MLflow 기능 중 가장 중점 기능인 실험 트래킹 기능에 대해 소개한다.
실험 트래킹
모델 실험과 관련된 정보들을 저장하고 이를 추적할 수 있게 하는 기능. 관련된 mlflow 함수는 https://mlflow.org/docs/latest/ml/tracking/tracking-api/ 에서 확인하면 된다.
실험 태그 기록
mlflow.set_experiment_tags()를 통해 학습 프로젝트 단위로 태그를 달거나, mlflow.set_tags()를 통해 학습 run 단위로 태그를 달 수 있다. 사실상 학습 프로젝트 단위로 태그를 다는 횟수는 빈번하지 않을것이기에 mlflow UI를 통해 태그를 달고, 학습을 run할때는 학습 코드시 mlflow.set_tags()를 통해 태그를 다는 것이 좋을 듯.
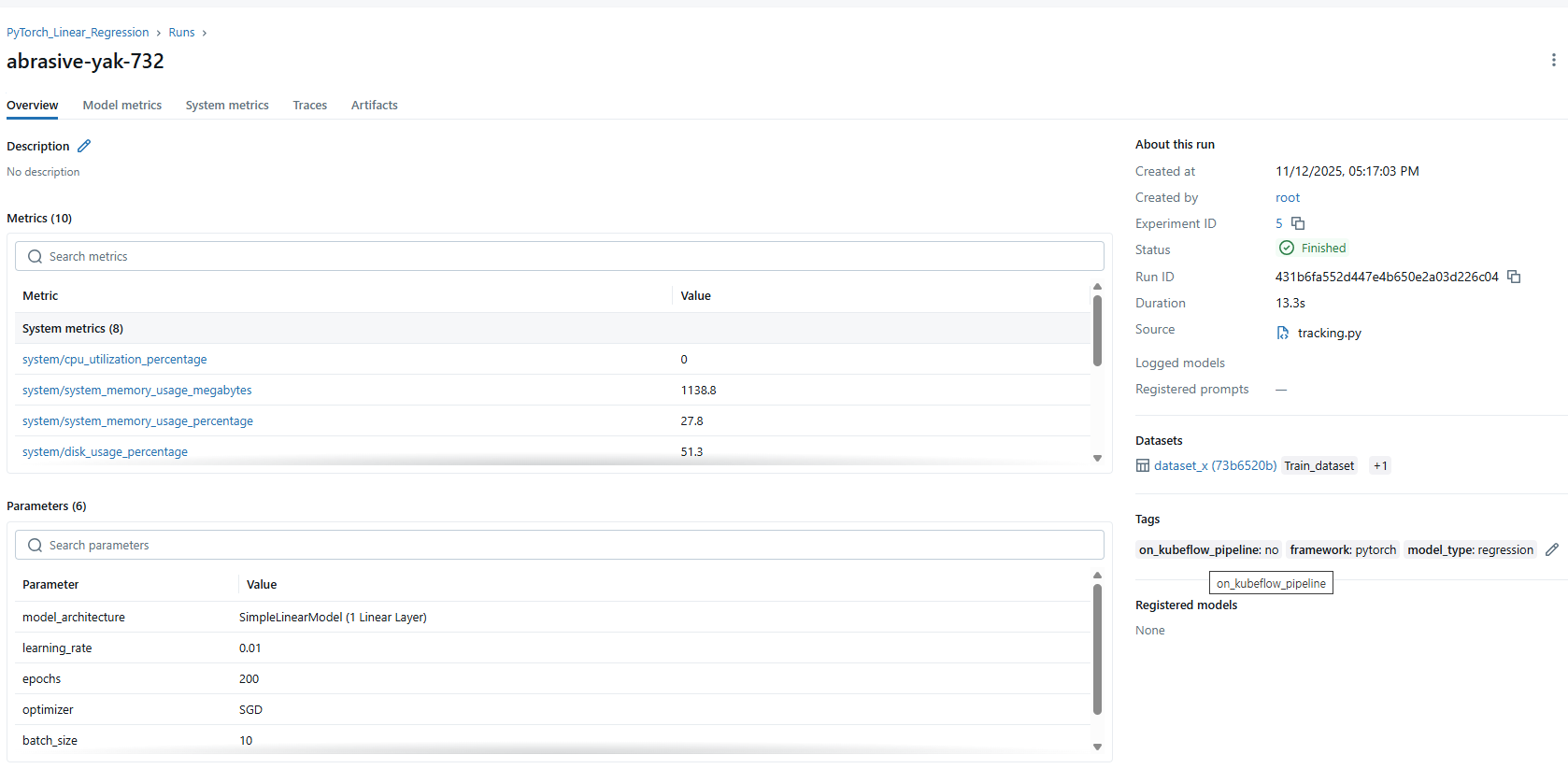
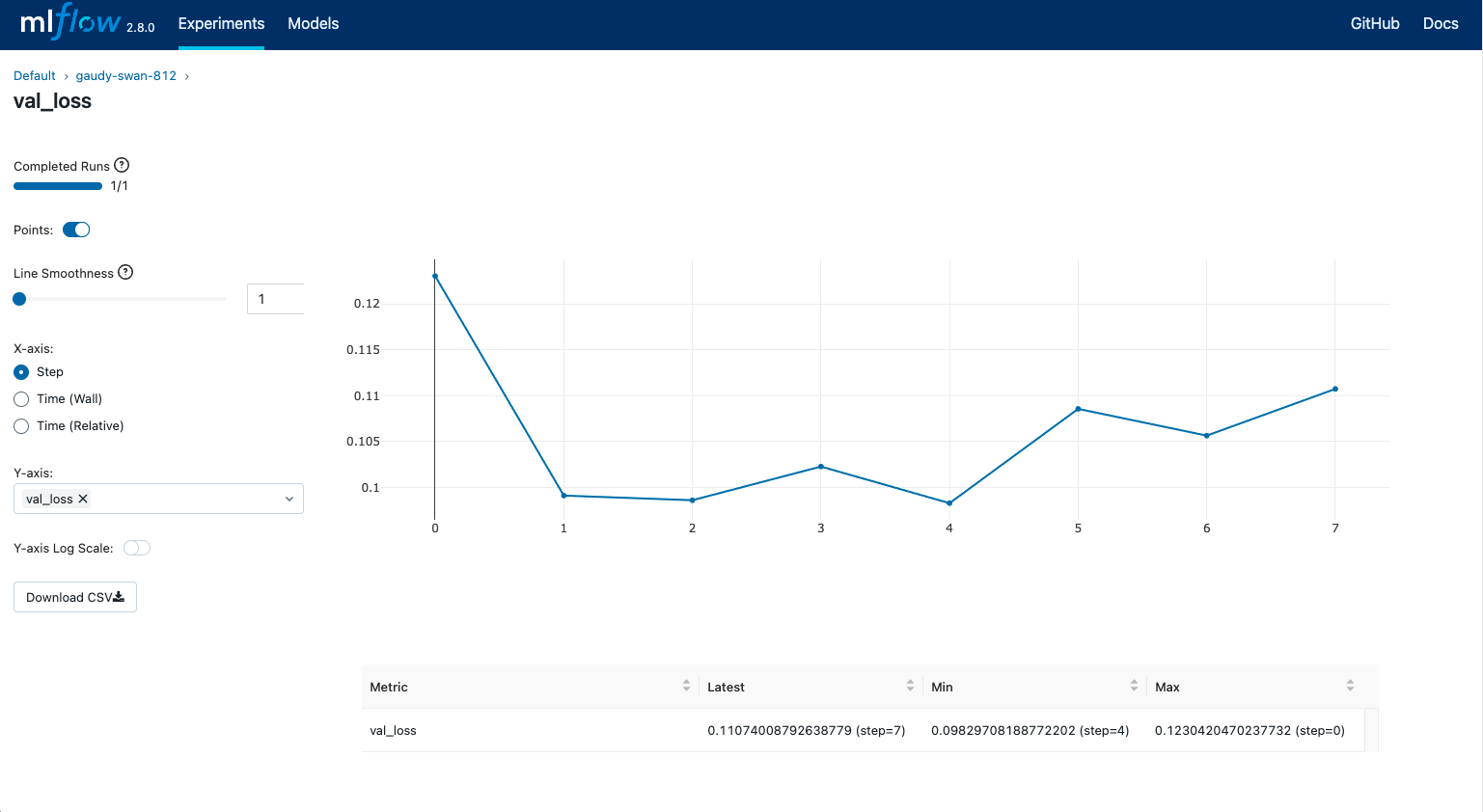
성능 기록
mlflow.log_metric(), mlflow.log_metrics()를 통해 성능을 기록할 수 있다.
