0. 서론
나는 습관적으로 Ctrl+S를 눌러 파일을 저장한다. 보통 한 줄을 다 작성하고 나면 습관적으로 저장 단축키를 누르는데, 그럼에도 불구하고 이번 주에 약 세 네시간 정도 작성한 모든 주간정리 글이 증발해버렸다.
아직 작성하지 않은 글을 임시저장하면 "임시저장" 탭에 그 기록이 남지만, 작성된 글을 수정하면서 임시 저장을 한다면 그 기록이 임시저장 탭에 남지 않는다는 사실을 배웠다.
이번 주 학습 내용은 본인이 중요하다고 생각했기 때문에 정리한 게 날라갔더라도 한 번 더 회고하는 것에 그 의의를 두며, 이번 주엔 과제가 없었으며 피어세션에서도 많은 질문이 오가지 않았기 때문에 별도의 작성을 하지 않는다.
1. 학습정리
이번 주에는 크게 Transformer와 이를 베이스로 만든 BERT 모델에 관하여 학습했다.
1.1 Transformer
Transformer Model은 Encoder-Decoder 구조를 차용한다. Encoder에서는 입력 Sequence를 받아 sequence 내 단어와 단어 사이의 관계를 학습하고, Decoder는 학습된 encoding vector를 바탕으로 주어진 단어 다음에 어떤 단어가 나올 것인지 예측한다.
Transformer의 전반적인 구조는 다음과 같다.

Transformer model은 특정 time step 이전의 sequence만 고려하는 것이 아니라 모든 sequence를 학습에 사용하기 때문에, sequence 길이가 길어질수록 이전의 내용이 소실되는 RNN의 고질적 문제인 Long Term Dependency를 해결할 수 있다는 장점이 있다.
1.1.1 Encoder
1.1.1.1 Positional Encoding
Transformer Model이 가지는 여타 RNN과의 차이점중 하나는 특정 단어가 문장 내에서 가지는 상대적 위치를 고려하지 않는다는 것이다. 가령 "I go to school"이라는 문장과 "go I school to"라는 문장이 입력으로 주어졌을 때, 각 단어가 생성하는 hidden vector는 동일하다는 것이다. 그러나 두 번째 문장은 문법적으로 말이 되지 않으므로, 단어의 순서를 고려하지 않는 이런 학습법은 큰 단점으로 작용할 수밖에 없다.

이에 "sequence 내에서 단어가 가지는 상대적 위치"에 대한 정보를 가진 값을 input embedding vector에 더해주는 것으로, transformer가 단어의 순서를 고려하는 쪽으로 학습할 수 있도록 도와주는 장치가 바로 Positional Encoding 작업이라고 할 수 있다.
1.1.1.2 Multi-head Attention
Multi-head attention을 이해하기 위해서, 우선 Self-attention 구조를 이해할 필요가 있다.

입력벡터 에 곱해지는 가중치의 집합 를 attention head라고 한다. attention head를 통해 입력벡터 는 query vector (), key vector (), value vector (), 를 생성한다. 이때, query vector의 크기 ()와 key vector의 크기 ()는 동일해야 한다.
이후 query vector와 key vector를 내적하여 attention weight 를 구해준다. attention weight는 로 나눈 후에 softmax 연산을 거쳐 일종의 확률값으로 변환이 되는데, 로 나누는 까닭은 학습 시, 기울기(Gradient)값을 안정화 시키기 위함이다.
- 한 단어에서 나오는 attention weight는 scalar 값으로 표현되기에, 와 에 관한 정보를 포함하지 않는다.
가 커질수록 이에 비례하여 분산 역시 커지기 때문에, softmax 확률분포가 편향되는 것을 막기 위해 로 나눠준다.
최종적으로는 softmax 값을 value vector에 곱해, hidden vector를 생성한다.
Multi-head attention은 앞선 Self-attention을 attention head의 개수만큼 병렬적으로 실행하는 것이다.

