서비스 검색 소개
DNS
이번 장 모든 소스코드는
https://github.com/PacktPublishing/Hands-On-Microservices-with-Spring-Boot-and-Spring-Cloud/tree/master/Chapter09 참고
이번 장에서는 기존 프로젝트 들에 microservices/eureka-server 가 추가된다.
(뒤에서 온 사람인데요 책 또 틀림 microservices/eureka-server 이 아니라 microservice랑 같은 계층에 spring-cloud/eureka-server 임 ㅡㅡ)
서비스 검색
DNS 기반 서비스 검색의 문제
서비스 검색
내가 이해한 바로 마이크로서비스 아키텍처에서 '서비스 검색' == 사용 가능한 마이크로서비스 인스턴스를 추적
- 새 마이크로서비스 인스턴스 시작 후 round-robin 방식 DNS를 이용해 검색하면 안 되는 이유
: DNS서버는 마이크로서비스 인스턴스의 DNS 이름이 같으면 ->사용 가능한 인스턴스의 IP 주소 목록으로 분석해버림. ==> 클라이언트는 라운드 로빈 방식으로 서비스 인스턴스를 호출할 수 있다.
실습을 .. 해야 하는데 ..
bash 로 하네요.. 내용만 적자면
./test-em-all.bash start 로 시스템 환경 시작하고 -> docker-compose up -d --scale review=2 인스턴스 2개 확장 -> docker-compose exec product-composite getent hosts review product-composite 서비스를로 review 의 IP 주소를 찾으면? ==> 2개의 ip주소 나옴
==> 근데 인스턴스 모두 사용하면 문제 없는거 아닌가? 싶지만
curl localhost:8080/product-composite/2 -s | jq -r .serviceAddresses.rev
product-composite 서비스를 여러 번 호출 시 -> review 마이크로서비스의 인스턴스 2개를 모두 사용하는가 --> 하나만 응답받음 🤔

DNS 이름에 대응되는 IP 주소가 여러 개인 경우에는 '동작하는 첫 번째 IP 주소를 계속 사용'하기 때문임
==> DNS 서버와 DNS 프로토콜 --> 동적으로 변하는 마이크로서비스 인스턴스를 처리하는 데 부적합X
서비스 검색의 문제
그러면 어떤 방식으로 마이크로서비스 인스턴스를 추적해야하는가??
몇 가지 고려사항이 있음
- 언제든지 새로운 인스턴스가 시작가능
- 언제든지 기존 인스턴스가 응답하지 않거나 중단될 가능성이 있음
- 몇 실패한 인스턴스 중에선 다시 정상 상태로 돌아와서 다시 트래픽을 수신 하는 것들도 있고 + 안되는 놈들도 있다. 그놈들은 서비스 레지스트리에서 제거 필요!
- 일부 마이크로서비스 인스턴스는 시작하는 데 시간이 걸림.
(== HTTP 요청을 수신한다 != 즉시 해당 인스턴스로 트래픽을 라우팅할 수 있다) - 언제든지 의도하지 않은 네트워크 파티셔닝+ 그외 네트워크 관련 오류가 발생할 가능성 존재
이 모든 사항을 고려해야 '견고하고 탄력적인' 검색 서버 인것
넷플릭스 유레카를 이용한 서비스 검색
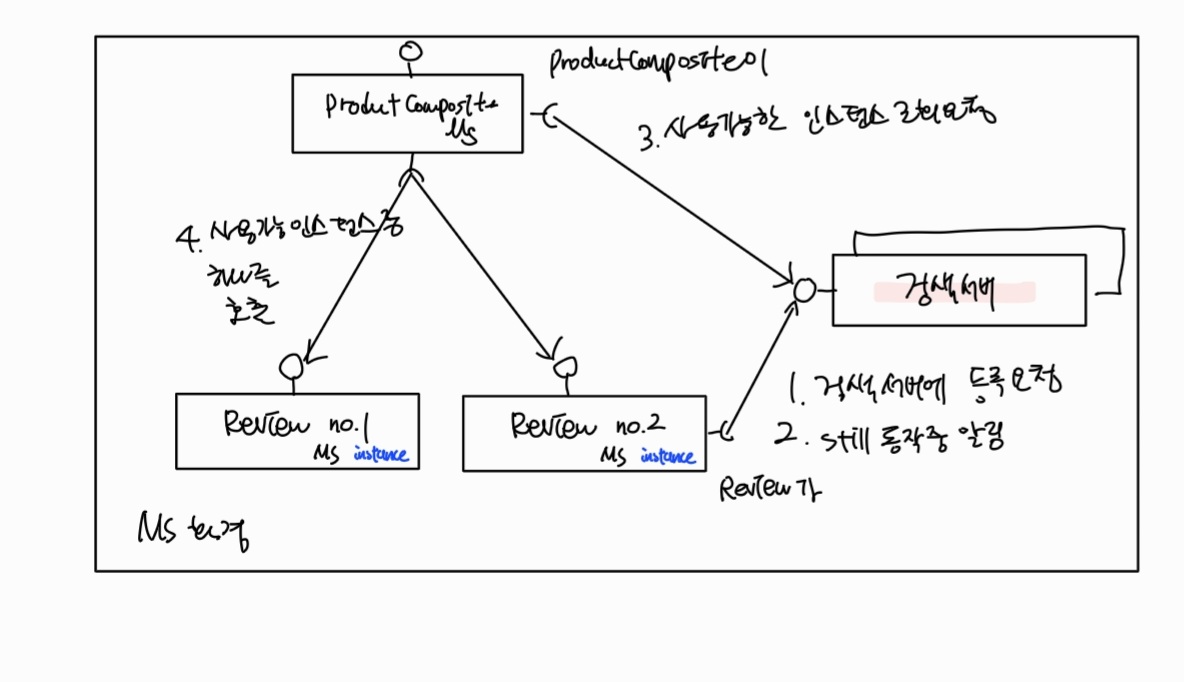
위 그림처럼
1 인스턴스가 시작할때마다 유레카 서버에 자신을 등록하고 -> 2 정기적으로 유레카 서버에 본인이 살아있다고 heartbeat 메시지를 보냄

-> 3 product-composite 는 사용가능한 서비스 정보를 정기적으로 유레카에게 요청 -> 4 클라이언트에서 다른 마이크로서비스로 요청을 보내야 하는 경우 보존된 목록에서 대상 선택함 (보통 RR 방식)
스프링 클라우드는 넷플릭스 유레카와 같은 검색 서비스와 통신하는 방법을 추상화한, DiscoveryClient라는 인터페이스를 제공
( 사용 가능한 서비스 및 인스턴스에 관한 정보를 얻고 (3번) + 자동으로 스프링 부트 애플리케이션을 검색 서버에 등록하는 기능(1번 ) 제공)
넷플릭스 유레카 서버 설정
2부쯤 오니까 책이 굉장히 불친절해졌음 ^^;
스프링부트 프로젝트를 microservices 폴더와 같은 계층에 spring-cloud 하위에 eureka-server 로 생성한다.