예시 사진은 위 파라미터 기록 예시 사진을 참조
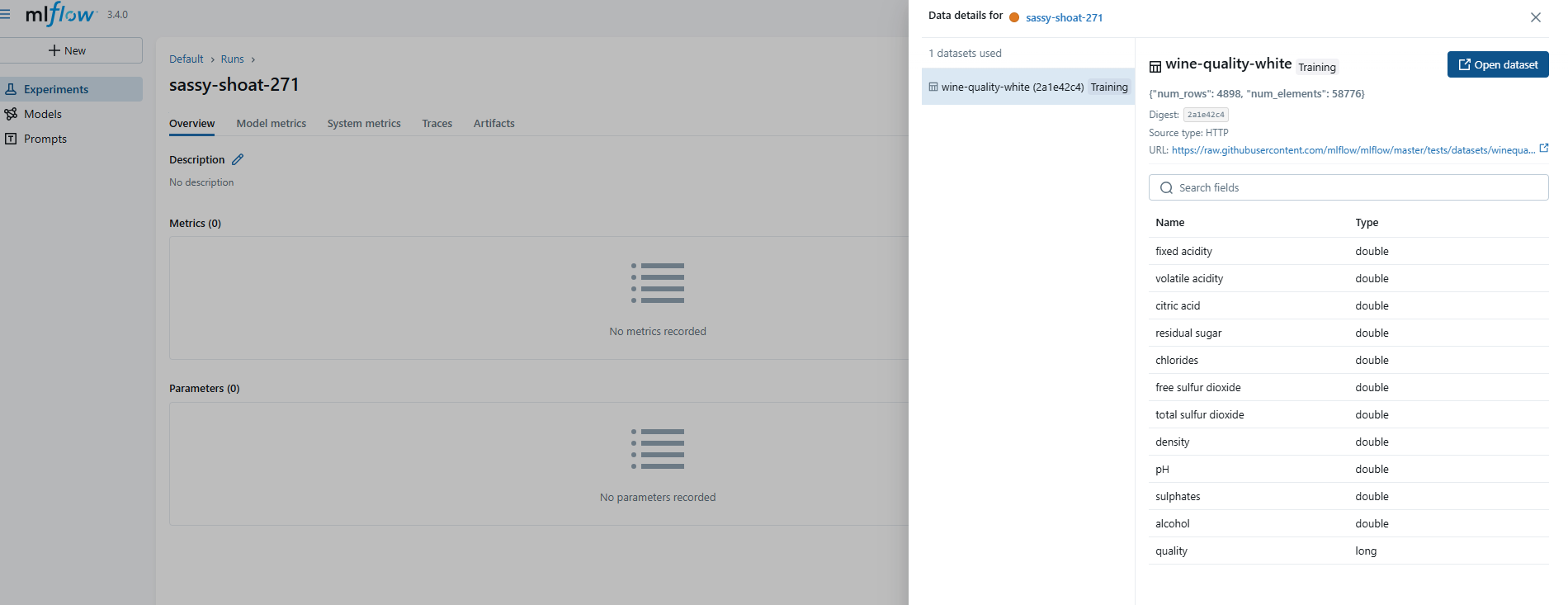
데이터셋 기록
mlflow.log_input()을 통해 데이터셋의 메타 정보와 source url 등을 로깅할 수 있다. source를 연결하면 open dataset 버튼을 통해, 용량이 큰 데이터를 조회할 수 있도록 연결하여 사용하면 편리할 듯하다.
