
PytorchOperations
Pytorch Tensor
Tensor


다차원 Arrays 를 표현하는 PyTorch 클래스
사실상 numpy의 ndarray와 동일
(그러므로 TensorFlow의 Tensor와도 동일)
Tensor를 생성하는 함수도 거의 동일
>>> n_array=np.arange(10).reshape(2,5)
>>> print(n_array)
[[0 1 2 3 4]
[5 6 7 8 9]]
>>> t_array=torch.FloatTensor(n_array)
>>> print(t_array)
tensor([[0., 1., 2., 3., 4.],
[5., 6., 7., 8., 9.]])
>>> n_array.shape
(2, 5)
>>> t_array.shape
torch.Size([2, 5])
>>>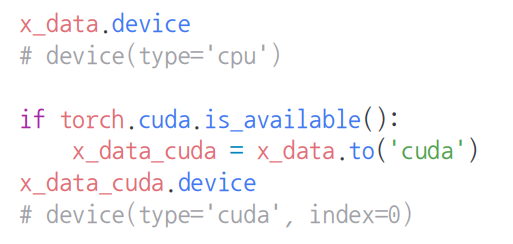
Tensor를 사용하는 이유는 GPU에서의 연산이 가능하기 때문
Tensor operations
nn.functional 모듈에서 딥러닝 연산을 위한 다양한 함수 지원
mm & matmul
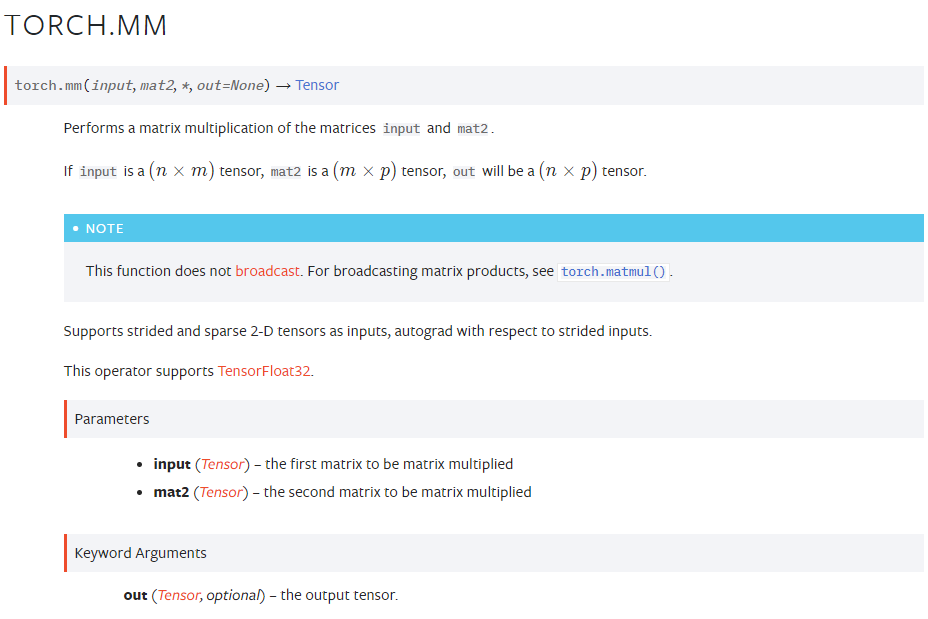
>>> n2 = np.arange(10).reshape(5,2)
>>> t2 = torch.FloatTensor(n2)
>>> n1 = np.arange(10).reshape(2,5)
>>> t1 = torch.FloatTensor(n1)
>>> t1.mm(t2)
tensor([[ 60., 70.],
[160., 195.]])
>>># mm은 브로드케스팅 미지원, 브로드케스팅 시 matmul 연산
>>> a = torch.rand(5, 2, 3)
>>> b = torch.rand(3)
>>> a.mm(b)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: self must be a matrix
>>> a.matmul(b)
tensor([[0.6796, 0.9354],
[0.7770, 0.7377],
[0.3269, 0.2283],
[0.9234, 0.3304],
[0.9173, 0.7840]])
>>>
Softmax
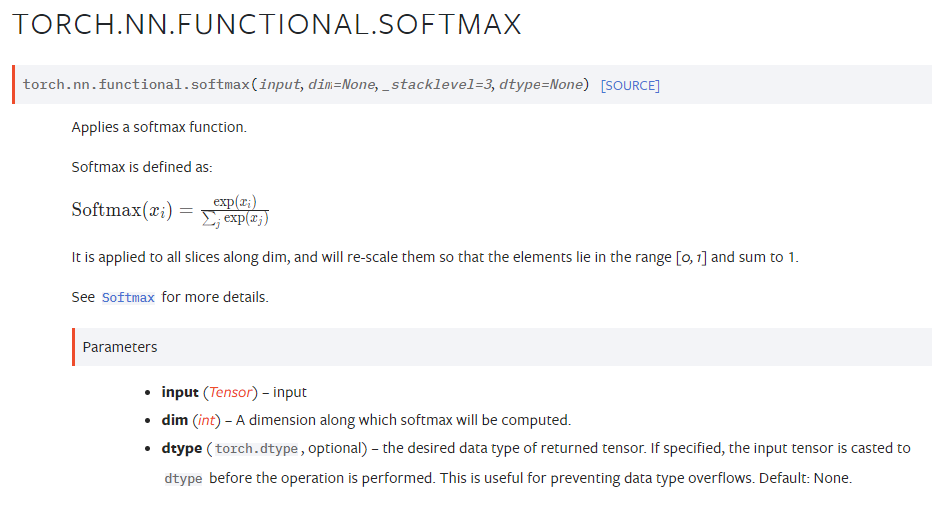
텐서의 값을 확률로 변환해주는 소프트맥스 함수
>>> import torch.nn.functional as F
>>> tensor = torch.FloatTensor([0.5, 0.7, 0.1])
>>> h_tensor = F.softmax(tensor, dim=0)
>>> h_tensor
tensor([0.3458, 0.4224, 0.2318])
>>>Argmax
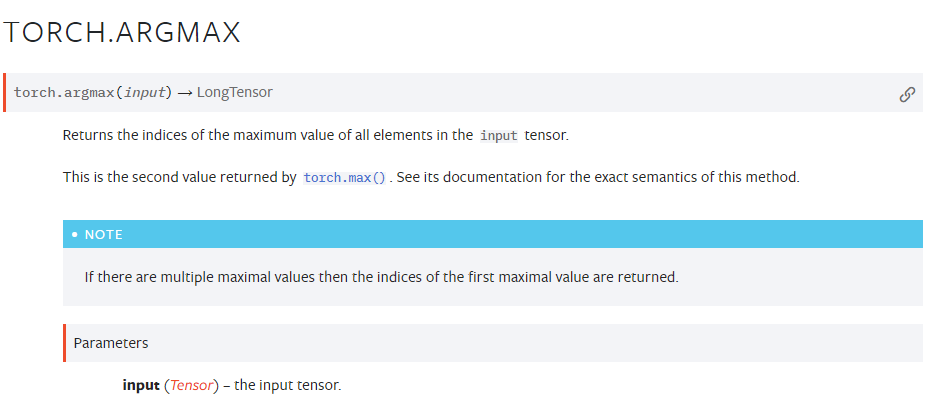
텐서에서 가장 큰 원소의 인덱스 번호를 리턴해 주는 argmax 함수
>>> a = torch.randn(4, 4)
>>> a
tensor([[-0.0872, 1.4650, -1.5463, -1.1279],
[-0.4658, -0.8992, 0.3674, -0.7540],
[-1.1629, 0.4612, 1.3172, -0.0475],
[ 0.0782, 1.6749, -0.0573, 1.3400]])
>>> torch.argmax(a)
tensor(13)
>>>one_hot
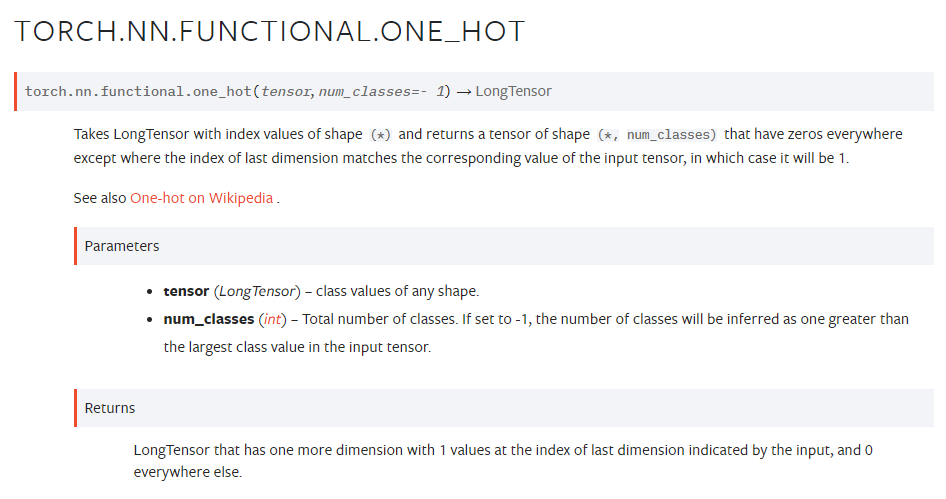
tensor의 값이 1의 인덱스가 된다.