의존성을 추가해주고
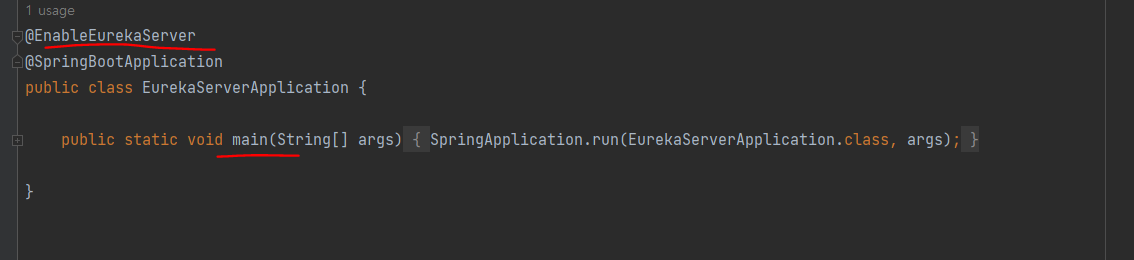
main 클래스에 어노테이션 넣어주고
도커파일에 유레카 서버 추가해줌
넷플릭스 유레카 서버에 마이크로서비스 연결

얘네들 build.gradle에
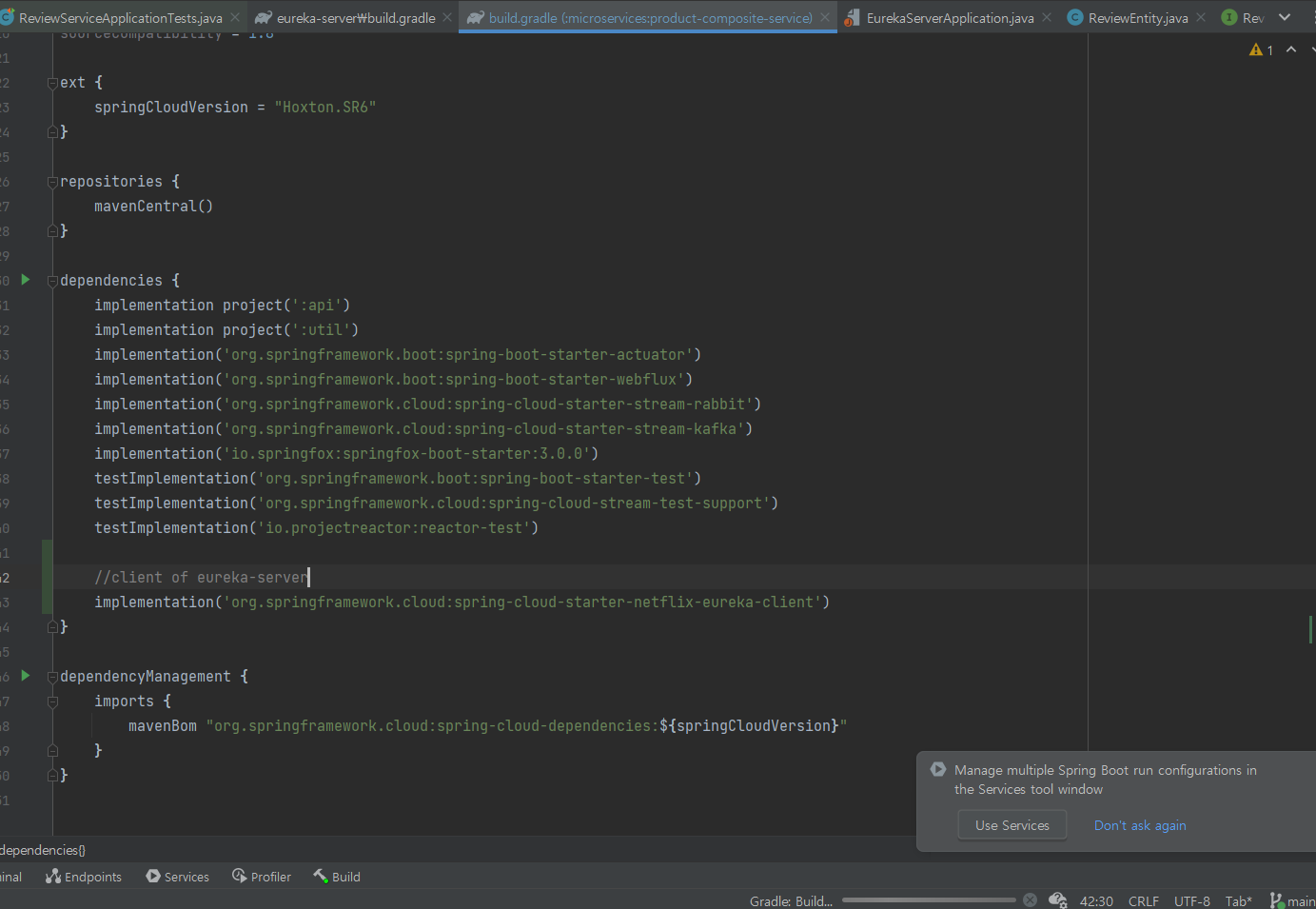
implementation('org.springframework.cloud:spring-cloud-starter-netflix-eureka client') 추가
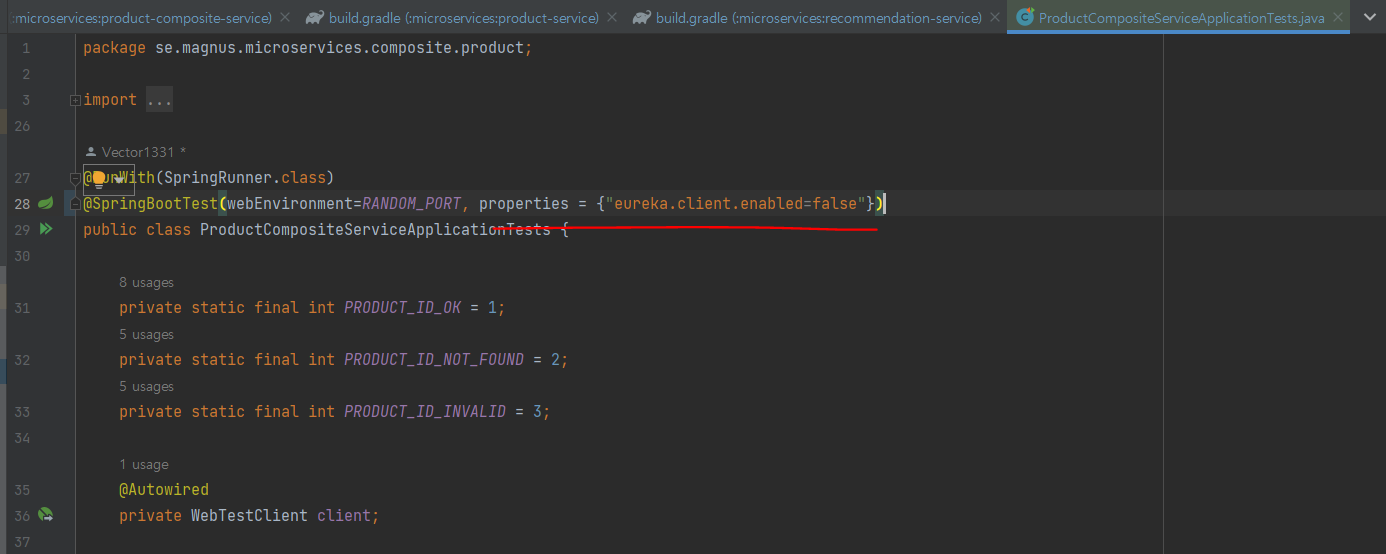
단일 테스트에서 유레카 서버 비활성화하기
