Airflow Celery Executor
As of Airflow 2.7.0, you need to install the
celeryprovider package to use this executor. This can be done by installingapache-airflow-providers-celery>=3.3.0or by installing Airflow with theceleryextra:pip install 'apache-airflow[celery]'.
설정 관련
CeleryExecutor는 작업자의 수를 확장(scale out)하는 방법 중 하나. 이를 사용하려면 Celery 백엔드(RabbitMQ, Redis, Redis Sentinel 등)를 설정하고, 필요한 의존성(librabbitmq, redis 등)을 설치하며, airflow.cfg 파일에서 executor 매개변수를 CeleryExecutor로 변경하고 관련 Celery 설정을 해야한다. Celery broker 설정에 관한 자세한 내용은 Celery documentation on the topic 참조, Celery Executor 파라미터 설정에 관한 자세한 내용은 Configuration Reference 참조
DAG 폴더 접근 관련
worker는 자신의 DAGS_FOLDER에 접근할 수 있어야 하며, File System은 사용자가 직접 동기화해야 한다. 일반적인 설정으로는 DAGS_FOLDER를 Git 저장소에 저장하고 Chef, Puppet, Ansible과 같은 도구를 사용하여 환경 내의 머신 간에 이를 동기화하는 방법이 있다. 만약 모든 머신에 공통 마운트 지점이 있다면, 해당 위치에 파이프라인 파일을 공유하는 방식도 가능하다.
celery 명령어 관련
worker를 실행하기 위해서는, Airflow 설정을 하고 아래 명령어를 통해 worker를 실행할 수 있다.
airflow celery worker실행중인 worker를 멈추기 위해서는 아래 명령어를 실행. 이 명령어를 통해 SIGTERM 시그널을 보내 graceful stop을 진행한다.
airflow celery stopCelery Flower는 Celery 위에 구축된 웹 UI로, 작업자들을 모니터링할 수 있다. Flower 웹 서버를 시작하려면 다음 단축 명령어를 사용
airflow celery flowerairflow celery bundler을 설치하는 방법은 아래 명령어를 통해 가능하다
pip install 'apache-airflow[celery]'Architecture
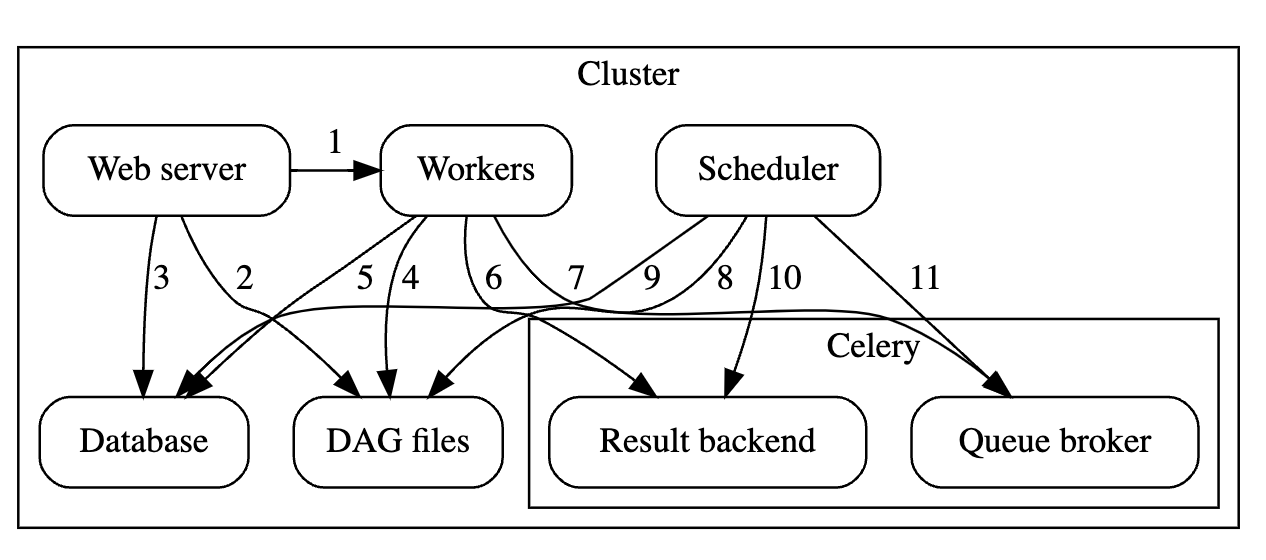
airflow’s components
- Workers - Execute the assigned tasks
- Scheduler - Responsible for adding the necessary tasks to the queue
- Web server - HTTP Server provides access to DAG/task status information
- Database - Contains information about the status of tasks, DAGs, Variables, connections, etc.
