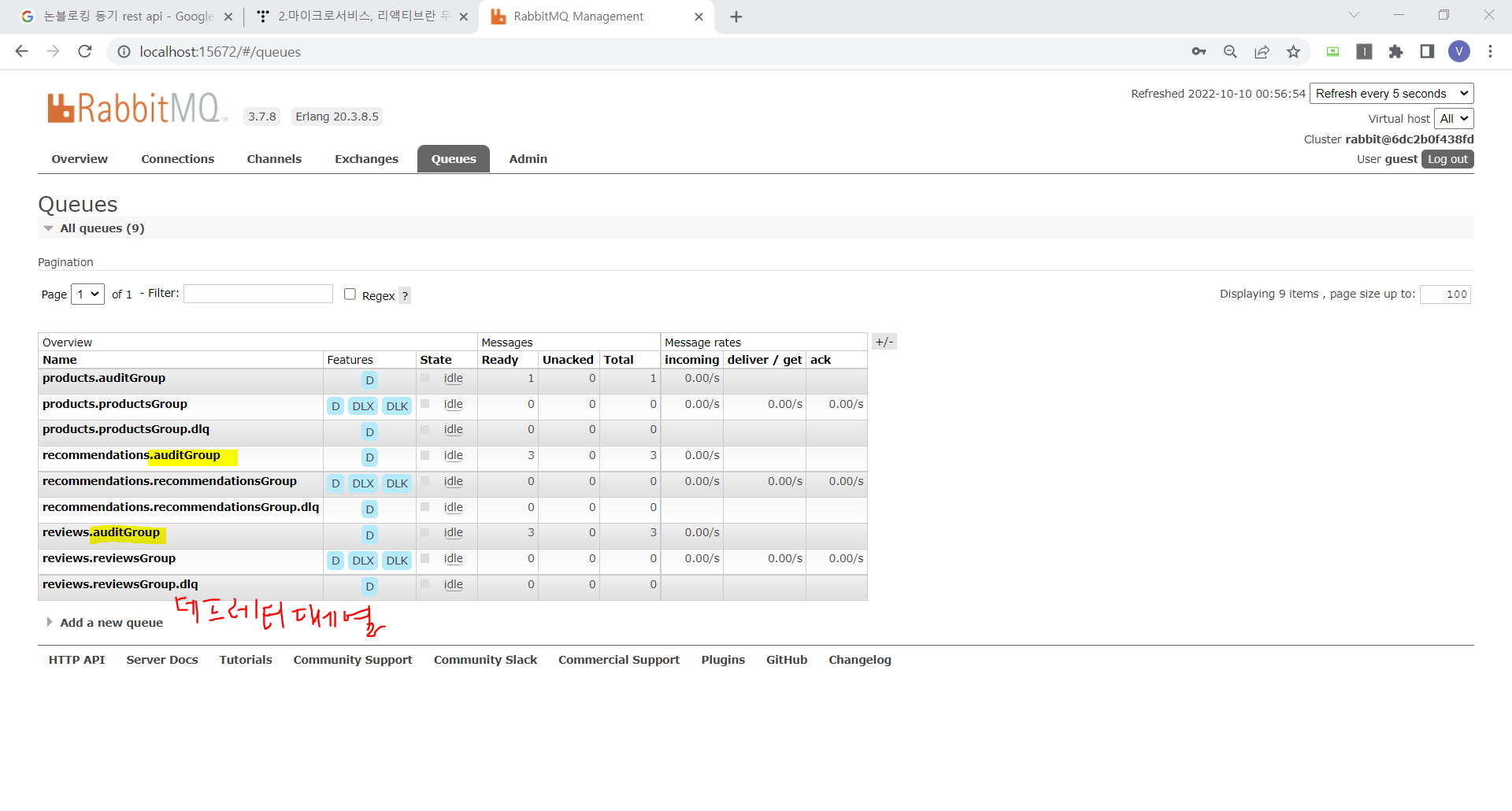
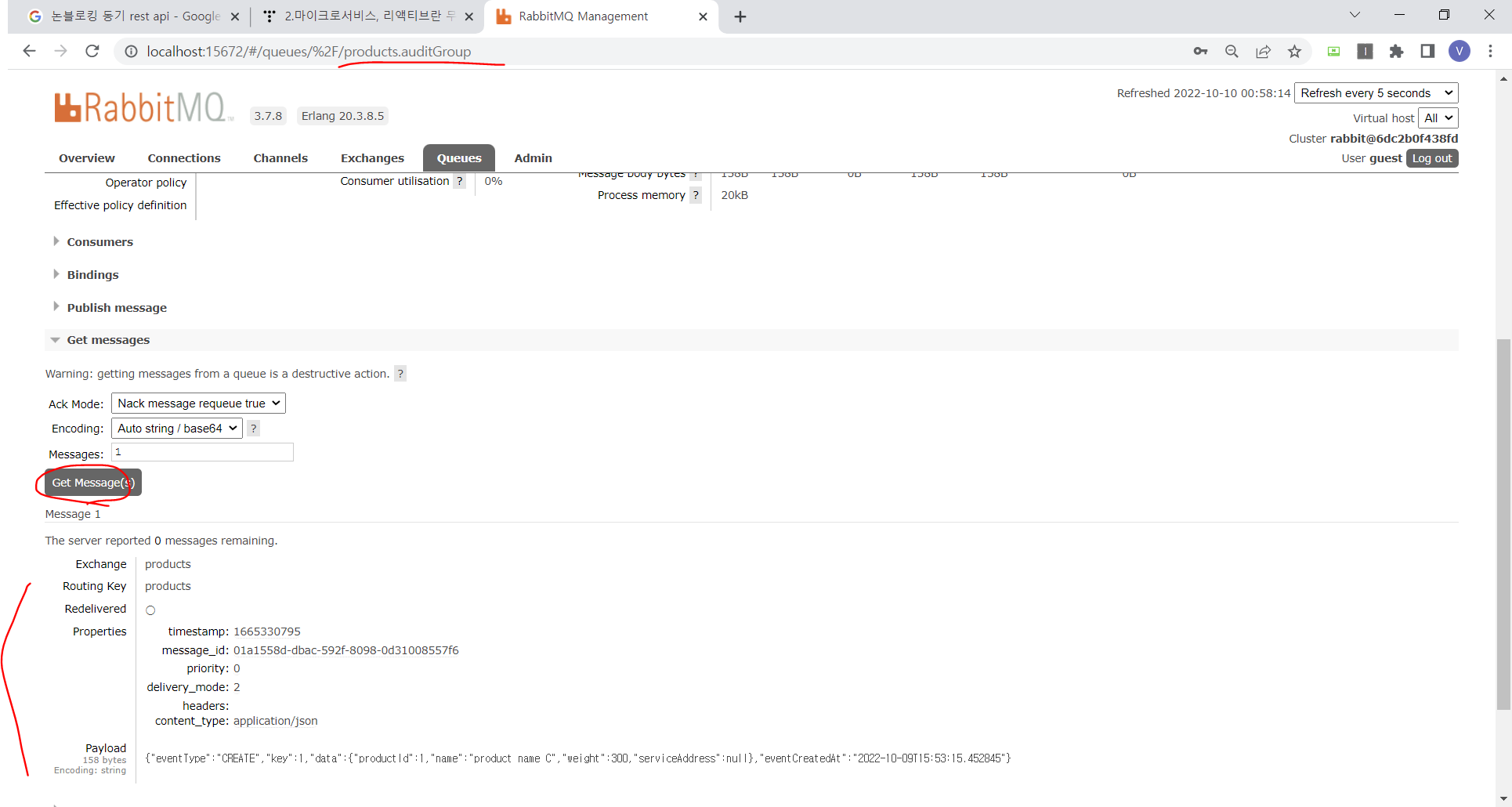
curl로도 조회

- 파티션으로 rabbitmq 와 카프카 사용
토픽당 2개의 파티션으로 RabbitMQ를 사용하고자 별도의 도커 컴포즈 파일 docker-compose-partitions.yml
-> 스프링 클라우드 스트림이 생성한 대기열은 파티션별로 대기열이 하나씩
정리 및 느낀점
이번 장에서는
스프링을 사용해 논블로킹 동기 REST API 및 비동기 이벤트 기반 서비스를 개발하는 방법으로 리액티브 마이크로서비스를 구현해봤다. 코드 에러는 많이 나지만..
논 블로킹 동기 api는 처리되어야 하는 한 작업이 전체적인 작업의 흐름을 막지않고 호출되는 함수의 작업 완료 여부를 신경쓰는 api이고 비동기 이벤트 기반은 이벤트가 발생함에 따라서 호출되는 함수의 작업 완료 여부와 상관없는 api인 것으로 이해했다.
스프링 webflux 및 스프링 webclient, spring data는 스프링 리액터를 사용해 리액티브및 논블로킹 기능을 제공한다.