>>> a=torch.arange(0, 5) % 3
>>> a
tensor([0, 1, 2, 0, 1])
>>> F.one_hot(a)
tensor([[1, 0, 0],
[0, 1, 0],
[0, 0, 1],
[1, 0, 0],
[0, 1, 0]])
>>> F.one_hot(torch.arange(0, 5) % 3, num_classes=5)
tensor([[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 1, 0, 0],
[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0]])
>>> F.one_hot(torch.arange(0, 6).view(3,2) % 3)
tensor([[[1, 0, 0],
[0, 1, 0]],
[[0, 0, 1],
[1, 0, 0]],
[[0, 1, 0],
[0, 0, 1]]])
>>>AutoGrad

pytorch의 핵심인 자동 미분 함수
>>> w = torch.tensor(2.0,
# w의 기울기를 저장
... requires_grad=True)
#관계식을 선언
>>> y = w**2
>>> z = 10*y + 2
#z'를 구함 -> z=10*w^2+25 이므로 z'=20*w 이고 tensor w는 2.0 이므로
>>> z.backward()
#w가 2.0에서의 기울기 w.gard 는 40
>>> w.grad
tensor(40.)
>>>from_numpy
zeros
zeros_like
max
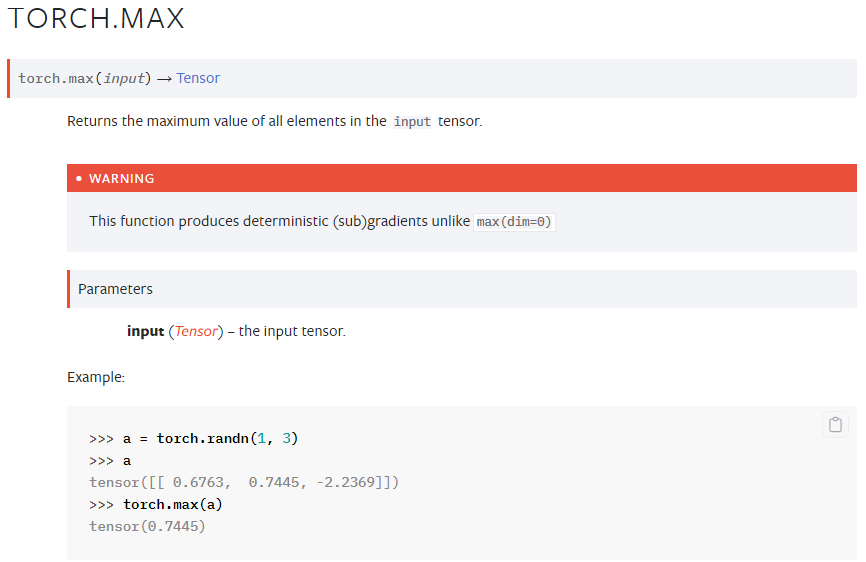
피라미터를 input 하나만 줄 경우 input에서 가장 큰 원소(tensor)를 리턴
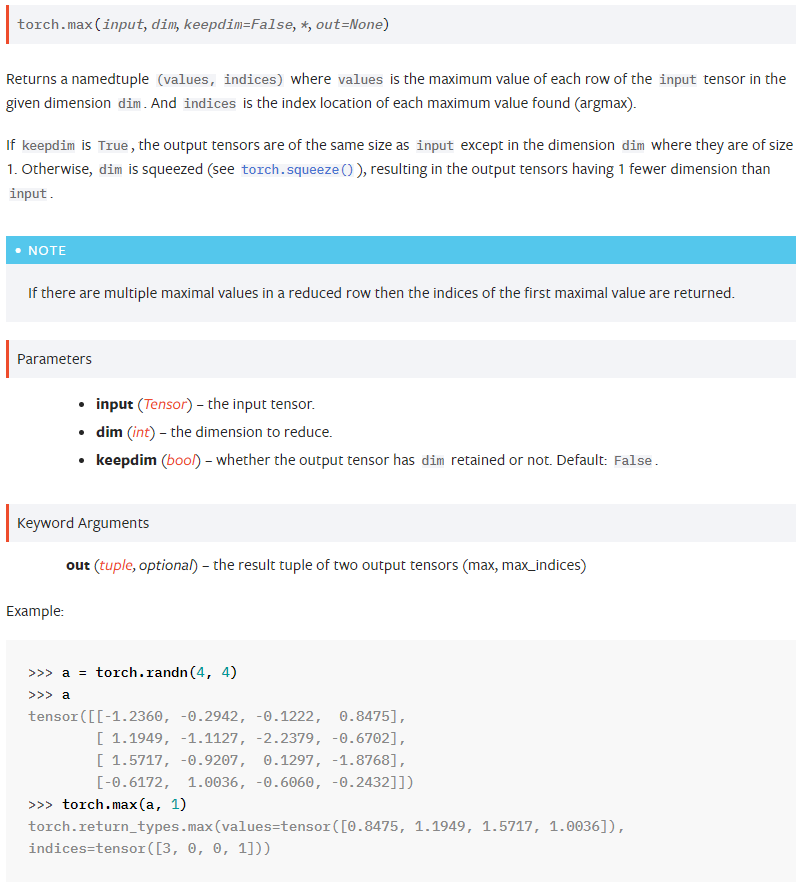
피라미터가 input,dim일 경우 input에서 입력한 dim에 따라(dim-> tensor shape(0,1,2,....))