@SpringBootTest(webEnvironment=RANDOM_PORT, properties ={"eureka.client.enabled=false"})
- 구성 추가하기
spring.application, name로 유레카 서비스가 서비스 식별하는 이름 부여(URL로 만들어서 호출하기 때문)
1 ProductComposite : 로드 밸런서 클라이언트를 주입하는 WebClient 빌더 추가
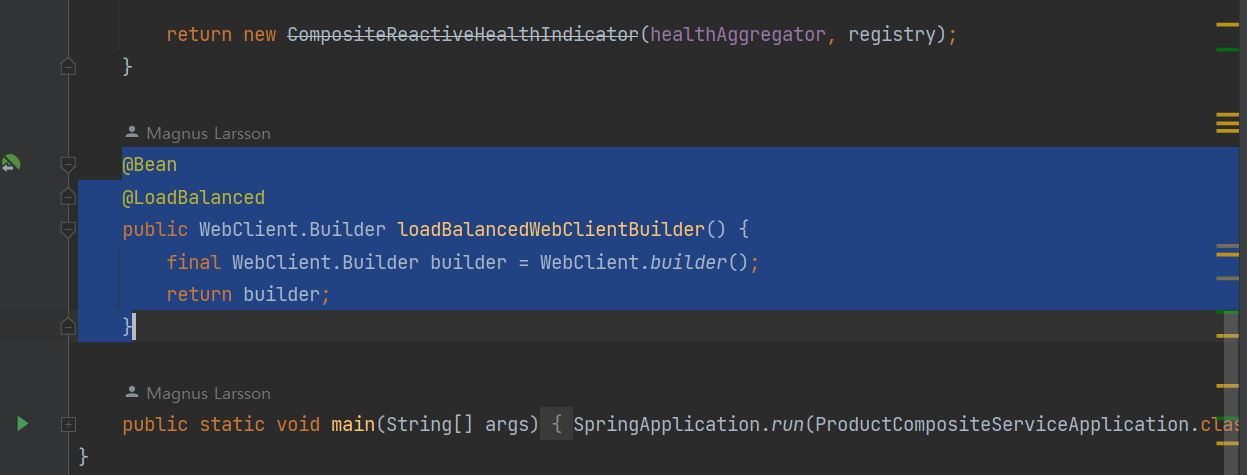
2 ProductComposite통합 (Integration)에 WebClient 객체를 생성하는 방식 업데이트 해주기
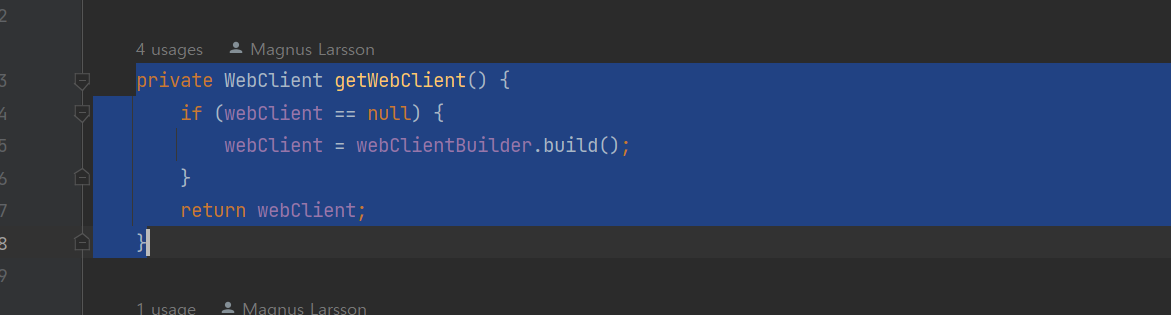
