[KT에이블스쿨] 시각지능 : Image Data Augmentation , Transfer Learning , Object detection (with YOLO)
KT에이블스쿨 - AI트랙 6기 💻✍🏻💚

- 10/23 - 10 /25
📌 Image Data Augmentation (이미지 데이터 증강)
-
Augmentation(데이터 증강)은 딥러닝에서 모델의 일반화 능력을 향상시키기 위해 학습 데이터셋을 인위적으로 확장하는 기법
-
Augmentation 나오게 된 배경
- 문제에 맞는 데이터가 없을때 데이터를 수집하고, 수집한 데이터만으로도 어떻게든 성능을 높이고자 ...
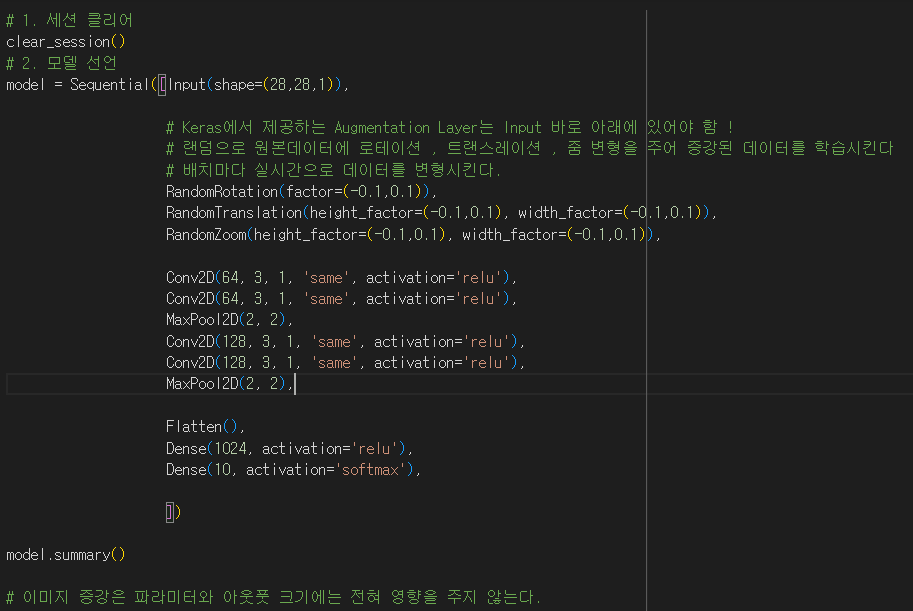
CNN + Image Data Augmentation
- Image Data Augmentation
데이터의 변형이나 처리는 학습 전 데이터를 준비하는 전처리 단계에서 하는 과정이므로 이 단계에서 증강을 수행하여 데이터의 다양성을 증가시켜 모델을 일반화 시킨다.
- 따라서 인풋 -> Image Data Augmentation 이어야 한다.
- Image Data Augmentation 하고나면 파라미터 , 아웃풋레이어 크기에 변함이 없다. 단지 매 훈련반복마다 모델이 약간씩 다른 이미지를 학습하여 데이터 양을 늘리는 효과가 있을뿐이다.
- 즉 , 원본데이터 수는 똑같지만 랜덤으로 데이터변형이 일어나 새로운 데이터를 학습하는 효과가 난다
➡️ [실습 : Image Data Augmentation Exercise : CIFAR-100 : 클래스 100개 ]
🏷️ CIFAR 데이터셋링크
🏷️ Image Augmentation Layer 공식문서링크
- Image Augmentation Layer 사용예시
keras.layers.RandomRotation(factor=(-0.3,0.3)),
keras.layers.RandomTranslation(height_factor=(-0.3,0.3), width_factor=(-0.3,0.3)),
keras.layers.RandomZoom(height_factor=(-0.2,0.2), width_factor=(-0.2,0.2)),
keras.layers.RandomFlip(mode='horizontal_and_vertical')
-
이번 실습에서는 데이터 전처리 中 원핫인코딩 하지않았다. 그 이유는
클래스가 100개라서 첫 번째 클래스에 0이 99개 1개의 1이 나오고 99개의 0이 나온다. 그러면 traget에 0이 너무 많아진다.
✔️ 비효율 , 학습이전에 OOM(out of memory) 가능성 높음 -
(train_x, train_y), (test_x, test_y) = load_data(label_mode='coarse')