가장 큰 원소(tensor)와 인덱스를 리턴
>>> temp=np.arange(30).reshape(2,3,5)
>>> temp
array([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]],
[[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]]])
>>> d=torch.from_numpy(temp)
>>> d
tensor([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]],
[[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]]], dtype=torch.int32)
# dim이 0 일경우 -> 입력이 (2,3,5)모양이므로 2에서 가장 큰 텐서를 찾아서 리턴한다.
>>> torch.max(d,0)
torch.return_types.max(
values=tensor([[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]], dtype=torch.int32),
#인덱스는 0번째 dim 의 모양인 (3,5) 형태인것을 확인할 수 있다.
indices=tensor([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]]))
# dim이 1 일경우 -> 입력이 (2,3,5) 모양이므로 3에서(행에서) 가장 큰 텐서를 찾는다.
>>> torch.max(d,1)
torch.return_types.max(
values=tensor([[10, 11, 12, 13, 14],
[25, 26, 27, 28, 29]], dtype=torch.int32),
# 1번째 dim 모양인 (5) 형태인것을 확인할 수 있다.
indices=tensor([[2, 2, 2, 2, 2],
[2, 2, 2, 2, 2]]))
# dim이 2 인경우 -> 입력인 (2,3,5)모양의 5에서(열에서) 가장 큰 원소(텐서)를 찾는다.
>>> torch.max(d,2)
torch.return_types.max(
