8장은 2부에서 다루는 것들을 대략적으로 소개하는 장
2부는 분산 시스템을 구축할 때 발생하는 문제를 관리하는 방법을 중점적으로 다룬다 (==스프링 클라우드를 사용한 마이크로서비스 구축)
그래서 8장은 스프링 클라우드 소개를 하고있다.
그 후의 장들은 이렇게 이뤄져있다.
• 9장: 넷플릭스 유레카와 리본을 사용한 서비스 검색
• 10장: 스프링 클라우드 게이트웨이를 에지 서버로 사용
• 11장: API 접근 보안
• 12장: 구성 중앙화
• 13장: Resilience4j를 사용한 탄력성 개선
• 14장: 분산 추적
spring cloud의 진화 (지원, 전환, 대체)
스프링 클라우드 1.0(2015년 3월 출시) 은 다음과 같은 넷플릭스 OSS 도구를 기반이다. (open source software)
1 Netflix Eureka : 검색 서버
2 Netflix Ribbon : 클라이언트 측 로드 밸런서
3 Netflix Zuul : 에지 서버
4 Netflix Hystrix : 서킷 브레이커
여기서나오는 netflix는 우리가 아는 netflix가 맞다
넷플릭스가 전 세계 사용자에게 고화질 동영상 서비스를 안정적으로 제공하는 이유는 운영시스템이 msa인것과 oss때문이다. 넷플릭스는 msa전환을 7년에 걸쳐 클라우드 환경으로 이전했고 이 과정에서 경험한 노하우와 문제해결법을 공유하기 위해 msa 전환기술을 오픈소스로 공개했다! 😮
참고 : https://www.samsungsds.com/kr/insights/msa_and_netflix.html

- 스프링 클라우드 1.0의 지원
OAuth 2.0으로 API를 보호하는 스프링 시큐리티와 컨피그 서버와의 통합을 지원 - 스프링 클라우드 브릭스턴(Spring Cloud Brixton )릴리스(v1.1)의 지원
스프링 클라우드 슬루스(Spring Cloud Sleuth)와 트위터에서 만든 집킨(Zipkin)을 활용한 분산 추적을 지원 - 추가 지원
아파치 주키퍼 기반의 서비스 검색 및 구성 중앙화 지원
스프링 클라우드 스트림을 사용한 이벤트 기반 마이크로서비스지원
Microsoft Azure, Amazon AWS, GCP(Google Cloud Platform) 지원
그리고 2019년 스프링 클라우드 그리니치 v2.1 출시하면서 위의 넷플릭스 oss 도구 중 일부를 유지보수 모드로 전환했음
| 현재 컴포넌트 -> 대체 컴포넌트 |
|---|
| 넷플릭스 히스트릭스 -> Resilience4j |
| 넷플릭스 히스트릭스 대시보드/넷플릭스 터빈(NetflixTurbine) -> 마이크로미터(Micrometer) 및 모니터링 시스템 |
| 넷플릭스 리본 -> 스프링 클라우드 로드 밸런서 |
| 넷플릭스 주울 -> 스프링 클라우드 게이트웨이 |
그리고 이 책에서는 스프링 클라우드의 대체 컴포넌트를 사용해 서비스 검색 , 에지 서버 ,구성 중앙화, 서킷 브레이커, 분산 추적 디자인 패턴을 구현한다
| 디자인패턴 | 소프트웨어 컴포넌트 |
|---|---|
| 9장 서비스 검색 | 넷플릭스 유레카 및 스프링 클라우드 로드 밸런서 |
| 10장, 11장 에지 서버 | 스프링 클라우드 게이트웨이 및 스프링 시큐리티 OAuth |
| 12장 구성 중앙화 | 스프링 클라우드 컨피그 서버 |
| 13장 서킷 브레이커 | Resilience4j |
| 14장 분산 추적 | 스프링 클라우드 슬루스 및 집킨 |
넷플릭스 유레카를 검색 서비스로 사용
검색 서비스는 상용화 준비가 완료된 공조 마이크로서비스 환경 구축에 필수인 가장 중요한 지원 기능.
9장 : 스프링 클라우드 로드밸런서 +넷플릭스 유레카 사용할 예정이다.
