.png)
0. 서론
NLP 두 번째 프로젝트도, 부스트캠프 총 일정도 벌서 절반에 다다랐다. 지난 주에 MRC, 그 중에서도 ODQA의 기본을 익혔다면, 이번 주에는 문제(task)를 풀 때 발생할 수 있는 문제(Problem)이나, 각종 추가적인 방법론 등을 중심으로 강의가 진행되었다.
1. 학습정리
I. Reducing Training Bias
머신러닝에서의 bias(편향)은 결국 학습의 결과로 나타나는 의도치 않은 부(?)작용, 혹은 이러한 결과를 이끌어내는 원인이라고 말할 수 있다.
편향이 항상 나쁜것만은 아닌데, 가령 어떤 모델을 만들고 싶다고 하자. 개발자는 특정 문제를 해결하기 위해 특정 결과를 도출해내는 모델을 만들 것이다. 이 경우, 모델은 "특정" 결과를 도출해내는 쪽으로 학습이 될 텐데, 이 역시 일종의 편향성을 가지고 있다고 말할 수 있다. (Inductive bias)
또한, 이런 편향은 현실세계에서도 매우 쉽게 발생한다. 현실세계가 편향되어있기 때문에 모델이 원치 않은 속성을 학습할 수도 있을 것이며(Historical Bias), 특징 간의 표면적 상관관계 때문에 원치 않는 속성이 학습될 수도 있을 것이다. (Co-occurence bias)
i. Gender Bias
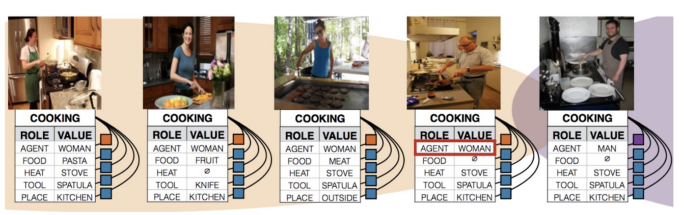
일반적으로 요리는 여성이 담당하는 경우가 많기에, 본 예시에서는 남성이 요리를 했음에도 불구하고 여성이 요리를 하고 있다는 결과가 도출되었다.
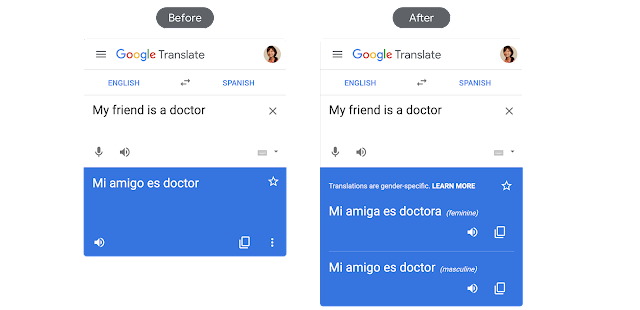
마찬가지로 전문직의 경우 남성이 더 많기에, 성별을 알 수 없는 명사(My friend)를 번역했을 경우에도, Mi amigo(남성)형으로 번역이 되었음을 확인할 수 있다. 구글 번역기는 남성형과 여성형을 모두 넣어주는 것으로 해당 문제를 해결하였다.
ii. Sampling Bias
통계를 배운 사람이라면 한 번은 들어봤음직한 이야기다. "The Literary Digest"라는 여론조사기관에서 1936년 미국 대통령으로 누가 당선될지에 관해 여론 조사를 한 적이 있다.
당시 표본 크기는 약 240만 명으로 역대 최대 규모였으며, 그 중 민주당의 루즈벨트(Franklin D. Roosevelt) 지지자는 43%, 공화당의 랜던(Alf Landon)의 지지자는 57%로 본사는 랜던의 당선을 예측하였다.
그러나 실제 결과는 루즈벨트가 62%, 랜던이 38%를 득표하여 미국의 32번째 대통령으로 당선되었다. 이는 표본 대상으로 잡지 정기구독자, 자동차 등록명부 등 경제적으로 여유가 있는 시민들을 선정해서 나온 결과인데, 경제적으로 여유가 있는 사람들은 공화당을 선호하는 경향이 있기 때문에 랜던의 지지율이 더 높게 나온 것이다.
