우분투 환경 설정
💬참고
- 내 로컬에서
ssh admin@{ip}로 입장- 또는 putty 사용
🔴2개의 SSD를 RAID1하기
ai-service가 돌아갈 서버에 ubuntu 24.04 LTS를 설치하였다.
서버엔 2개의 ssd와 1개의 hdd가 있는데, 설치할 때 removing previous storage devices에서 에러가 나 모든 저장장치를 Non-Raid로 진행하였다.
파티션 정책 설정에서 hdd(3.49T)에 boot와 root(/)폴더를 mount하여 설치를 완료하였는데, 남은 2개의 ssd를 RAID하여 사용하고자 한다.
🔻
sudo fdisk -l
현재 시스템에 연결된 모든 디스크와 디스크의 파티션 정보를 세부 정보를 보여준다.
❓참고
ssd에 밑에 보이는Partition 1 does not start on physical sector boundary경고는 파티션의 시작이 섹터의 경계에서 시작하지 않는다는 뜻으로 물리섹터 크기와 논리섹트 크기가 맞지 않아 생긴다.
사용하는데 문제는 없지만 파티션을 초기화하고 다시 설정해서 지울 수 있다.
🔻
sudo lsblk
현재 시스템에 연결된 디스크, 파티션, 논리 볼륨 등을 포함한 블록 장치(block devices)의 목록을 트리 형태로 보여준다.
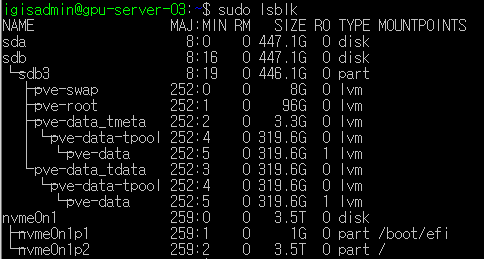
🔻
df -h
현재 시스템에 마운트된 모든 파일 시스템의 디스크 사용량을 보여준다.
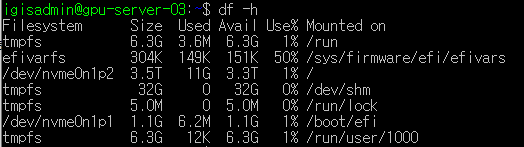
command 결과를 보면 sudo fdisk -l 엔 ssd 두개와 hdd 한개가 전부 보이지만 df -h 명령어에선 hhd 파티션인 nvme0n1p1, nvme0n1p2만 보인다.
지금 hdd만 mount되어있기 때문이다.
따라서 두개의 ssd의 파티션을 전부 초기화 ➡ 하나로 raid ➡ mount하여 사용하고자 한다.
ssd 파티션 초기화하기
이 글을 참고해 파티션을 삭제하였다.
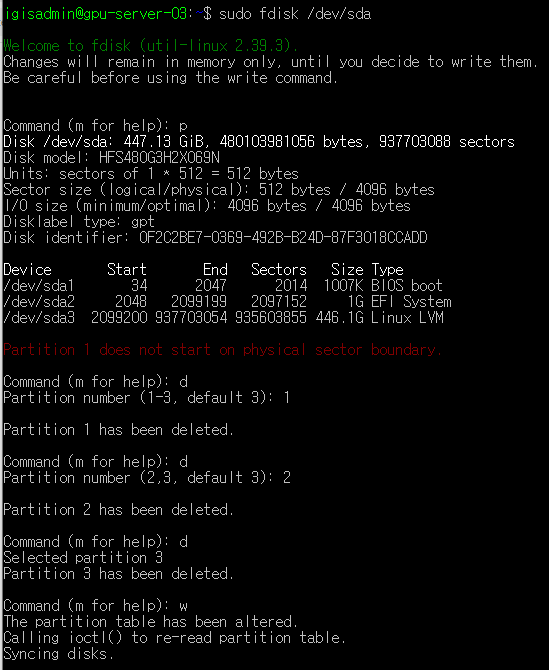
sudo fdisk /dev/sda➡ sda ssd로 입장
Command (m for help):p➡ 현재 파티션 정보 확인
Command (m for help):d➡ 파티션 삭제 (sda 뒤의 번호 고르기)
Command (m for help):w➡ 저장하고 나오기
이걸 sda, sdb 둘다 진행하였다.
sdb3에 남은 prv 어쩌구들도 다 삭제하려고 논리 볼륨을 삭제하는 명령어를 입력했다.
sudo lvremove /dev/mapper/pve-swap
sudo lvremove /dev/mapper/pve-root
sudo vgremove pve
sudo pvscan
sudo vgscan
sudo lvscan
전부 삭제했더니 sudo fdisk -l도 sudo lsblk도 깔끔하게 보인다.