- Celery - Queue mechanism
celery’s components : two components
- Broker - Stores commands for execution
- Result backend - Stores status of completed commands
component 간의 communication
- [1] Web server –> Workers - Fetches task execution logs
- [2] Web server –> DAG files - Reveal the DAG structure
- [3] Web server –> Database - Fetch the status of the tasks
- [4] Workers –> DAG files - Reveal the DAG structure and execute the tasks
- [5] Workers –> Database - Gets and stores information about connection configuration, variables and XCOM.
- [6] Workers –> Celery’s result backend - Saves the status of tasks
- [7] Workers –> Celery’s broker - Stores commands for execution
- [8] Scheduler –> DAG files - Reveal the DAG structure and execute the tasks
- [9] Scheduler –> Database - Store a DAG run and related tasks
- [10] Scheduler –> Celery’s result backend - Gets information about the status of completed tasks
- [11] Scheduler –> Celery’s broker - Put the commands to be executed
task execution process
초기에는 두개의 프로세스가 실행
- SchedulerProcess – 이 프로세스는 작업을 처리하고 CeleryExecutor를 사용하여 작업을 실행
- WorkerProcess – 이 프로세스는 작업 큐를 관찰하고 새로운 작업이 나타나기를 기다림
- WorkerChildProcess – 이 서브 프로세스는 새로운 작업이 할당될 때까지 기다림
2개의 database도 사용됨
- QueueBroker
- ResultBackend
process를 실행하면서 두개의 프로세스도 생성된다
- LocalTaskJobProcess – 이 프로세스는 LocalTaskJob을 통해 작업 실행 로직을 처리. RawTaskProcess를 모니터링하고 TaskRunner를 통해 새로운 프로세스를 시작함.
- RawTaskProcess – 이 프로세스는 사용자 정의 코드를 실행. 예를 들어
execute()함수와 같은 작업 로직을 수행
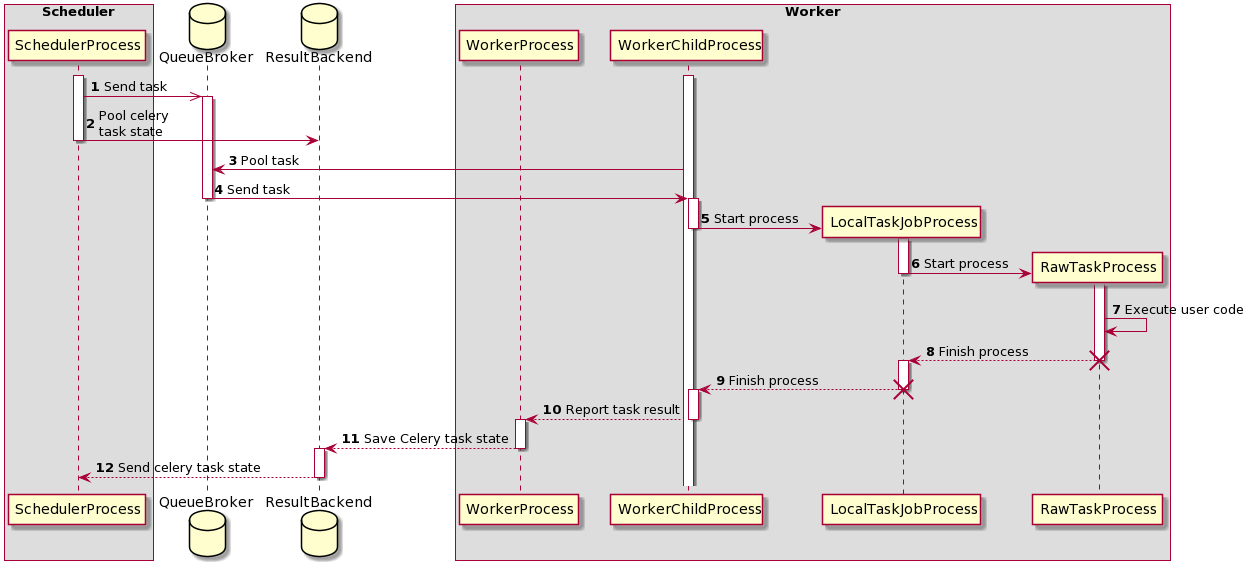
동작과정은 아래와 같다
[1] SchedulerProcess processes the tasks and when it finds a task that needs to be done, sends it to the QueueBroker.