본 사례는 표본을 추출할 때 발생할 수 있는 편향을 염두에 두고, 다양한 변수들을 고려해야 한다는 교훈을 준다.
여담
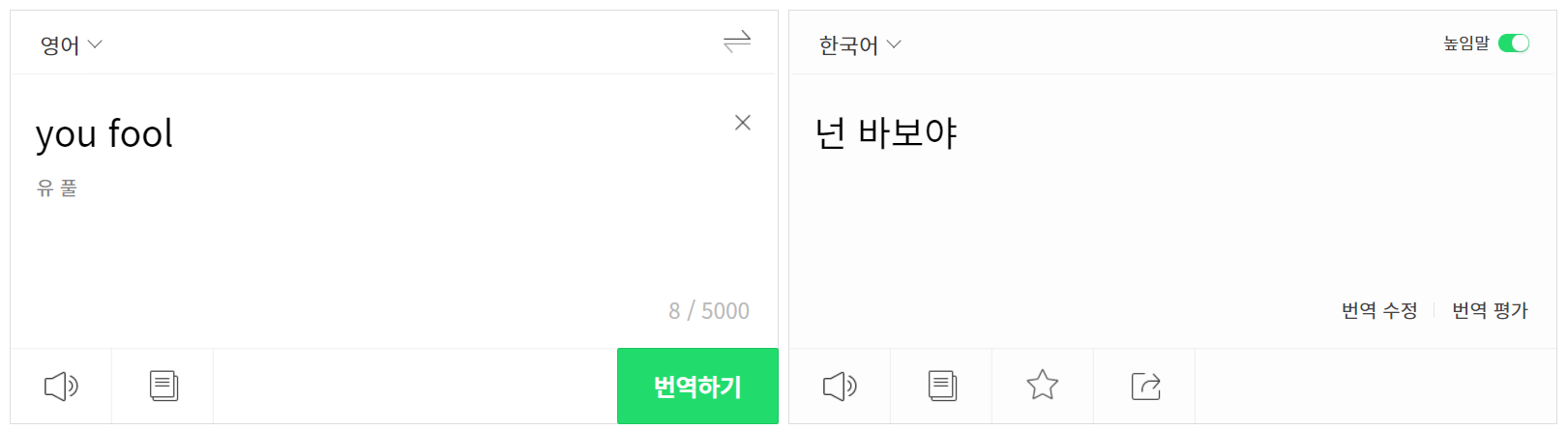
파파고에서 "you fool"이라는 문장을 번역했는데, 높임말 설정을 했음에도 불구하고 반말로 번역이 되었다. 욕설의 경우 낮춤말로 하는 경우가 많기에 이 또한 일종의 편향이라고 볼 수 있을까..?
iii. Bias in ODQA
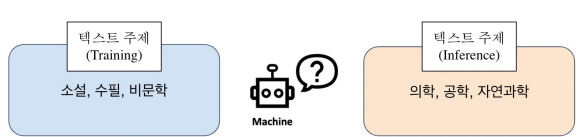
Retriever-Reader 모델에서, 만약 Reader 모델이 한정된 데이터셋에서만 학습된다면 편향된 값만을 도출할 가능성이 크다. 가령, Training Text data와 Test Text data의 주제가 다른 경우가 있다. [소설, 수필 비문학] 주제로 학습한 Reader model에 [의학, 공학, 자연과학]과 관련된 질문을 하는 경우에 잘못된 대답을 할 가능성이 크다.
Retriever
Retriever 모델은 Query vector와 Passage Vector의 유사도를 통해 Query와 가장 유사한 Passage를 도출해낸다. 비슷한 Query, Passage 쌍 사이의 거리를 줄어들게 학습하는 것 뿐만 아니라, 관련없는 쌍 사이의 거리를 증가시키도록 학습할 수 있다면 Retriever의 성능이 향상될 수 있다.
