문자 인코딩에 대해 처음 맞닥뜨리면 ASCII, ISO-8859, Unicode 등 종류가 많아 헷갈린다.
표준으로 딱! 한 개만 있으면 좋을 텐데 왜 여러 개가 있을까?
여기엔 역사처럼 흐름이 있으며 크게 3부로 나누어 정리해본다.
1부: 문자 표현이 필요해 (ASCII의 탄생)
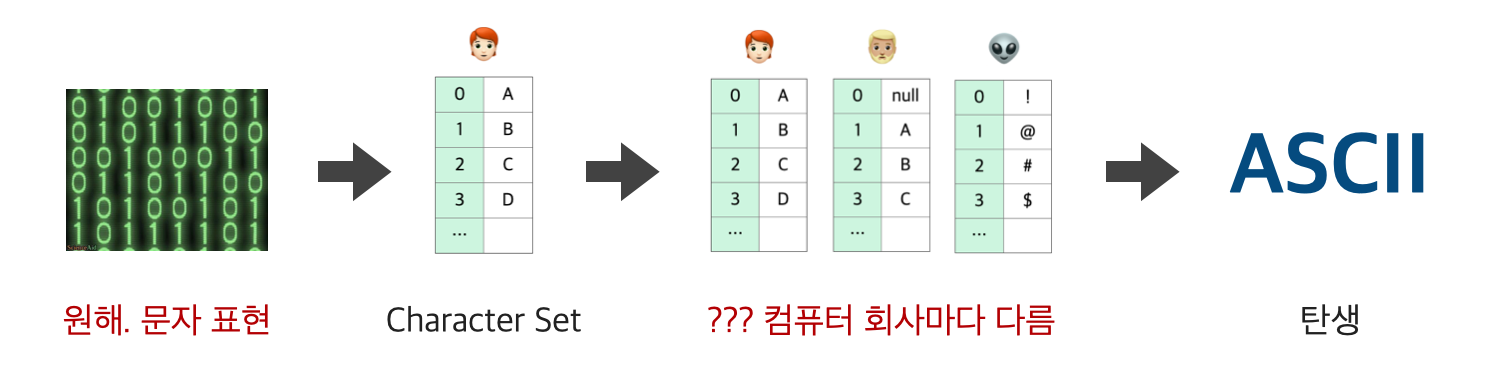
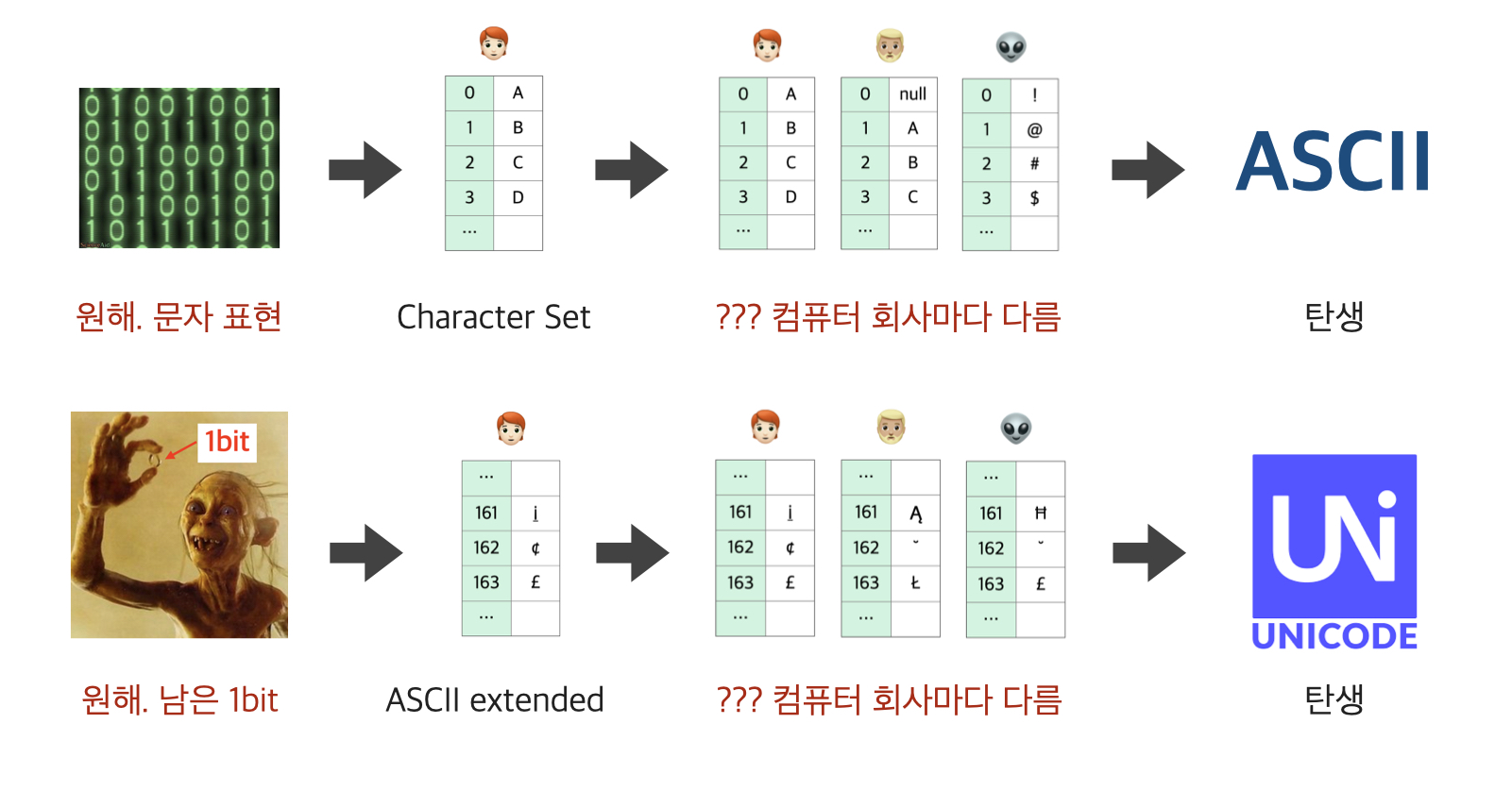
원래 최초의 컴퓨터는 계산을 위해 만들어졌었다.
하지만 시간이 지남에 따라 문자 표현에 대한 니즈가 생겼고, 문자와 숫자를 1:1 매핑한 문자표라고 할 수 있는 character set을 정의하게 됐다.
- 예시) 내 컴퓨터에선 65를