각각의 self-attention의 결과값들은 하나의 matrix로 concat되며, 선형변환을 통해 최종 결과물을 산출한다. 이를 한 장의 그림으로 표현하자면 다음과 같다.

MHA는 동일한 문장을 다양한 측면에서 해석하는 효과를 가진다.
1.1.1.3 Add & Norm
MHA의 output vector와 input vector를 더하는 것을 residual connection이라 한다. 이를 위해서 input vector와 output vector의 크기가 일치해야 하며, 결과적으로 레이어를 깊게 쌓았을 때 발생하는 고질적 문제인 기울기 소실 문제(Gradient descending problem)를 예방할 수 있다.
Layer normalization은 한 레이어의 평균과 분산을 각각 (0,1)로 조정하는 작업으로, 보다 안정적인 학습을 가능하게 해준다. 이후 affine transformation 작업을 통해 학습된 값으로 최적의 평균과 분산으로 조정된다.

1.1.2 Decoder
1.1.2.1 Masked Multi-Head Attention
Decoder가 수행하는 작업은 전반적으로 Encoder와 유사하지만, Masked Multi-head attention을 우선적으로 실행한다는 차이점을 보인다.
가령 Decoder가 "I go home"이라는 문장을 출력하고 싶다고 가정해보자. 입력 토큰으로는 right shifted된 "<SOS> I go"를 받아야 한다.
"<SOS>" token은 그 다음 단어인 "I"를 생성해야 하는데, 만약 Encoder처럼 self-attention을 이용한다면, input sequence 내의 "I", "go"를 참조하게 되어 일종의 cheating이 발생한다.
따라서 특정 단어 이후에 나오는 단어들을 가린 채로 inference를 진행해야 하는데, 이를 Maksed multi-head attention이라고 한다.

Softmax로 변환된 Matrix에서 대각선 우측 위의 값들을 모두 0으로 조정한 후에, 각 row의 합을 1로 재조정한다.
이후, Add & Layer Normalization layer를 거친 후에는 기존 Encoder와 같은 작업을 수행하는데, MMA의 output을 query vector로, 앞선 Encoder의 output을 key vector와 value vector로 사용한다.
1.2 BERT
BERT는 Bidirectional Encoder Representations from Transformers의 약자이다.

BERT는 Pre-trained Language Model로, BERT에 추가적인 Network를 추가하는 것으로 classification, entailment 등 다양한 task를 수행할 수 있다. 즉, 문제 해결을 위한 모델이 아니라, 문제 해결의 성능을 높이는 데 도움을 주는 사전 학습 모델이다.
BERT는 크게 단어를 학습하는 pre-training 과정과, 학습한 지식을 이용하여 특정 task를 수행하는 model의 parameter를 재조정하는 fine-tuning 과정으로 나눌 수 있다.
1.2.1. Pre-training
BERT의 Pre-training 방법은 크게 Masked Language Model과 Next Sentence Prediction 두 가지로 분류할 수 있다.
1.2.1.1 Masked Language Model
MLM은 입력 단어의 약 15%를 [Mask] 단어로 치환하는 방법이다. 모델은 이 치환된 단어가 원래 무슨 단어였는지 맞추는 방식으로 학습을 진행한다.
그러나 inference 단계에서는 'Mask'단어가 없기 때문에 너무 많은 단어를 치환하면 정답을 맞추기 위한 충분한 정보가 제공되지 않는다. 따라서 선택된 15%의 단어의 80%만 'Mask'로, 10%는 전혀 관계 없는 단어로 치환하며, 나머지 10%는 그냥 내버려둔다.
전체 단어중 1.5% 단어는 변경되지 않았지만, 모델은 이 단어들이 치환된 단어인지 아니면 원래 단어인지에 대한 정보가 없기 때문에 학습이 가능하다.
1.2.1.2 Next Sentence Prediction
NSP는 두 문장을 주고, 두 문장이 서로 연속된 문장인지 아닌지를 학습하는 방법이다.

