머신러닝 종류
- 지도학습 (Supervised Learning)
: 레이블된 데이터, 직접적 피드백, 예측 결과/미래 - 비지도학습 (Supervised Learning)
: 레이블X , 피드백X, 데이터의 숨은 구조 찾음 - 강화학습 (Supervised Learning)
: 결정과정 학습, 보상시스템으로 더 나은 결정
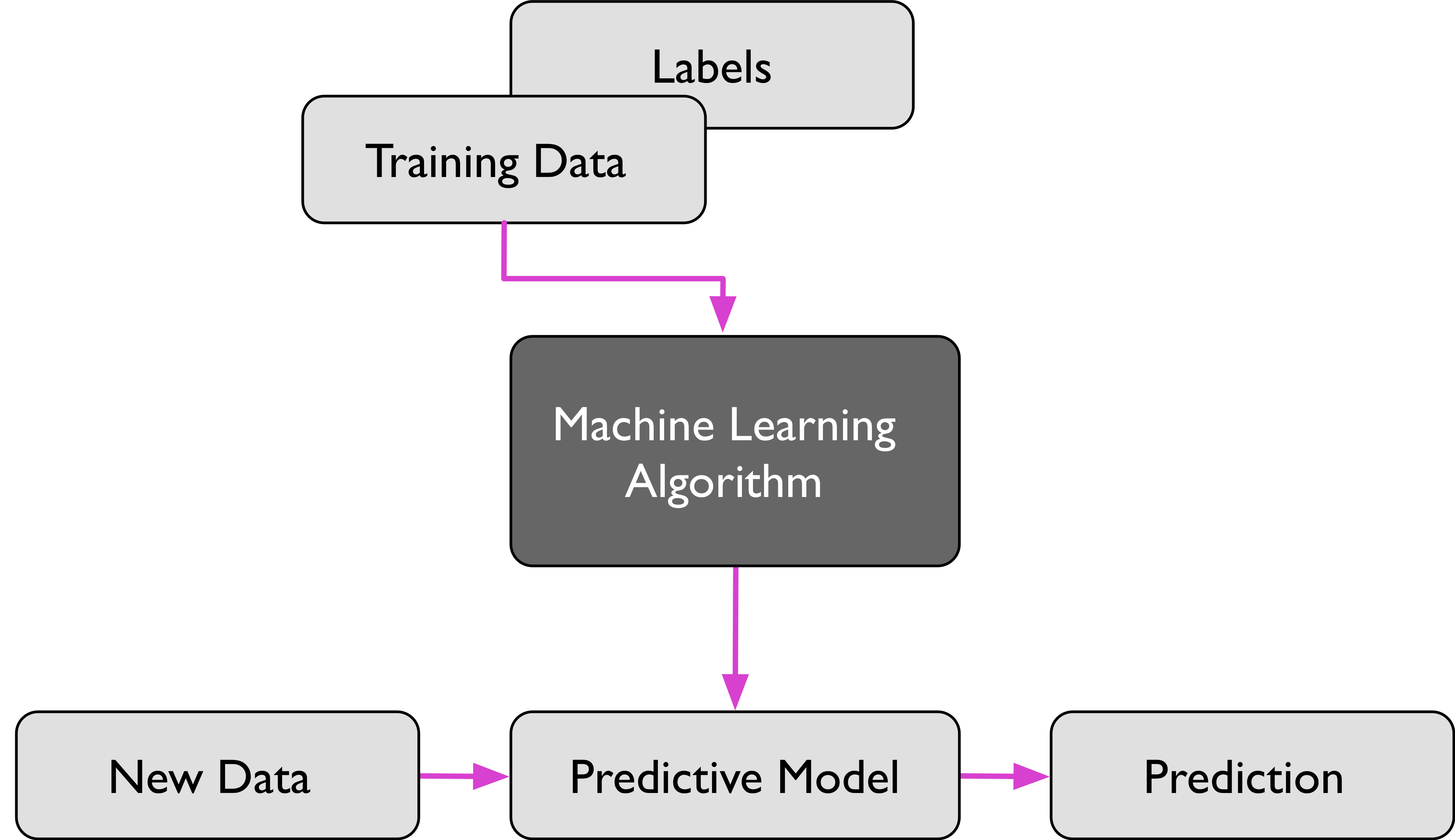
지도학습으로 미래 예측
레이블 없는 새로운 데이터를 예측값/출력값을 들고 프로세스 진행.
분류
: 클래스 레이블 예측
이진분류(binary classification) : 두개의 분류로 나누는 것
여러 개로 분리되는 경우는 다중분류(multiclass classification)
이진분류에는 특별히 양성 클래스(positive class) / 음성 클래스(negative class) 로 둬서 분류 가능. 세개의 클래스가 있을 경우에는 다중분류 문제
밑의 사진의 양성/음성 클래스를 나누는 경계를 결정경계(decision boundary) 라고 함.