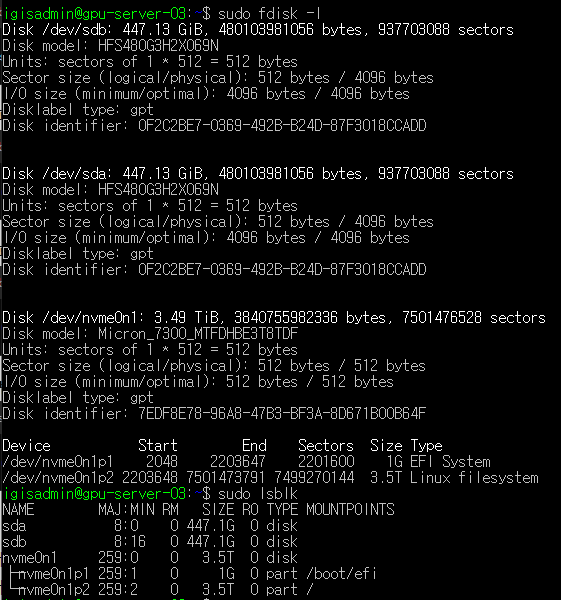
ssd에 파티션 생성
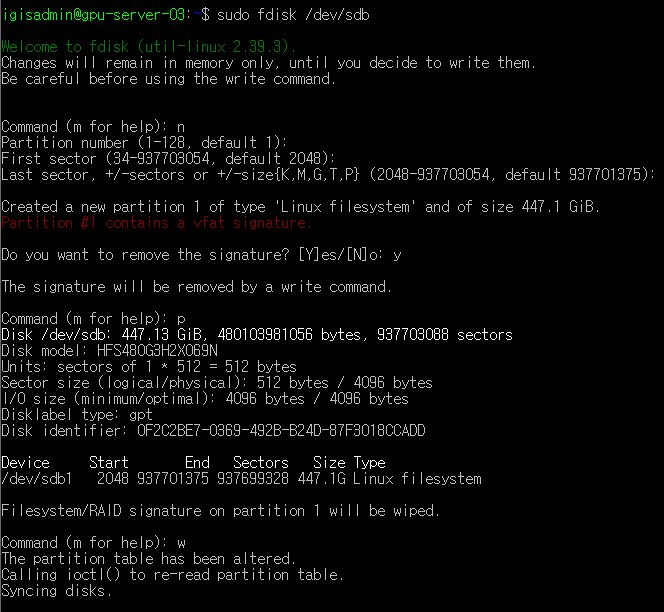
sudo fdisk /dev/sdb➡ sdb ssd로 입장
Command (m for help):n➡ 파티션 생성
Partition number:enter➡ 파티션 번호
First sector:enter➡ 파티션 시작 위치
Last sector:enter➡ 파티션 종료 위치(파티션 크기 지정 가능)
Do you want to remove the signature?:y
Command (m for help):p➡ 생성된 파티션 정보 확인
Command (m for help):w➡ 저장하고 나오기
이걸 sda, sdb 둘다 진행하여 sda1, sdb1을 생성하였다.
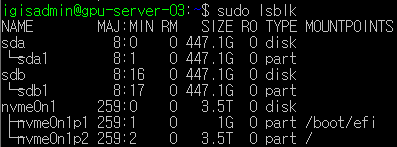
sda1, sdb1을 RAID1으로 묶기
이 글을 참고하여 진행하였다.
먼저 mdadm를 설치하고
sudo apt-get install mdadm
두 개의 디스크를 raid1으로 묶는다.
sudo mdadm --create /dev/md1 --level=1 --raid-device=2 /dev/sda1 /dev/sdb1
mdadm --create {장치명} --level={레이드 번호} --raid-device={구성할 파티션 개수} {구성 파티션 리스트}
RAID가 적용되었는지 확인
cat /proc/mdstat
 이렇게 뜨면 된다.
이렇게 뜨면 된다.