📌 Model Checkpoint
-
모델 학습 과정 중 성능이 가장 좋은 모델을 자동으로 저장하는 콜백 기능

-
Model Checkpoint ?
최고 성능을 낸 시점의 모델이 저장되며, 이 모델의 구조와 가중치, 그리고 컴파일 정보가 포함되어 있다. 학습 중의 모든 모델이 아니라 가장 성능이 좋은 모델만 저장되기 때문에, load_model()로 불러오면 항상 최적의 모델을 복원한다. 주로 검증 손실(val_loss)이 가장 낮은 모델을 저장한다.
따라서 ModelCheckpoint를 사용한 경우 최적 성능의 가중치만 저장하여 성능이 가장 좋은 상태의 모델만 로드할 수 있는 효율성을 얻을 수 있다. -
get_weights()로 구체적인 가중치를 볼 수 있다.
📌 image_dataset_from_directory
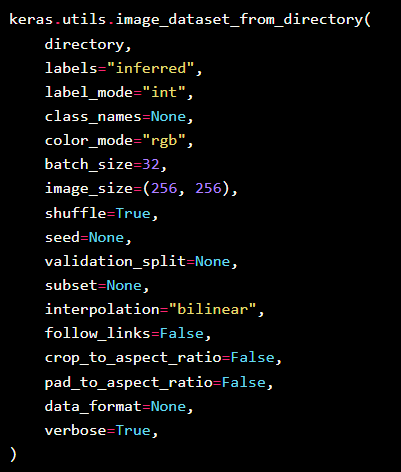
image_dataset_from_directory 공식문서링크
- image_dataset_from_directory 는 언제 , 어떻게 사용 ?
1. 일반적인 데이터 불러오기와 수동 전처리 : 데이터셋이 완성된 상태에서 전처리 수행 혹은 라벨과 이미지를 수동으로 매칭
2. image_dataset_from_directory : 폴더 구조만으로 구분된 이미지 데이터를 불러오는 데 최적화 , 폴더명이 라벨 역할을 하며, 별도의 라벨 파일 없이도 자동으로 각 폴더에 따라 라벨을 할당한다.- 그래서 image_dataset_from_directory 사용전 각 데이터를 라벨링하고 싶은대로 폴더별로 분류해야한다.
📌 Transfer Learning (전이 학습)

