알고리즘 디버깅 by 학습 곡선과 검증 곡선
학습 알고리즘 성능 향상에 도움되는 간단하지만 아주 강력한 분석 도구
주어진 훈련 데이터셋에 비해 모델 너무 복잡 == 모델의 df나 모델 parameter가 너무 많다 == 훈련데이터에 모델이 과대적합된다 == 처음 본 데이터에 잘 일반화 안된다
solve) 훈련 샘플 더 모으면 보통 도움이 된다.
but 실전에서는 데이터 더 모으는거 매우 비싸거나 불가능 할때도 많다. 😂
모델의 훈련 정확도와 검증 정확도를 훈련 데이터셋의 크기 함수로 그래프 그려보면 모델에 높은 분산 문제 있는지 높은 편향 문제 있는지 쉽게 감지 가능. (더 많은 데이터 모으는 것이 문제 해결가능한지 판단 가능)
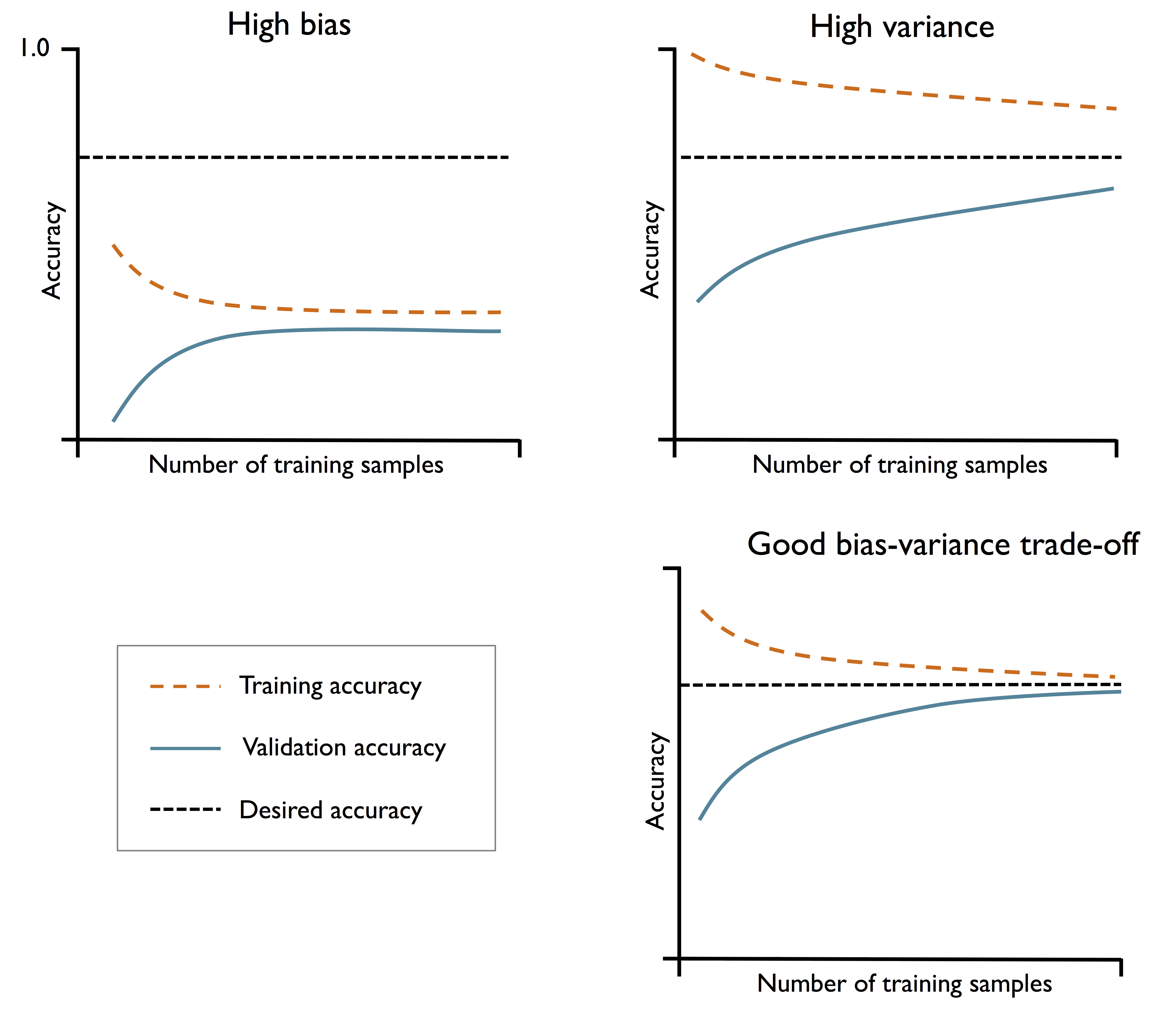
왼쪽 위는 높은 편향 모델 == 과소적합 == 모델의 훈련 정확도는 줄어들고 교차 검증 정확도도 낮다.