values=tensor([[ 4, 9, 14],
[19, 24, 29]], dtype=torch.int32),
#2번째 dim은 열의 원소들이므로 각 행당 하나씩 (2,3) 모양인것을 확일 할 수 있다.
indices=tensor([[4, 4, 4],
[4, 4, 4]]))
>>>
에서 몇개나 맞았는지 확인하는 n_correct는 다음과 같이 돌아간다
>>> a=torch.tensor([0,1,2,3,4,5])
>>> b=torch.tensor([0,1,2,3,6,7])
>>> a==b
tensor([ True, True, True, True, False, False])
>>> (a==b)
tensor([ True, True, True, True, False, False])
>>> (a==b).sum()
tensor(4)
>>> (a==b).sum().item()
4
>>>Tensor indexing
AutoGrad & Optimizer
torch.nn.Module
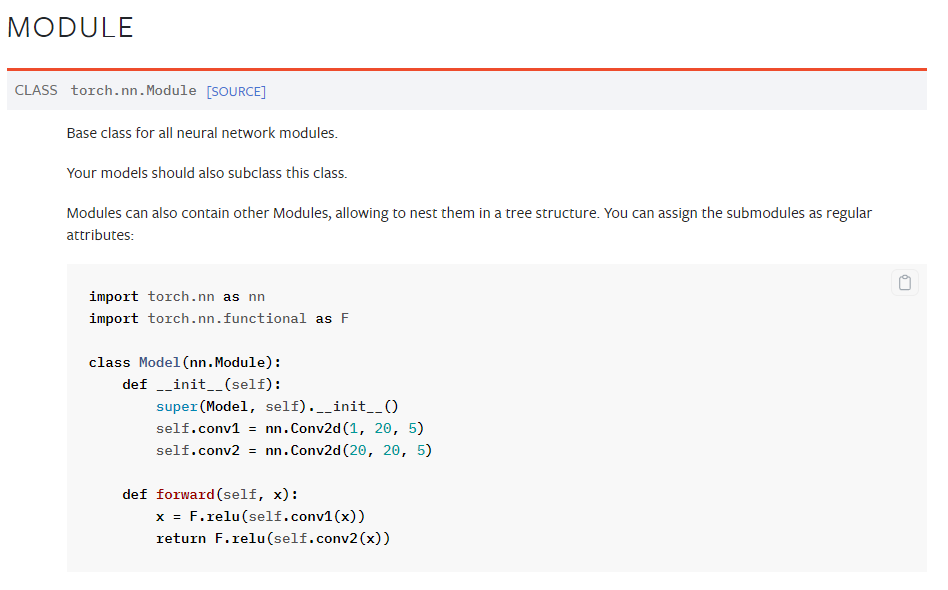
딥러닝을 구성하는 Layer의 base class
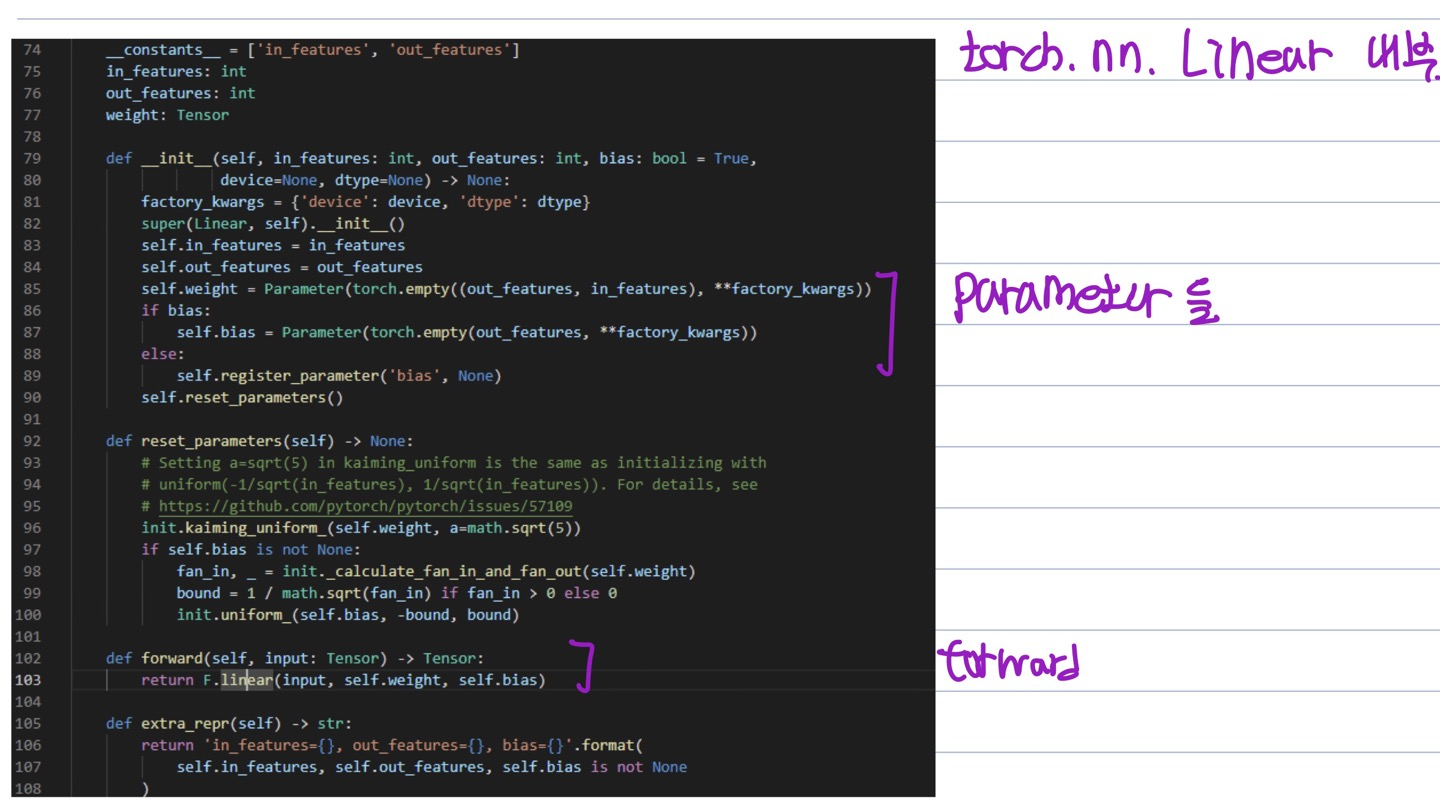
nn.Module을 상속하여 만들어지는 nn.Linear 의 구조
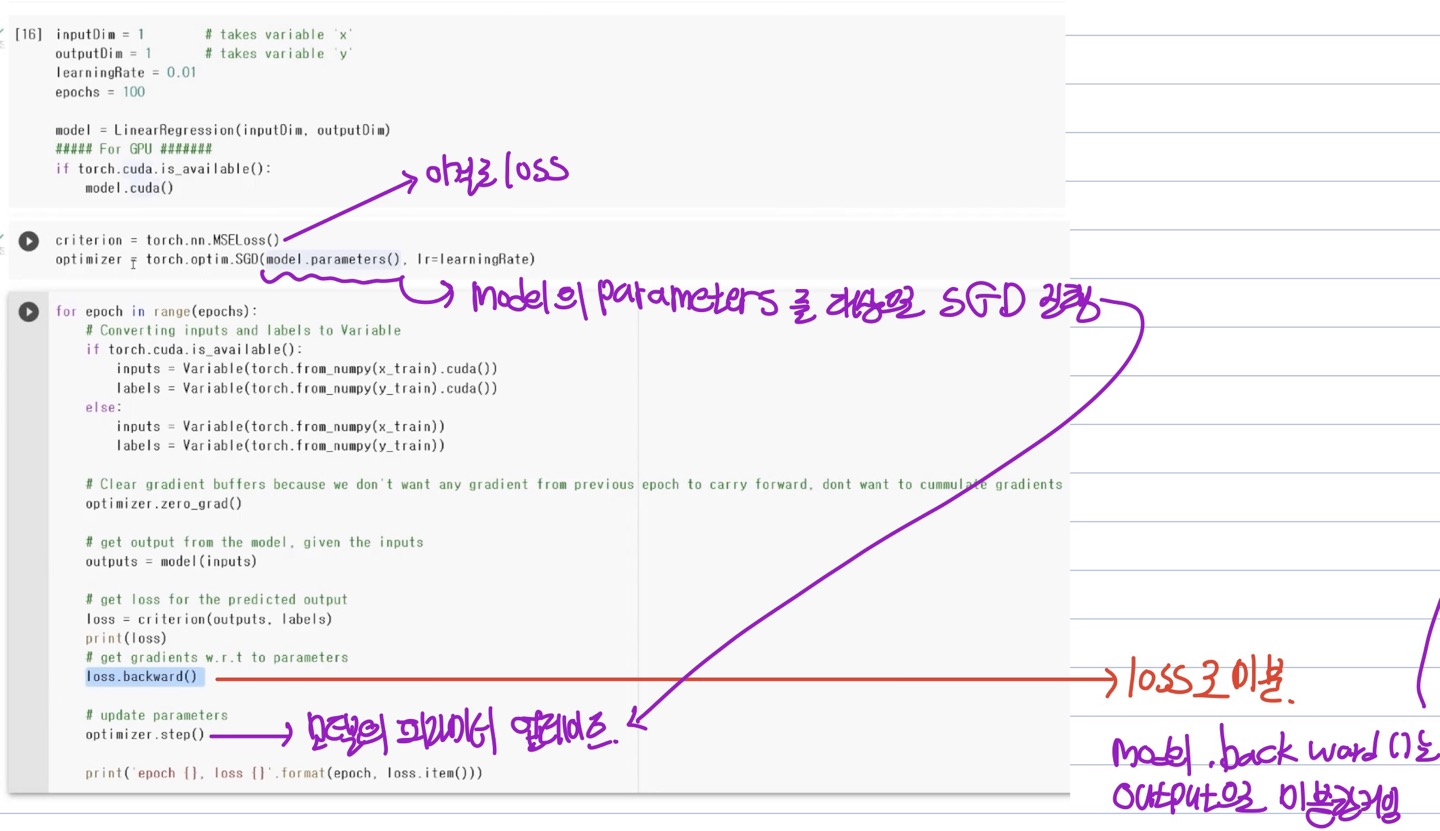
기본적인 선형 회귀 예시
forward & backward
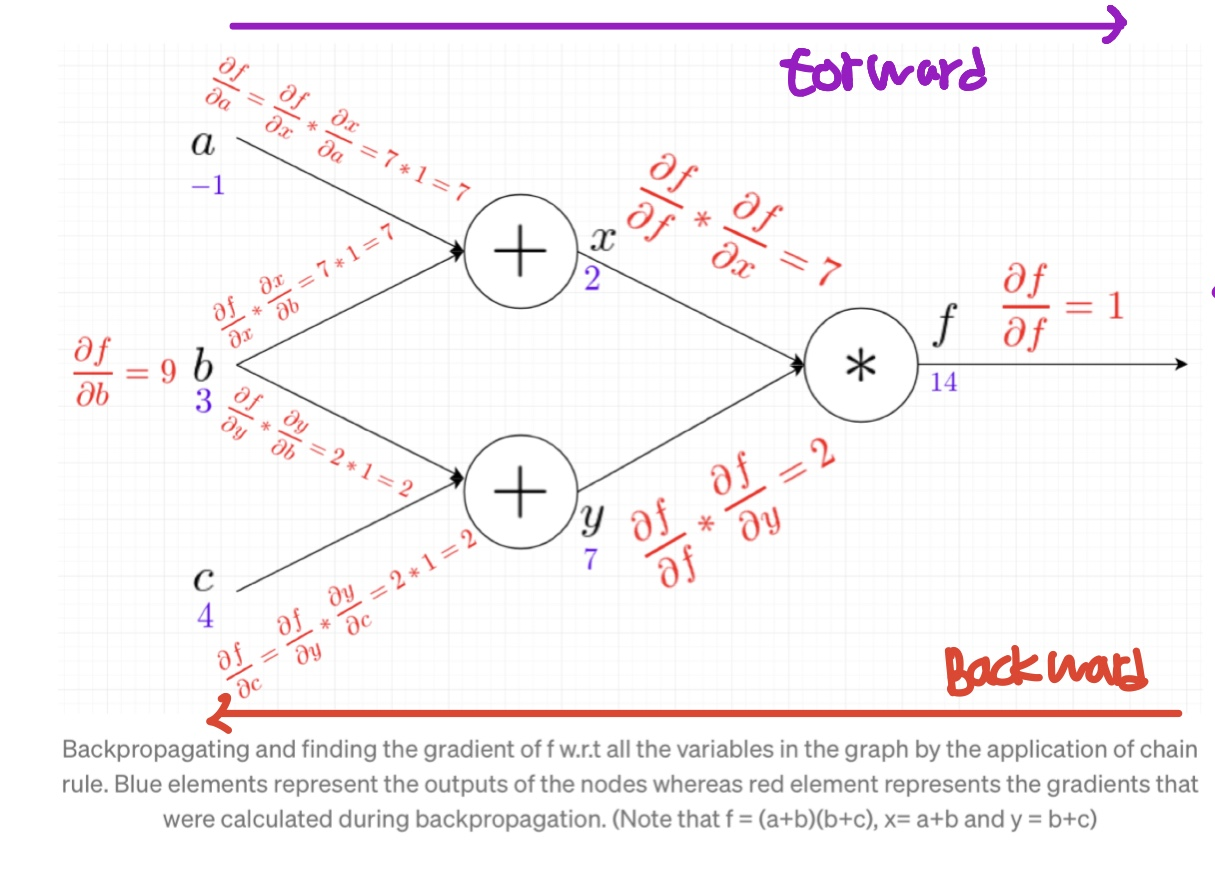
모델이 어떤 식을 표현한다면, 해당 모델의 결과를 내는 방향이 순전파(forward)이고
해당 모델의 결과값에 대해 거꾸로 미분하는것이 역전파(backward)이다.
backward :
Layer에 있는 Parameter들의 미분을 수행
Forward의 결과값 (model의 output=예측치)과
실제값간의 차이(loss) 에 대해 미분을 수행
해당 값으로 Parameter 업데이트

1) 최적화할때 항상 grad를 초기화 시켜준다
2) loss 값을 구해주고
3) loss 값에 대해 피라미터들의 역전파를 계산하여
4) 가중치를 업데이트 시킨다.