A로, 66은B로 해야지~
문제는 표준 규약이나 글로벌이란 개념이 미미할 때라 컴퓨터 제조사마다 각각 다른 character set을 사용한 것이다.
- 예시) 내 컴퓨터에선 65가
A로 보이는데 다른 컴퓨터에선#임
그래서 지금의 ANSI🇺🇸에서 표준화한 것이 ASCII이다.

- ASCII (American Standard Code for Information Interchange)
- 알파벳, 숫자, 공백문자, 제어문자, 특수문자로 구성됨
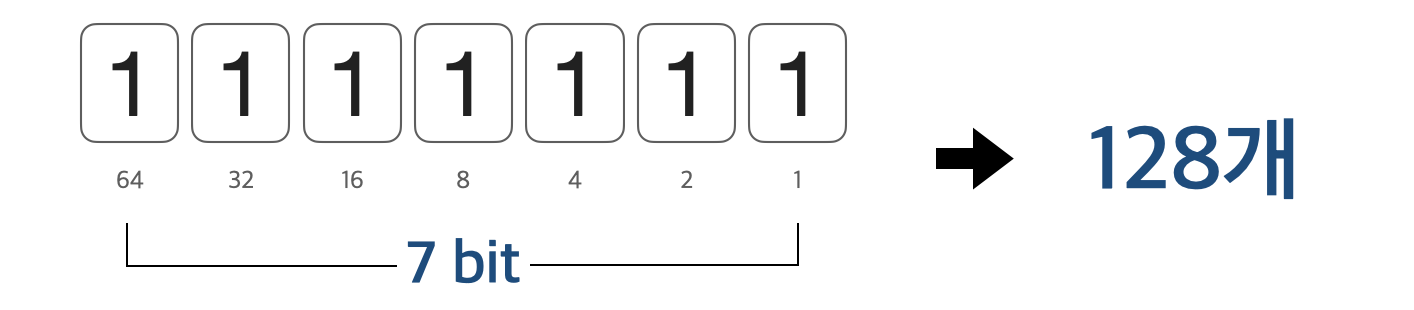
ASCII는 7bit를 사용하므로 charset에는 0~127(2⁰~2⁶)까지 총 128개(2⁷)의 문자가 1:1 매칭되어 있다.