Transfer Learning 이란 ?
이미 학습된,유명한 모델(보통 대규모 데이터셋에서 훈련된)을 가져와서, 그 지식을 새로운 문제에 적용하는 기법. 특히, 많은 데이터와 리소스를 요구하는 이미지 처리나 자연어 처리 같은 분야에서 매우 유용하다.학습된 모델을 사용하는 이유는 ?
이미지데이터 그 자체에 대한 feature를 잘 추출해 낸다는 기대가 있다 >> object detection backbone
➡️ [실습 : Pretrained_Model 이미 '잘 만들어진' 모델들을 사용]
vvg 모델
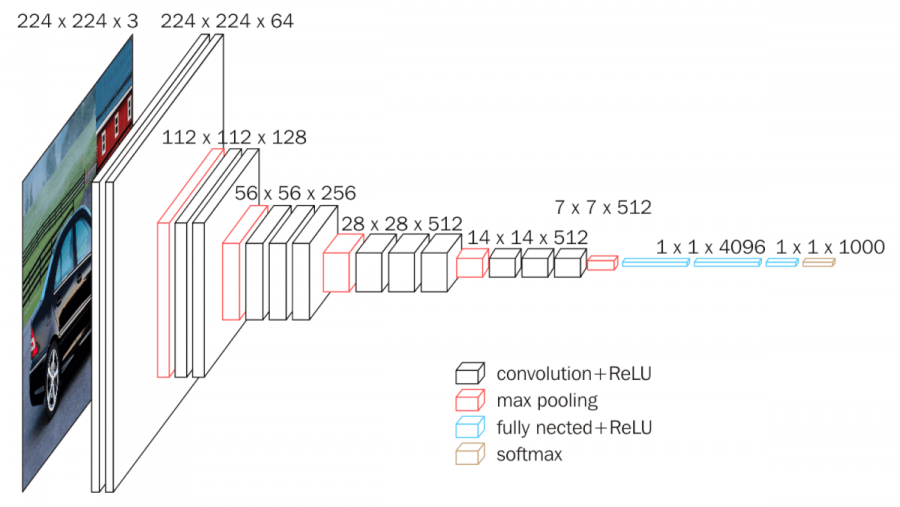
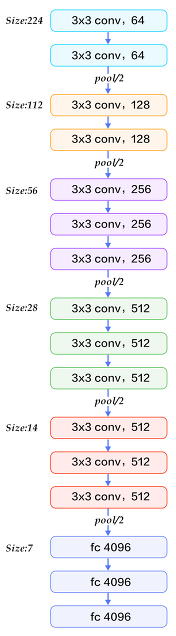
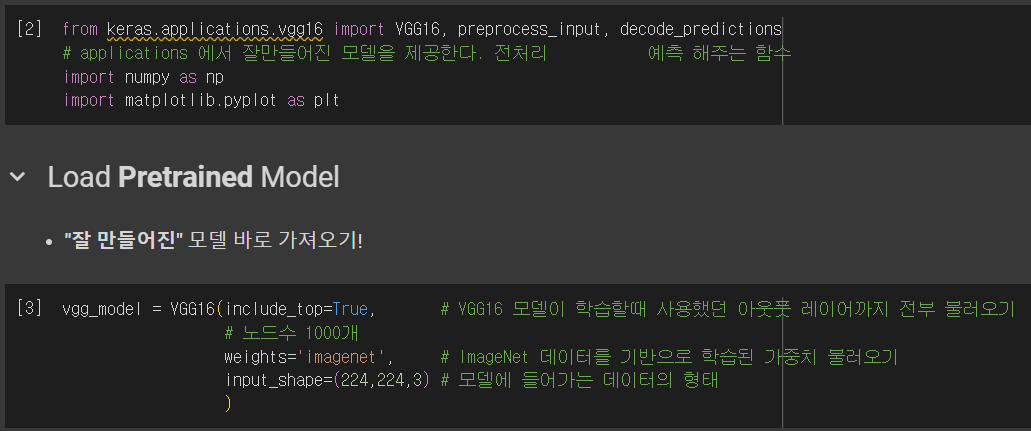
📌 Object Detection
📖 Object Detection = Classification + Localization
정확히 Multi-Labeled Classification + Bounding Box Regression
-
Localization VS Object Detection
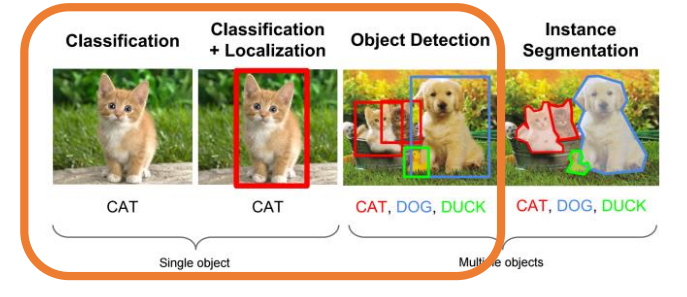
-
Localization

-
Object Detection
여러 개의 Object들의 위치를 Bounding Box로 지정하여 찾음

📖 Bounding Box
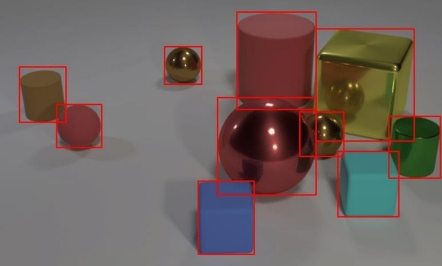
- Bounding Box : x min, y min, x max, y max , x center, y center, width, height
즉, 하나의 Object가 포함된 최소 크기 박스 , 위치 정보 이다.
cf) CNN에서도 위치 정보를 중요하게 다뤘다.