넷플릭스 유레카에 마이크로서비스를 등록하고(스프링 클라우드를 사용), -> 클라이언트가 넷플릭스 유레카에 등록된 인스턴스로 전송하는 방법 살펴봄 -> 마이크로서비스의 인스턴스를 늘리는 방법 -> 서비스에 대한 요청을 사용 가능한 인스턴스에 맞춰 로드 밸런싱하는 법
스프링 클라우드 게이트웨이를 에지 서버로 사용
사설 서비스를 외부에서 접근하지 못하도록 숨기고 외부 클라이언트가 공개 서비스를 사용할 때 보호 == 마이크로서비스 환경을 보호하고자 에지 서버를 사용
스프링 클라우드 그리니치가 출시된 이후로는 넷플릭스 주울에서 URL 경로 기반 라우팅과 OAuth2.0, OIDC(OpenID Connect)에 기반한 엔드포인트 보호 등을 지원하는
"스프링 클라우드 gateway"로 대체하는 것을 권장.
- 넷플릭스 주울 v1과 스프링 클라우드 게이트웨이의 차이점
스프링 클라우드 게이트웨이는 넷플릭스 주울 v1에 비해 더 많은 양의 동시 요청을 처리할 수있다. (에지서버는 외부 트래픽 처리하므로 중요)
cf) 넷플릭스 주울 v1 : 블로킹 API를 사용
스프링 클라우드 게이트웨이: 스프링 5와 프로젝트 리액터, 스프링 부트 2 기반의 논블로킹 API를 사용
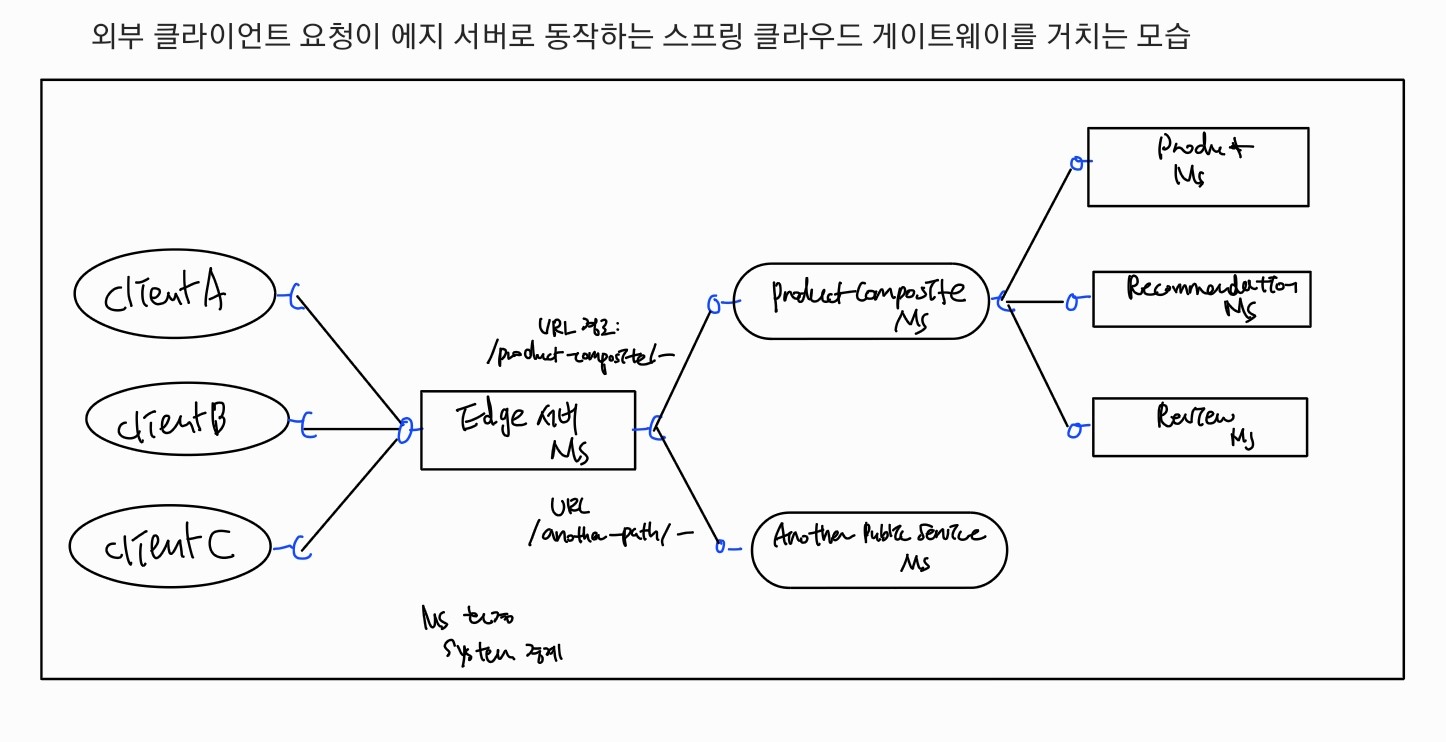
그림을 보면 외부 클라이언트 요청이 에지 서버로 동작하는 스프링 클라우드 게이
트웨이를 거쳐 URL 경로에 해당하는 마이크로서비스로 라우팅된다.