2부: 남는 1bit를 원해 (ISO-8859의 탄생)
이렇게 ASCII를 표준으로 지정했지만 몇 가지 ASCII의 부족한 점과 상황이 맞물려 이 역사의 2부가 시작된다.
🤔
ASCII의 부족한 점
ASCII에는 미국 영어만 있다- 수학 기호가 충분치 않다
🤔 그 당시 상황
- 8bit = 1byte가 표준화되기 시작했음

표현하고 싶은 글자들은 많은데 마침 1bit의 여분이 생긴다면 누구나 효율적으로 채워 쓰고 싶을 것이다.
이런 이유로 많은 제조사들이 자체적으로 ASCII를 확장하기 시작한다.
8bit(1byte)에서 7bit인 ASCII를 쓰고 남는 이 1bit를 각자 확장한 것이다.
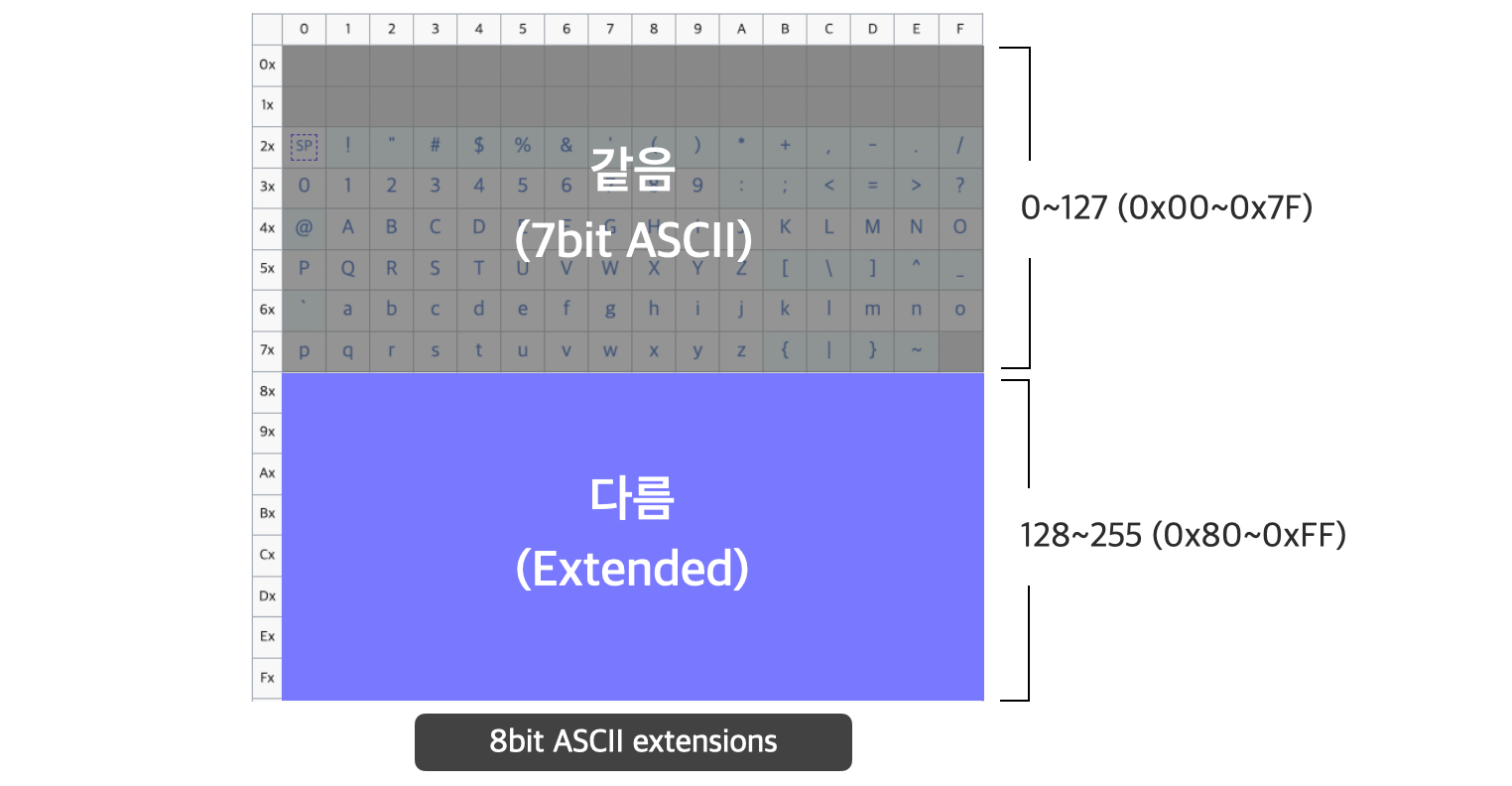
그러다보니 확장된(Extended) 1bit 부분이 서로 달라지게 됐고,
이 8bit 확장된 ASCII를 최초로 공식화한 국제 표준이 ISO의 ISO-8859 시리즈이다.
그래서 인코딩에 따라 ISO-8859 시리즈가 아래와 같이 128번(0x80)부터 결과가 다른 것이다.
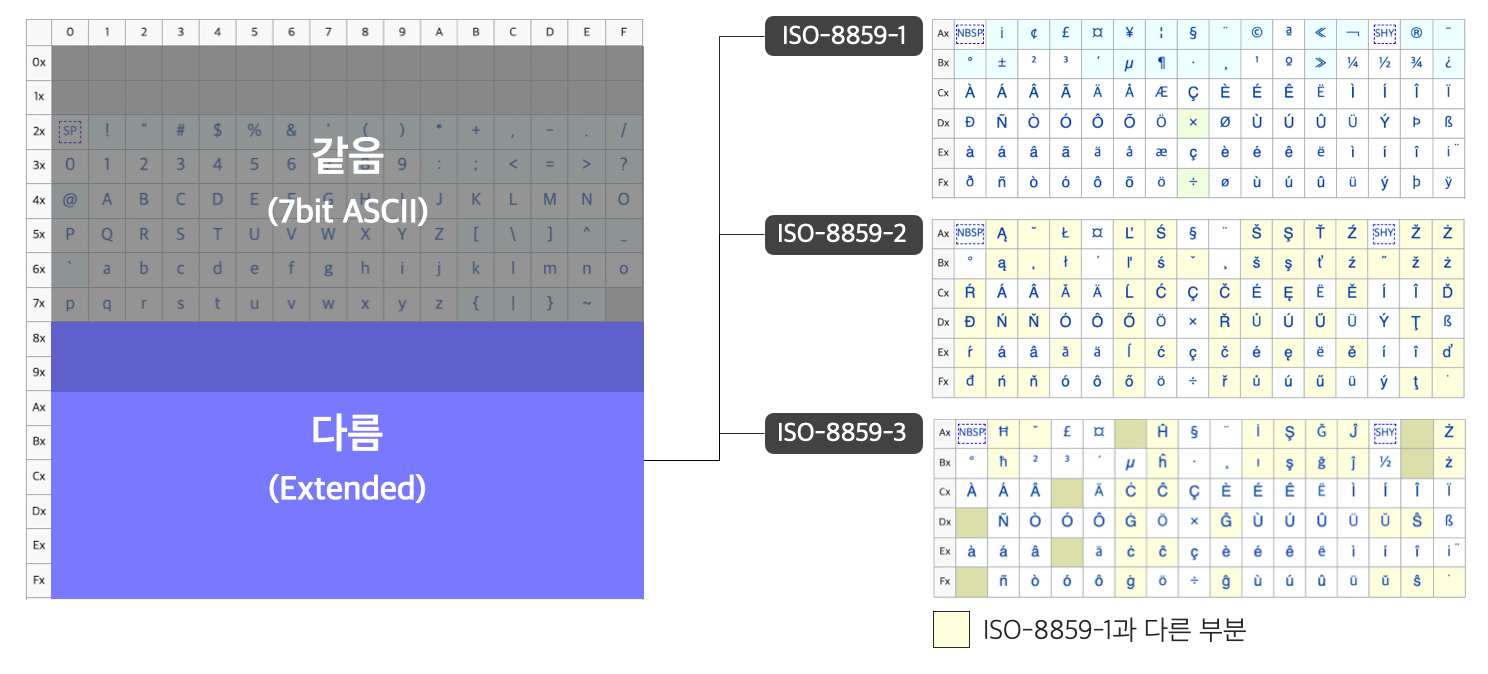
ISO 8859-1- 우리가 자주 보는 Latin1 (서유럽)ISO 8859-2- Latin2 (중앙유럽)- ...