백워드함수의 기본 작동방식
- nn.Module 에 선언되어있는 parameter들의 미분을 수행
- 이떄 미분이 되는 parameter들은 Forward의 결과값(output)과 실제값의 차이(loss)로 미분된다.
- parameter들의 업데이트는 opti.step() 함수를 사용하여 진행
해당 과정들은 실제 backward는 Module 단계에서 직접 지정가능하다.
Module에서 backward 와 optimizer 오버라이딩하여 사용할 수 있지만,
사용자가 직접 미분 수식을 써야하는 부담이 있기 때문에 자주 사용하지 않는다.
→ 쓸일은 없으나 순서는 이해할 필요는 있음
nn.Parameter
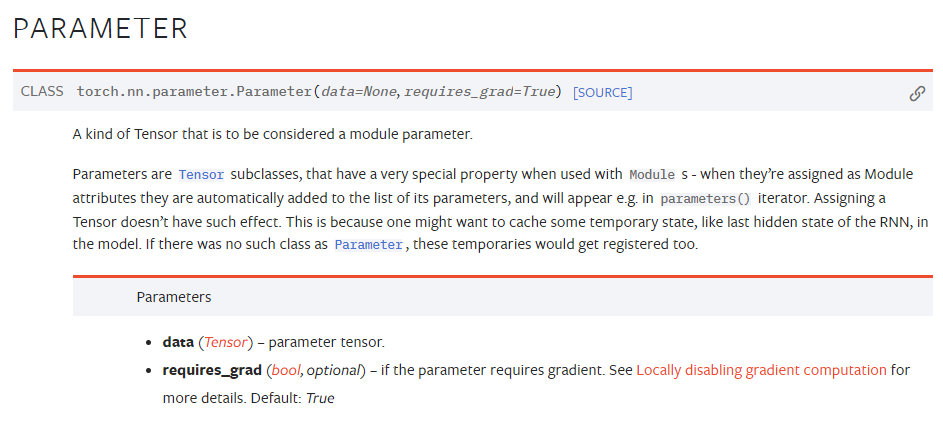
가중치가 저장되는 변수로써,Tensor 객체의 상속 객체
nn.Module 내에 attribute가 될 때는 required_grad=True 로 지정되어 학습 대상이 되는 Tensor
우리가 직접 지정할 일은 잘 없음 : 대부분의 layer에는 weights 값들이 지정되어 있음

Backward-detail

Backward 함수는 outputs에서 parameter를 받아올 수 있고 optimizer는 선언시에 parameter를 받아온다.
Datasets
Overview
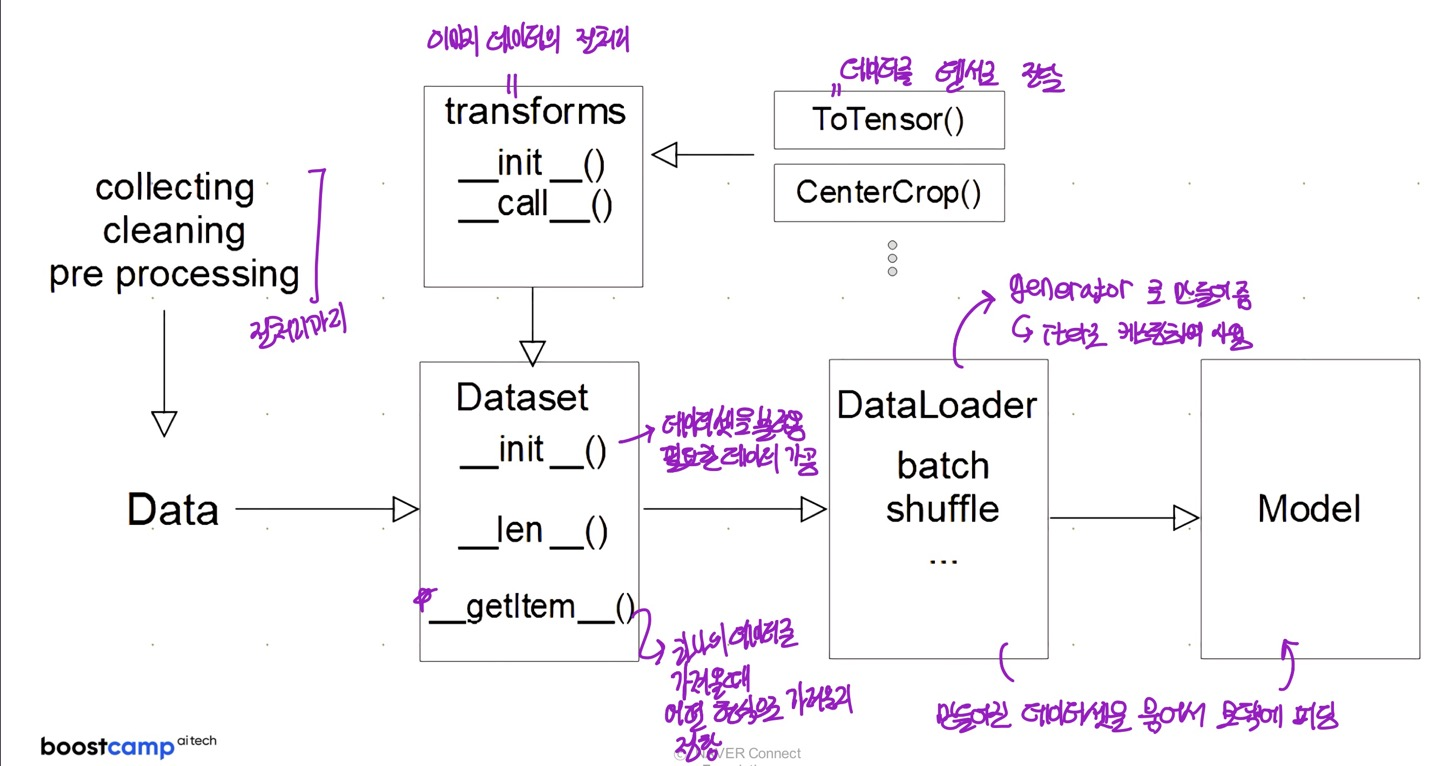
기본적으로 Dataset을 구성할 때는 PyTorch의
torch.utils.data에서Dataset 클래스를 상속해서 만듭니다. 이렇게 생성된 Dataset 클래스는 크게 아래와 같이 3가지 메서드로 구성됩니다.__init__메서드와__len__메서드와 마지막으로__getitem__메서드로 구성됩니다. 이런 방식은map-style dataset과 같은 Dataset일때에만 가능합니다. 보다 자세한 내용은 PyTorch Documentations 참고하세요.