생성한 RAID1 mount하기
raid된 디스트를 포맷한다.
sudo mkfs.ext4 /dev/md1
내 raid1이 연결될 폴더를 만들고 mount한다.
sudo mkdir /home/ssd
sudo mount /dev/md1 /home/ssd
부팅할 때마다 raid와 mount가 작동할 수 있도록 설정한다.
sudo mdadm --detail --scan | sudo tee -a /etc/mdadm/mdadm.conf
sudo update-initramfs -u
echo '/dev/md1 /home/ssd ext4 defaults 0 0' | sudo tee \-a /etc/fstab
결과 확인
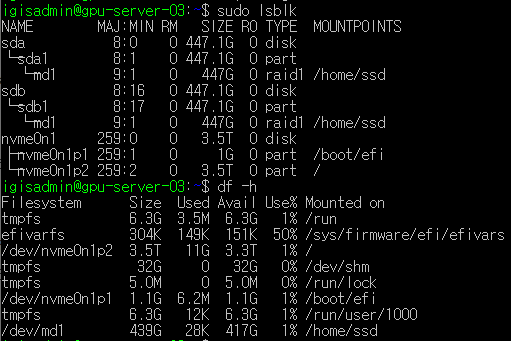
sudo lsblk와 df -h로 확인해보면 raid1이 잘 생성되어 mount까지 되었다.
sudo fdisk -l로도 확인
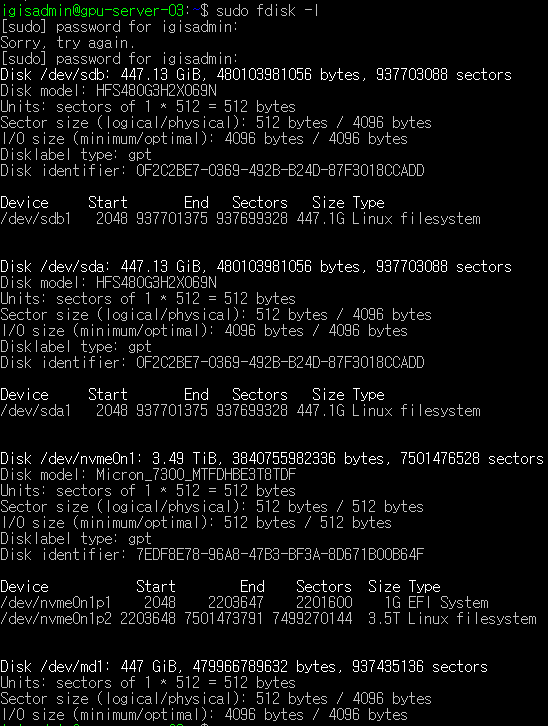 즉 저장공간 sda와 sab에 각 sda1, sdb1이라는 파티션을 생성하고 md1라는 이름으로 raid1해서 /home/ssd 경로에 mount하였다.
즉 저장공간 sda와 sab에 각 sda1, sdb1이라는 파티션을 생성하고 md1라는 이름으로 raid1해서 /home/ssd 경로에 mount하였다.
🟠docker 설치하기
docker docs 참고해서 설치했다.
도커 설치
Docker apt 저장소를 설정하고
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update최신버전 Docker 패키지를 설치한다.
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Docker 엔진 설치가 성공했는지 확인하기 위해 hello-world 이미지를 실행해본다.
sudo docker run hello-world
테스트 이미지를 다운로드하여 컨테이너에서 실행하고 컨테이너가 실행되면 확인 메시지를 인쇄하고 종료된다.
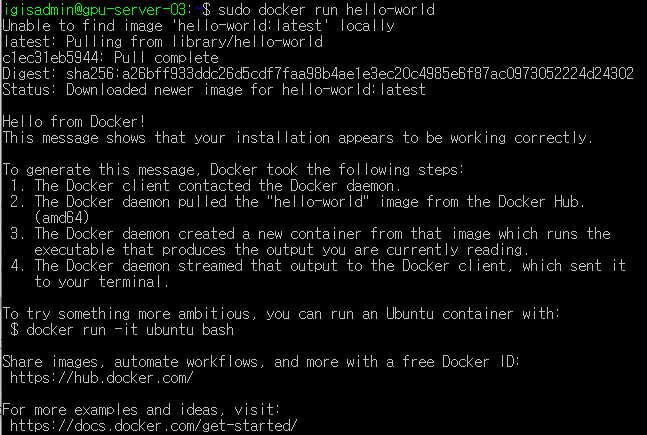 이렇게 나온다면 설치 성공!