ISO 8859-16- Latin10 (남동유럽)
따라서 두 인코딩은 두 개의 다른 문자에 대해 동일한 숫자를 사용하거나, 동일한 문자에 대해 다른 숫자를 사용할 수 있는 문제점이 여전히 존재하게 된다.
💡 참고
확장된 ASCII(Extended ASCII)라는 용어는 ASCII 표준이 128자 이상을 포함하도록 업데이트 됐다는 의미로 오용될 수 있다는 지적이 있다고 한다.
3부: 세상의 모든 언어의 문자를 표현할래 - 유니코드의 탄생
2부에 여러 인코딩이 등장했지만 여전히 부족함을 느낄 것이다.
- 128번(0x80)부터 인코딩끼리 서로 충돌함
- 전 세계 모든 언어의 문자를 지원하는 인코딩이 없음
그래서 이런 것들을 해결하기 위해 유니코드(Universal character encoding)가 탄생하게 된 것이다.
⛳️ 목표
- 세계의 각 문자마다 숫자(code point)를 할당하자!
📍 참고
- 시기적으로 1987년도에 ISO-8859 시리즈도 개정 시작되었고, 유니코드도 이때쯤부터 탐구가 시작됐다.
- 1991년도부터는 유니코드 컨소시엄, ISO, IEC가 함께 유니코드 표준을 개발하기 시작한다.
추가로,
이렇게 우여곡절 끝에 탄생한 유니코드에도 변화가 있었으니,
오래~~된 개발 책을 보면 유니코드가 6만여개를 표현한다고 적혀있는데 유니코드의 최초 버전은 고정 너비 16bit 인코딩으로 설계됐었기 때문이다.

하지만 기존의 많은 legacy character set과의 호환성과 아시아권의 폭발적인 글자 갯수 등의 이유로 16bit(=65536개)가 더 이상 충분하지 않아져서 유니코드 2.0부터 21bit에 해당하는 범위로 늘어나 현재는 약 110만 개의 글자를 나타낼 수 있게 됐다.
📍 참고
java를 공부하면서 "char type은 왜 2byte로 정했을까? 2byte를 넘는것도 있는데?"라고 궁금한적이 있었다면,
마치며
-
이걸 공부하며 느낀 내 생각은 완벽한 설계는 없고, 변화에 맞춰 답을 찾아나가다 보니 이렇게 여러 가지가 생긴 것 같다.
-
이 글을 읽고 태초(?)의 표준 인코딩인 ASCII를 근간으로 대부분의 인코딩이 파생됐다는 것과 왜 많은 인코딩들이 127번(7bit)까지만 동일한건지 정리되었으면 좋겠다.
-
평소에 이건 왜 이렇지?라는 의문들이 이 히스토리를 알게되면서 납득가는 부분이 있어 함께 정리해봤다.
-
개인적으론
확장된 ASCII보다는ASCII와 호환되는 인코딩이라는 말이 더 좋은 것 같다.