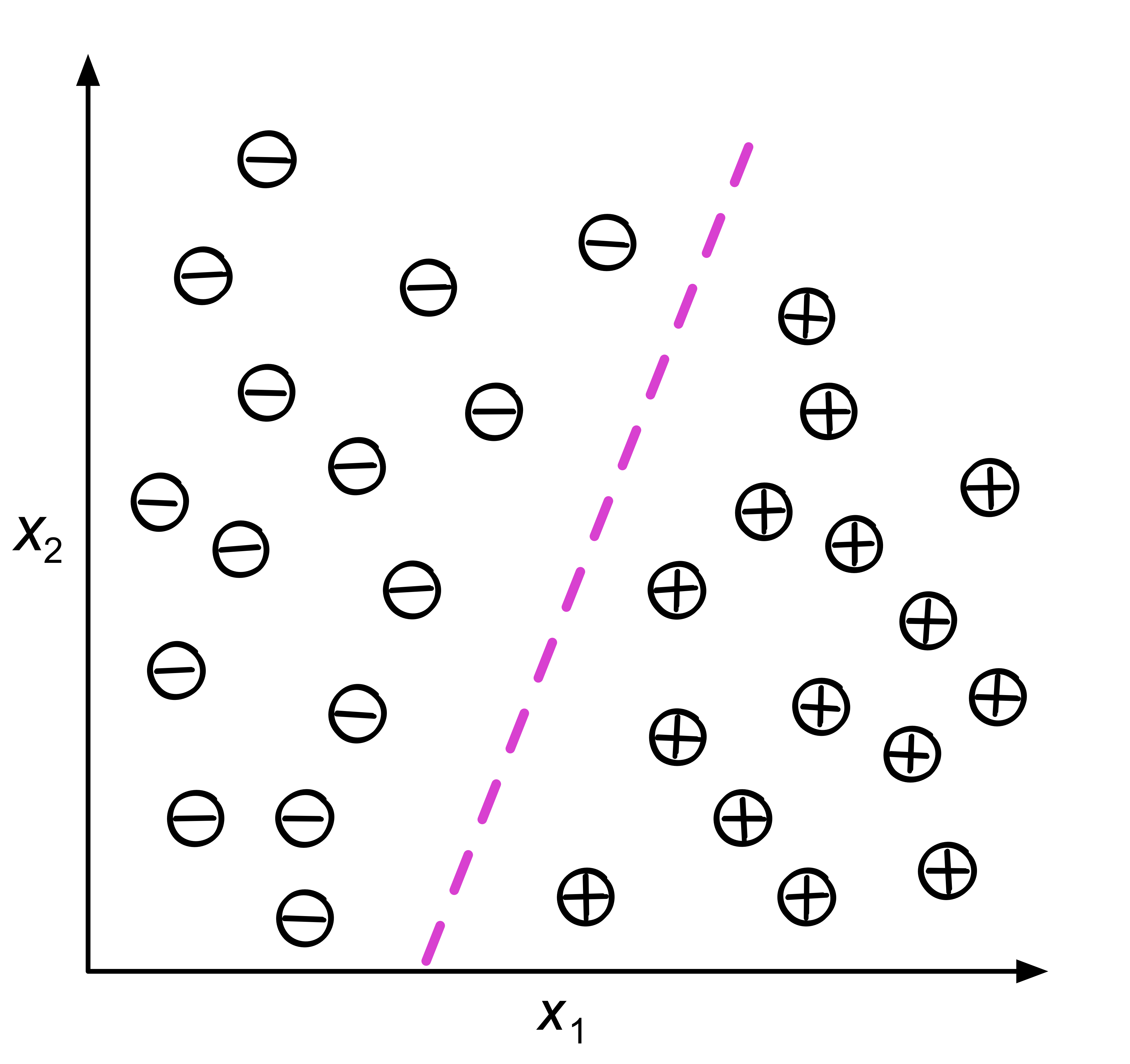
결정을 내릴 수 있는 경계선 ,
임의의 수를 예측하는 문제 : 회귀의 문제
입력x 예측y이라면
y에 대한 x의 식 직선방정식을 이용해서 (모델링) 새로운 값에 대한 출력값을 예측
여기서 X를 예측 변수(특성)(입력) 으로 부르고
Y를 반응 변수(타깃)(출력)
하나의 직선으로 훈련데이터를 모델링하는 것을 선형회귀라고 함.
강화학습, 반응형 문제 해결
보상을 통해서 (reward) 주어진 환경에 대한 리워드를 받는다.
리워드와 상태를 보고 행동을 선택해서
더 좋은 리워드를 받도록 반복
비지도 학습, 숨겨진 구조발견
타깃이 없다면 비슷한 것 끼리 데이터를 모을 수 있다.(클러스터링, 모아진 군집은 cluster)
차원축소
많은 특성을 적은 특성으로 줄이는 과정을 차원축소라한다.
원소의 개수를 줄이더라도 모델의 특성에는 큰 영향없도록 줄인다. 원래 샘플 있던 위치를 그대로 유지하면서 차원축소
머신러닝 용어
- 훈련 샘플 : 하나의 행벡터
- 훈련 : 모델이 어떤걸 예측하거나 분류할 수 있도록 만드는 것
- 손실 함수(비용 함수) : 모델 특성 이용해서 타깃 예측이 어느정도인지 평가하는 지표, 손실 함수는 샘플 하나에 대한 손실이고, 비용함수는 전체 샘플에 대한 손실의 평균
머신러닝 시스템 구축 로드맵
전처리 : 원래 있는 데이터를 바로 쓰지X, 사전에 가공
-> 훈련 -> 평가 -> 예측
학습 훈련 과정에는 모델 선택하거나 교차 검증하거나 성능 측정하고 하이퍼파라미터 최적화 등을 한다.
데이터 전처리
: 모델에 잘 훈련되도록 조정하는 작업
가장 대표적으로는 스케일 조정 (단위가 다 다른거 맞주는 작업)
공부 자료 : 머신 러닝 교과서 3판
원문 : https://github.com/rickiepark/python-machine-learning-book-3rd-edition/blob/master/ch01/ch01.ipynb
강의 : https://www.youtube.com/watch?v=WC4po1W4LzA&list=PLJN246lAkhQiEc-QvvGzUneCWuRnCNKgU

깔끔한 정리 잘 보구 갑니당~~ 스터디 파이팅😍