(훈련 샘플 개수 늘어날 수록 기대하는 정확도와 차이가 큼)
solve) 모델 parameter 개수 늘려서 모델을 좀 더 복잡하게 만든다. (너무 간단한게 문제)
예) 추가적 특성을 수집하거나 만든다. 또는 SVM(서포트 벡터 머신)이나 로지스틱 회귀 분류기에 규제 강도 줄인다.
오른쪽 위는 높은 분산 모델 == 훈련 정확도와 교차 검증 정확도사이 큰 차이 있음 == 과대적합
(훈련 샘플 개수 늘어날 수록 기대하는 정확도와 차이를 줄이고 있지만 훈련 정확도와 교차 검증 정확도 차이가 크다)
solve) 더 많은 훈련 데이터 모으거나 모델 복잡도 낮추거나 규제 증가.
규제 없는 모델이라면 특성 선택이나 특성 추출 통해 특성 개수 줄여 과대적합 감소 가능.
더 많은 훈련 데이터가 항상 도움되는 것은 아님
-> 잡음 많거나 모델이 이미 거의 최적화 된 경우
학습 곡선으로 편향과 분산 문제 분석
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
pipe_lr = make_pipeline(StandardScaler(),
LogisticRegression(penalty='l2', random_state=1,
max_iter=10000))
train_sizes, train_scores, test_scores =\
learning_curve(estimator=pipe_lr,
X=X_train,
y=y_train,
train_sizes=np.linspace(0.1, 1.0, 10),
cv=10,
n_jobs=1)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(train_sizes, train_mean,
color='blue', marker='o',
markersize=5, label='Training accuracy')
plt.fill_between(train_sizes,
train_mean + train_std,
train_mean - train_std,
alpha=0.15, color='blue')
plt.plot(train_sizes, test_mean,
color='green', linestyle='--',
marker='s', markersize=5,
label='Validation accuracy')
plt.fill_between(train_sizes,
test_mean + test_std,
test_mean - test_std,
alpha=0.15, color='green')
plt.grid()
plt.xlabel('Number of training examples')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.ylim([0.8, 1.03])
plt.tight_layout()
plt.show()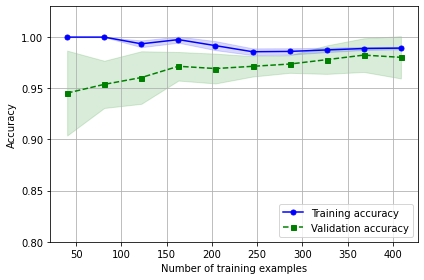
학습 곡선 그래프에서 보듯 모델 훈련 모델에 250개 이상 데이터 사용시 훈련, 검증 데이터셋 잘 작동. 데이터<250일경우 훈련 정확도 증가, 검증 정확도와 차이는 커짐 == 과대적합
검증 곡선으로 과대적합과 과소적합 조사
- 학습곡선 : 샘플 크기의 함수로 훈련 정확도와 테스트 정확도를 그린다.
- 검증 곡선은 모델 파라미터 값의 함수로 그린다.
from sklearn.model_selection import validation_curve
param_range = [0.001, 0.01, 0.1, 1.0, 10.0, 100.0]
train_scores, test_scores = validation_curve(
estimator=pipe_lr,
X=X_train,
y=y_train,
param_name='logisticregression__C',
param_range=param_range,
cv=10)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(param_range, train_mean,
color='blue', marker='o',
markersize=5, label='Training accuracy')
plt.fill_between(param_range, train_mean + train_std,
train_mean - train_std, alpha=0.15,
color='blue')
plt.plot(param_range, test_mean,
color='green', linestyle='--',
marker='s', markersize=5,
label='Validation accuracy')
plt.fill_between(param_range,
test_mean + test_std,
test_mean - test_std,
alpha=0.15, color='green')
plt.grid()
plt.xscale('log')
plt.legend(loc='lower right')
plt.xlabel('Parameter C')
plt.ylabel('Accuracy')
plt.ylim([0.8, 1.0])
plt.tight_layout()
plt.show()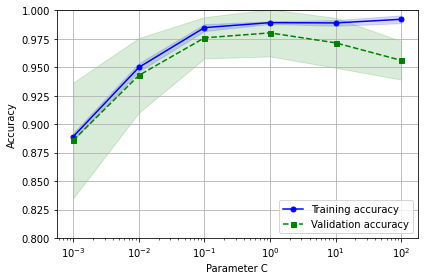
평균 훈련 정확도와 교차 검증 정확도 그리고 이에 상응하는 표준편차를 나타냄.