이렇게 나온다면 설치 성공!
설치 후 사용자 설정
명령어 앞에 sudo를 붙이지 않고도 도커를 사용하기 위해선 그룹을 만들어 사용자를 추가해야한다.
그룹생성하고
sudo groupadd docker
사용자를 그룹에 추가한다
sudo usermod -aG docker $USER1
$USER 환경 변수는 현재 로그인한 사용자 아이디를 나타낸다.
재부팅하고
sudo reboot
sudo없이도 명령어를 실행할 수 있는지 확인
docker run hello-world
잘된다!
NVIDIA 그래픽 카드 드라이버 설치
GPU 모델과 드라이버 확인
sudo lshw -c display
- product(gpu모델): RTX A4000
- configuration(그래픽 카드 드라이버 이름): nouveau
설치 가능한 드라이버 목록 확인
sudo ubuntu-drivers devices
recommended되어있는 nvidia-driver-535 설치
드라이버 설치
sudo apt install nvidia-driver-535
재부팅하고
sudo reboot
다시 sudo lshw -c display에 들어가서 configuration을 확인하면 nvidia로 바뀌어있다.
nvidia-smi으로 확인
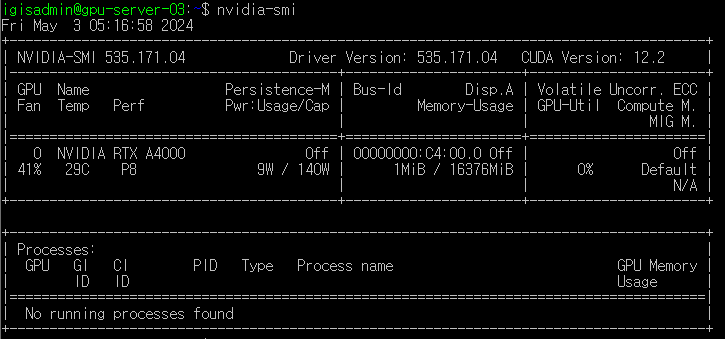 드라이버 설치 성공!
드라이버 설치 성공!
NVIDIA Container Toolkit 설치
nvidia 공식문서에서 참고
production 저장소 구성
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list패키지 목록 업데이트
sudo apt-get update
NVIDIA Container Toolkit packages 설치
sudo apt-get install -y nvidia-container-toolkit
도커가 Nvidia Container Runtime을 사용할 수 있도록 /etc/docker/daemon.json 파일 수정
sudo nvidia-ctk runtime configure --runtime=docker
도커 재시작
sudo systemctl restart docker
pytorch 이미지 다운로드하고 container 실행해보기
먼저 Docker hub 사이트에서 pytorch 이미지를 다운로드한다.
Tags에서 원하는 버전 다운로드 가능해 cuda11.8을 가져왔다.
docker pull pytorch/pytorch:2.1.2-cuda11.8-cudnn8-devel
images 명령어로 다운받은 이미지들을 확인
docker images
 Tag나 ID도 볼 수 있다.
Tag나 ID도 볼 수 있다.
도커 컨테이너를 생성 및 실행
docker run -itd --name pytorch --gpus all pytorch/pytorch:2.1.2-cuda11.8-cudnn8-devel
$ docker run \
-i \ # 컨테이너에 키보드 입력이 필요한경우
-t \ # 컨테이너에 TTY할당하여 터미널 이용이 필요한 경우
--rm \ # 컨테이너 실행 종료후 자동 삭제가 필요할때
-d \ # 백그라운드로 실행하고 싶을 때
--name hello-world \ # 이름을 지정하고 싶을때
-p 80:80 \ # 포트 바인딩을 하고 싶을 때
-v /opt/example:/example \ # 볼륨 바인딩을 하고 싶을 때
bbangi/hello-world:latest \ # 실행할 이미지는 그냥 적어주기
my-command # 마지막은 컨테이너 내에서 실행할 명령어-it는 shell을 실행하기 위한 용도로 한쌍으로 생각하는것이 좋다.
docker run -it --name pytorch --gpus all pytorch/pytorch:2.1.2-cuda11.8-cudnn8-devel /bin/bash
이렇게 실행하면 바로 컨테이너에 접속되고 명령어 치고 나오면 컨테이너가 종료된다.