이처럼 관련없는 데이터까지 함께 학습하는 방법을 Negative Sampling이라 한다. 관련 없는 데이터를 선택할 때에는 (1) Corpus 내에서 무작위로 선택하는 방법과, (2) 높은 유사도를 지니지만 답을 도출할 수 없는 샘플을 선택하는 방법 등이 존재한다.
Reader
가령 올바른 Query와 Passage를 찾았다 하더라도, 답을 도출해 낼 수 없는 경우 또한 존재한다.
입력 시퀀스 맨 마지막에 한 개의 토큰(no answer bias)를 추가하여, start end 확률이 해당 bias 위치에 있을 경우 "대답할 수 없다"라고 취급하는 것으로, 답을 할 수 없을 경우 역시 대비할 수 있다.
Annotation Bias from datasets
Bias는 데이터셋을 만드는 단계에서도 발생할 수 있다.

위 문서는 wikipedia에 유희열을 검색했을 때의 결과의 일부이다. 만약 해당문서를 바탕으로 질문과 답을 만든다고 가정해보자. 예를 들어 "유희열이 중학교 1학년 때 처음 본 공연은 누구의 공연이었는가?"라는 문제와 "김창완 밴드"라는 정답을 만들 수 있을 것이다. 그러나 문서를 이미 알고 있는 상태에서, 해당 문서와 관련된 문제와 답을 만들려고 하면 문서와 최대한 비슷하게 만들어질 것이며, Annotator에 의한 Bias가 발생하게 된다.
해당 Bias를 줄이는 방법으로는 "Natural Questions"가 있다. 이는 Suporting Evidence가 주어지지 않은 상황에서, 실제 유저들의 질문을 바탕으로 Dataset을 생성하는 것이다.
또한, ODQA에 적용할 수 없는 bias가 데이터 제작 단계에서 발생할 수도 있다. 가령 "그가 기타를 처음 친 것은 언제인가?"라는 문제가 있다고 가정하자. "유희열"이라는 문서가 주어지지 않은 상황이라면, 문제의 "그"가 누구를 지칭하는 것인지 알 방법이 없다. 따라서 이를 인지하고 데이터를 모아야 한다.
II. Closed-book QA with T5

Retriever-Reader 모델은 query가 주어졌을 때, 이와 관련된 passage를 retriever를 통해 가져오고, passage 내에서 답을 찾는 모델이다.
Closed-book QA 모델은 retriever의 search 과정을 생략한다. 가령 BERT 학습 모델은 wikipedia + 데이터로 학습이 되기 때문에, 해당 모델이 이미 wikipedia 문서에 관한 지식을 충분히 저장하고 있다고 가정하고 바로 정답을 도출하는 것이다. 따라서, (1)지식 소스를 저장하기 어렵고, (2)문서를 찾는데 시간이 걸리는 Retriever reader 모델의 단점을 해결할 수 있다. 또한, 사전 학습에 본 적 없는 데이터에 관해서도 어느 정도 대답을 할 수 있다.
그러나 Closed-book QA 모델은 "사전학습된 언어 모델이 얼마나 지식을 잘 기억하고 있는지"가 매우 중요하다. 보다 많은 지식을 저장하기 위해서 (1) 필연적으로 모델의 크기가 커지고 계산량이 많아 속도가 느리며, (2) 모델이 어떤 과정으로 정답을 도출하는지를 해석하는 능력(interpretability)이 부족하다. 또한 (3) 모델이 참조하는 지식을 추가하거나 제거하는 것이 어렵다.
III. QA with Phrase Retrieval
Phrase Retrieval은 query vector와 유사한 문서를 document 단위로 받아오는 것이 아니라, Phrase 단위로 받아오는 것이다. 즉, "유희열이 중학교 1학년 때 처음 본 공연은 누구의 공연이었는가?"이라는 질문에 대해 앞선 유희열 문서 전체를 가져오는 것이 아니라, "김창완 밴드라는 Phrase를 가져오는 것이다.
