Airflow란
Apache Airflow is an open source platform to programmatically author, schedule, and monitor workflows.
Apache Airflow는 프로그래밍 방식으로 워크플로우를 작성, 예약 및 모니터링하는 오픈 소스 플랫폼입니다.
Airflow 구성요소 흐름
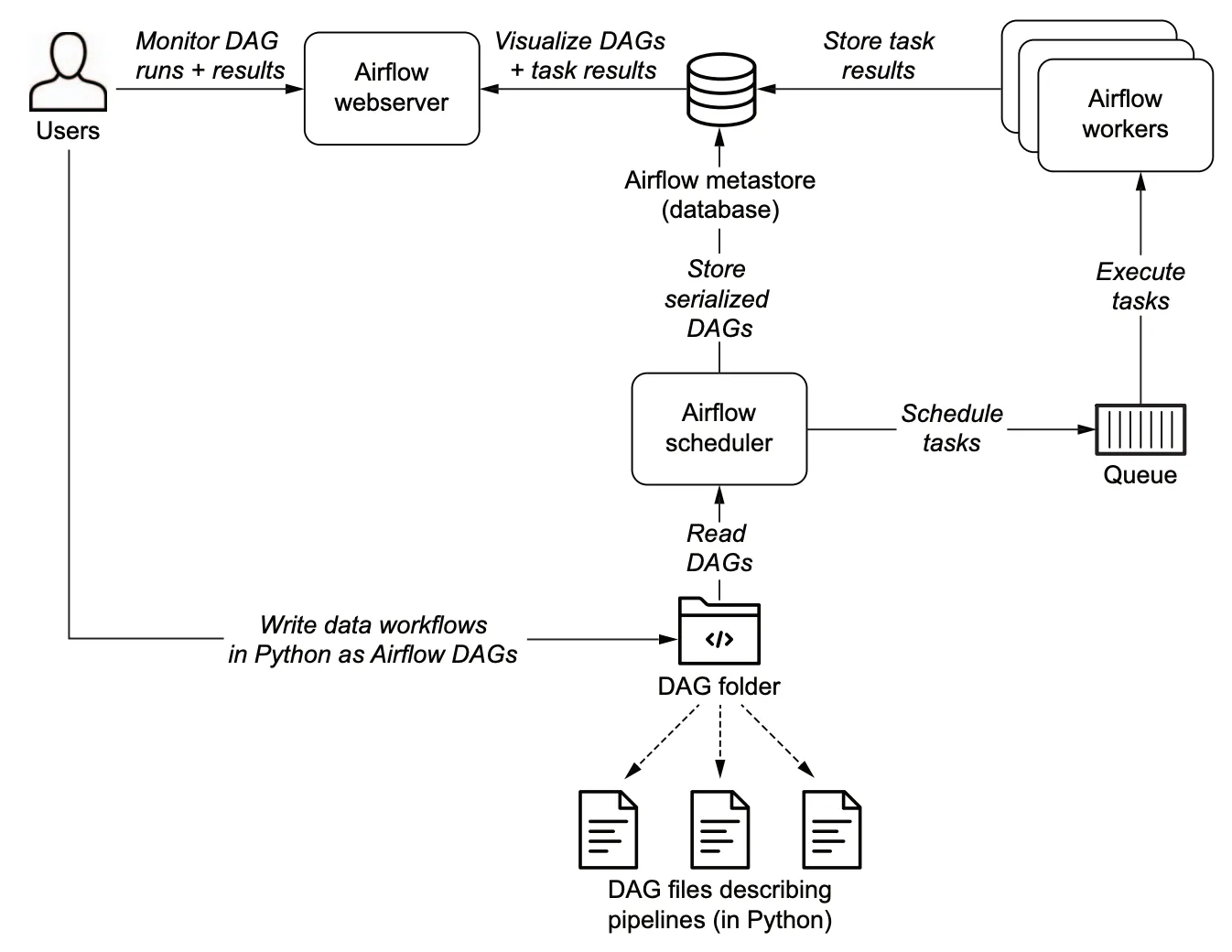
- Web Server : Airflow의 웹 인터페이스를 제공하는 웹 서버.