artifacts 기록
학습을 진행하면서 만들어진 어느 파일이든 이를 기록하고 싶으면 이를 artifacts에 넣으면 된다. mlflow.log_artifacts() 코드를 통해 폴더 통째로 s3 artifacts 폴더에 넣을 수 있으며, mlflow.log_artifact() 코드를 통해 한 파일을 s3 artifacts 폴더에 넣을 수 있다.
그리고 해당 파일이 mlflow UI에서 조회되는 파일이라면 preview 기능도 지원한다. Download artifacts 버튼을 통해 해당 파일을 다운로드할 수 도 있다.
아래는 학습 실험 시 artifact로서 저장하면 좋을 데이터를 정리하였다.
학습/평가 데이터
아래와 같이 학습/평가 데이터를 저장하면 이를 조회할 수 있다. mlflow WebUI는 image, text, html, pdf, geojson 파일의 미리보기를 지원한다고 하고, csv 파일도 미리 보기가 된다.
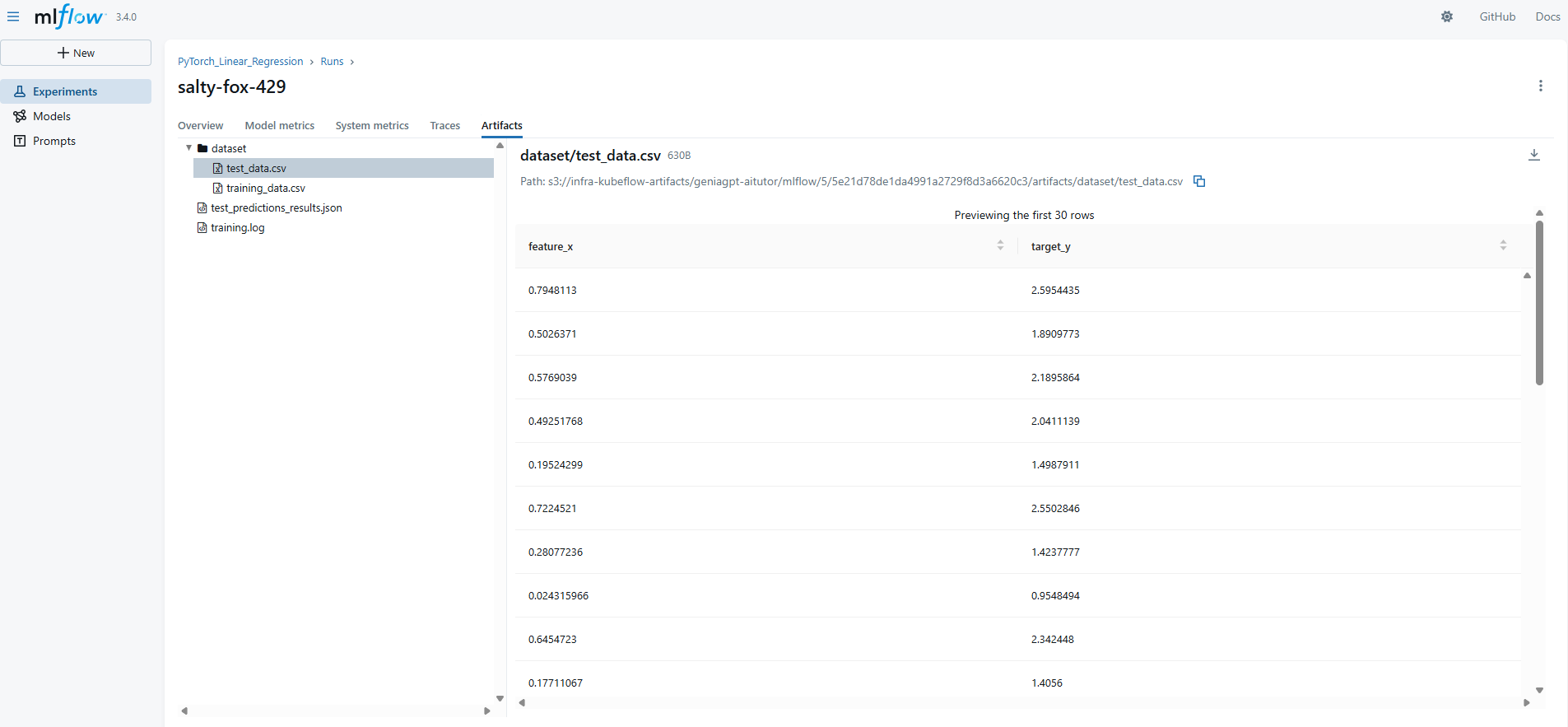
학습 로그
학습을 하면서 epoch 별로 성능을 정확하게 기록하고 저장하고 싶을 때나 해당 학습 시 발생하는 시스템 로그들을 저장하는 것도 유용할 거 같다.