실행중인 컨테이너를 보려면
docker ps
전체 컨테이너(종료된거 포함)를 보려면
docker ps -a

실행중인 컨테이너에 접속
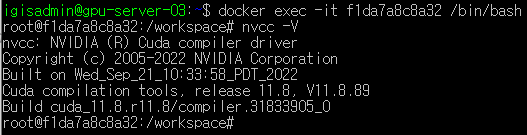
docker exec -it f1da7a8c8a32 /bin/bash
docker exec -it {container_id} /bin/bash
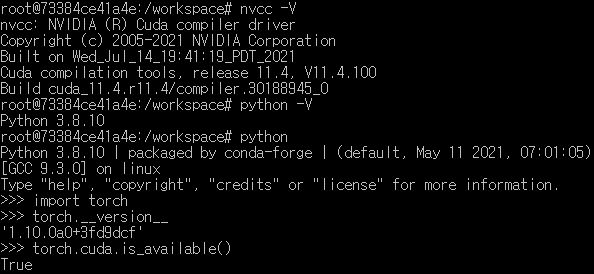
컨테이너에 접속 후 nvcc -V로 cuda version을 확인하면 다운받은 이미지인 11.8로 나온다.
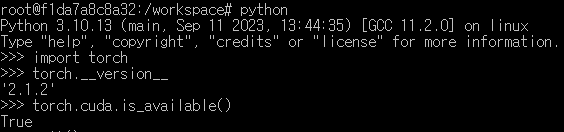
 torch.cuda.is_available()도 True로 나옴
torch.cuda.is_available()도 True로 나옴
컨테이너 나가기
exit
지금은 docker ps에서 컨테이너가 살아있다.
컨테이너 종료
docker stop f1da7a8c8a32
docker stop {container_id}
이렇게 종료하면 docker ps에서 컨테이너가 사라진다.
yolov7을 실행시킬 image 가져오기
yolov7 git을 참고하여 docker 환경을 설정한다.
내 서버 home경로 ai-service폴더 만들고 거기에 coco폴더와 yolov7폴더를 생성했다.
mkdir ai-service
cd ai-service
mkdir coco
mkdir yolov7
이제 이 폴더들과 컨테이너의 폴더들을 mount하여 yolov7 컨테이너를 시작한다.
docker run --name yolov7 -it -v /home/igisadmin/ai-service/coco/:/coco/ -v /home/igisadmin/ai-service/yolov7/:/yolov7 --shm-size=64g --gpus all nvcr.io/nvidia/pytorch:21.08-py3
-v {host 경로}:{컨테이너 경로}
yolov7 컨테이너에 접속했다면 apt로 필요한 패키지를 설치하고
apt update
apt install -y zip htop screen libgl1-mesa-glx
pip로 필요한 패키지도 설치한다.
pip install seaborn thop
 대충 환경은 이렇다.
대충 환경은 이렇다.
yolov7 이미지를 기반으로 fastAPI 쓸 수 있는 이미지 생성하기
방금 만든 yolov7 컨테이너에서 fastAPI를 다운받고
pip install fastapi
pip install uvicorn[standard]
그외 필요한 ffmpeg, opencv-python도 다운받았다.
apt install ffmpeg
pip install opencv-python==4.4.0.42
pip install opencv-python-headless==4.4.0.42
처음에 opencv==4.3.0.36을 설치하였는데 영상이 끝나도 ret, frame = video.read()에서 ret이 계속 True가 나오는 버그가 있어서 버전을 올렸다.
exit로 컨테이너를 나간다음
yolov7 컨테이너의 환경을 바탕으로 fastapi-service라는 이미지를 생성한다.
docker commit yolov7 fastapi-service
fastapi-service 이미지로 fastapi-yolov7 컨테이너를 생성한다.
docker run --name streaming_process -it -v /home/igisadmin/ai-service/coco/:/coco/ -v /home/igisadmin/ai-service/yolov7/:/yolov7 --shm-size=64g -p 8000:8000 --gpus all fastapi-service
-p {host port}:{컨테이너 port}
mount되어있는 yolov7폴더에 fastAPI 기본 코드가 담겨있는 main.py파일을 만들어두었다.
fastapi-yolov7 컨테이너에서 yolov7폴더로 이동하고
cd /yolov7
fastapi를 실행하면
uvicorn main:app
 일단 fastAPI는 잘 실행된다.