문장과 문장 사이와 문장의 끝에는 [sep] token을 넣어 두 문장이 서로 별개의 문장이라는 것을 분리하며, [CLS] token의 출력을 통해 두 문장이 연결된 문장인지 별개의 문장인지 유추한다.
위 사진에서 알 수 있듯이, MLM과 NSP는 동시에 진행된다.
1.2.1.3 Segment Embedding
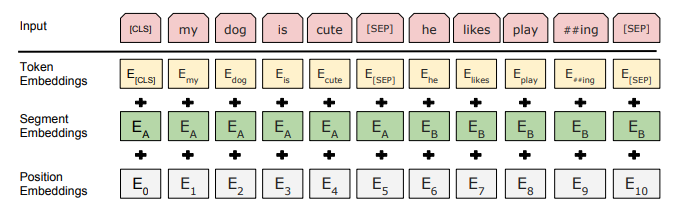
position embedding vector는 앞서 Transformer에서 언급했듯이, 문장 내에서 단어가 가지는 상대적 위치를 표현해주기 위한 값이다. 그러나 BERT는 두 가지 문장을 한 번에 학습하기에 position embedding vector만으로는 위치를 표현하는 데에 한계가 있다.
가령, 위 사진처럼 "my dog is cute"와 "he likes play ##ing"을 학습한다고 가정해보자. he는 두 번째 문장에서 첫 번째 단어지만, position embedding vector만을 사용했을 때에는 6번째 단어라고 mapping이 된다.
따라서 문장을 구분해주는 segment embedding vector를 통해, "이 문장은 두 번째 문장이다"라는 정보를 입력해주어야 할 필요가 있다.
1.2.2. fine-tuning
Fine-tuning은 사전 학습된 BERT 모델을 다양한 문제에 사용할 수 있도록 해주는 작업이다.
1.2.2.1. Sentence Pair Classification Task

이는 두 문장이 서로 어떤 관계에 있는지 푸는 문제이다.
[sep] token으로 구분된 두 문장을 입력으로 받으며, 앞서 언급한 것처럼 "두 문장이 서로 연결관계에 있는지" 혹은 "두 문장이 포함/모순/중립관계에 있는지" 등을 유추하는 것을 목적으로 한다.
출력 [CLS] token을 input으로 받는 model을 붙이는 것으로 문제를 해결한다.
1.2.2.1. Single Sentence Classification Sask

이는 한 문장이 어떤 카테고리로 분류되는지 푸는 문제이다. 앞선 Pair classification 문제와 달리 하나의 문장만을 입력으로 받는다.
마찬가지로 출력 [CLS] token을 input으로 받는 model을 붙이는 것으로 문제를 해결한다.
1.2.2.1. Question Answering Task

질문과 본문을 [SEP] token을 통해 분리한 sequence를 입력으로 받으며, 본문의 일부에서 값을 뽑아 문제에 대한 답을 찾는다.
1.2.2.1. Single Sentence Tagging Task

이는 각 단어가 어떤 품사를 가지는지, 혹은 어떤 개체의 속성을 가지고 있는지 등을 태깅하는 작업이다. 각 출력 토큰에 모델을 붙이는 것으로 값을 예측한다.
2. 회고
Language Model은 텍스트 데이터를 바탕으로 학습하기 때문에 CV에 비해 학습 데이터를 구하는 것이 쉽다고 생각했고 이를 어떻게 실생활에 응용할 수 있을지 생각해보는 계기가 되었다.
학원에서 보조강사를 할 때 학생들이 영어문제를 푸는 것에 큰 어려움을 겪었던 것을 떠올려, 영어 지문이 주어지면 가장 적절한 대답을 추론하는 모델을 만들고 싶다는 생각이 들었다.
3. 참조
그림 출처 :
http://jalammar.github.io/illustrated-transformer/ (attention module)
https://arxiv.org/pdf/1706.03762.pdf (transformer architecture)
부스트캠프 - 자연어 처리 Part 4 Transformer (Masked multi-head attention)
https://arxiv.org/pdf/1810.04805.pdf (BERT)