- MetaStore(MetaDB) : 메타데이터가 저장되는 데이터베이스. 주로 PostgresSQL을 추천하지만, SQL Alchemy와 호환 가능한 MySQL이나 SQLite도 이용가능
- Scheduler : Workflow를 스케줄링. DAG를 분석하고, 실행될 수 있도록 Queue에 task 예약
- Worker : 실제 task를 실행. Queue에서 task를 가져와 실행시킴
Airflow Architecture
Components
Airflow의 아키텍처는 여러 구성 요소로 이루어져 있다. 아래 내용은 각 구성 요소의 기능과 해당 구성 요소가 airflow 설치를 위해 무조건 설치해야하는 컴포넌트인지, 아니면 Airflow의 scalability, extensibility, performance를 더 높이기 위한 선택할 수 있는 컴포넌트인지를 설명한다.
Required components
- Scheduler : 스케줄링된 workflow를 트리거하거나 executor에게 task를 실행할 수 있도록 전달한다. basic installation에서 executor는 scheduler에 포함된다. 따라서 executor는 scheduler process 내에서 실행된다. 기본적으로 여러 종류의 executor가 제공되며, executor를 직접 작성하여 사용할 수도 있다
- webserver : dag와 task를 확인할 수 있도록 user interface를 제공
- a folder of DAG files : scheduler가 어떤 task를, 언제 실행할지 알기 위해 분석하는 파일들
- a metadata database : airflow component들이 워크플로우와 task의 상태를 저장하기 위해 사용하는 컴포넌트. 자세한 세팅관련 글은 Set up a Database Backend 에서 확인할 수 있다
Optional components
아래 컴포넌트들은 extensibility, scalability, performance을 위해 옵션으로 설치할 수 있는 컴포넌트들이다.
- worker : scheduler를 통해 받은 task를 실행하는 컴포넌트. 기본 설치를 하면 worker는 scheduler의 일부로 포함된다. CeleryExecutor를 통해 long running process로 worker를 실행할 수 있고, 또는 KubernetesExecutor를 통해 POD 형태로 worker를 실행할 수 있다.
- trigger : asyncio event loop에 있는 deferred tasks를 실행한다. 기본 설치에서는 deferred tasks가 사용되지 않고, 따라서 trigger는 필요하지 않다. deferring tasks에 관한 내용은 Deferrable Operators & Triggers에서 확인할 수 있다
- dag processor : DAG 파일들을 분석하고 metadata database에 그들을 serializes한다. 기본적으로 DAG processor 프로세스는 스케줄러의 일부이지만, scalability과 security 이유로 별도의 컴포넌트로 실행할 수 있다. 만약 dag processor가 존재한다면, scheduler는 DAG file들을 읽을 필요가 없다. 더 많은 DAG files의 processing에 관한 내용은 DAG File Processing 에서 확인할 수 있다.
- folder of plugins : plugin은 airflow의 기능을 확장하기 위해 사용된다. 패키지를 설치하는것과 비슷한 개념. scheduler, dag processor, triggerer and webserver가 plugin을 읽어 사용한다. plugin에 더 많은 내용은 Plugins 참조.
Deploying Airflow components
모든 컴포넌트들은 python application이다. 추가로 패키지를 설치할 수 있으며, 이는 custom operators or sensors를 설치하고 custom plugin을 통해 airflow 기능을 확장하기에 좋다
Airflow는 단일 머신에서 실행되거나 스케줄러와 웹 서버만 배포되는 간단한 설치로 실행될 수 있지만, Airflow는 확장성과 보안을 염두에 두고 설계되어 Airflow는 분산 환경에서의 실행도 가능하다. 여러 machine에서 다양한 components가 동작할 수 있으며, 각기 다른 보안 경계 내에서 실행될 수 있다. 또한 위에 언급된 구성 요소의 여러 인스턴스를 실행하여 확장할 수도 있다.
components의 분리는 각 구성 요소를 서로 격리하고 서로 다른 작업을 수행할 수 있게 함으로써 보안을 강화할 수 있다. 예를 들어 DAG 프로세서를 스케줄러와 분리하면 스케줄러가 DAG 파일에 접근하지 못하게 하고, DAG 작성자가 제공한 코드를 실행하지 못하도록 보장한다.
또한 한사람이 airflow 설치를 실행하고 관리할 수 있지만, 더 복잡한 설정에서는 여러 사용자가 다양한 역할을 담당할 수 있도록 한다. 이를 통해 시스템의 각 component와 상호작용할 수 있고, 이는 Airflow deployment의 보안 측면에서 중요하다. 역할에 대한 자세한 내용은 Airflow Security Model에 기재되어 있으며, 일반적으로 아래와 같다.