일단 fastAPI는 잘 실행된다.
내 local에서 이 페이지를 접근하려면 --host 0.0.0.0 파라미터로 외부에서 이 서버에 접속할 수 있도록 아이피를 개방해야한다.
uvicorn main:app --host 0.0.0.0 --port 8000
이제 내 local 크롬에서 url 검색칸에 http://{ip}:8000/라고 입력하면 접근 할 수 있다.
{ai 서버의 ip}:{8000}
필요한 폴더를 포함하면서 fastAPI를 실행까지 한번에 해주는 image build하기
지금 사용한 이미지는 내 서버의 폴더와 컨테이너의 폴더를 mount해서 data를 사용할 수 있게 하였다.
난 이 이미지로 컨테이너를 생성해서 컨테이너에서 uvicorn main:app 명령어로 fastAPI를 실행했다.
지금부터는 아예 내 ai service가 돌려지는데 필요한 파일들(fastAPI 실행할 python 파일, detect model, yolov7 git 폴더 전체 등)을 모두 포함하고 이 이미지로 컨테이너를 시작하면 fastAPI가 자동으로 실행되는 완전체 image를 만들고자 한다.
먼저 source폴더에 필요한 파일들을 모두 넣었다.
(docker_process_ubuntu폴더엔 fastAPI main 파일과 detect하는 python 파일들이 들어있다.)

Dockerfile을 만들고 이미지 설정에 필요한 코드를 작성한다.
FROM fastapi-service:latest
COPY /source /home
WORKDIR /home/docker_process_ubuntu
CMD ["uvicorn", "streaming_ffmpeg_main:app", "--host", "0.0.0.0", "--port", "8000"]image를 생성한다.
docker build -t forestdiseasedetect-service .
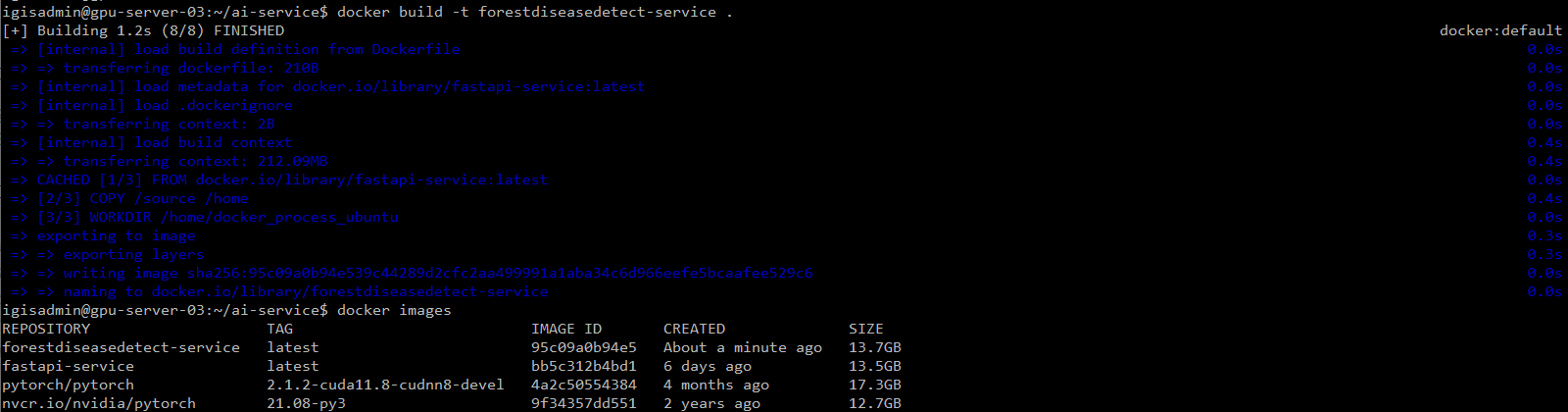
docker images로 확인했더니 image가 잘 생성되었다.
이제 이 이미지로 컨테이너를 생성한다.
docker run --name forestdisease_streaming_process -p 8000:8000 --gpus all forestdiseasedetect-service
컨테이너는 생성되면서 바로 fastAPi를 실행한다.
http://{ip}:8000/로 접근해서 service를 사용할 수 있다.