3 WebClient를 사용해 발신용 HTTP 요청을 만들 때 webClient 필드를 직접 사용하는 대신 getWebClient() getter 메서드를 사용해 접근

이렇게 직접 webclient 필드를 썼던 애들을
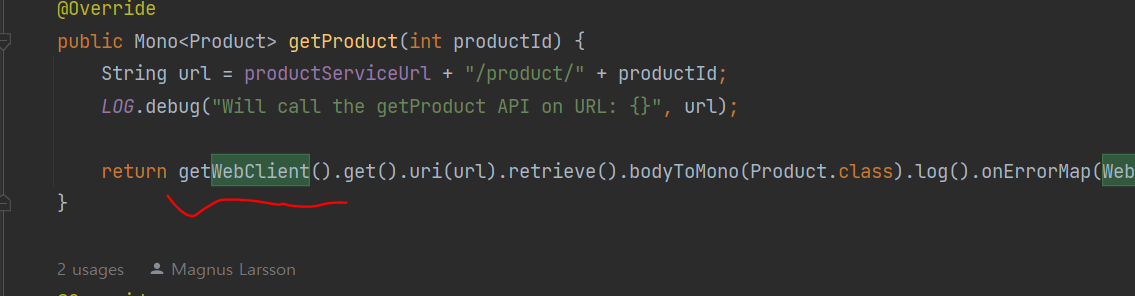
이렇게 변경 (ProductCompositeIntegration 안에 여러개임)
4 application.yml에 하드코딩된거 목록 제거 가능
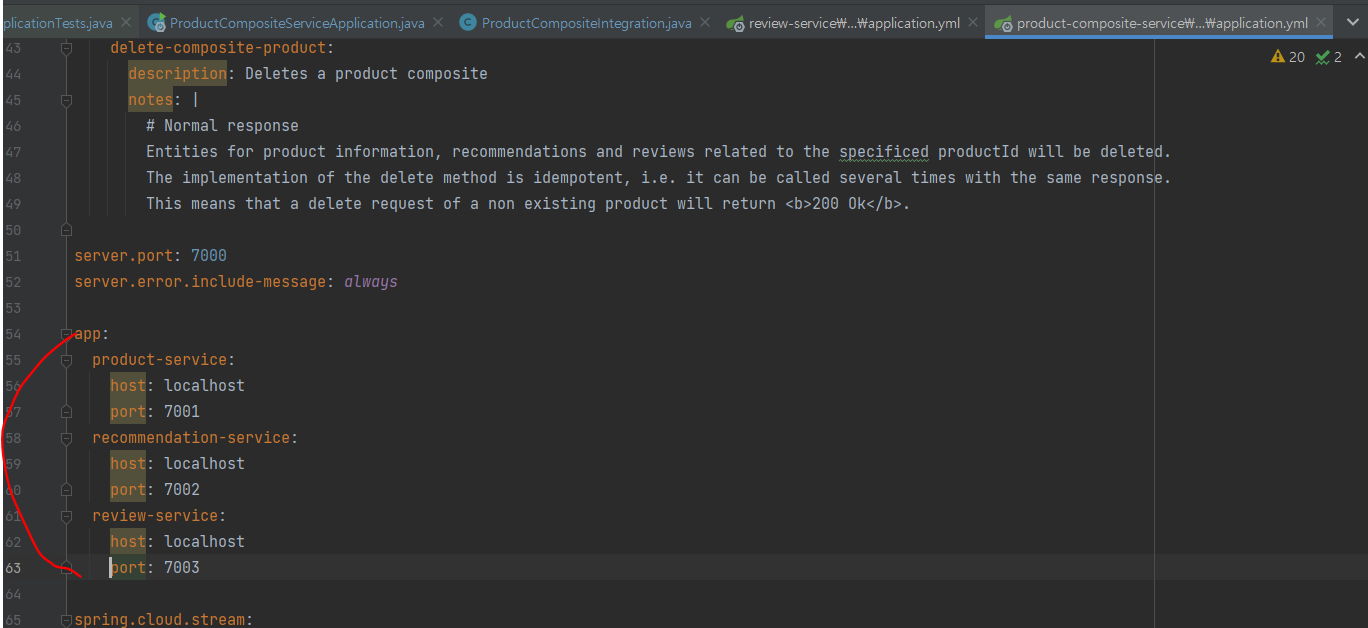
이부분 삭제
ProductCompositeIntegration에 핵심 마이크로서비스 가리키는 url 추가 (이름이다!)