- Deployment Manager - a person that installs and configures Airflow and manages the deployment
- DAG author - a person that writes DAGs and submits them to Airflow
- Operations User - a person that triggers DAGs and tasks and monitors their execution
💡 근데 basic installation으로 단일 머신에 airflow를 설치하더라도 위 3개의 역할로 나누어 담당할 수 있을거 같음
Architecture Diagrams
아래 다어이그램들은 다양한 Airflow 배포 방법에 대해 설명한다. 단순한 "단일 머신" 및 한 사람이 관리하는 배포 방식에서 점차적으로, 구성 요소가 분리되고 사용자 역할이 구분되며, 최종적으로 더 격리된 보안 경계를 갖는 더 복잡한 배포 방식으로 발전할 수 있다.
아래 다이어그램에서 다양한 connection type은 아래와 같다.
- brown solid lines represent DAG files submission and synchronization
- blue solid lines represent deploying and accessing installed packages and plugins
- black dashed lines represent control flow of workers by the scheduler (via executor)
- black solid lines represent accessing the UI to manage execution of the workflows
- red dashed lines represent accessing the metadata database by all components
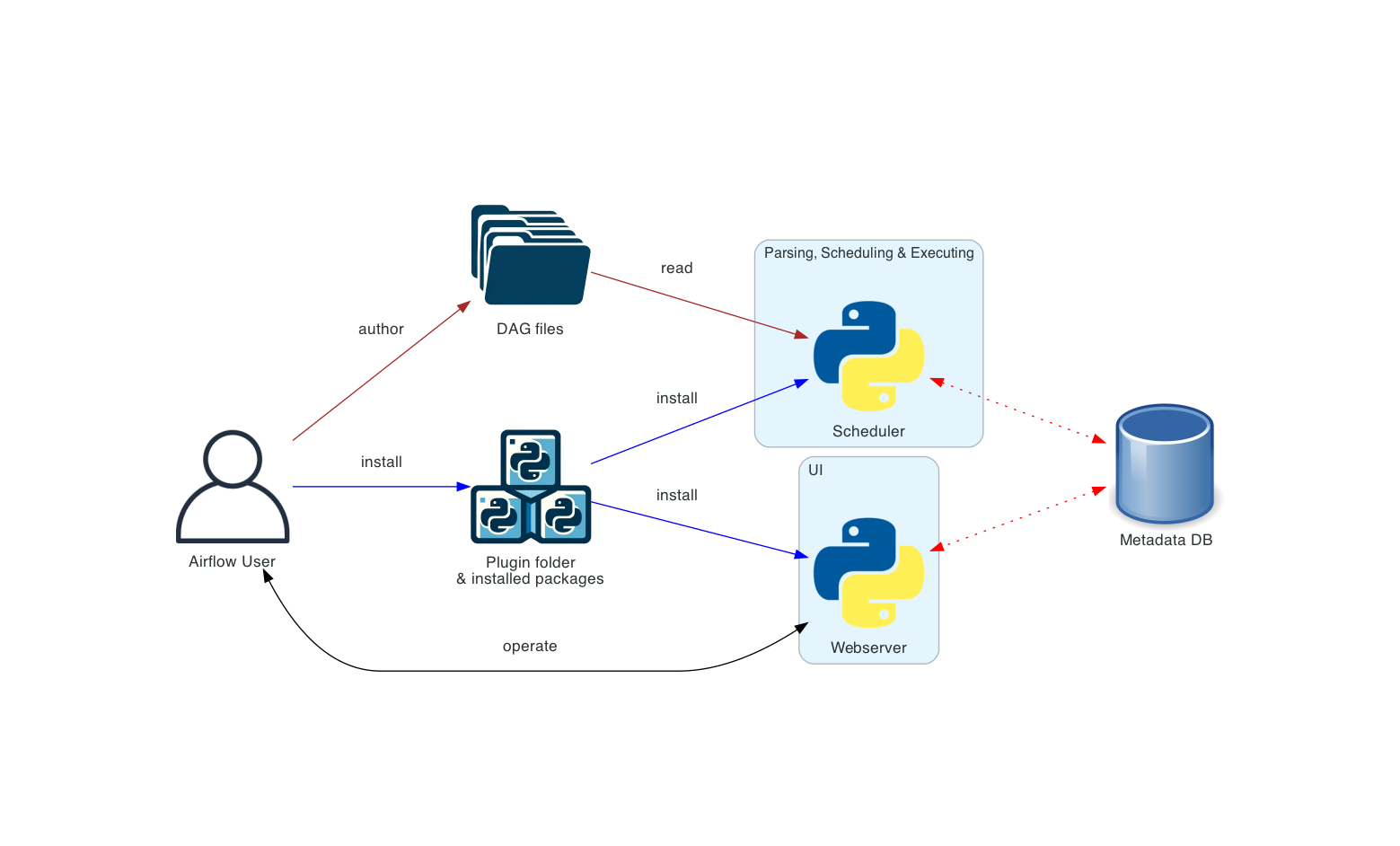
Basic Airflow deployment
가장 단순한 방법. 이 배포 방법은 보통 LocalExecutor을 사용하고, 이는 scheduler와 workers가 같은 python process에 있고(worker가 scheduler component에 