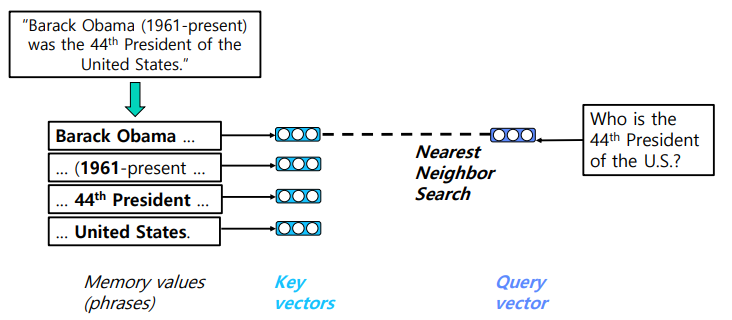
기존의 Retriever-Reader 모델에서는 Reader가 받아온 passage에서 정답 span을 계산하여 도출해야만 했다. 그러나 Phrase Retriever을 사용한다면 Reader가 정답을 도출해내는 과정 없이, Search 만으로 정답을 찾아낼 수 있을 것이다.
문제는 각 Phrase를 vector 상에 완벽하게 mapping하는 것이 굉장히 어렵다는 것이다. 이에 본 강의에서는 Sparse Embedding과 Dense Embedding을 복합적으로 사용하는 것을 제시한다.
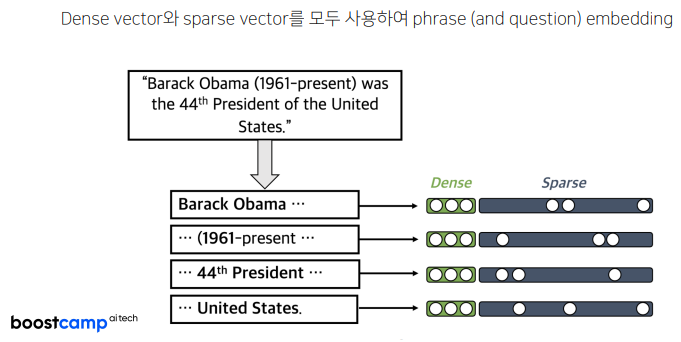
Dense Embedding
본 예시에서는 "The American library Association" 이라는 Phrase를 embedding하고자 한다.
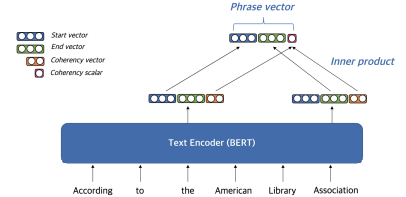
해당 Phrase는 "The"로 시작하고 "Association"으로 끝난다. Phrase의 시작과 끝을 start vector, end vector, coherency vector로 decompose 한 후에, Phrase 첫 단어의 start vector와 끝 단어의 end vector, 그리고 두 단어의 coherency vector의 내적값을 concat하여 최종적으로 Phrase Vector를 생성한다. coherency vector는 구(句)를 형성하지 않는(non-constituent) phrase를 걸러내기 위한 vector이다.
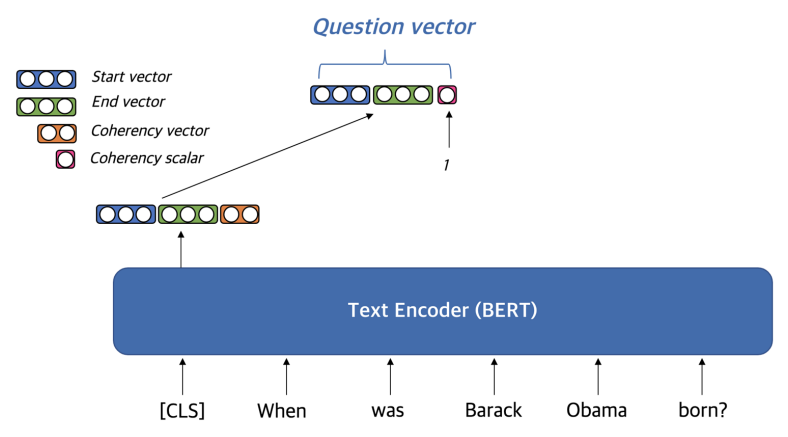
Question을 Embedding 할 때에는 embedding vector to [CLS] 를 사용한다.