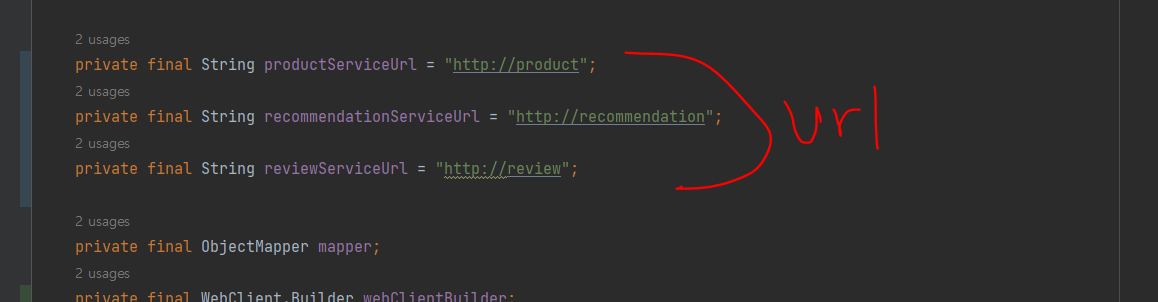
이 이름들은 각각 핵심 마이크로 설정ㅍ파일안에

요롷게 잇음
마이크로서비스 인스턴스가 시작하는 동안 유레카 서버에 자신을 등록하는 방법
넷플릭스 유레카는 많은 장점 가짐 (다양한 사용 사례에 대한 설정을 할 수 있는 구성 가능성이 높은 검색 서버이며, 런타임 특성으로 견고성과 탄력성, 내결함성을 가지고,,, 어찌고저찌고 😪)
이런 유연성과 견고성 이라는 말이 뭐다뭐다?? == 너무 많은 구성 옵션이 있다 🤗
그래도 구성 옵션에 default값이 있다는것 에 감사해야지..
이런 구성들때매 클라이언트가 유레카 서버에 등록된 마이크로서비스 인스턴스를 처음 호출해서 성공하기까지 많은 시간이 소요될 가능성 있음 (이럴거면 이걸 왜쓸까! )
대기 시간이 발생하는 이유 : 관련 프로세스가 서로의 등록 정보를 동기화해야함
대기 시간을 최소화하는 구성을 사용하는 것이 유용하며, 상용화 환경에선 기본값 바탕의 구성을 사용함 ==> 개발에서는 유레카 서버 1개만 사용하지만, 사용화에서는 유레카 서버도 둘 이상의 인스턴스 사용 (고가용성 때문)
클라이언트에서 호출할 마이크로서비스 인스턴스를 찾고자 유레카 서버를 사용하는 방법
- 유레카의 구성 매개 변수 3그룹