포함되어 있음), scheduler가 File System에서 DAG 파일들을 직접 읽는다. webserver는 scheduler가 설치된 같은 machine 안에서 동작한다. triggerer component는 따로 없으며, 이는 작업 연기(task deferral)가 불가능함을 의미한다.
이러한 설치는 user role을 분리하지 않는다. deployment, configuration, operation, authoring and maintenance 작업들이 한 사람의 의해 행해지고, 컴포넌트 사이에 보안 경계도 없다.
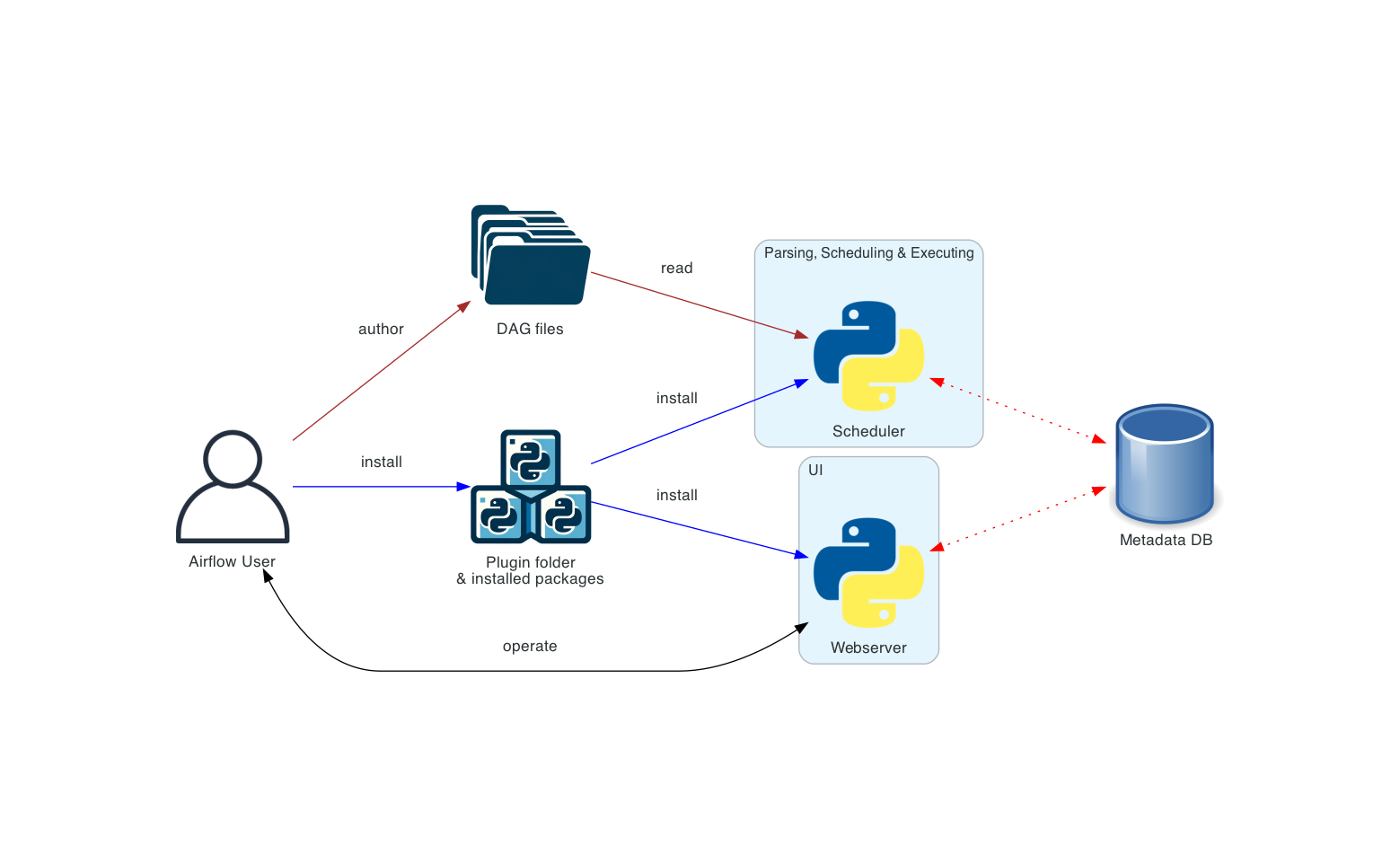
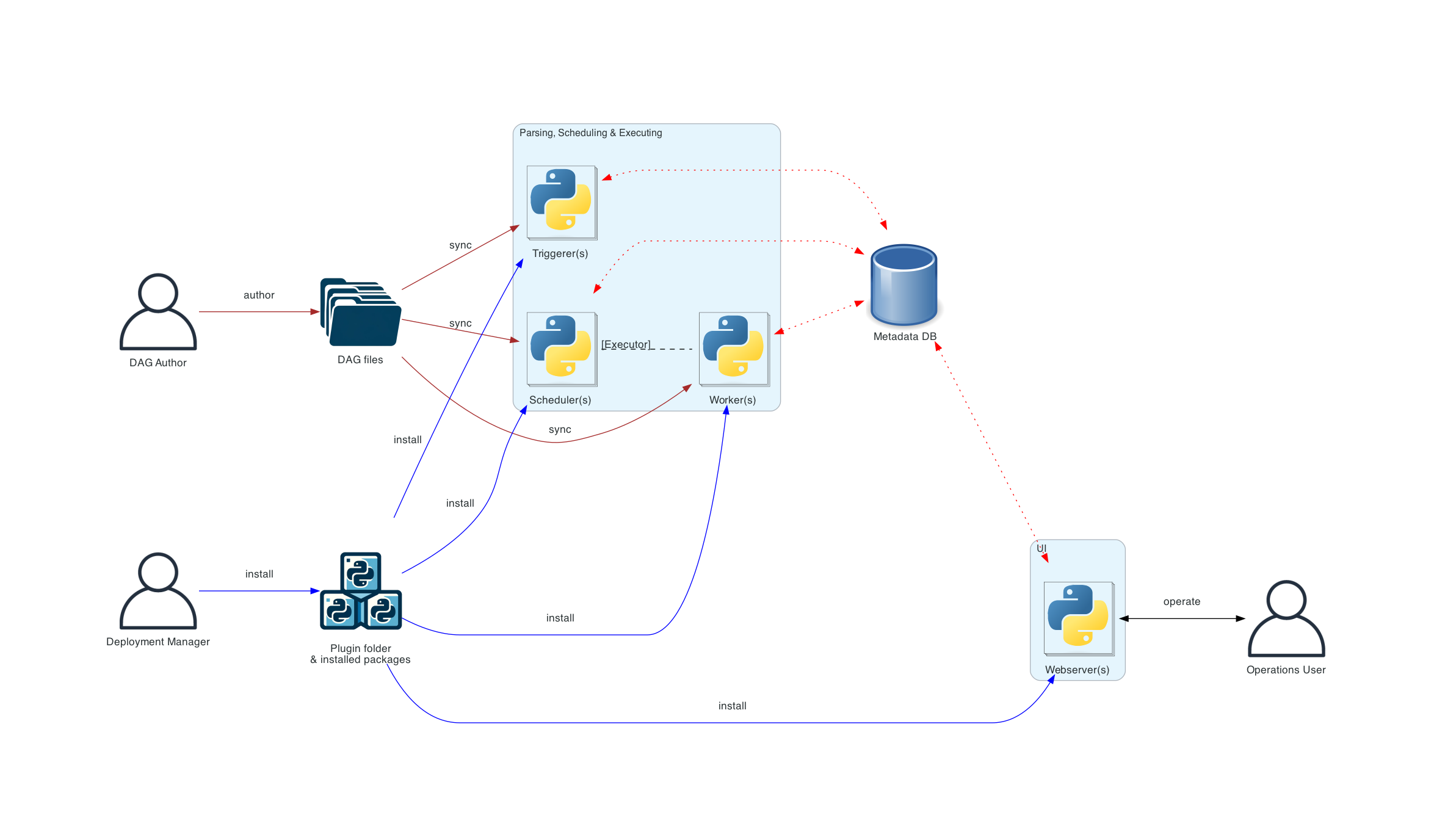
Distributed Airflow architecture
여러 machine에 airflow를 설치할 수 있으며 Deployment Manager, DAG author, Operations User와 같은 여러 사용자 롤을 도입할 수 있는 방법. 더 다양한 역할에 대해서는 Airflow Security Model을 권장.