에지서버가 외부요청을 Product Composite 마이크로서비스로 보내기 때문에 핵심 서비스인 product, recommendation, review에 접근 X
구성 중앙화를 위해 스프링 클라우드 컨피그 사용
스프링 클라우드 컨피그는 마이크로서비스 환경의 구성 정보를 중앙집중식으로 관리함
- 구성파일 저장 가능한 저장소
깃 저장소(예: 깃허브, 비트버킷Bitbucket), 로컬 파일 시스템, 하시코프 볼트, JDBC 데이터베이스
스프링 클라우드 컨피그를 사용하면 계층 구조로 구성을 관리가능
스프링 클라우드 컨피그는 구성 변경을 감지+ Spring Cloud Bus를 사용해 영향받는 마이크로서비스로 (스프링 클라우드 스트림을 바탕으로 RabbitMQ 및 카프카 메시징 시스템 사용해) 알림을 보내는 기능도 지원한다.
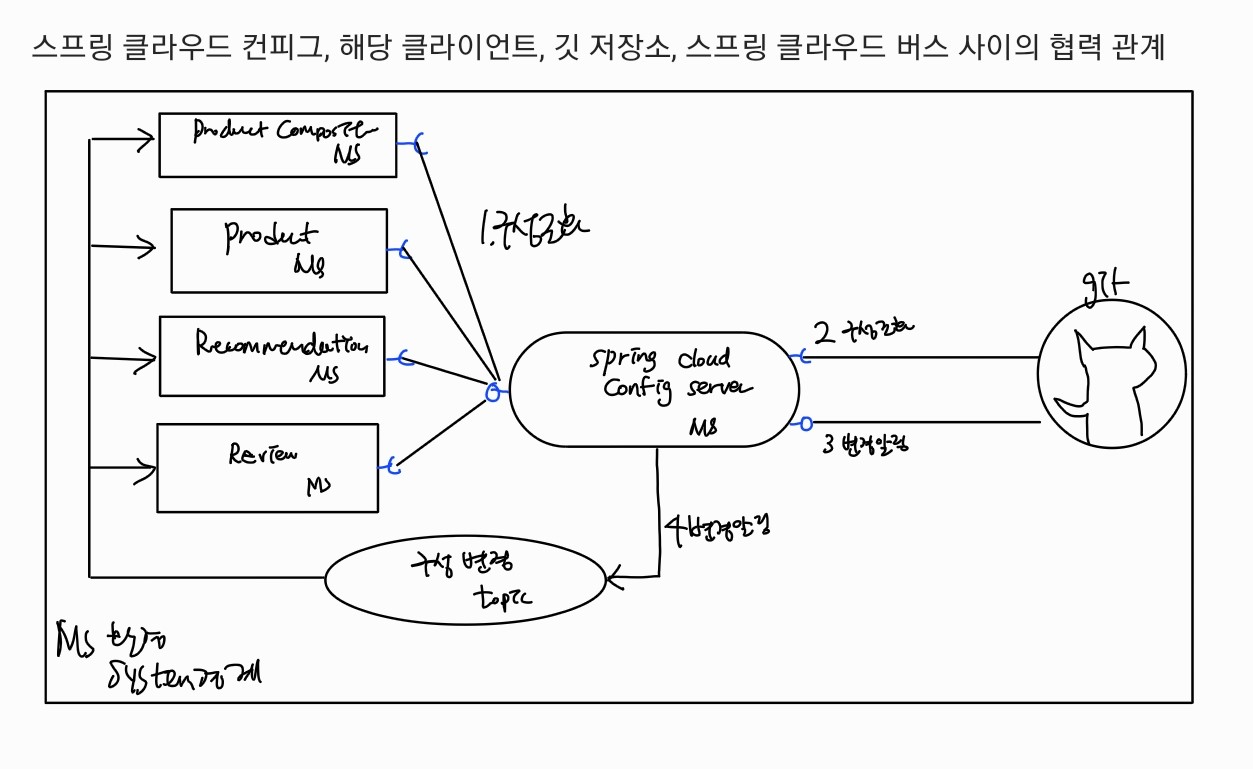
그림 순서를 보면
마이크로서비스가 컨피그 서버에 구성을 요청 -> 컨피그 서버가 git에서 구성을 가져옴 -> (선택)git에 commit이 push 되면 컨피그 서버에 알림을 보내도록 깃 저장소를 구성 -> 컨피그 서버는 스프링 클라우드 버스를 사용해 변경 이벤트를 게시+ 변경에 영향받는 마이크로서비스는 이에 반응해 컨피그 서버에서 업데이트된 구성을 받음
탄력성 향상을 위해 Resilience4j 사용
대규모의 공조마이크로서비스 시스템 환경에선 장애 발생 가능성이 당연하다고 간주해야함 -> 장애 처리 가능하도록 시스템 환경 설계 필요
- Resilience4j의 내장 내결함성 메커니즘
- 서킷 브레이커: 원격 서비스가 응답하지 않을 경우에 발생하는 연쇄 장애를 방지
하고자 사용
- 비율 제한기rate limiter : 지정한 시간 동안의 서비스 요청 수를 제한
- 격벽(bulkhead): 서비스에 대한 동시 요청 수를 제한