규제 강도 높이면 (==c값 줄이면) 모델이 조금 과소적합 된다.
마찬가지로 규제 강도 낮추면 (==c값 높이면) 조금 과대적합 된다.
머신 러닝 모델 세부 튜닝 by 그리드 서치
머신 러닝 파라미터 :
1. 훈련 데이터 학습되는 파라미터
예) 로지스틱 회귀 가중치
2. 별도로 최적화되는 학습 알고리즘 파라미터
== 모델 튜닝 파라미터 == 하이퍼파라미터
예) 로지스틱 회귀의 규제 매개변수, 결정 트리의 깊이 매개변수
위에서는 검증 곡선 사용해 hyperparameter 하나를 튜닝해 모델 성능 향상시켰다면, 이번에는 그리드 서치로 hyperparameter 최적화 기법 배움
그리드 서치이용 hyperparameter튜닝
그리드 서치 사용 법은 리스트로 지정된 여러가지 하이퍼파라미터 값 전체를 모두 조사해 이 리스트에 있는 값의 모든 조합에 대해 모델 성능 평가해 최적의 조합 찾는 간단한 방법.
sklearn.modelselection 모듈의 GridSearchCV객체 만들어 SVM을 위한 파이프라인 훈련하고 튜닝함.
훈련 데이터셋 사용해 그리드 서치 수행한 후 최상의 모델 점수는 best_score속성에 얻고 이 모델 매개변수는 bestparams 속성에서 확인
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
pipe_svc = make_pipeline(StandardScaler(),
SVC(random_state=1))
param_range = [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]
param_grid = [{'svc__C': param_range,
'svc__kernel': ['linear']},
{'svc__C': param_range,
'svc__gamma': param_range,
'svc__kernel': ['rbf']}]
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
refit=True,
cv=10,
n_jobs=-1)
gs = gs.fit(X_train, y_train)
print(gs.best_score_)
print(gs.best_params_)독립적 테스트 데이터셋 사용해 최고 모델 성능 추정
clf = gs.best_estimator_
# refit=True로 지정했기 때문에 다시 fit() 메서드를 호출할 필요가 없습니다.
# clf.fit(X_train, y_train)
print('테스트 정확도: %.3f' % clf.score(X_test, y_test))테스트 정확도: 0.974 로 나옴
알고리즘 선택 by 중첩 교차 검증
여러 종류의 머신러닝 알고리즘 비교하려면 중첩 교차 검증 방법 권장됨.
중첩 교차 검증 : 바깥쪽 k겹 교차 검증 루프가 데이터를 훈련 폴드와 테스트 폴드로 나누고 안쪽 루프가 훈련 폴드에서 k겹 교차 검증 수행해 모델 선택, 모델 선택되면 테스트 폴드 사용해 모델 성능 평가함.