[2] SchedulerProcess also begins to periodically query ResultBackend for the status of the task.
[3] QueueBroker, when it becomes aware of the task, sends information about it to one WorkerProcess.
[4] WorkerProcess assigns a single task to a one WorkerChildProcess.
[5] WorkerChildProcess performs the proper task handling functions - execute_command(). It creates a new process - LocalTaskJobProcess.
[6] LocalTaskJobProcess logic is described by LocalTaskJob class. It starts new process using TaskRunner.
[7][8] Process RawTaskProcess and LocalTaskJobProcess is stopped when they have finished their work.
[10][12] WorkerChildProcess notifies the main process - WorkerProcess about the end of the task and the availability of subsequent tasks.
[11] WorkerProcess saves status information in ResultBackend.
[13] When SchedulerProcess asks ResultBackend again about the status, it will get information about the status of the task.
Queues
CeleryExecutor를 사용할 때, 작업이 전송될 Celery 큐를 지정할 수 있다. 큐는 BaseOperator의 속성으로 모든 작업은 원하는 큐에 할당될 수 있고, 기본 큐는 airflow.cfg의 operators -> default_queue에 정의된다. 이 설정은 각 task의 큐가 특정되지 않은 경우 할당되는 큐를 정의한다. (현재 띄워져 있는 airflow의 airflow.cfg 파일을 확인해보니 default_queue = default로 설정되어 있다.)
worker는 하나 이상의 큐를 연결할 수 있고, 작업자가 시작될 때(airflow celery worker 명령어 사용), 쉼표로 구분된 큐 이름 목록(공백 없음)을 지정할 수 있다(예: airflow celery worker -q spark,quark). 그러면 이 worker는 지정된 큐에 들어온 작업을 처리한다.
이 설정은 리소스 관점(예: 아주 가벼운 작업의 경우 하나의 작업자가 수천 개의 작업을 문제없이 처리할 수 있는 경우)이나 환경 관점(예: 매우 특정한 환경과 보안 권한이 필요한 작업이 있기 때문에 Spark 클러스터 내에서 작업자가 실행되도록 설정하고자 하는 경우)에서 유용하다.
정리
- Celery는 실행할 command를 저장하는 broker와 완료된 command의 상태를 저장하는 Result backend로 구성돤다. (Message Queue는 포함되지 않기에, 위에 언급된 Celery 백엔드와 같이 Message Queue인 RabbitMQ, Redis, etc 중에서 선정하여 설치해주어야 한다.)
- Celery Executor로 airflow를 설치할때 각 component가 어떻게 동작하는지 알 수 있었음
- task를 실행할 때, scheduler와 Celery Executor worker 사이 동작과정을 알 수 있었음. 특히 worker에서 task를 실행할 때 여러 프로세스(WorkerProcess, WorkerChildProcess, LocalTaskJobProcess, RowTaskProcess)로 작업이 처리됨을 알 수 있었다.
- WorkerProcess는 하나의 task를 받으면 이를 하나의 WorkerChildProcess에 할당
- WorkerChildProcess는 task handling functions인
execute_command()를 실행. 새로운 프로세스인 LocalTaskJobProcess을 생성한다. - LocalTaskJobProcess의 **로직은
LocalTaskJob** 클래스에 의해 정의됨. TaskRunner를 통해 새로운 process를 실행한다. - RowTaskProcess는 task code를 실행한다.
- LocalTaskJobProcess와 RowTaskProcess은 자신의 일이 끝나면 종료된다.
- 각 worker가 연결(정확히는 listen)할 Queue를 정의할 수 있다. 이때 Queue는 worker가 수행해야하는 작업을 넣기 위해 사용된다. 이를 통해 특정 task를 특정 worker에서 실행할 수 있도록 한다.
