어떤 방식으로 'A', '가' 같은 텍스트가 byte로 바뀌는 것일까?
문자 인코딩 structure의 큰 흐름을 보기 위해 Unicode Character Encoding Model에 대해 간단하게 알아보자.
유니코드란?
- What is Unicode?
유니코드는 모든 언어로 된 텍스트 데이터의 처리, 저장 및 교환을 위한 기반을 제공하는 문자 인코딩이다.
유니코드는 인코딩할 문자 목록을 정의하고 문자를 나타내는 방법에 대한 체계적인 규칙을 제공한다.
유니코드는 모든 언어를 다루므로 다양한 표준과 기술이 필요한 것이다.
- Unicode Bidirectional Algorithm - 아랍어는 오른쪽>왼쪽으로 읽지만, 숫자는 왼쪽>오른쪽으로 읽으므로 양방향 표시 알고리즘이 필요
- Unicode Vertical Text layout - 일본어는 텍스트를 세로로 표시하는데, 일본어는 수직으로 영어는 눕혀서 표시하므로 필요
- ...etc
Unicode Character Encoding Model
유니코드의 문자 인코딩 구조에 대한 모델 레벨 4가지는 아래와 같다.
- Abstract Character Repertoire(
ACR) - 인코딩할 abstract character의 집합 - Coded Character Set(
CCS) - ACR을 음수가 아닌 정수 집합으로 매핑 - Character Encoding Form(
CEF) - code point를 code unit으로 매핑 - Character Encoding Scheme(
CES) - code unit sequence를 byte sequence로 매핑
흐름을 간단히 보자면 이렇다.
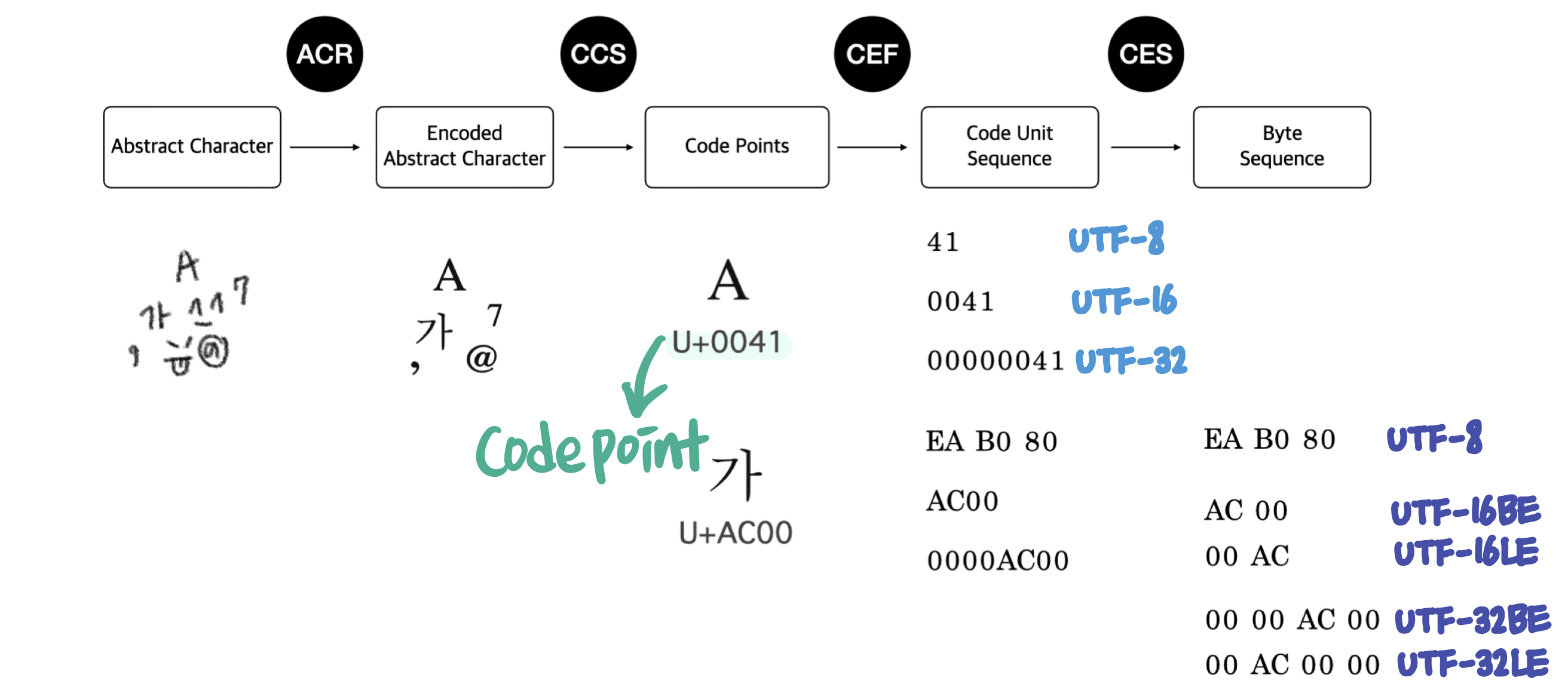
ACR의 예시로는 Unicode/10646 repertoire와 Latin1의 서유럽 알파벳, 기호가 있다.
우리가 흔히 문자표라고 말하는 것은 CCS에 해당한다.
유니코드는 CEF 세 가지와 CES 일곱 가지가 있다.
CEF- UTF-8, UTF-16, UTF-32CES- UTF-8, UTF-16, UTF-16BE, UTF-16LE, UTF-32, UTF-32BE, UTF-32LE
UTF는 CES? CEF?뭐라고 불러야하나?
- What is a UTF?
Code point에서 고유한 Byte sequence로의 알고리즘 매핑
UTF는 Unicode Transformation Format의 약자인데 이 용어는 CEF와 CES에 대한 모호한 동의어이고, 이제는 CES라고 부르는 것이 선호된다고 한다.
CEF로서 UTF-16, UTF-32는 메모리에서 엑세스할 때 코드 단위를 나타내며,CES로서 UTF-16, UTF-32는 serialized bytes를 나타내기 때문이다.
이렇듯 약어인 UTF-16나 UTF-32는 잘못 해석될 여지가 있으므로 form이나 scheme의 용어 구분이 중요한 경우 전체 용어를 사용해야 한다고 한다.
문서를 보다가 풀 네임이 나오면 의미를 주의해서 읽자.
마치며
이번 포스팅은 문자 인코딩의 흐름을 간략하게 알아보는걸 목표로 했다.
UTF-8, UTF-16에 대한 자세한 것은 다음 포스팅에서 알아보자.