datasets method __init__
일반적으로 해당 메서드에서는 데이터의 위치나 파일명과 같은 초기화 작업을 위해 동작합니다. 일반적으로 CSV파일이나 XML파일과 같은 데이터를 이때 불러옵니다. 이렇게 함으로써 모든 데이터를 메모리에 로드하지 않고 효율적으로 사용할 수 있습니다. 여기에 이미지를 처리할 transforms들을 Compose해서 정의해둡니다.
datasets method __len__
해당 메서드는 Dataset의 최대 요소 수를 반환하는데 사용됩니다. 해당 메서드를 통해서 현재 불러오는 데이터의 인덱스가 적절한 범위 안에 있는지 확인할 수 있습니다.
datasets method __getitem__
해당 메서드는 데이터셋의 idx번째 데이터를 반환하는데 사용됩니다. 일반적으로 원본 데이터를 가져와서 전처리하고 데이터 증강하는 부분이 모두 여기에서 진행될 겁니다. 이는 이후 transform 하는 방법들에 대해서 간단히 알려드리겠습니다.
Custom Iris dataset
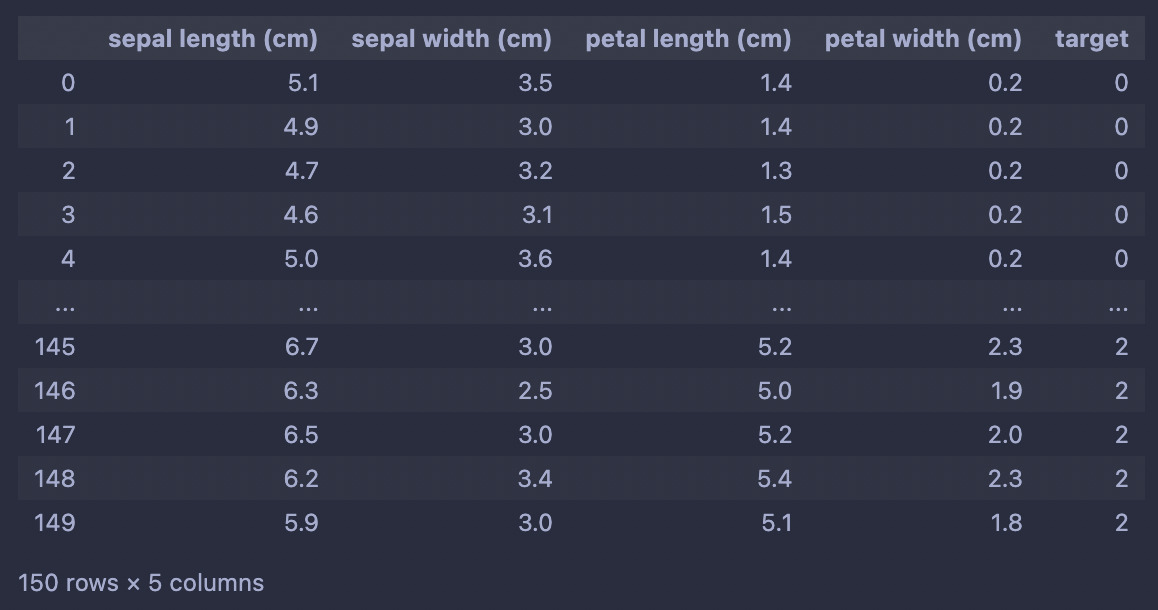
아이리스 데이터셋에서 한 행씩 반환하는 데이터셋을 만들 예정입니다.
iris = load_iris()
iris_df = pd.DataFrame(iris['data'], columns=iris['feature_names'])
iris_df['target'] = iris['target']
iris_df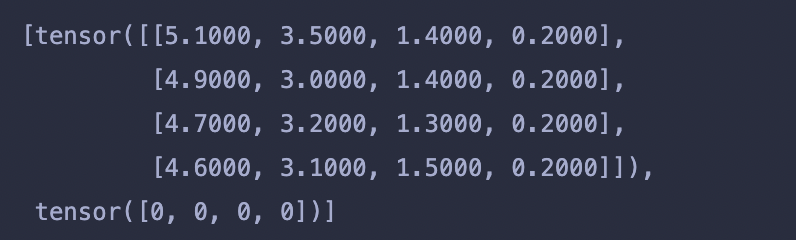
을 기반으로 torch.utils.data.Dataset를 상속하는 커스텀 데이터셋을 작성해보면 다음과 같습니다.
class IrisDataset(Dataset):
def __init__(self): # 데이터셋을 선언
iris = load_iris()
######################################TODO######################################
self.X = iris['data']
self.y = iris['target']
self.feature_names = iris['feature_names']
self.target_names = iris['target_names']
################################################################################
def __len__(self):# 데이터셋의 길이 리턴
len_dataset = None
######################################TODO######################################
len_dataset = len(self.X)
################################################################################
return len_dataset
def __getitem__(self, idx): # 데이터셋에서 하나의 인덱스를 입력할 경우 리턴할 데이터 형식을 정의
X, y = None, None
######################################TODO######################################
X = torch.tensor(self.X[idx],dtype=torch.float)
y = torch.tensor(self.y[idx],dtype=torch.long)
################################################################################
return X, yDataloaders
Overview & Parameter
Dataloader는 모델 학습을 위해서 데이터를 미니 배치(Mini batch)단위로 제공해주는 역할을 합니다. PyTorch Documentations을 확인해보면 아래와 같이
DataLoader가 정의되어 있는 걸 확인할 수 있습니다. 여기서 dataset은 앞서 우리가 만든Dataset을 인자로 넣어주시면 됩니다! 보통batch_size나collate_fn와 같은 인자를 주로 사용할겁니다!DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None)
Dataset
Dataloader에서 사용할 데이터셋을 파라미터로 넘겨줌
Batch_size
Dataloader에서 한번에 몇개의 데이터를 넘겨줄것인지(배치사이즈) 정하는 파라미터
next(iter(DataLoader(dataset_iris, batch_size=4)))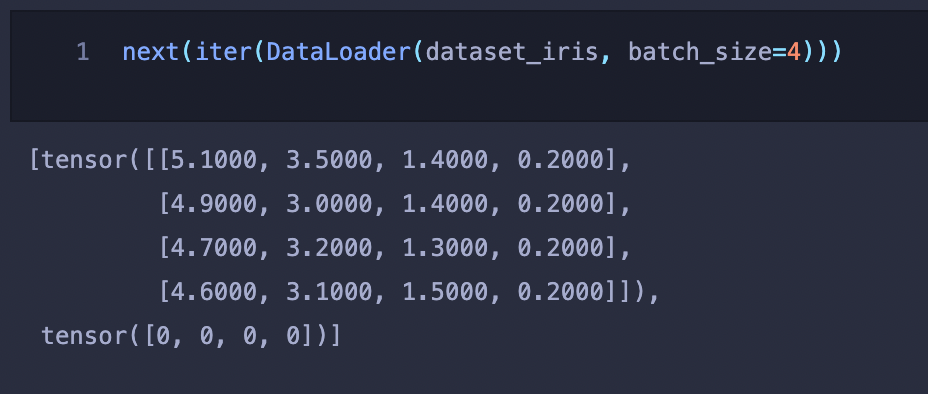
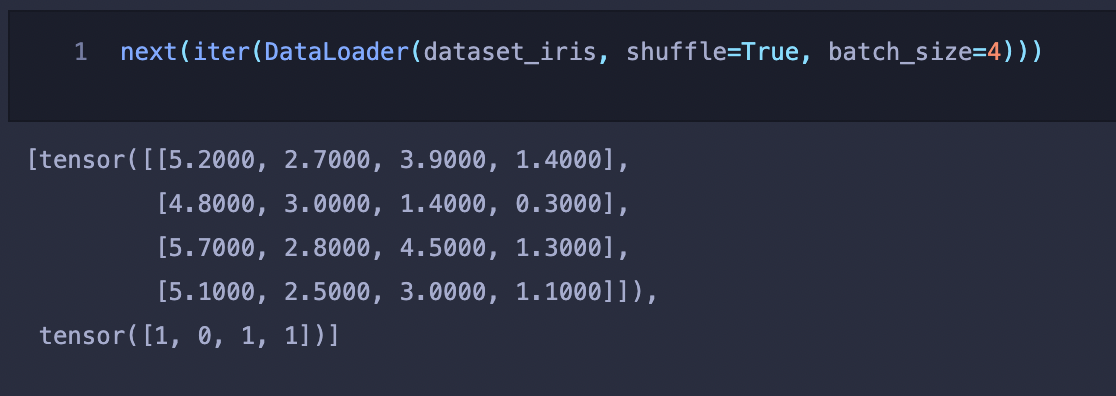
shuffle
데이터로더에서 데이터를 섞어서 사용하겠는지를 설정하는 파라미터
sampler
불균형 데이터셋의 경우, 클래스의 비율에 맞게끔 데이터를 제공해야할 필요가 있습니다. 이럴 때 사용하는 옵션이 sampler입니다.