1그룹 : eureka.server
2그룹 : eureka.client = 유레카 서버와 통신하는 클라이언트의 변수
3그룹 : eureka.instance =유레카 서버에 자신을 등록하려는 마이크로서비스 인스턴스의 것
-
유레카 서버 구성
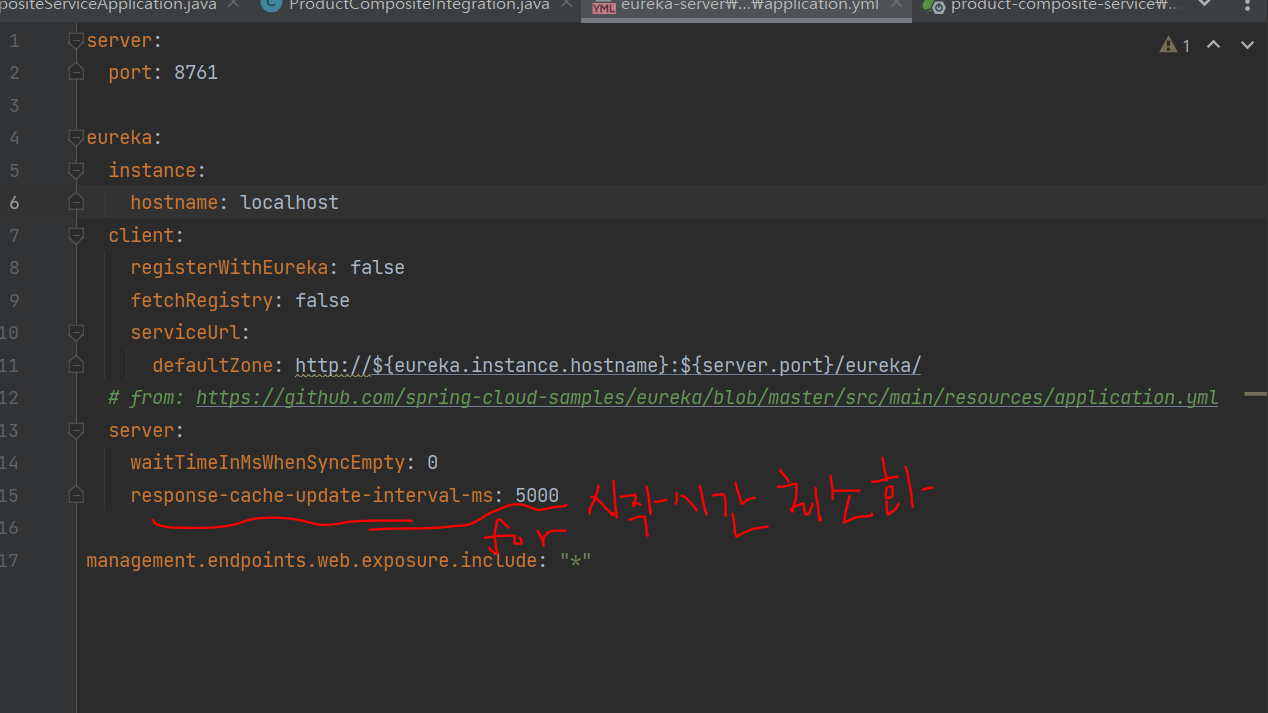
-
유레카 서버에 연결할 클라이언트 구성
microservices폴더 밑에 review, product, recommendation, product-composite에게 구성 정보 준다
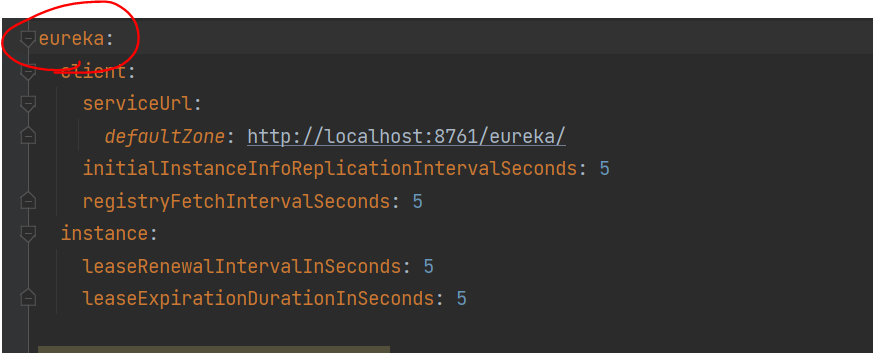
검색 서비스 사용
프로젝트 빌드하고
와 정말 오랜만에 한방에 빌드
docker를 올리고
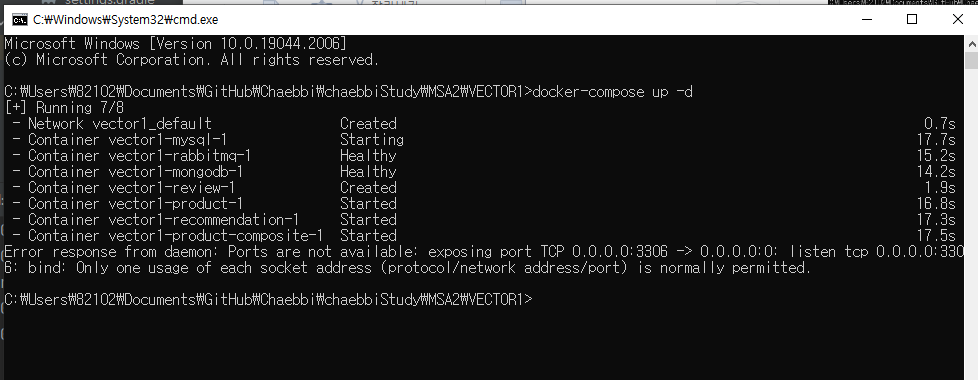
3306쓰고있는 프로세스를 없애자

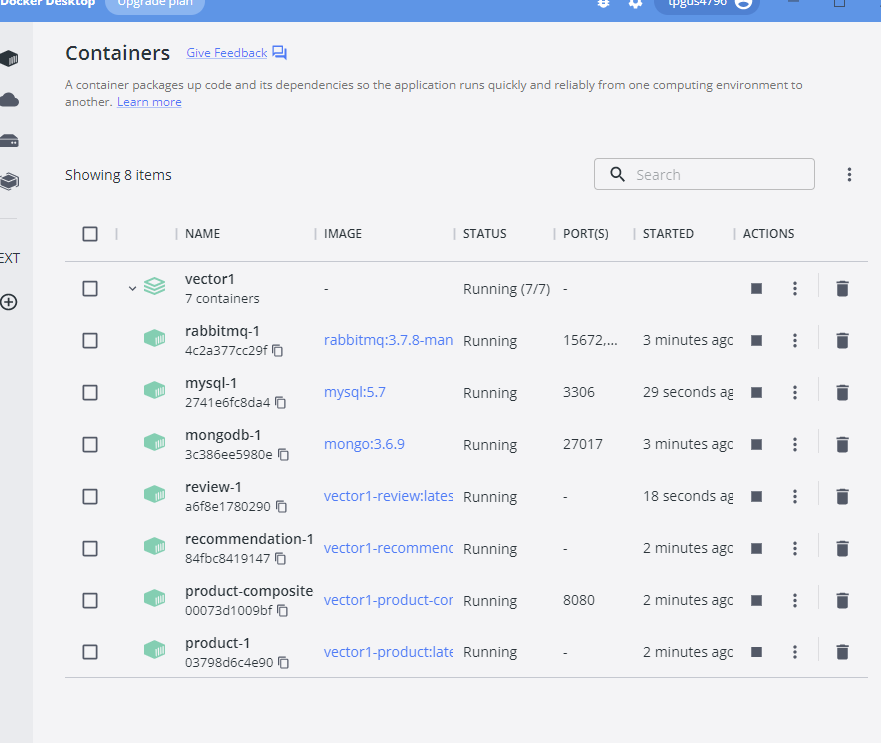
검색 서비스를 테스트하고자 review 마이크로서비스의 인스턴스를 2개 더 시작
docker-compose up -d --scale review=3
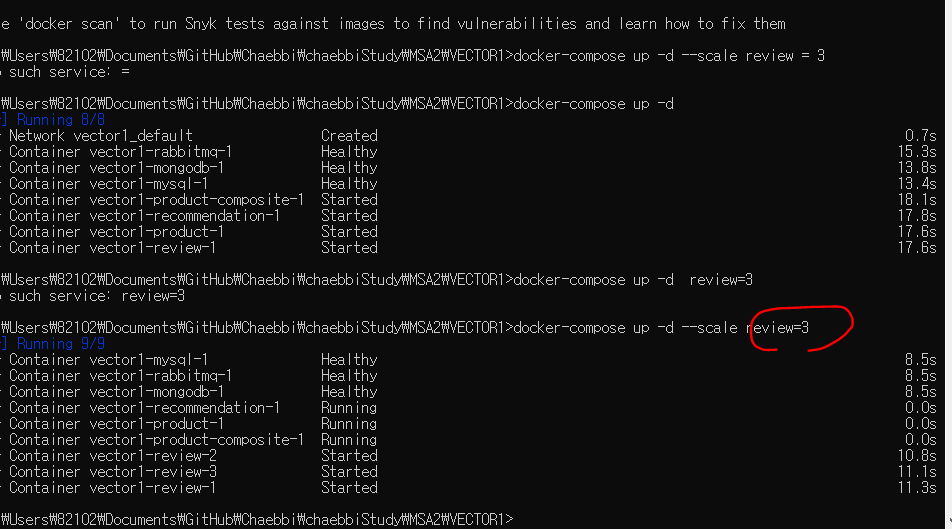
아 =사이에 띄어쓰기 해주면 안된다~~ 꼭 붙여서!