- 재시도
- timeout
스프링 클라우드 슬루스와 집킨을 사용한 분산 추적
for)) 분산 시스템에서 발생하는 상황을 파악
시스템 환경에 대한 외부 호출을 처리하는 과정에서 마이크로서비스 사이를 오가는 요청 및 메시지의 흐름을 추적하고 시각화필요
스프링 클라우드 슬루스는 상관 ID를 사용해 하나의 처리 흐름에 포함된 요청과 메시지/이벤트에 표시를 남김 + 로그 메시지에 상관 ID를 덧붙인다 (b/c 하나의 처리 흐름에서 나오는 여러 마이크로서비스의 로그 메시지를 쉽게 추적) + 슬루스는 추적 데이터를 저장 /시각화하고자 < HTTP를 이용한 동기 요청이나 RabbitMQ 및 카프카를 사용한 비동기 요청을> 분산 추적 시스템인 집킨으로 보냄
정리 및 느낀점
1부에서는 (1-7장) 스프링 부트 기반의 마이크로서비스를 구축하는 방법을 살펴봤고 이후는 스프링 클라우드를 이용한 마이크로서비스 구축하는 방법을 설명한다.
스프링 웹플럭스 및 스프링 폭스로 swagger를 이용해 문서화가 잘 된 API를 만들었고, 스프링 데이터 MongoDB와 JPA를 사용해 MongoDB와 SQL 데이터베이스에 데이터를 저장했었다. 메세징 시스템인 RabbitMQ, kafka, 그리고 docker, 스프링 클라우드 스트림을 사용해 비동기 서비스를 구축했고, 프로젝트 reactor 기반의 논블로킹 API와 이벤트 기반 비동기 서비스를 사용해 reactive 마이크로서비스를구축했다.
사실 이 위에있는 것까지만 해도 msa의 기본은 된 것 같지만🤔 서비스의ㅣ확장성, 견고성, 보안성, 탄력성과 구성 가능성을 고려하고, 상용화 준비가 완료된 서비스를 만들기 위해서 스프링 클라우드를 사용하는 방법이 2부에 진행된다. 이론은 알아두는 것이 도움이 될 것같고, 이를 적용하는냐의 문제는 1부의 내용을 적용하고 난 다음에 적용을 하는 것이 좋을 것 같다.