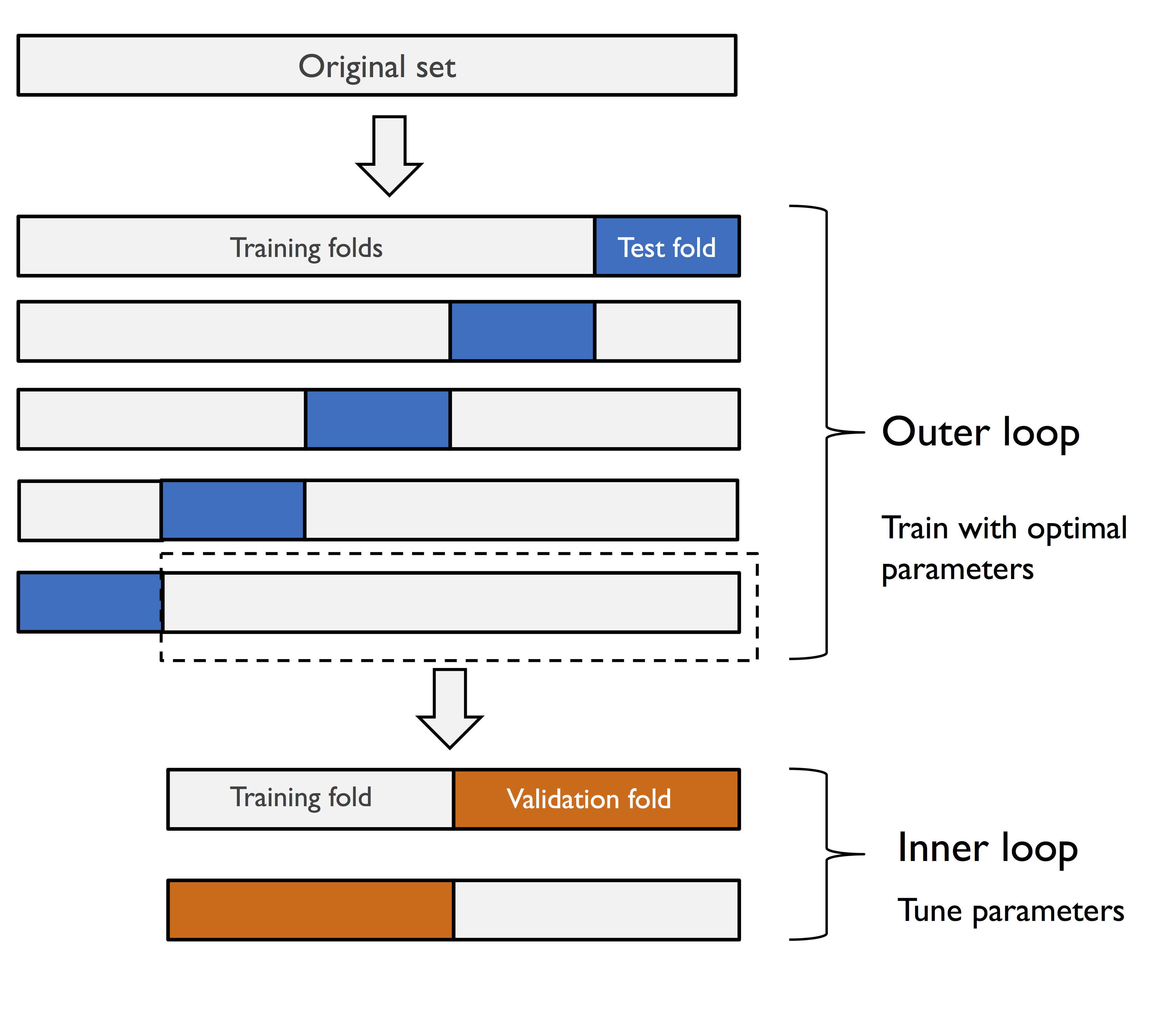
사이킷런의 중첩 교차 검증은
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
cv=2)
scores = cross_val_score(gs, X_train, y_train,
scoring='accuracy', cv=5)
print('CV 정확도: %.3f +/- %.3f' % (np.mean(scores),
np.std(scores)))출력은 CV 정확도: 0.974 +/- 0.015 로 된다.
(평균 교차 검증 점수 반환)
이전까지는 정확도 사용해 모델 평가했음. 정확도는 일반적으로 분류 모델의 성능 정량화하는데 유용함.
성능 평가 지표는 여러개 있는데 정밀도, 재현율, F1-점수 있음
오차 행렬
학습 알고리즘 성능을 행렬로 펼쳐 놓은 행렬.