http://localhost:8761/로 이동하면
허허 역시 한방에 될리가 없지
(감쪽같이 저자의 코드로 갈아타고😋)
접속한 넷플릭스 유레카 웹 UI에서 review 인스턴스가 3개인지 확인
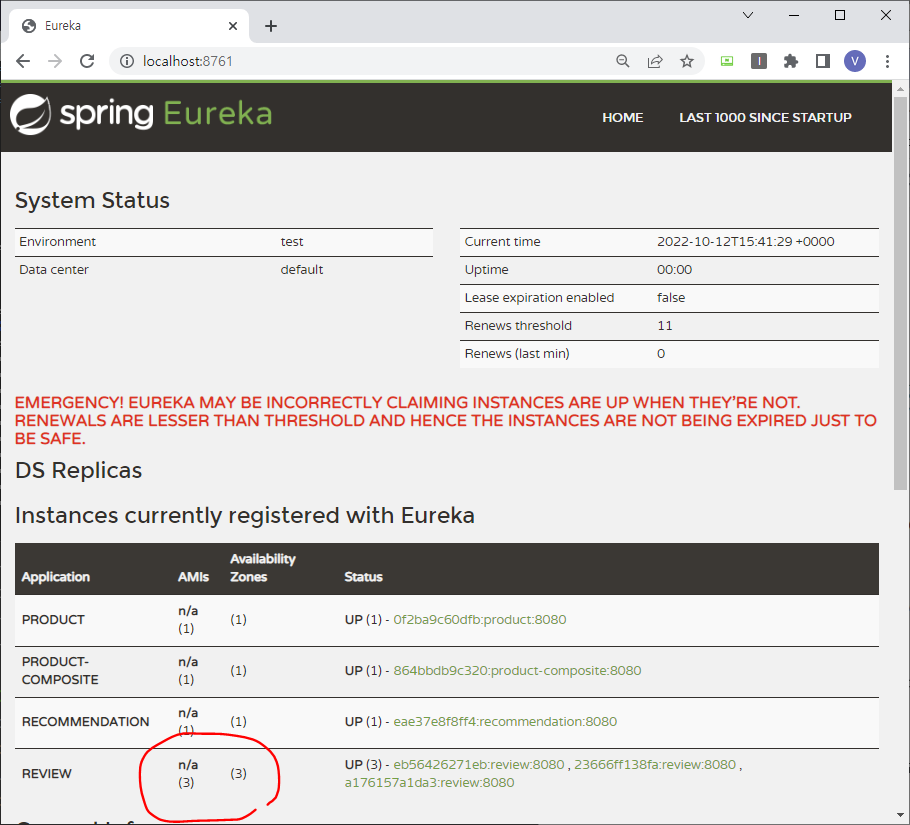
docker-compose logs -f review 결과와 비교
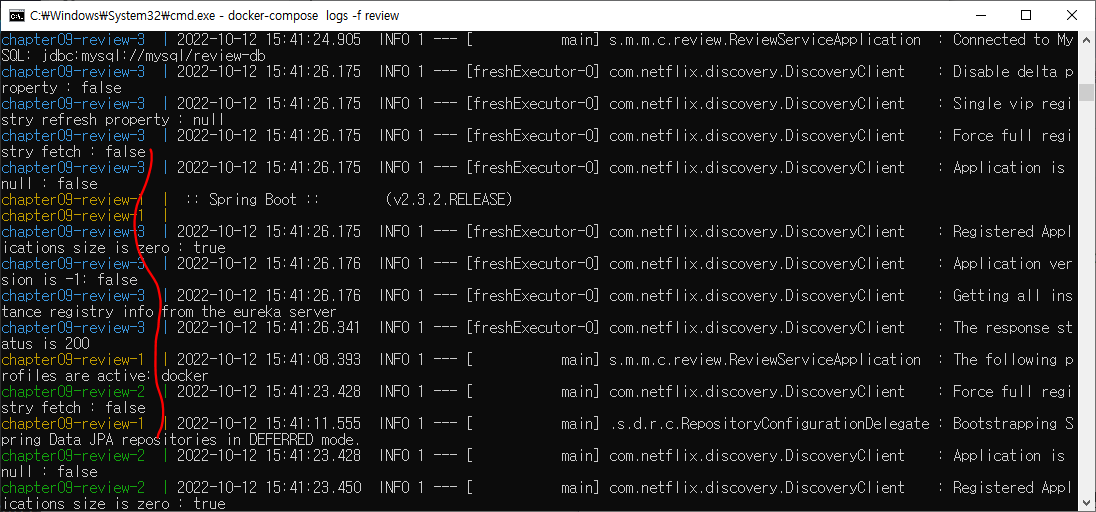
3개 맞음
- 유레카 서비스가 제공하는 REST API를 사용
인스턴스의 ID 목록을 가져오고
클라이언트 측 로드밸런서로 요청을 보낸 후 결과에 있는 review 서비스의 주소를 확인
curl localhost:8080/product-composite/2
(나는 저자걸로 했는데도 curl이 안된다 흑)

실행결과가 매번 다른 이유 : 로드 밸런서가 review 서비스 인스턴스를 호출할 때 라운드 로빈(RR) 방식을 사용하기 때문
review 인스턴스의 로그를 확인
docker-compose logs -f review
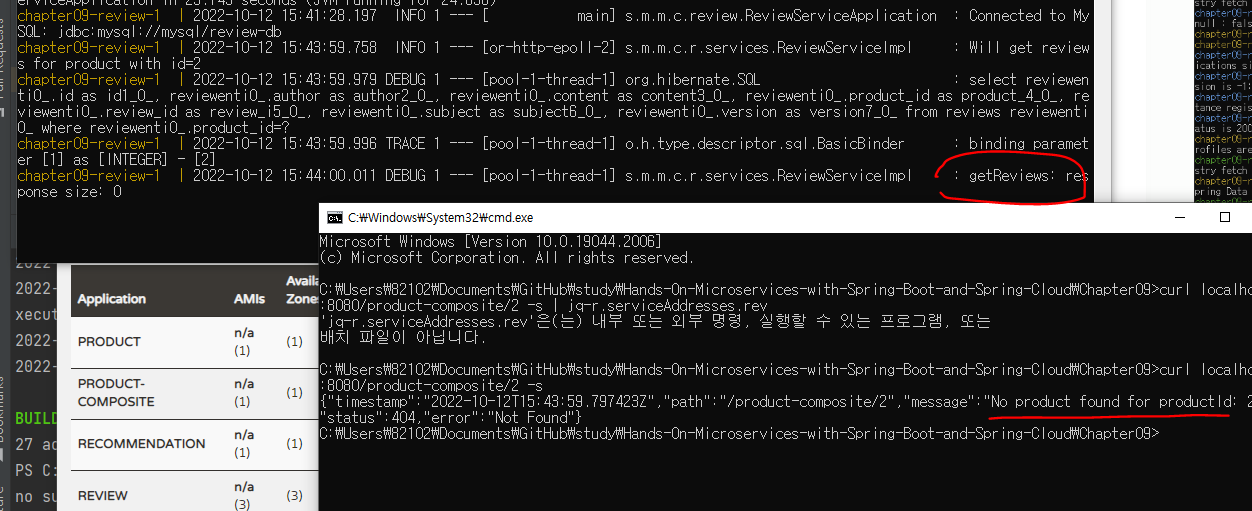
- review 마이크로서비스의 인스턴스 중 하나가 사라지면
docker-compose up -d --scale review=2
사라진 인스턴스에 대한 정보가product-composite 서비스에 전파되는 데 걸리는 시간 때문에 api 호출 실패 가능성 있음
- 유레카 서버의 장애 상황 테스트
유레카 서버가 멈추면 ?
중단되기 전에 클라이언트가 사용 가능한 마이크로서비스 인스턴스에 대한 정보를 이미 읽었으면 --> 로컬에 정보가 캐시돼 있으므로 OK , but 새 인스턴스 사용X + 실행중이라고 읽어둿던 인스턴스가 종료되어도 모른다 유레카를 중지하고 2개의 review 인스턴스가 계속 실행되도록 만들고
docker-compose up -d --scale review=2 --scale eureka=0

curl localhost:8080/product-composite/2 api 호출하면 review가 2개의 주소 포함되어있음 (유레카 서버 호출 전과 마찬가지)