의문
We fine-tune BERT to learn a -dimensional vector hi for encoding each token . Every token encoding is split into four vectors , where [,] is a column-wise concatenation. Then we obtain the dense start vector ai from and dense end vector from . Lastly, we obtain the coherency scalar from the inner product of and . The inner product allows more coherent phrases to have more similar start and end encodings. That is,
- Real-Time Open-Domain Question Answering with
Dense-Sparse Phrase Index
원문 내용을 저는 각 Embedded token을 4개의 벡터로 나눈다고 이해했습니다. 그러나 그림을 보면 3개의 벡터로 나누는 것처럼 확인이 되는데, 제가 이해를 잘 못한건지 왜 그림 상에는 저렇게 표현되는지 잘 모르겠습니다.
서민준 교수님의 답변
-
논문대로라면 4개의 벡터로 나누는 것이 맞다. 다만, 3개로 나눈 것과 4개로 나눈 것의 결과상의 차이가 뚜렷하지 않아서 좀 더 간소화된 3개로 나눈 것으로 강의를 진행하였다.
-
Query Embedding Vector의 Coherency Scalar도 마찬가지. 논문대로라면 4개의 벡터로 나눈 후, 3번째 벡터와 4번째 벡터의 내적을 통해 Coherency Scalar를 구해야 하지만, 1로 하더라도 큰 성능의 차이가 나타나지 않아 간소화하였다.
Sparse Embedding
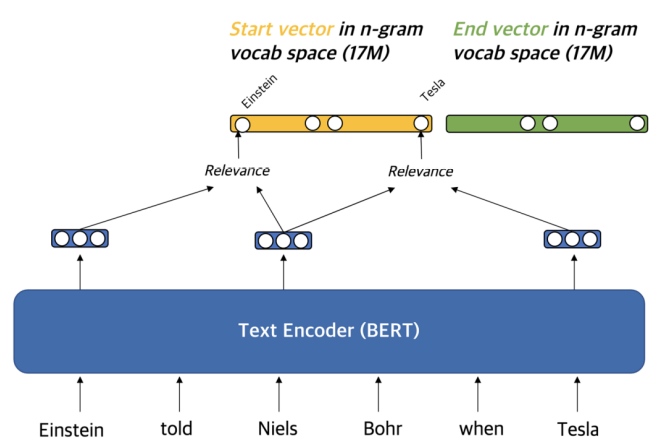
문맥화된 임베딩(contextualized embedding)을 활용하여 가장 관련성이 높은 n-gram으로 sparse vector 구성
한계
- 수 많은 양의 Phrase를 저장하고 빠르게 불러오기 위한 장비 필요
- 최신 Retriever-Reader 모델들 대비 낮은 성능
- Question과 Passage, Answer이 각각 Encoding되기 때문에 Question과 Passage 사이의 정보가 없음 (Decomposability gap)
2. 피어세션
이번 주에는 Retriever를 구현하는 것을 진행하였다. 처음엔 Sparse Retriever를 구현한 Base line code를 이해하고자 하였고, 이후 Special Mission으로 주어진 Dense Retriever Code를 이해하고 체화시키는 데 중점을 두었다.