오차 행렬은 진짜양성(TP) 진짜음성(TN), 거짓양성(FP) 거짓음성(FN)의 개수를 적은 단순한 정방 행렬임 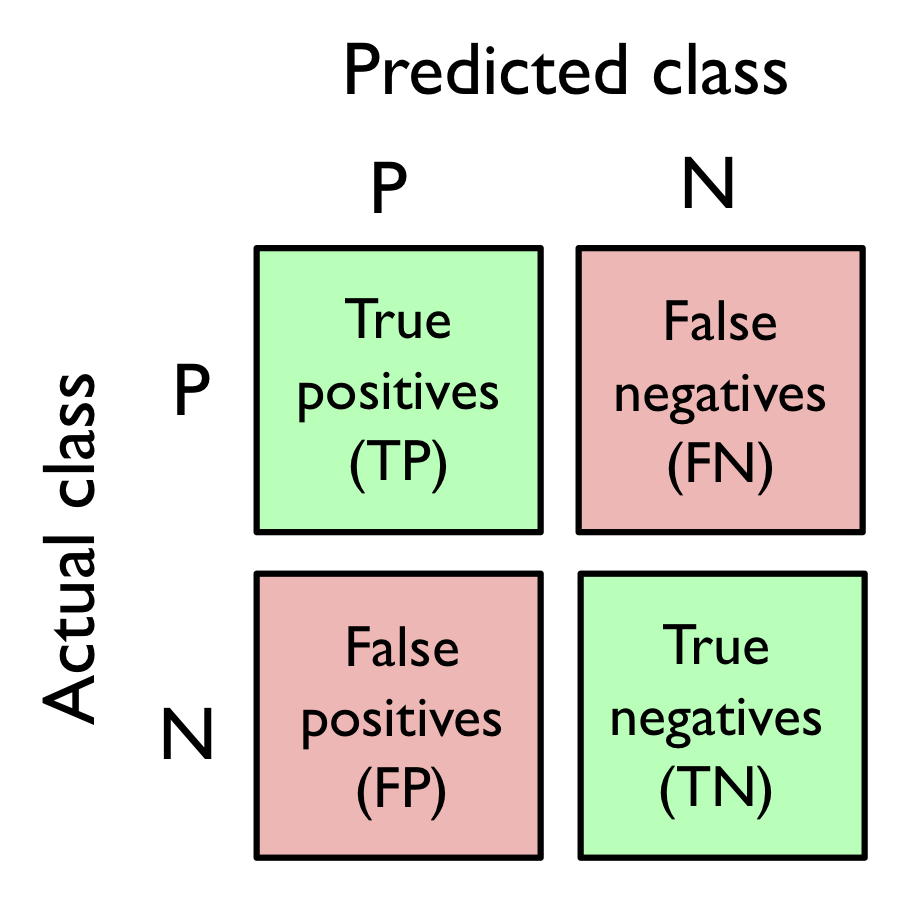
사이킷런 함수도 있음
from sklearn.metrics import confusion_matrix
분류 모델의 정밀도와 재현율 최적화

예측 오차 , 정확도 : 얼마나 많은 샘플을 잘못 분류 했는지 일반적 정보 알려줌
F1점수: PRE(정확도)와 REC(재현율) 최적화로 인한 장단점의 균형 맞추기 위해 pre와 rec 조합
사이킷런에서 이런 성능지표 구현되어있음
from sklearn.metrics import precision_score, recall_score, f1_score
import해서 사용가능
또 GridSearchCV의 scoring 매개변수 사용해도 성능 지표 출력 가능
ROC 곡선
ROC 그래프는 분류기의 임계 값을 바꾸어 가면서 계싼괸 FPR과 TPR 점수 기반으로 분류 모델 선택하는 도구
완벽 분류기의 그래프는 TPR 1이고 FPR이 0
이렇게 이진 분류 성능 지표 외에도 다중 분류 성능 지표방법도있으나 책에서 이진 분류 만큼 자세히 다루고 있지 않아서 여기선 생략함
불균형 클래스
실전 데이터는 매우 자주 불균형 클래스가 나타남.
한 개 또는 여러개 클래스 샘플이 데이터셋에 너무 많을 때 나타난다.
이런 데이터셋에 분류 모델 훈련 할 때 모델 비교위해 정확도를 사용하는 것보다 다른 지표 활용하는 것이 낫다.
애플리케이션 주요 관심 대상 따라
정밀도, 재현율, ROC 곡선 등을 사용할 수 있음
클래스 불균형은 모델 훈련동안 학습 알고리즘 자체에 영향을 미친다. (모델 평가와 별개로)
알고리즘 훈련동안 처리한 샘플에서 계산한 보상/비용함수 합을 최적화하는데 결정 규칙은 多數 클래스 쪽으로 편향되기 쉽다!
== 알고리즘 훈련 과정에서 비용 최소화/보상최대화 위해 데이터에서 가장 빈도 높은 클래스 예측을 최적화하는 모델 학습한다.
- 불균형 클래스 다루는 방법 :
小數 클래스 발생한 예측 오류에 큰 벌칙 부여
-> 사이킷런의 class_weight 매개변수를 'balanced'로 설정해 조정
또는
小數 클래스 샘플 늘리거나 多數 클래스 샘플 줄이거나 인공적으로 훈련 샘플 생성하는 것
-> 사이킷런의 resample함수 사용해 데이터셋에서 중복 허용한 샘플 추출 방식으로 소수 클래스 샘플 늘리기 가능

내용이 쏙쏙 눈에 들어옵니당 잘 보고 가요~~^^!