이 방식의 경우 컴포넌트들의 보안을 고려하는 것이 중요하다. webservers는 DAG를 직접 읽지 않는다. UI의 Code 탭의 코드는 metadata database를 통해 읽어온다. webserver는 DAG author가 작성한 코드를 실행(execute)할 수 없다. (오직) Deployment Manager가 설치한 패키지나 플러그인으로 설치된 코드를 실행할 수 있으며, Operations User는 UI에 대한 접근만 가능하고 DAG와 task를 trigger만 할 수 있다. 즉 DAG는 작성하지 못한다.
💡 webserver에서 dag를 왜 수정하지 못하게 되어 있을까 생각했는데(수정할 수 있으면 굉장히 편리할거 같았음) 이런 role 구분을 위해 그렇게 만들었다는 것을 알 수 있었다.
DAG files는 모든 컴포넌트 간에 동기화되어야 한다. DAG files를 동기화하는 여러 방법이 있는데 가장 전형적인 방법은 Manage DAGs files 에 소개되어 있듯이 Helm chart를 사용하는 것이다. Helm chart는 k8s cluster 내에서 airflow를 배포하는 방법 중 하나이다.
Separate DAG processing architecture
보안과 격리가 중요한 더 복잡한 설치 환경에서는 스케줄러가 DAG 파일에 접근하지 못하도록 분리할 수 있도록 독립형 DAG 프로세서(DAG Processor) 구성 요소를 사용할 수도 있다. Airflow는 multi-tenant 기능을 지원하지는 않지만, DAG author가 작성한 코드가 scheduler 측에서 실행되지 않도록 할 수 있다. 