스프링 데이터의 MongoDB 지원 기능(flux와 mono객체를 반환하게 만들고 repository 클래스를 ReactiveCrudRepository로 만드는 것)을 사용해서 데이터베이스 응답을 기다리는 동안 스레드를 차단하지 않는 논블로킹 방식으로 MongoDB 데이터베이스에 접속할 수 있다.
jpa를 이용하는 관계형 db (review 서비스 ) 는 Scheduler를 사용해 블로킹 코드를 실행했다.
스프링 데이터 스트림과 메시징 시스템인 RabbitMQ 및 카프카를 이용해 코드 변경
없이 이벤트 기반 비동기 서비스를 개발하는 방법을 살펴봤는데 이부분이 아마 코드 구현이 잘 안됐던것 같다. 그래도 배웠던 내용은 1소비자 그룹으로 문제를 해결하는법, 2재시도및 데드 레터 대기열, 3파티션로 문제해결하는 법을 통해서스프링 클라우드 스트림의 기능을 사용해 여러 가지 비동기 메시징 문제를 처리할 수 있다는것을 알았다.
리액티브 시스템은 메시지 기반의 비동기 통신을 토대로 유연성, 확장성, 탄력성을 확보하므로 장애에 강하고 유연성과 탄력성이 있기 때문에 적시에 반응할 수 있지만 이를 다 이용하기 위해서는 알아야할 것들이 많아서 적용의 스케일을 컨트롤 가능한 만큼만 하는 것이 좋겠다