- Object Detection은 꼭짓점을 잘 예측하게 하는 것이다.
- Object Detection은 지도학습 => 예측값 , 실제값 필요하다.
📖 Confidence Score

-
Confidence Score : Object가 Bounding Box 안에 있는지 확신의 정도
다른말로 실제 확률이 아니라, 박스에 대한 모델의 자체 신용평가이다.
실제 객체위치와 관계없이 모델이 혼자 박스그리고 난 이 정도 가능성을 가지고 객체가 여기 있을거라 생각하는것 -
Confidence Score는 박스안에 Object가 존재하는지를 얼마나 확신하는지 평가
- Confidence Score : 0 ~ 1
- Ground-Truth Bounding Box의 Confidence Score = 1
- 모델에 따라 계산이 조금씩 다름
1. 단순히 Object가 있을 확률
2. Object가 있을 확률 X IoU
3. Object가 특정 클래스일 확률 X IoU
-
Confidence Score가 높다는 것은 모델이 스스로 판단했을 때 해당 박스 안에 객체가 있을 가능성이 높다고 "평가"하는 것. 이 점수는 실제 객체 존재 여부와 일치할 수 있지만, 모델의 예측일 뿐이므로 오류 가능성도 존재한다.
-
높은 Confidence Score = 모델이 예측한 박스 안에 객체가 있을 가능성이 높다고 자기 평가함. 하지만 실제로 객체가 있을 확률과는 다름 = 모델의 예측이 항상 옳지 않을 수 있음. 모델이 오판하거나, 박스 위치가 정확하지 않을 수 있다.
따라서, Confidence Score는 모델의 예측 신뢰도일 뿐, 절대적인 보장이 아니다. 이를 감안해 Threshold 등을 설정하여, 신뢰도가 충분히 높은 예측만 사용하는 것이 일반적이다.
📖 IoU (Intersection over Union)
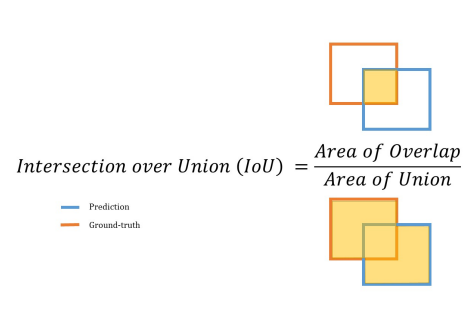
- IoU : 예측된 박스의 위치가 실제 물체의 위치와 얼마나 일치하는지 평가
- 두 박스의 중복 영역 크기를 통해 측정 -> 겹치는 영역이 넓을수록 좋은 예측
- IoU 값 범위 : 0 ~ 1
📖 NMS (Non-Maximum Suppression)