I. Sparse Retriever
- Base Line의 Sparse Retriever에서 Tokenizer를
Bert-based-multilingual-cased에서KLUE/RoBERTa로 바꾸었더니 정확도가 오히려 떨어지는 것을 확인
II. Dense Retriever
-
5강 실습에 올라와있는 Passage(Query) Encoding Model은 "bert-base-multilingual-cased" 이고, 다른 모델로 바꿔보고 싶었지만 실패함
- BertModel은
BaseModelOutputWithPoolingAndCrossAttentionstype을 반환하는데, 그 중pooler_output을 우리가 학습에 사용한다. - 그러나 KLUE/RoBERTa는 output format이 BERT Model과 다르기 때문에 pooler layer를 따로 구현해주고 학습해줘야 한다. ->
BertModel을 쓰면 해결되는 듯? - 성능에 상관없이 일단 Dense Retriever를 구현하는 것이 1차적 목표기 때문에 모델을 바꾸는 것은 나중에 따로 하도록 한다.
- BertModel은
-
Batch size의 문제
- 전처리를 완료한 Dataset의 크기는 3952기 때문에 batch size를 3952의 약수로 해주어야 한다.
batch_size = 4의 경우 OOM 문제가 발생하며,batch_size = 3의 경우 3952의 약수가 아니기 때문에 input vector를 reshape 하는 과정에서 문제가 생긴다. 따라서batch_size = 2로 하여 실험 중- Dataset의 크기와 상관없이 general하게 batch_size를 조정할 수 있는 방법을 생각해봐야 할듯
-
dataset의 문제
wikipedia_document.json파일에는 약 5만 개의 unique document가 존재하지만, document encoder는 약 3천 개의 document밖에 학습하지 못했다. 이것 만으로 5만 개의 document 중에서 제대로 된 document를 뽑아낼 수 있을지 의문 :(
-
retriever validation 과정에서 positive sample 끼리의 cosine similarlity와 negative sample의 cosine similiarty를 구해서 둘을 비교함.
- retriever의 objective는 cosine similarity of positive sample은 높이고, that of negative ones는 최대한 낮추는 것.
- 즉, 두 metric 간의 거리를 최대화 시키는 것이 모델의 목적
- 그러나, 두 metric이 같이 올라가는 방향으로 학습이 됨
- positive sample의 cosine similarity가 증가하면, negative sample의 cosine similarity도 같이 증가하고, 감소하면 같이 감소한다.
torch.nn.CrossEntropyLoss함수 쓰지 말고 DPR 논문에 나온 Loss function을 직접 구현해서 써볼까...?- DPR 논문 제대로 읽고 한 번 해보자...📃
3. 회고
프로젝트 기간은 4주지만 벌써 2주가 마무리되었다. 시간 많이 남았다고 안주하지 말고 더욱 열심히 하자.
참조
학습정리 슬라이드:
Lecture 8: Reducing Training Bias (Minjoon Seo
Assistant Professor, Graduate School of AI, KAIST)
- Seo et al., 2019. Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index
- Karpukhin et al., 2020. Dense Passage Retrieval for Open-Domain Question Answering
- Lee et al., 2019. Latent Retrieval for Weakly Supervised Open Domain Question Answering
- Rajpurkar et al., 2016. SQuAD: 100,000+ Questions for Machine Comprehension of Text
- https://rajpurkar.github.io/SQuAD-explorer/explore/1.1/dev/Nikola_Tesla.html
Lecture 9: Closed-book QA with T5 (Minjoon Seo
Assistant Professor, Graduate School of AI, KAIST)
- Raffel et al., 2020, Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- Khashabi et al., 2020, UNIFIEDQA: Crossing Format Boundaries with a Single QA System
- Roberts et al., 2020, How Much Knowledge Can You Pack Into the Parameters of a Language Model?
- Petroni et al., 2019. Language Models as Knowledge Bases?
- Radford et al., 2019. Language Models are Unsupervised Multitask Learners
Lecture 10:
QA with Phrase Retrieval (Minjoon Seo
Assistant Professor, Graduate School of AI, KAIST)
- Lee et al., 2020, Contextualized Sparse Representations for Real-Time Open-Domain Question Answering
- Sel et al., 2019, Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index
- https://github.com/danqi/acl2020-openqa-tutorial/tree/master/slides: Lecture 5
- Lee et al., 2021, Learning Dense Representations of Phrases at Scal
thumbnail :
https://velog.io/@oneook/썸네일-메이커Thumbnail-Maker-Toy-Project