즉 기존에 dag파일을 파싱한 후 이를 스케줄링 작업을 scheduler가 했는데, DAG Processor를 설치하면 dag 파일을 파싱하는 작업을 DAG Processor에게 할당하고 scheduler는 dag 파일을 직접적으로 읽지 않도록 할 수 있음.
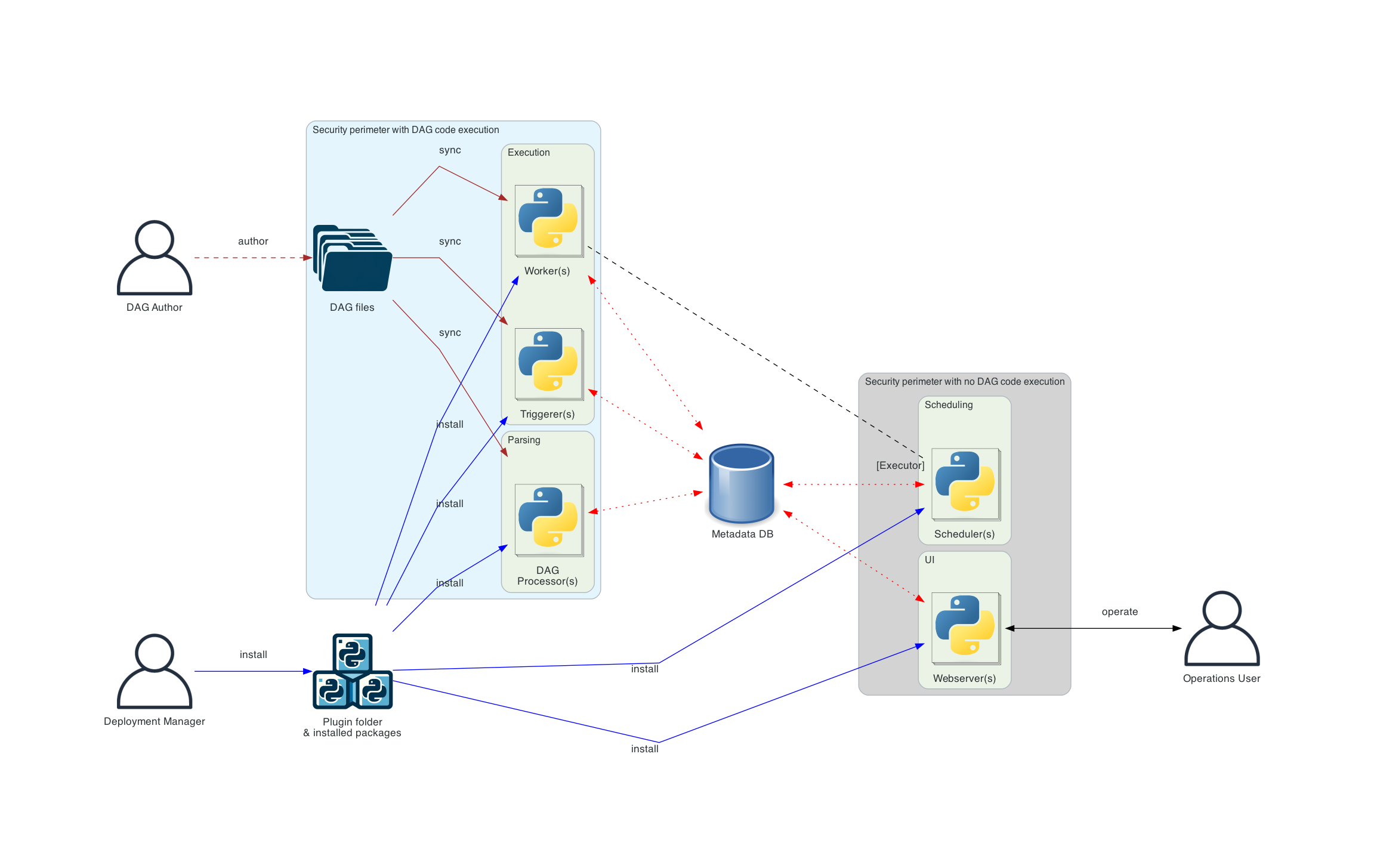
💡 개인적으로 worker도 dag file에 직접 파일을 읽어들이지 않고 db에 있는 데이터를 가져와서 코드를 실행할 수는 없나 생각이 든다. 아마 스케줄링할때는 dag file 중 스케줄링 관련한 내용한 가져와서 사용하면 되기에 metadata DB를 사용할 수 있는거겠지? 그렇다면 dag file을 worker가 직접 읽어야 하긴 하겠다. 코드가 길어지고 파일구조가 복잡해질수록 DB에 넣는게 어려울 테니깐…
metadata DB에 어떤 데이터가 들어가는지 확인해보면 좋겠다.
Workloads
task 타입으로 아래 3가지가 존재
- Operators, predefined tasks that you can string together quickly to build most parts of your DAGs.
- Sensors, a special subclass of Operators which are entirely about waiting for an external event to happen.
- A TaskFlow decorated
@task, which is a custom Python function packaged up as a Task.