Dataset은 idx로 데이터를 가져오도록 설계 되었다. 이 때 Sampler는 이 idx 값을 컨트롤하는 방법이다.
따라서 sampler를 사용할 때는 shuffle 파라미터는 False가 되어야한다.
__len__과 __iter__ 를 구현해 커스텀할 수 있고 미리 선언된 아래와 같은 Sampler들도 있다.
- SequentialSampler : 항상 같은 순서
- RandomSampler : 랜덤, replacemetn 여부 선택 가능, 개수 선택 가능
- SubsetRandomSampler : 랜덤 리스트, 위와 두 조건 불가능
- WeigthRandomSampler : 가중치에 따른 확률
- BatchSampler : batch단위로 sampling 가능
- DistributedSampler : 분산처리 (torch.nn.parallel.DistributedDataParallel과 함께 사용)
batch_sampler(미작성)
num_workers
데이터셋을 불러오기 위해 할당하는 sub_prosess의 개수입니다.(단순히 많아도 빨라지지 않을 수 있음->병목,에러가 발생)
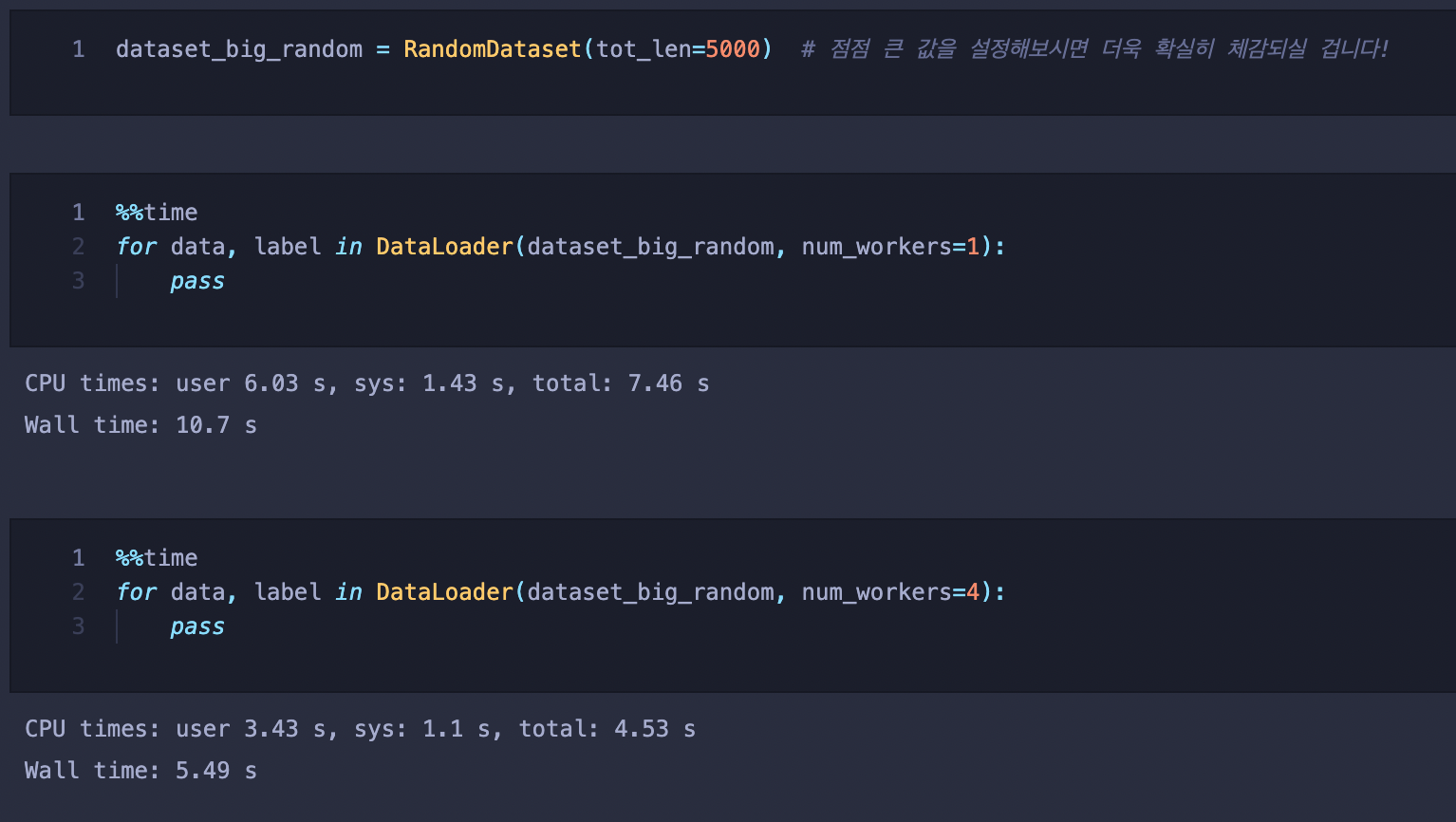
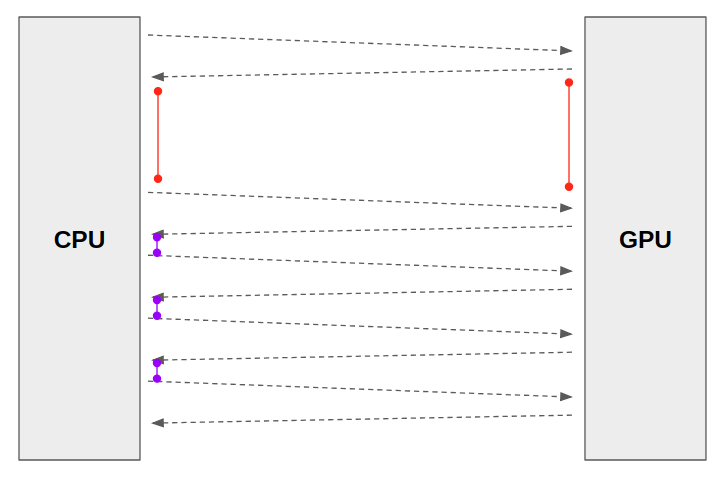
그렇다면 CPU의 성능을 이끌어내는 가장 단순한 방법은 작업을 단일코어가 아닌 멀티코어로 처리하는 것입니다. DataLoader에서 그것을 가능하게 해주는것이 바로 num_workers 파라미터 입니다. 단순하게 생각해보면 CPU 작업(전처리 및 data loading)을 빨리 끝내기 위해 num_workers를 최대로 만들어 빠르게 GPU(행렬연산)으로 넘기는것이 좋아보이지만, 이럴 경우 다른 작업을 하고 있는 자원까지 모조리 num_worker에 사용되기 때문에 오히려 총 시간이 더 오래걸리는 상황이 발생합니다.