review 인스턴스 중 하나를 중지하면?
docker-compose up -d --scale review=1 --scale eureka=0
유레카 서버가 죽은 상황이니까 인스턴스 중 하나가 못쓰는걸 모름 --> 여전히2개 라고 생각
존재하지 않는 인스턴스 호출하게 되는 상황
==> 시간 초과 및 재시도 등의 복원 메커니즘을 사용해 방지 가능
-
유레카 서벗 중단 시 새 인스턴스 시작됐을 때
product 마이크로서비스의 새 인스턴스를 시작했을 때
docker-compose up -d --scale review=1 --scale eureka=0 --scale product=2
api 호출해서 product 서비스 주소를 확인하면
curl localhost:8080/product-composite/2
새 인스턴스를 모르므로 첫 인스턴스로 모든 호출이 가게 된다 --> 인스턴스 여러 개 두는 의미가 없어지겠지 -
유레카 서버 다시 시작
docker-compose up -d --scale review=1 --scale eureka=1 --scale product=2
review가 하나고 (2번 review 가 사라진거 감지)
product가 2개라는걸 감지하겠지
여러번 curl localhost:8080/product-composite/2 호출해서 product 서비스와 review 서비스의 주소를 확인 ==> 다른 인스턴스 반환
정리 및 느낀점
이번엔 넷플릭스 유레카를 스프링부트 기반의 마이크로서비스를 위한 검색 서버로 사용하는 방법을 배웠음.
인스턴스를 DNS로 검색하는게 아니라 검색 서버가 왜 있는지는 알겟지만 프로젝트에 사용할만큼은 아닌 것같음. 트래픽이 엄청 엄청 많은 서비스라면 유레카 서버를 여러개 둬서 하는 것이 좋을 것 같음
그래도 좋은 내용 배웠음
그리고.. 리본..?
그리고 제목이 넷플릭스 유레카와 리본인데 리본 내용은 어딨지...? 싶었음
찾아보니까 Ribbon은 분산 처리 방법 인것이었다. 여러 서버를 라운드 로빈 방식으로 부하 분산 기능을 제공하는게 ribbon이라고 한다.
참고:https://ratseno.tistory.com/62