내부적으로 이들은 모두 Airflow’s BaseOperator의 subclass이고, task와 operator의 개념은 어느정도 교환 가능(interchangeable)하다. 하지만 이를 다른 개념이라고 생각하는 것이 더 좋다. Operators와 Sensors는 템플릿 개념이며, DAG 파일에서 이를 호출할때 task를 생성하게 된다. (즉 task는 인스턴스 개념)
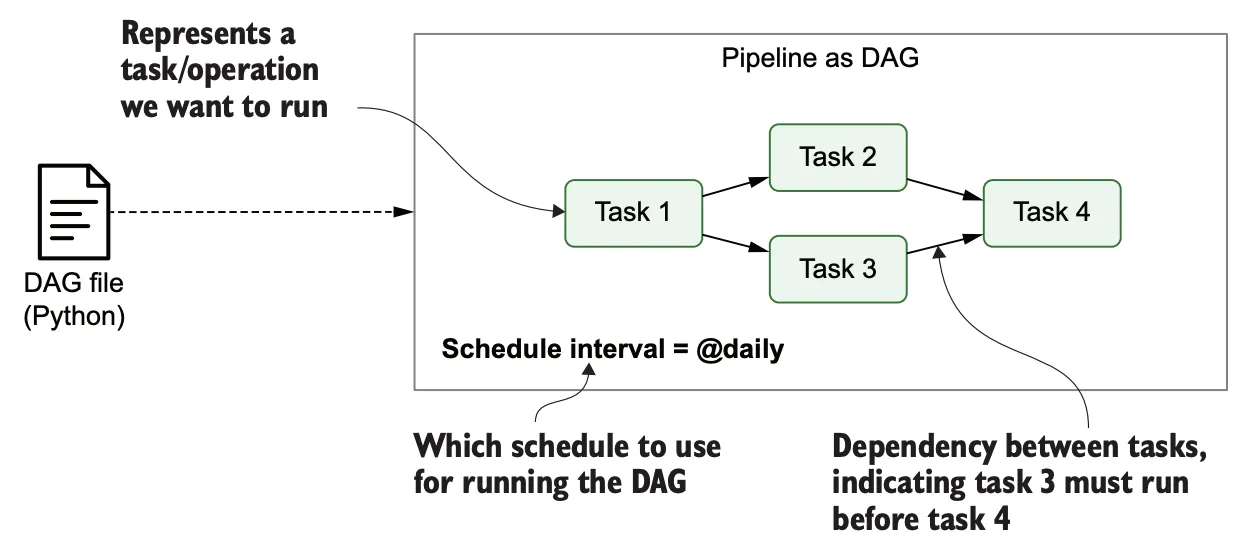
Control Flow
task는 서로 dependencies를 갖는데, 아래 2가지 방법을 통해 정의 가능하다
-
>>와<<기호를 통해 dependencies 정의first_task >> [second_task, third_task] fourth_task << third_task -
set_upstreamandset_downstream함수를 통해 dependencies 정의first_task.set_downstream([second_task, third_task]) fourth_task.set_upstream(third_task)
upstream task가 진행된 후 downstream이 진행될 수 있지만 Branching, LatestOnly, and Trigger Rules 기능을 통해 이를 커스텀마이징할 수 있다. Branching은 조건에 따라 다른 경로를 선택하게 하고, LatestOnly는 가장 최신 실행만 허용하며, Trigger Rules는 Task 실행 규칙을 설정하는 데 사용됩니다.
데이터를 task간에 교환하기 위해서 아래 3가지 방법이 있다.
- XComs (“Cross-communications”), a system where you can have tasks push and pull small bits of metadata.
- Uploading and downloading large files from a storage service (either one you run, or part of a public cloud)
- TaskFlow API automatically passes data between tasks via implicit XComs
airflow는 task를 실행하기 위해 가용할 공간이 생긴 worker에 보낸다. 따라서 한 DAG 내에 있는 모든 task가 같은 worker 또는 같은 machine 내에서 실행된다는 보장이 없다.
DAG를 작성하다 보면 굉장히 복잡해질 수 있는데, airflow는 좀 더 효율적으로 관리할 수 있는 여러 메커니즘을 제공한다. SubDAGs는 다른 DAG에 포함할 수 있는 "재사용 가능한" DAG를 생성하고, TaskGroups은 UI에서 시각적으로 task를 그룹화한다.
또한, 데이터 저장소와 같은 중앙 리소스에 쉽게 사전 구성된 액세스를 제공하기 위한 Connections & Hooks,
그리고 limiting concurrence을 위한 Pools 을 제공한다.
Airflow의 특징 및 주의점
특징
- python을 사용하여 DAG 정의
- 테스크간의 의존성, 순서 정의, 리소스 등을 자유롭게 정의하고 처리 가능
- 데이터 처리 관계를 직관적으로 표현
- 배치 지향 데이터 파이프라인을 구현하는데 적합
주의점
- 스트리밍 워크플로우에는 맞지 않다. 실시간 데이터를 처리하는 용도가 아님. Airflow는 반복적, 배치 테스크에 적합
- 대용량 데이터 처리보다는 데이터처리 프로세스를 관리하는 용도에 적합. (spark 같은 툴보다 느림)