아래 예시에서는 epoch 마다 학습시 loss 값을 기록하고, 최종적으로 test dataset으로 평가했을 때 loss 값을 기록하고 있다. 이를 log 파일로 저장하면 좀 더 깔끔하게 볼 수 있다.
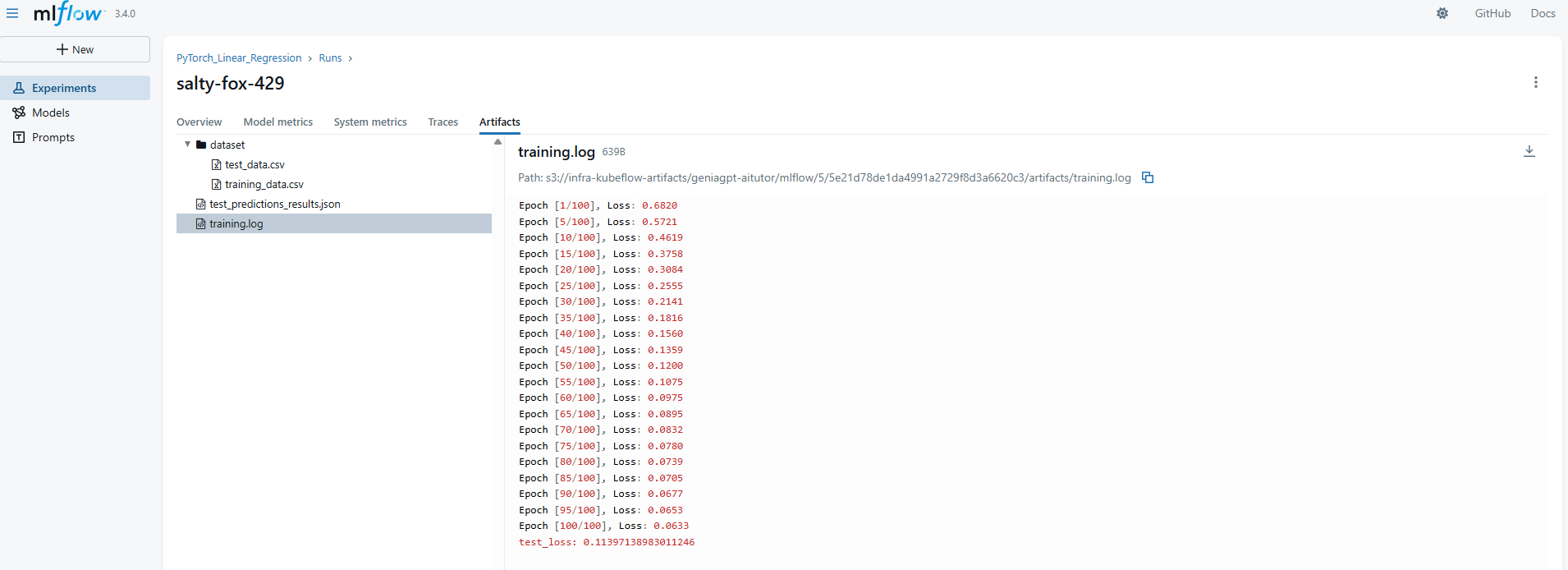
테스트 추론 결과
학습이 끝난후 테스트 데이터를 통한 평가 시, 성능을 확인할 수 있도록 모델 입/출력 데이터와 정답 데이터를 볼 수 있도록 저장해주면 유용할 것이라고 생각하였다. 이때 mlflow.log_table() 함수를 통해 저장했는데 아래와 같이 표 형태로 preview가 가능하고, 해당 데이터는 json으로 자동 저장된다.
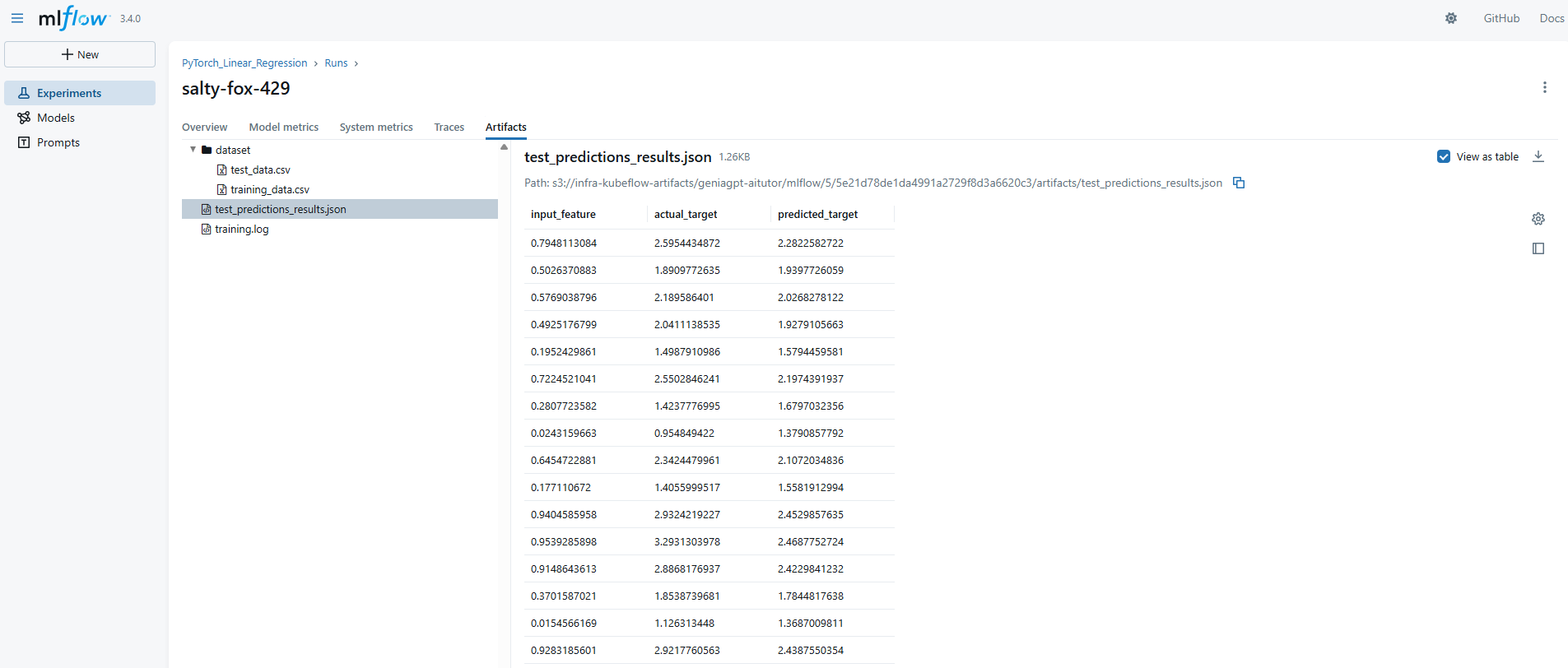
테이블 기록
위 테스트 추론 결과와 같이 테이블 형태의 데이터를 MLflow 아티팩트(Artifact)로 직접 기록하고 UI에서 시각적으로 확인하기 위해 사용된다. mlflow.log_table() 함수를 저장할 수 있다.
아래는 gemini를 통해 테이블을 어떨때 활용할수 있을지 정리한 내용이다.
주요 활용 사례
- 모델 오류 분석 (Error Analysis)
- 가장 강력한 활용법입니다. 테스트 데이터셋에 대한 모델의 예측값(Prediction)과 실제값(Label)을 테이블로 저장합니다.