결국 모델에 가장 적합한 num_workers 수치를 찾아내는 것도 파라미터 튜닝으로 볼 수 있습니다.
collate_fn
생각보다 많이 쓰는 옵션입니다. 보통 map-style 데이터셋에서 sample list를 batch 단위로 바꾸기 위해 필요한 기능입니다. zero-padding이나 Variable Size 데이터 등 데이터 사이즈를 맞추기 위해 많이 사용합니다.
참고: https://deepbaksuvision.github.io/Modu_ObjectDetection/posts/03_01_dataloader.html
HINT:
collate는 '함께 합치다'라는 의미입니다
직관적인 예시로는 프린터기에서 인쇄할때, 묶어서 인쇄하기와 같은 기능이라고 생각하면 됩니다.
즉, ((피처1, 라벨1) (피처2, 라벨2))와 같은 배치 단위 데이터가 ((피처1, 피처2), (라벨1, 라벨2))와 같이 바뀝니다.
 즉 batch를 자신이 원하는 아웃풋으로 바꿀 수 있다는 말로 이해하면 된다.
즉 batch를 자신이 원하는 아웃풋으로 바꿀 수 있다는 말로 이해하면 된다.
dataset_random = RandomDataset(tot_len=10)
def collate_fn(batch): # 이때 batch로 batch_size만큼의 데이터가 들어온다.
print('Original:\n', batch)
print('-'*100)
data_list, label_list = [], []
#output custom
for _data, _label in batch:
data_list.append(_data)
label_list.append(_label)
print('Collated:\n', [torch.Tensor(data_list), torch.LongTensor(label_list)])
print('-'*100)
#return output
return torch.Tensor(data_list), torch.LongTensor(label_list) next(iter(DataLoader(dataset_random, collate_fn=collate_fn, batch_size=4)))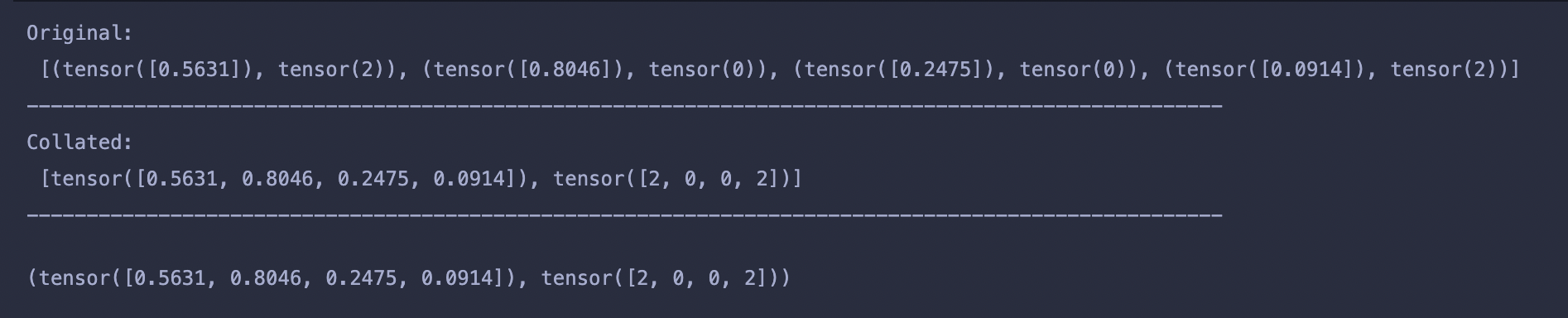
의 결과를 살펴보면 feature끼리, label끼리 합쳐진 것을 확인할 수 있습니다.
pin_memory
DataLoader에서 이걸 True로 바꾸면 Tensor를 CUDA 고정 메모리에 할당시킵니다. 고정된 메모리에서 데이터를 가져오기 때문에 데이터 전송이 훨씬 빠릅니다. 하지만 일반적인 경우에는 많이 사용하지 않을 argument라서 이번 시간에는 스킵하도록 하겠습니다. 보다 자세한 기술적인 내용은 아래의 내용을 참고해주세요! 본 내용은 출처1 및 출처2에서 가져왔습니다.
-
Pageable Memory: Memory 내용(contents)이 DRAM에서 하드디스크 (Secondary Storage Device)로 page out 되거나 반대로 하드디스크에서 DRAM으로 page in이 가능한 메모리를 의미합니다. Page in/Page out을 하기 위해서는 CPU (Host)의 도움이 필요하다고 합니다. 보통 OS에서 User Memory Space의 경우 Pageable Memory입니다. -
Non-Pageable Memory: Pageable Memory와 반대로 page in/page out이 불가능한 메모리를 Non-Pageable Memory라 합니다. 결과적으로 하드디스크로 데이터를 page out/page in 하는 작업이 필요없습니다. OS에서 Kernel Memory Space는 보통 Non-Pageable Memory라고 합니다.
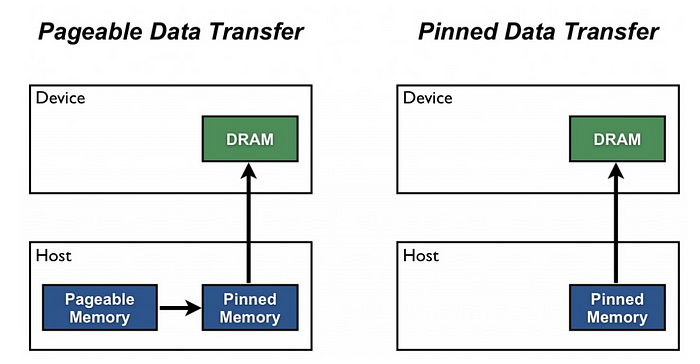
drop_last
batch 단위로 데이터를 불러온다면, batch_size에 따라 마지막 batch의 길이가 달라질 수 있습니다. batch의 길이가 다른 경우에 따라 loss를 구하기 귀찮은 경우가 생기고, batch의 크기에 따른 의존도 높은 함수를 사용할 때 걱정이 되는 경우 마지막 batch를 사용하지 않을 수 있습니다.
batch_size에 관련한 파라미터로써 만약 마지막 data의 사이즈가 batch 사이즈보다 작을 경우 마지막 data를 불러오지 않는다
#drop_last :
for data, label in DataLoader(dataset_random, num_workers=1, batch_size=4):
print(len(data))for data, label in DataLoader(dataset_random, num_workers=1, batch_size=4, drop_last=True):
print(len(data))torchvision
transforms methods
