0. 서론
대략 한 달 간의 공통 과정을 마치고, 이번 주부터 NLP와 CV 중 하나의 트랙을 선택하여 집중적으로 학습하게 되었다. 처음엔 CV를 선택하려 했지만, 일전에 상담데이터 분류대회에 지원했다가 데이터셋을 보고 포기해버린 기억이 되살아나 NLP를 최종적으로 선택하였다.
1. 강의 정리
1주차에는 다음과 같은 내용을 수강하였다.
- 워드 임베딩
- 순환 신경망 모델의 기본 구조 (RNN, LSTM, GRU)
- Attention
- Beam Search & BLEU Score
순환 신경망 모델은 공통과정 때 수강했기에, 처음 듣는 Attention 이후의 내용을 중심으로 정리해본다.
I. Attention
i. sequence to sequence model

sequence to sequence 모델은 이름에서 유추할 수 있듯이, 연속된 문자열을 입력으로 받아 연속된 문자열을 출력하는 모델이다.
Seq2Seq 모델은 크게 문장을 받는 인코더(Encoder)와 받은 문장을 바탕으로 학습 결과를 출력하는 디코더(Decoder)로 구성되어 있으며, 두 모듈은 파라미터를 서로 공유하지 않는 독립적인 모듈이다.
이 때, 인코더의 마지막 Hidden State Vector는 Decoder의 첫 번째 Hidden State Vector가 되며, 디코더는 입력 값으로 시작 토큰(<START>) 을 받으며, 끝 토큰(<END>)를 출력할 때까지 RNN을 구동시킨다.
그러나 아무리 LSTM이 Long Dependency 문제해결에 기여했다 하더라도, Sequence가 길어질수록 초반의 정보가 유실되는 것은 불가피하다.
ii. Attention
Attention은 인코더 내 각각의 레이어가 생성하는 Hidden state vector을 활용하여, 디코더가 특정 입력에 집중하여 학습할 수 있게 해주는 방법이다.

Attention을 이용한 학습은 다음의 순서로 진행된다.
- 디코더의 Hidden state vector가 인코더 내 각각의 hidden state vector와 내적 연산을 수행하여 유사도 (Attention Score)를 계산해준다.
- Dot product : 두 Vector의 단순 내적
- Generalized Dot product : 두 Vector 사이에 Matrix를 삽입하여 학습 가능한 가중치를 부여
- Concate 기반 Dot Product : 두 Vector가 합쳐진 Vector를 input으로 받는 Neural Network를 구성
-
유사도에 Softmax 연산을 취해 확률값을 구해준 후, 이를 가중치로 각각의 encoder hidden state vector에 곱해준다.
-
Encoder hidden state vector 끼리의 가중 평균을 통해 하나의 벡터(Attention output, Context Vector)를 구해준다.
-
어텐션 벡터와 디코더의 Hidden state vector를 하나로 합쳐(concatenate), output layer의 입력으로 하여 단어를 예측한다.
iii. 장점
- 입력 시퀀스의 어떤 정보를 학습해야 할지 알 수 있기 때문에 성능이 향상됨
- 입력의 모든 Hidden status vector를 활용하기 때문에 Bottleneck problem 해결
- Encoding hidden status vector까지의 shortcut을 제공하기에 Gradient Vanishing Problem 해결
- 인코더 상의 어떤 단어에 집중했는지 알 수 있는 해석 가능성 (Interpretability) 제공
II. Beam Search
i. Greedy Decoding
단어를 예측할 때, 전체 문장에서 단어가 가지는 확률값을 보는 것이 아니라 현재 step에서 가장 확률이 높은 단어를 선택하는 방법.
- 잘못된 선택을 했을 경우 수정이 불가능함.
ii. exhaustive Search
단어를 예측할 때, 가능한 단어의 배열을 모두 탐색한 후에 가장 높은 확률을 가지는 단어를 선택하는 것
- 단어의 개수를 , 문장의 길이를 라고 가정했을 때, 만큼의 시간이 소요되기 때문에 비효율적임
iii. Beam Search
Greedy Decoding과 Exhaustive Search의 절충안으로, 매 time step마다 가장 확률이 높은 개의 candidate만을 고려하는 방법
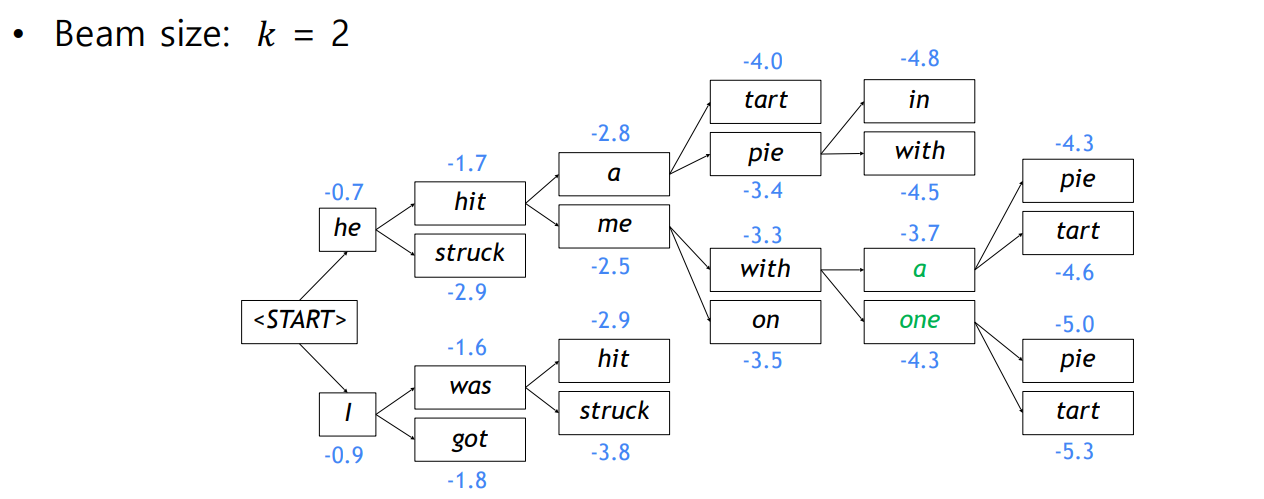
- Global optimum을 보장해주지 않지만, Exhaustive Search보다 효율적이다.
- End Token을 만나더라도, 별도에 공간에 저장해주고 탐색을 계속 진행한다.
Beam Search는 사전 설정한 time step에 도달했거나, hypothese가 일정 개수 이상 저장되었을 때 종료된다.
- 로그 확률은 음수로 표현되기 때문에, hypothesis가 길어질수록 점수가 필연적으로 낮아질 수밖에 없다.
- 따라서, score를 time step으로 나눈 평균값으로 최적의 hypothesis를 결정한다.
III. BLEU Score