- MLflow UI에서 이 테이블을 보며 '모델이 어떤 샘플을 틀렸는지' 직접 확인할 수 있습니다.
- 예:
[이미지 ID, 예측 레이블, 실제 레이블, 정답 여부]
- 데이터 샘플 로깅
- 학습이나 평가에 사용된 데이터의 일부 샘플(e.g., 상위 100개)을 저장하여, 해당 실험(Run)이 어떤 데이터로 학습되었는지 빠르게 파악할 수 있습니다.
- 피처 중요도 (Feature Importance)
- 트리 기반 모델 등에서 계산된 피처별 중요도를 테이블(
[피처명, 중요도 점수])로 저장하여 관리합니다.
- 트리 기반 모델 등에서 계산된 피처별 중요도를 테이블(
- 클래스별 상세 지표
- Accuracy, Precision, Recall 등을 전체 평균뿐만 아니라 각 클래스별로 계산하여 테이블로 저장합니다.
예시 코드
import mlflow
import pandas as pd
from sklearn.metrics import accuracy_score
# 예시 데이터 (실제로는 모델 예측 결과)
y_pred = [1, 0, 1, 1, 0]
y_true = [1, 1, 1, 0, 0]
with mlflow.start_run() as run:
# 1. 기본 메트릭 로깅
acc = accuracy_score(y_true, y_pred)
mlflow.log_metric("accuracy", acc)
# 2. log_table을 위한 DataFrame 생성
# 모델의 예측과 실제 값을 비교하는 테이블 생성
eval_data = {
"prediction": y_pred,
"actual": y_true,
"is_correct": [p == t for p, t in zip(y_pred, y_true)]
}
df = pd.DataFrame(eval_data)
# 3. mlflow.log_table로 테이블 로깅
# artifact_file 이름으로 MLflow UI의 Artifacts 탭에 저장됩니다.
mlflow.log_table(data=df, artifact_file="evaluation_results.json")
print(f"Run ID: {run.info.run_id} - Accuracy: {acc}")
print("Evaluation table logged.")Artifact evaluation 탭을 통한 결과 비교
Artifact evaluation 탭을 클릭하여 들어간 후, 결과를 비교할 artifact 파일을 선택하고 Group by, Compare 을 설정하면 각 실험별 데이터를 조회할 수 있다.