모델 사용 과정 中
.train (학습과정) -> .predict (추론과정) -> ... 등이 있다면
- NMS는 추론과정에서 하는 것이다. 추론과정에서만 동작함!
➡️ NMS의 동작 방식
1. Bounding Box의 Confidence Score 내림차순정렬
가장 높은 Confidence Score를 가진 경계 상자를 선택하고, 이와 겹치는 다른 박스들의 IoU(Intersection over Union) 값을 계산한다.
IoU는 두 경계 상자가 얼마나 겹치는지를 평가하는 척도이므로 값이 1에 가까울수록 두 상자는 완전히 겹친다는 의미 즉, IoU 값이 설정된 임계값(threshold)보다 높은 경계 상자는 중복된 박스로 간주되어 모두 제거한다. 제거 후 남은 경계 상자에 대해 동일한 절차를 반복한다.
- Threshold(임계값) : IoU가 임계값 이상일 때 중복된 박스로 간주하여 제거함. 일반적으로 0.5에서 0.7 사이로 설정됨.
정리
Confidence Score Threshold가 높을수록 : 신뢰할 수 있는 박스들만 남음.
IoU Threshold가 낮을수록 : 겹침이 적어도 중복으로 판단하고 제거하여 더욱 깔끔하게 하나의 박스만 남김.
즉, 이 두 값이 높고 낮음에 따라 NMS는 더 엄밀하게 경계 상자를 판단하게 되며, 최종적으로 더 적은 수의 고품질 박스가 결과로 남는다.
- Confidence score threshold , IoU threshold 사용자가 조절할 수 있다.
즉, HyperParameterConfidence Score Threshold와 IoU Threshold는 NMS에서 중복된 박스를 얼마나 엄격하게 제거할지 결정하는 중요한 하이퍼파라미터들
➡️ AP , MAP
AP는 Average Precision의 약자로, 객체 탐지(Object Detection)에서 모델의 성능을 평가하는 중요한 지표.
AP는 다양한 임곗값(threshold)에서 Precision-Recall 곡선을 기반으로 계산한다. 쉽게 말해, 모델이 객체를 얼마나 정확하게 탐지하고, 그 탐지 결과들이 얼마나 신뢰할 수 있는지를 수치화한 지표입니다.
- AP가 중요한 이유:
객체 탐지에서는 단순히 정확도(accuracy)만으로 성능을 평가할 수 없기 때문에, 탐지한 결과가 얼마나 신뢰할 수 있고, 놓친 객체가 얼마나 적은지를 모두 고려하는 AP가 더 적절한 성능 지표로 사용됩니다.
e.g. )
Confidence Threshold = 0.9로 설정하면:
모델은 확신이 매우 높은(0.9 이상) 예측만 양성으로 판단한다.
이때 Precision은 높을 수 있지만, 양성으로 예측한 게 적을 테니 Recall은 낮을 수 있다.
Confidence Threshold = 0.1로 설정하면:
모델은 매우 느슨한 기준으로 거의 모든 예측을 양성으로 판단한다.
이때 Recall은 높을 수 있지만, 많은 False Positive가 생겨 Precision이 낮아질 수 있다.
- 곡선이 Precision과 Recall이 둘 다 높은 구간에서 유지된다면, 모델이 매우 좋은 성능을 내고 있다고 볼 수 있다.
곡선이 Recall이 높아질수록 Precision이 급격히 떨어지는 경우, Threshold가 낮아질수록 모델이 잘못된 예측(양성이라고 했지만 실제로는 음성)을 많이 하고 있다는 뜻이다.
이 과정을 통해 모델의 성능을 한눈에 평가할 수 있고, AP(Average Precision)를 구할 수 있다.
AP는 이 Precision-Recall 곡선 아래의 면적(AUC)을 계산한 값이다.
📖 Annotation
- Annotation : 학습과정에 필요하다 !
Annotation 안에는 Object의 Bounding Box위치나 Object 이름 등 정보가 들어있다.
e.g. ) YOLO모델에서 Annotation은 txt로 나타낸다
- a. jpg - a. txt
여기서 a 그림안에 박스들에대한 레이블을 의미한다.
📌 YOLO
1. 파일구성
- nano , s , m , l , xl : 다양한 크기의 모델 의미
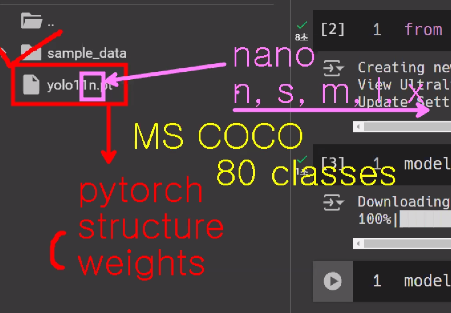
2. 파일저장방법 中 joblib / keras와는 차이점
- keras 는 가중치 , 구조 등 원본과 똑같이 저장한다. 그리고 보안상 keras 추천
3. 우리 data.yaml 파일을 쓸거야 ! (그래서 덮어쓴다)
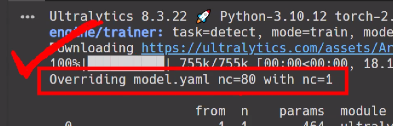
- Overriding model.yaml nc=80 with nc=1 - output layer를 80에서 1로 변경