i. F-measure
정밀도(Precision)과 재현율(Recall)의 조화평균
- Precision : 일치하는 단어의 개수 / Predicted sentence의 길이
- Recall : 일치하는 단어의 개수 / Reference sentence의 길이
- F-measure : Precision * Recall / 0.5 (precision + recall)
그러나 위 단위들은 단어의 순서를 고려하지 않는다.
가령 "Half my of hear in is Havana na na ooh"와 같은 단어를 예측했을 경우, 문법적으로 전혀 맞지 않는 문장이지만 이 기준들에 따르면 100%의 정밀도를 보여준다.
ii. BLEU (BiLingual Evaluation Understudy)
연속된 N개의 단어(N-gram)이 얼마나 겹치는지를 고려한 점수
- 언어의 특성에 따라 단어가 생략되는 경우가 발생하기 때문에 ground truth는 고려하지 않는다.
- 너무 짧은 문장에 대해서는 Brevity Penalty를 부여한다.
- Entire corpus에 대해 계산되며, 개별 문장에 대해선 대개 계산되지 않는다.

2. 과제
이번 주 필수과제에선 다음과 같은 작업을 진행하였다.
- 단어 토큰화, 불용어 처리, Corpus Class 생성
- RNN 모델로 문장 생성
- Subword로 토큰화된 Corpus과 RNN으로 문장 생성
3. 피어세션
이번 주 피어세션에서는 다음과 같은 문제를 제기하였다.
Q1.
batchify함수에선 단어를 column으로 배열하는데 그렇게 하는 까닭은 무엇인가?

A1.
가령 A를 입력으로 했을 때, 이에 대한 예측값으론 다음 문장인 B를 출력해야 한다. 그러나 만약 단어를 row로 배열했다면, B가 아닌 E를 예측하기 때문에 모델의 목적에 맞지 않는다.
Q2.
만약 Column으로 단어를 배열한다면, 한 번에 [A,G,M,S]를 입력으로 받게 되는데, A와 G는 서로 독립적인 단어이며, 배치 크기가 클수록 단어들의 독립성은 커진다. 이는 과거의 input을 고려하는 RNN의 취지에 맞지 않는 게 아닌가?
A2.
RNN은 batch_first라는 property를 가지기 때문에, 입력 벡터의 형태를 유동적으로 할 수 있다. 따라서 입력 단어를 행벡터로 표현하든, 열벡터로 표현하든 중요하지 않다.
(나중에 실험으로 증명해볼것)
Q3.
LSTM에서 Sigmoid대신에 Tanh를 Activation function으로 사용하는 까닭은?
A3.
Sigmoid 함수는 반복해서 사용할 수록 특정 값으로 수렴하는 경향이 있다. Tanh 함수는 그런 경향이 적다.
- sigmoid 함수를 반복적으로 사용했을 때

Sigmoid 함수를 세 번 거친 값은 0.6 근처로 수렴하는 것을 확인할 수 있다.
- Tanh 함수를 반복적으로 사용했을 때

Tanh 함수를 세 번 거친 값은 그 분포가 줄어들긴 하지만 그래도 일정 범위를 유지하는 것을 확인할 수 있다.
4. 1주차 회고
CV는 NLP와 달리 기본 베이스가 거의 없는 분야이다. 따라서 "전부 배웠던 것이네"하면서 자만하지 말고, 성실히 수업에 임하도록 하자.
- 강의만 보지 말고 실습도 해보면서 코드로 어떻게 구현했는지 확인해 보기
- Word2Vec과 Glove 논문을 읽으면서 python으로 한 번 구현해보기
- 게시글을 매일 작성하진 않더라도, 워드 파일로 매일의 강의내용 정리하기.
